







 本文介绍了HuggingFace的核心库,包括用于构建和训练NLP模型的Transformers和数据集管理的Datasets。重点讲解了Pipeline的使用,如何在GPU上加速计算,以及评估模型的Metrics和使用AutoClasses加载预训练模型。此外,还涵盖了模型的本地保存和加载。
本文介绍了HuggingFace的核心库,包括用于构建和训练NLP模型的Transformers和数据集管理的Datasets。重点讲解了Pipeline的使用,如何在GPU上加速计算,以及评估模型的Metrics和使用AutoClasses加载预训练模型。此外,还涵盖了模型的本地保存和加载。
Hugging Face 主要类和函数介绍
本文旨在为初学者介绍Hugging Face的主要类和函数,包括Pipeline, Datasets, Metrics, and AutoClasses。HuggingFace是一个非常流行的 NLP库。本文包含其主要类和函数的概述以及一些代码示例。可以作为该库的一个入门教程 。本文所有代码通过Colab notebook进行编写!
Hugging face是什么?
Hugging face 是一家总部位于纽约的聊天机器人初创服务商,开发的应用在青少年中颇受欢迎,相比于其他公司,Hugging Face更加注重产品带来的情感以及环境因素。官网链接在此 https://huggingface.co/ 。
但更令它广为人知的是Hugging Face专注于NLP技术,拥有大型的开源社区。尤其是在github上开源的自然语言处理,预训练模型库 Transformers,已被下载超过一百万次,github上超过24000个star。Transformers 提供了NLP领域大量state-of-art的预训练语言模型结构的模型和调用框架。以下是repo的链接(https://github.com/huggingface/transformers)
这个库最初的名称是pytorch-pretrained-bert,它随着BERT一起应运而生。pytorch-pretrained-bert用当时已有大量支持者的pytorch框架复现了BERT的性能,并提供预训练模型的下载,使没有足够算力的开发者们也能够在几分钟内就实现state-of-art-fine-tuning。
直到2019年7月16日,在repo上已经有了包括BERT,GPT,GPT-2,Transformer-XL,XLNET,XLM在内六个预训练语言模型,这时候名字再叫pytorch-pretrained-bert就不合适了,于是改成了pytorch-transformers,势力范围扩大了不少。这还没完!2019年6月Tensorflow2的beta版发布,Huggingface也闻风而动。为了立于不败之地,又实现了TensorFlow 2.0和PyTorch模型之间的深层互操作性,可以在TF2.0/PyTorch框架之间随意迁移模型。在2019年9月也发布了2.0.0版本,同时正式更名为 transformers 。到目前为止,transformers 提供了超过100种语言的,32种预训练语言模型,简单,强大,高性能,是新手入门的不二选择。
但是,对于我们来说,Hugging Face 是一个开源库,用于构建、训练和部署最先进的NLP模型。Hugging Face 提供了两个主要的库,用于模型的transformers 和用于数据集的datasets 。可以直接使用 pip 安装它们。
pip install transformers
什么是自然语言处理?
NLP 是语言学和机器学习交叉领域,专注于理解与人类语言相关的一切。 NLP 任务的目标不仅是单独理解单个单词,而且是能够理解这些单词的上下文。
以下是常见 NLP 任务的列表,每个任务都有一些示例:
- 对整个句子进行分类: 获取评论的情绪,检测电子邮件是否为垃圾邮件,确定句子在语法上是否正确或两个句子在逻辑上是否相关
- 对句子中的每个词进行分类: 识别句子的语法成分(名词、动词、形容词)或命名实体(人、地点、组织)
- 生成文本内容: 用自动生成的文本完成提示,用屏蔽词填充文本中的空白
- 从文本中提取答案: 给定问题和上下文,根据上下文中提供的信息提取问题的答案
- 从输入文本生成新句子: 将文本翻译成另一种语言,总结文本
NLP 不仅限于书面文本。它还解决了语音识别和计算机视觉中的复杂挑战,例如生成音频样本的转录或图像描述。
Pipeline
使用transformers库中的Pipeline是开始试验的最快和最简单的方法:通过向Pipeline对象提供任务名称,然后从Hugging Face模型存储库中自动下载合适的模型,然后就可以使用了!
transformers库中已经提供了以下的几个任务,例如:
- 文本分类
- 问答
- 翻译
- 文本摘要
- 文本生成
除此以外还有计算机视觉和音频任务(主要也是基于transformer的)。下面是一个情绪分析任务的例子。为了预测句子的情绪,只需将句子传递给模型。
Transformers 库中最基本的对象是pipeline() 函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够通过直接输入任何文本并获得最终的答案:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")

我们也可以多传几句:

results = classifier("I'm so happy today!")
print(f"{results[0]['label']} with score {results[0]['score']}")
# POSITIVE with score 0.9998742341995239
模型的输出是一个字典列表,其中每个字典都有一个标签(对于这个特定示例,值为“POSITIVE”或“NEGATIVE”)和一个分数(即预测标签的分数)。
也可以通过设置模型名称的参数指定要使用的模型,所有的模型和关于模型的信息都在官方文档中提供了。例如下面代码使用的是twitter-roberta-base-sentiment

执行分析并输出结果:

默认情况下,此pipeline选择一个特定的预训练模型,该模型已针对英语情感分析进行了微调。创建分类器对象时,将下载并缓存模型。如果重新运行该命令,则将使用缓存的模型,无需再次下载模型。
将一些文本传递到pipeline时涉及三个主要步骤:
- 文本被预处理为模型可以理解的格式。
- 预处理的输入被传递给模型。
- 模型处理后输出最终人类可以理解的结果。
目前可用的一些pipeline是:
- 特征提取(获取文本的向量表示)
- 填充空缺
- NER(命名实体识别)
- 问答
- 情感分析
- 文本摘要
- 文本生成
- 翻译
- 零样本分类
Dataset
Dataset库可以轻松下载 NLP 中使用的一些最常见的基准数据集。
我们尝试加载Stanford Sentiment Treebank (SST2) ,它包含来自电影评论的句子和对其情感的人工注释。它使用双向(正面和负面)类分割,只有句子级别的标签。我们可以在数据集库下找到SST2数据集,它作为GLUE数据集的一个子集存储。我们使用load_dataset函数加载数据集。
import datasets
dataset = datasets.load_dataset("glue", "sst2")
print(dataset)

数据集已经被分为训练集、验证集和测试集。可以使用split参数调用load_dataset函数,直接得到我们感兴趣的数据集的拆分。
dataset = datasets.load_dataset("glue", "sst2", split='train')
print(dataset)

如果想使用 Pandas 处理数据集,可以直接使用数据集的对象创建df。
import pandas as pd
df = pd.DataFrame(dataset)
df.head()

Pipeline on GPU
现在,已经加载了有关情感分析的数据集,我们尝试使用它的情感分析模型。
要提取数据集中的句子列表,我们可以访问其数据属性。预测500个句子的情感,并测量它需要多长时间。
classifier = pipeline("sentiment-analysis")
%time results = classifier(dataset.data["sentence"].to_pylist()[:500])

预测 500 个句子需要 27.9 秒,平均每秒 18 个句子。
现在,我们试试 GPU。为了让分类器使用 GPU,首先必须保证GPU是可用的,然后用参数device=0 。这样就可以在 支持CUDA 的GPU上运行模型,其中从零开始的每个 id 都映射到一个 CUDA 设备,值 -1 是 CPU。
classifier = pipeline("sentiment-analysis", device=0)
%time results = classifier(dataset.data["sentence"].to_pylist()[:500])

预测 500 句只用了 3.1 秒,平均每秒 161 句,速度提高了大约 9 倍!
Metrics
如果想在SST2数据集上测试分类器的效果怎么办?应该使用哪个指标?在 Hugging Face 中,metrics 和 datasets 是配对在一起的。所以可以使用与 load_dataset 函数相同的参数调用 load_metric 函数。
对于 SST2 数据集,指标是准确度(Accuracy)。可以使用以下代码直接通过metric获得指标值。
metric = datasets.load_metric("glue", "sst2")
n_samples = 500
X = dataset.data["sentence"].to_pylist()[:n_samples]
y = dataset.data["label"].to_pylist()[:n_samples]
results = classifier(X)
predictions = [0 if res["label"] == "NEGATIVE" else 1 for res in results]
print(metric.compute(predictions=predictions, references=y))

AutoClasses
pipeline在底层是由AutoModel和AutoTokenizer类来实现的。AutoClass(即像 AutoModel 和 AutoTokenizer 这样的通用类)是加载模型的快捷方式,它可以从其名称或路径中自动检索预训练模型。在使用时只需要为任务选择合适的AutoModel并使用AutoTokenizer为其关联的分词器:在上面的示例中是对文本进行分类,因此正确的AutoModel是AutoModelForSequenceClassification。
下面展示如何使用AutoModelForSequenceClassification 和 AutoTokenizer 来实现与上面Pipeline相同的功能:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)

这里使用 AutoTokenizer 创建一个分词器对象,并使用 AutoModelForSequenceClassification 创建一个模型对象。只需要传递模型的名称,剩下的事情都会自动完成。
接下来展示如何使用分词器对句子进行分词。tokenizer 输出是一个字典,由 input_ids(即在输入句子中检测到的每个 token 的 id,取自 tokenizer 词汇表)、token_type_ids(用于需要两个文本进行预测的模型中,我们现在可以忽略它们)组成的字典, 和 attention_mask(显示在标记化期间发生填充的位置)。
encoding = tokenizer(["Hello!", "How are you?"], padding=True,
truncation=True, max_length=512, return_tensors="pt")
print(encoding)

然后将标记完的句子传递给模型,模型负责输出预测。这个特定的模型输出五个分数,其中每个分数是human review得分的概率,因为分数从 1 到 5。
outputs = model(**encoding)
print(outputs)

该模型在logits属性中输出最终结果。将softmax函数应用于logits可以获得每个标签的概率。
from torch import nn
pt_predictions = nn.functional.softmax(outputs.logits, dim=-1)
print(pt_predictions)
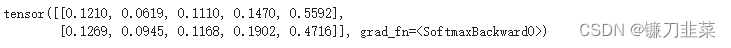
在本地保存和加载模型
最后,展示如何在本地保存模型。这可以使用分词器和模型的save_pretrained函数来完成。
pt_save_directory = "./model"
tokenizer.save_pretrained(pt_save_directory)
model.save_pretrained(pt_save_directory)
如果要加载之前保存的模型,可以使用AutoModel 类的 from_pretrained 函数加载它。
model = AutoModelForSequenceClassification.from_pretrained("./model")
结论
在本文中介绍了Hugging Face 库的主要类和函数。包括transformers 的datasets库,以及如何使用Pipeline在几行代码中加载模型,并让这些代码在 CPU 或 GPU 上运行,还介绍了如何直接从库中加载基准数据集以及如何计算指标。最后还演示了如何使用最重要的两个类 AutoModel 和 AutoTokenizer和如何在本地保存和加载模型,通过以上的介绍已经可以使用Hugging Face库开始NLP之旅了。


















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











