







 超级会员免费看
超级会员免费看
 Performer是一种Transformer架构,通过低秩近似和正交随机特征,将自注意力机制的计算复杂度从O(n²)降至O(n),适合处理长序列。该模型使用Fast Attention和Orthogonal Random Features提高效率,同时保持性能,适用于自然语言处理等领域的应用。
Performer是一种Transformer架构,通过低秩近似和正交随机特征,将自注意力机制的计算复杂度从O(n²)降至O(n),适合处理长序列。该模型使用Fast Attention和Orthogonal Random Features提高效率,同时保持性能,适用于自然语言处理等领域的应用。
语言模型Performer:一种基于Transformer架构的通用注意力框架
Performer是一种用于高效处理自注意力机制(Self-Attention)的神经网络架构。自注意力机制在许多自然语言处理和计算机视觉任务中取得了出色的成绩,但由于其计算复杂度与序列长度的平方成正比,因此在处理长序列时存在问题。为了解决这些问题,Google AI引入了Performer,这是一种 具有线性扩展性的Transformer架构,其注意机制具有线性扩展性。该框架是通过
Fast Attention Via Positive Orthogonal Random Features(
FAVOR+)算法实现的,该算法提供了可扩展的、低方差和无偏估计,可以表达由随机特征图分解(特别是常规softmax-attention)表示的注意机制。这种映射有助于保持线性的空间和时间复杂度。
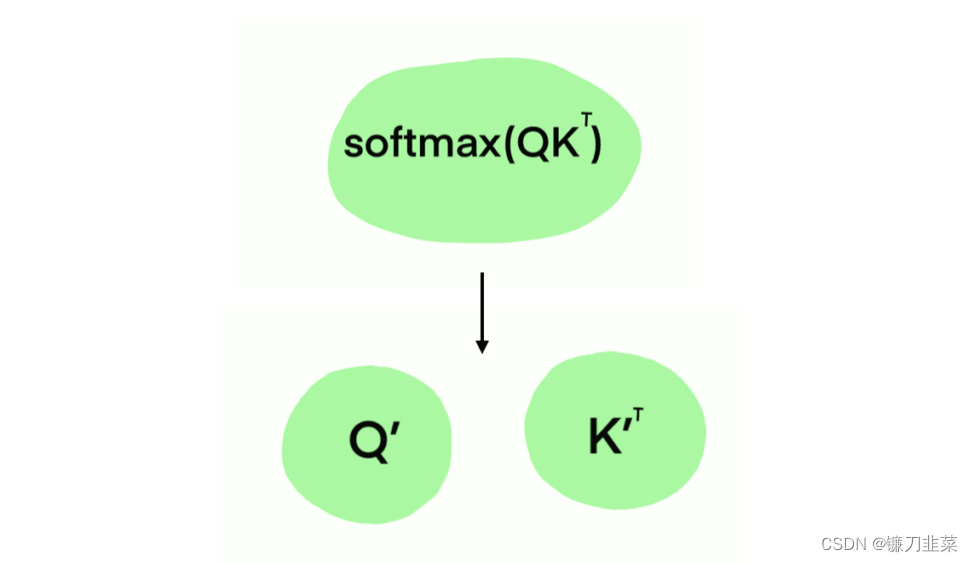
Performer的核心思想是采用低秩近似来替代传统的完全连接的自注意力矩阵,从而减少计算复杂度。具体来说,Performer使用了以下几种关键技巧:
- Fas

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1867
1867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











