






Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Introduction
目前主流的两种演示方式:遥操作和人类演示,都不是充分有效的演示收集方式,前者对硬件和操作人员来说具有较高的成本,后者对机器人表现出很大的具身差距。
使用传感器化的手持式夹持器作为数据收集接口成为一种很有前途的中地替代方案——保持直观和灵活的同时最小化实施差距,虽然理论上用户可以通过这些手持设备收集任何动作,但其中大部分数据无法传输到有效的机器人策略中。尽管在数以百计的环境中实现了令人印象深刻的视觉多样性,但收集的动作仅限于简单的抓取或准静态的拾取和放置,缺乏动作多样性。
阻碍动作迁移的原因
- 没有充分的上下文信息:摄像机与被操作物体的接近往往会导致严重的遮挡,为动作规划提供不充分的视觉上下文。
- 动作表征不精确:大多数手持设备依靠单目运动产生的结构SfM恢复机器人动作,由于尺度模糊、运动模糊或纹理不足,这样的方法往往难以恢复精确的全局动作,限制了系统所能执行任务的精度。
- 延迟差异:在数据收集过程中,无延迟地进行观察和动作记录。在实际推理过程中,系统内部会产生各种各种延迟源,没有意识到这些延迟差异的策略将遇到分布外的输入,进而产生不同步的动作。对于快速、动态的动作影响由为突出。
- 策略表示不足:过去的工作通常使用MSE作为简单的策略表示,无法捕捉人类数据中固有的复杂多模态动作分布的能力。
本文的改进之处
- 使用鱼眼镜头来增加视野和视觉上下文,并在夹持器上添加侧镜,以提供隐式的立体观测,结合GoPro内置的IMU传感器时,可以实现快速运动下的鲁棒跟踪。
- 使用推理时间延迟匹配来处理不同的传感器观测和执行延迟,使用相对轨迹作为动作表示,以消除对精确全局动作的需求,最后,用扩散模型对多模态动作分布进行建模。
最后构成Universal Manipulation Interface (UMI)系统框架,证明了UMI能够通过只改变每个任务的训练数据来实现包括动态、双手、精确和长时程动作的各种操作任务,此外,当使用不同的人类演示进行训练时,最终的策略对新环境和新对象表现出零样本泛化能力,在非分布测试中取得了显著的成功率。

Related Work
任何数据驱动的机器人系统的一个关键使能因素是数据本身。
遥操作机器人数据
行为克隆利用遥操作机器人演示,因其具有直接可转移性而脱颖而出。以前的方法使用3D空间鼠标,VR或AR控制器,智能手机和触觉设备等接口进行遥操作。这些方法要么非常昂贵,要么由于高延迟和缺乏用户直观性而难以使用。
虽然最近的领航跟随设备的进步,如ALOHA和GELLO提供了直观和低成本的接口,但它们在数据收集期间对真实机器人的依赖限制了系统可以访问无标注数据采集的环境类`型和数量,外骨骼(一种方法)去除了数据收集时对真实机器人的依赖,但需要使用遥操作的真实机器人数据进行部署的微调。
相比之下,UMI在数据收集过程中消除了对物理机器人的需求,并为野外机器人教学提供了更便携的接口,提供数据和策略,可转移到不同的机器人实施方案。
来自人类视频的视觉演示
有一个独特的工作,致力于从in-the-wild视频数据(没有针对模仿学习定制化收集的数据)中进行政策学习。先前的工作学习了任务代价函数,可供性函数,稠密物体描述符,动作对应和预训练的视觉表示。
这种方法面临三大挑战:
- 大多数视频演示缺乏明确的行动信息,这对于学习可推广的政策至关重要。为了从被动的人体视频中推断动作数据,先前的工作采用手部姿态检测器,或者结合人体视频和域内遥操作机器人数据来预测动作。
- 人与机器人之间明显的具身性差距阻碍了动作迁移。弥补这一差距的努力包括学习人与机器人的动作映射,手部姿态重定向或提取具身-不可知的关键点。尽管有这些尝试,但固有的具身性差异仍然使得从人类视频到物理机器人的政策转移变得复杂。
- 由具身性差距诱导的固有观测差距引入了不可避免的训练/推理时间观测数据之间的不匹配,加剧了由此产生的政策的可转移性,尽管在将示范观测与机器人观测对齐方面做出了努力。
用于准静态动作的手持抓手
手持式夹持器最大限度地减少了操作数据收集中的观测实施差异,然而,从这些设备中准确和鲁棒地提取6DoF末端执行器位姿仍然具有挑战性,阻碍了从这些数据中学习到的机器人策略在细粒度操作任务上的部署。
之前的工作试图通过各种方法来解决这个问题:SfM具有尺度歧义;RGB-D融合需要昂贵的传感器和机载计算机;外部运动跟踪仅限于实验室设置。
以上的方法由于EE跟踪精度和鲁棒性较低,受限于准静态动作,往往需要笨重的机载计算机或外部运动捕捉系统,降低了其数据采集的便携性。
Dobb-E提出了一种安装在iPhone上的"触手抓取"工具,用于收集拉伸机器人的单臂演示。然而,Dobb-E只展示了针对准静态任务的策略部署,需要针对具体环境进行策略微调。
Method
UMI是考虑以下目标的情况下设置的:
- 便携:手持式UMI夹持器可以被带到任何环境中,并以接近零的安装时间开始数据采集。
- 高效:具有超越拾放的捕捉和传递自然和复杂的人类操纵技能的能力。
- 适配:收集的数据应该包含足够的信息来学习有效的机器人策略,并且包含最少的特定于实施的信息,以降低策略转移的成本。
- 可重复性:模型适用于不同的机器人手臂。
演示接口设置

UMI的数据采集硬件采用触发器激活的手持式3D打印软指平行夹爪的形式,安装有GoPro相机作为唯一的传感器和记录设备,通过联合惯性-视觉的SLAM算法(
<
=
1
c
m
,
4
。
<=1cm,4^。
<=1cm,4。)计算相机相对位姿配合特制的观测视图作为观测输入。
- 用于捕捉上下文信息的鱼眼摄像头:使用一个155度的鱼眼镜头附着在手腕上的GoPro相机上增加视觉广度,视图中心部分区域不会扭曲。
- 用于隐式立体视觉信息捕捉的侧镜:单目视图具有尺度不确定性,只能在运动中形成对尺度(深度)的感知,在相机外围视图中放置了一对物理镜,由此构建了左右两侧的虚拟视图,用于从多视图中(隐式)重建尺度信息。

- IMU感知跟踪:利用GoPro内置的将IMU数据(加速度计和陀螺仪)记录到标准mp4视频文件中的能力来捕获具有绝对尺度的快速运动,即使由于运动模糊或缺乏视觉特征而导致视觉跟踪失败,也能在短时间内保持跟踪,这使得UMI可以捕获和部署高速动态动作(如投掷)。
- 连续夹爪控制:在某些动态任务(投掷)中,夹爪释放的时间很重要,而二进制开闭动作在物体宽度不同时无法满足精度要求。通过基准标记点(图2左)连续跟踪手指宽度(演示设备没有标准执行器那样的宽度检测传感器)。
- 基于运动学的数据i滤波:当机器人的基座位置和运动学已知时,通过SLAM恢复的绝对末端位姿允许在演示数据上进行运动学和动力学可行性滤波。在过滤后的数据集上进行训练,确保策略符合特定的运动学约束。
策略接口设置
主要目标:策略对底层机器人硬件平台不敏感
策略执行的本质在于期望时间戳达到期望位姿
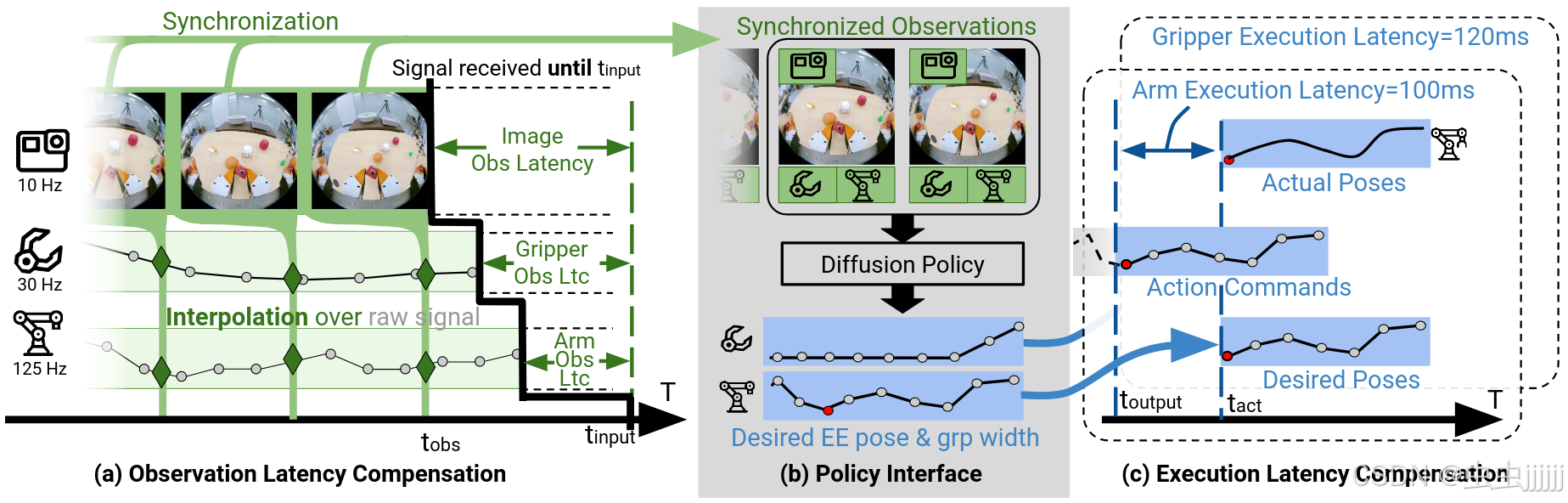
Pipeline
利用采集到的演示数据,使用Diffusion Policy训练一个视觉运动策略,该策略接受一个同步观测序列( RGB图像、末端执行器位姿、连续夹爪宽度),并产生一个动作序列(末端执行器位姿和夹持器宽度)。
关键挑战
- 硬件特有的延迟:各种硬件(流式摄像机、机器人控制器、工业抓手)的延迟是高度可变的,从单个数字到数百毫秒不等。而UMI夹持器捕获的所有信息流相对于图像观测具有零延迟。
- 具身特定的传感数据:末端执行器位姿是相对于特定机械臂和底座的,如何将策略输出与特定机械臂用一种可推广的方式联合。
具体实现
推理-时间延迟匹配
训练和测试之间的时序不匹配会导致在需要快速移动和精确手眼协调的动态操作任务上的性能大幅下降。
- 观测延迟匹配(演示数据处理):首先将RGB相机的观测值按时间降采样到期望的频率(机器人策略执行流硬件的最低频率),然后利用每张图像的捕获时间戳对手爪和机器人本体感觉流进行线性插值,在双手系统中,我们通过寻找最近邻帧来软同步两个相机。
- 动作延迟匹配(执行过程处理):机器人策略执行只能跟踪期望的位姿序列,执行延迟因机器人硬件的不同而不同,这会导致策略与实际执行的不一致性,为了确保机器人和手爪在期望的时间到达期望的位姿,需要提前发送命令来补偿执行延迟。具体来说,从最新观测中预测期望未来动作序列,抛弃最大延迟的前几个期望动作,只执行最大延迟时间戳后的期望动作。
相对末端执行器位姿
避免对具体化/部署特定坐标的依赖。
- 相对EE轨迹作为动作表示:本文实验证明了预测期望相对位姿,再利用当前EE位姿将其还原到基座上作为动作表示具有更稳定的性能,在执行过程中移动基座不会影响任务性能。相对位姿的窗口设置为2,如果参考的坐标系时间步上距离较远会有较大的累计误差。
- 相对夹爪之间的感知: 对于双手操作,需要引入夹持器间的相对位姿,否则当两个相机之间的视觉重叠度较小时,夹持器间位姿感知的影响特别大。本文通过视频重构场景地图,将夹持器位姿重新定位在同一地图上获取相同的坐标系。
Evaluation
从三个方向评估算法性能:操作能力、泛化性能、数据采集效率。
CAPABILITY EXPERIMENTS
任务设置

- 杯子放置:2名演示者收集305次演示,测试20次。
- 动态投掷:280次演示,测试120次。
- 折叠衣服:250次演示,测试20次。
- 洗碗操作:258次演示,测试20次。
实验结果
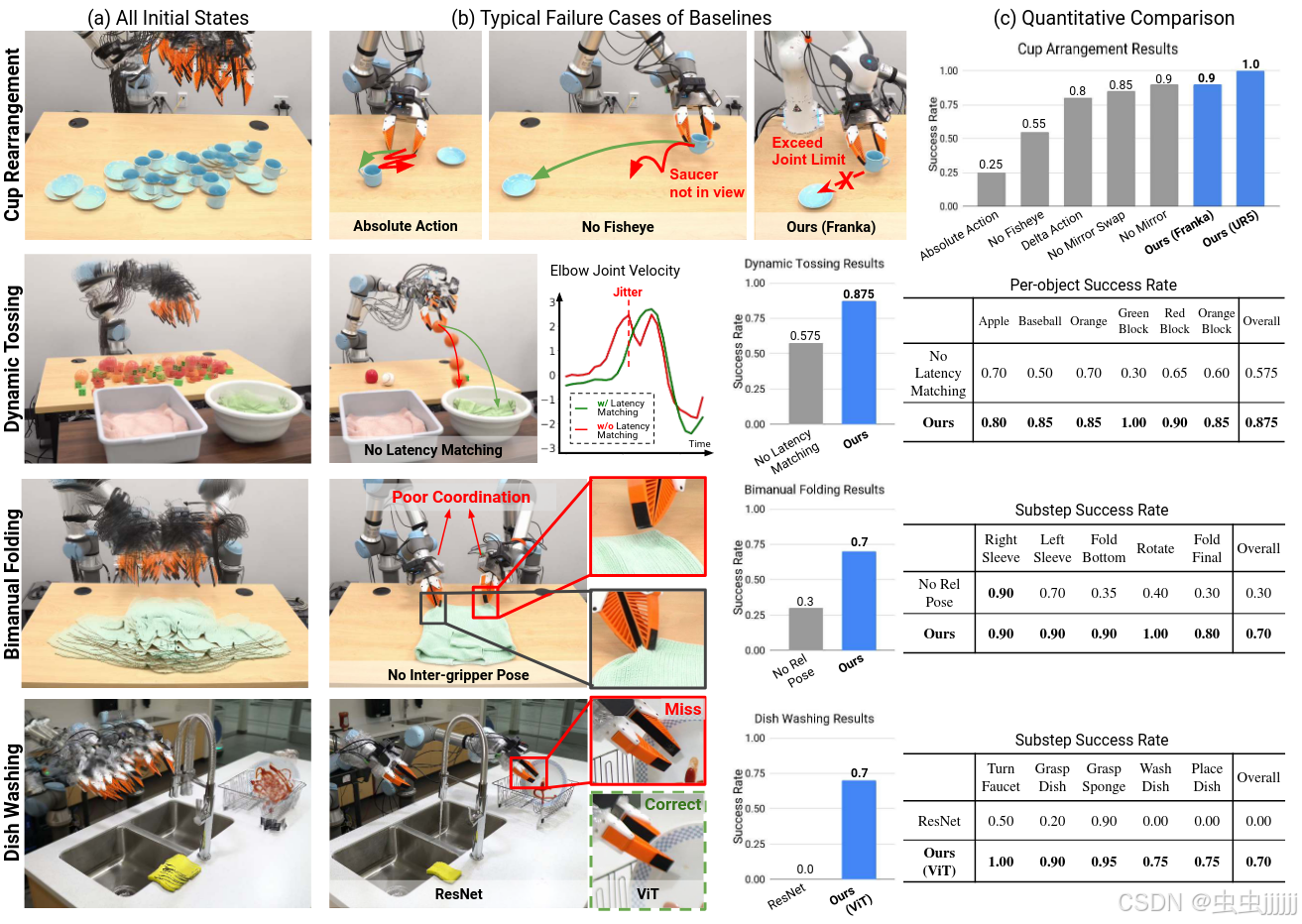
IN-THE-WILD GENERALIZATION EXPERIMENTS
扩大数据采集测试模型的可泛化性能
先前的行为克隆工作通常只在与数据收集相同的环境中进行评估,通常受限于它们无法收集足够多样化的数据集以允许泛化。
通过不依赖与真实机器人的遥操作,UMI可以在任何环境中实现低成本的数据采集。
任务设置
在12个人小时内,3名演示者在30个不同的物理地点,包括家庭、办公室、餐馆和室外环境,收集了1400次关于杯子安排任务的演示。演示涉及15个不同颜色、形状(圆柱形和锥形)、材质(陶瓷、玻璃、金属)的浓缩咖啡杯。为了保证模型的容量,我们在CLIP预训练的ViT-L/14的基础上进一步增加了视觉编码器。我们在两个看不见的环境中评估了UMI政策。

在未知对象上反而成功率更高?实验次数不够多。
鲁棒性测试

演示吞吐量比较

Limitation
- 下游部署机器人的运动学极限未知,因此依赖对数据进行筛选,以确保所得政策的动态可行性,如何从从有效但硬件不可行的动作中迁移技能。
- 基于SLAM的动作恢复系统继承了视觉SLAM对环境中足够纹理的要求。
- 使用UMI抓手采集数据的效率仍然低于人手演示,主要是由于夹持器的重量和笨重,另一部分是由于与人手相比自由度的减少。


















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











