







 本文围绕自动驾驶技术,介绍了Apollo平台中的感知融合方法,重点讲解了卡尔曼滤波在融合中的应用。通过实例展示了Lidar和Radar数据融合的过程,并分享了学习自动驾驶的资源和交流机会。
本文围绕自动驾驶技术,介绍了Apollo平台中的感知融合方法,重点讲解了卡尔曼滤波在融合中的应用。通过实例展示了Lidar和Radar数据融合的过程,并分享了学习自动驾驶的资源和交流机会。
#Apollo开发者#
学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往:
《自动驾驶新人之旅》免费课程—> 传送门
《Apollo Beta宣讲和线下沙龙》免费报名—>传送门
文章目录
前言
感知融合
感知融合利用各个传感器相辅相成,可以提高感知性能,减少跟踪误差,对预测结果更加确信。
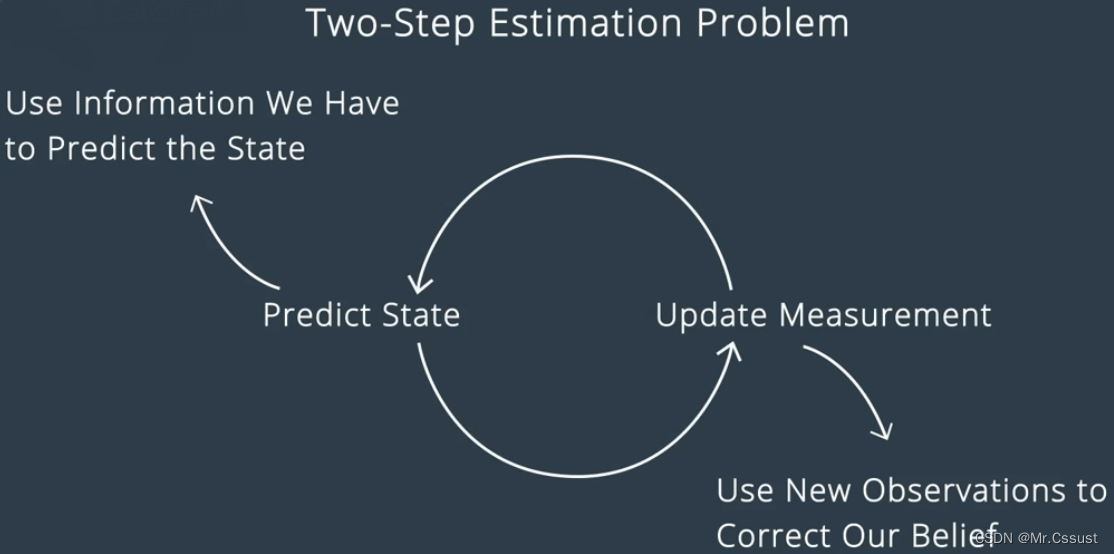
卡尔曼滤波
感知融合的一个基本算法是卡尔曼滤波,即模型预测和测量更新的无限循环,如下图所示:
融合策略
1、同步融合:同时更新来自不同传感器的测量结果。
2、异步融合:逐个更新传感器的测量结果。
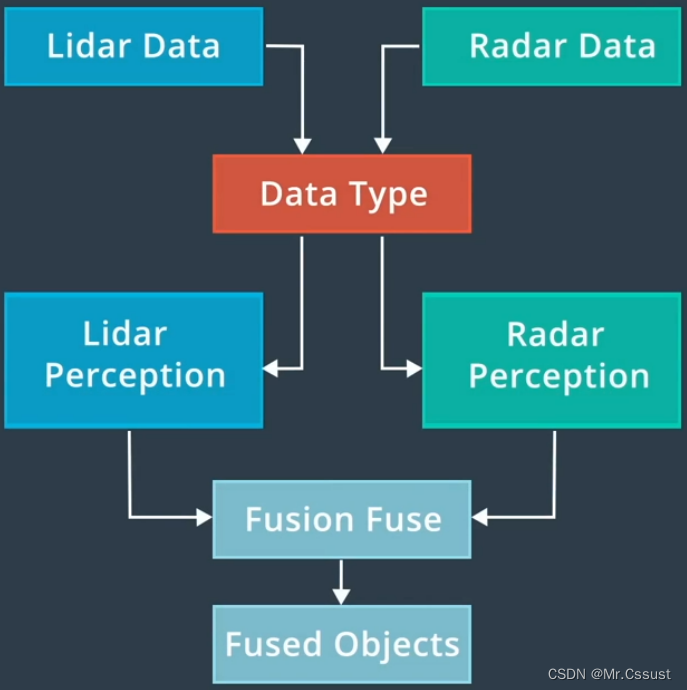
实例
Lidar和Radar两种传感器检测到的目标位置数据,如下图所示:

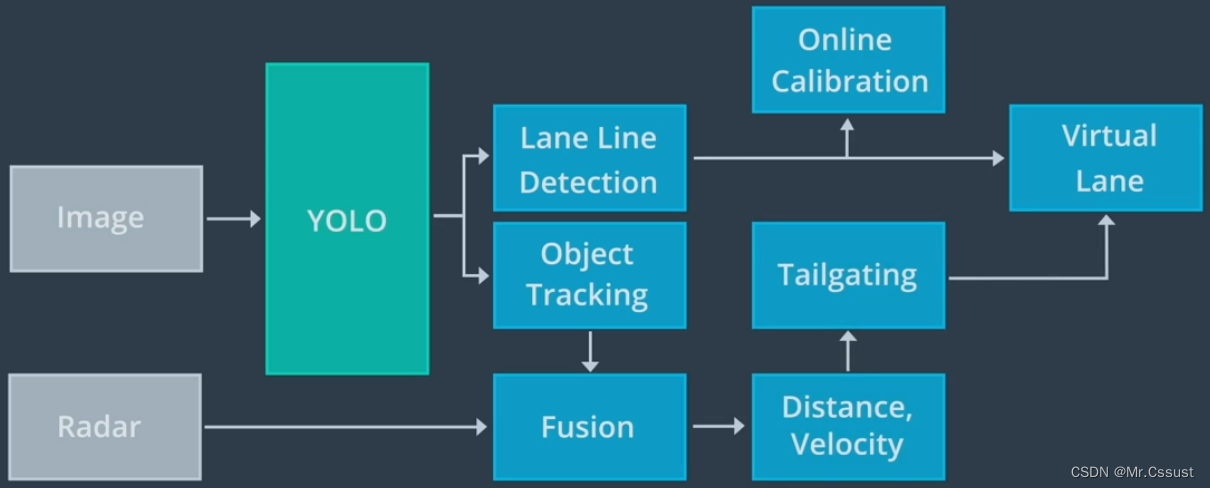
Tips
Apollo的车道和目标感知框架:
总结
以上就是本人在学习自动驾驶时,对所学课程的一些梳理和总结。后续还会分享另更多自动驾驶相关知识,欢迎评论区留言、点赞、收藏和关注,这些鼓励和支持都将成文本人持续分享的动力。
另外,如果有同在小伙伴,也正在学习或打算学习自动驾驶时,可以和我一同抱团学习,交流技术。
版权声明,原创文章,转载和引用请注明出处和链接,侵权必究!
文中部分图片来源自网络,若有侵权,联系立删。


















 2553
2553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











