






点击下方卡片,关注“具身智能之心”公众号
在机器人领域,双手协同操作具有重要意义,但也面临诸多困难。双手操作需要高维连续控制以确保任务成功和操作精度,同时双手还需协作完成任务,避免相互干扰。机器人需要同时学习协调双手的运动,随着任务维度增加、非平稳动力学以及不对称协作等因素的影响,双手协同操作的难度进一步增大。此外,获取大量且有效的双手协同操作训练数据十分困难。现有的数据集往往侧重于单臂操作或简单的双手操作场景,无法满足复杂的双手协同操作研究需求,这导致模型在学习过程中缺乏足够的样本,难以学习到有效的双手协同策略。
同时,手指灵巧操作同样是机器人面临的挑战。手指的操作涉及到多个自由度的控制,每个手指关节都需要精确控制,以实现如抓取、旋转、放置等精细动作。传统的控制方法往往依赖于特定的假设,在面对复杂和不确定的环境时,难以实现有效的手指灵巧操作。
本期具身智能之心带来了几篇研究双臂协同操作的文章。学者们致力于改进模型架构和硬件系统使其更适应精细操作,引入剪切形变缩小模拟到现实的差距,引入重力补偿机制实现更平滑、可预测的运动,用统一的物理可解释空间将不同机器人的动作空间统一,设计异构的手指、关节智能体,模拟人类手指精细操作……
更多具身智能内容,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
Aloha:使用低成本硬件学习细粒度的双手操作
https://github.com/tonyzhaozh/aloha
https://arxiv.org/pdf/2304.13705
精细操作任务对机器人来说很难,通常需要高端机器人、精确传感器或仔细校准,成本高且设置困难。本文旨在探索学习能否使低成本、不精确的硬件执行这些任务。本文介绍了一种低成本学习精细双手操作的系统,包括遥操作系统和新型模仿学习算法ACT。
ALOHA遥操作系统具有低成本的优点,整个系统在大多数机器人实验室的预算范围内,约20k美元,与单个工业机械臂价格相当,由两个ViperX 6 - DoF机械臂和一些3D打印部件等组成。它可应用于多种精细操作任务,如穿拉链、插内存、玩乒乓球等。此外,ALOHA对用户友好,由于采用直接关节空间映射,操作体验好,如设计了3D打印的“手柄和剪刀”机制和橡胶带负载平衡机制等。并且,ALOHA易搭建、易维修,仅使用现成的机器人和少量3D打印部件,研究人员可在不到2小时内组装完成。
ACT模仿学习算法能够有效处理复合误差,通过动作分块和时间集成减少任务的有效范围,缓解模仿学习中的复合误差问题,提高了在精细操作任务中的性能。将策略训练为条件变分自编码器(CVAE),能够更好地对有噪声的人类演示数据进行建模,准确预测动作序列。实验证明在多个模拟和真实世界的精细操作任务中显著优于之前的模仿学习算法。
但ALOHA系统也有局限性,比如ALOHA难以完成需要双手多指、大力气或指甲操作的任务,如打开儿童防护药瓶、举起重物、打开贴紧的胶带边缘等。此外,ACT在解开糖果包装和打开平放在桌上的小拉链袋两个任务上学习困难,可能由于感知困难和数据不足。

ALOHA 2:一种用于双手遥操作的增强型低成本硬件
https://arxiv.org/abs/2405.02292
本文介绍了ALOHA 2,一种增强版的低成本双手遥操作硬件,相比原始设计具有更高的性能、更好的人体工程学和更强的鲁棒性。具体硬件组成为由两个ViperX 6 - DoF机械臂(“从动臂”)和两个较小的WidowX臂(“主动臂”)组成的双手平行夹爪工作单元,搭配多个摄像头,安装在桌子上,有铝制笼子和重力补偿系统。相对于先前版本,作者为主动臂和从动臂设计新的低摩擦轨道,升级手指上的胶带材料,提高耐用性和抓取能力。并且,使用现成组件创建被动重力补偿机制,提高耐用性。此外,作者简化了工作单元周围的框架,保持相机安装点的刚性,为人类 - 机器人协作和道具留出空间。摄像头使用更小的Intel RealSense D405摄像头和定制3D打印相机支架,减少从动臂的占用空间,增加视野、提供深度、具有全局快门并允许更多定制。
实验表明,以上改进十分有效。在夹爪比较实验中,6名用户使用原始ALOHA剪刀式设计、线性轨道设计和触发式设计操作ALOHA 2解开糖果,线性轨道设计受到大多数用户好评。在重力补偿实验中,6名用户分别使用被动硬件重力补偿系统和基于软件的主动系统进行10分钟的插入形状任务,结果表明被动系统平均性能更好,且具有更平滑、可预测的运动,以及更安全和防止手臂过度旋转的优点。此外,重新设计的框架简化了设计,增加了空间,便于收集人类 - 机器人交互数据和放置更大的道具。并且,升级后的摄像头减少了碰撞状态,提高了某些精细操作任务的遥操作性能。

DiT - Block Policy: 机器人Diffusion Transformer的组成要素
https://arxiv.org/abs/2410.10088
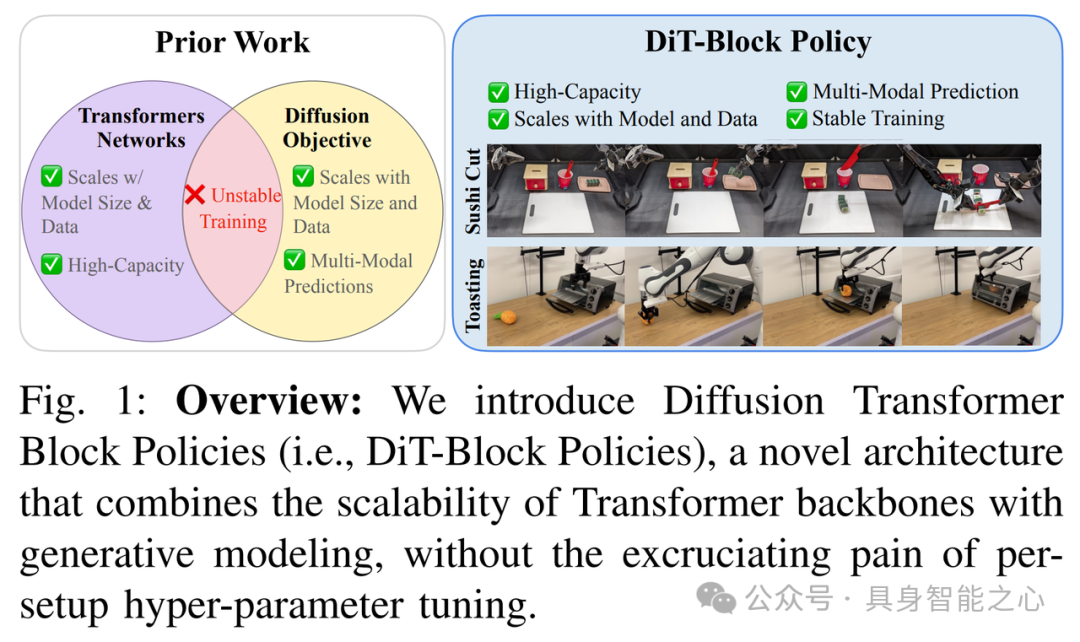
本文提出了 DiT - Block Policy,在机器人扩散 Transformer 策略学习方面有诸多创新。首先,受Peebles等人启发,提出添加自适应层归一化(adaLN)块来稳定训练扩散 Transformer 策略层,在包含超过 1000 个决策的长时域、灵巧的现实世界操作任务中,性能提高了 30% 以上。其次,作者比较了多种对多个相机观察进行标记化的方法,发现相对简单的 ResNet 图像标记器 + Transformer 策略组合,相比竞争策略可提供 40% 以上的性能提升。此外,采用多种方式组合来自多个传感器的信息,如使用ResNet - 26编码器分别处理相机图像,通过FiLM层将文本目标融入视觉编码器,对本体感受输入进行正则化处理等,这些方法对长周期、双手动任务性能提升约40%。
相对于前人的研究,本文在双手 ALOHA 机器人上执行一系列任务,如 Pick Place(拾取放置)、Pen Uncap(拔笔帽)、Sushi Cut(切寿司)等,与 SOTA 基线相比,平均性能提升约 20%。并且,能够更稳定地学习扩散策略 Transformer,在所有三个任务上都能提供可靠的性能,而其他基线方法在某些任务上表现不佳,例如 ACT 在 Pen Uncap 任务中表现挣扎,D.P. U - Net 在 Sushi Cut 任务中表现不佳。此外,还在单臂 Franka 机器人上进行测试,执行 Toasting(烤面包)和 Wiping(擦拭)等任务,结果表明 DiT - Block Policy 再次提供了 SOTA 性能,平均比 ACT 高出 20%,比 D.P. U - Net 高出 35%,显示出对新机器人形态和控制空间的良好泛化能力。
DiT - Block Policy 架构将性能最佳的组件集成到统一框架中,在双手 ALOHA 机器人和单臂 DROID Franka 设置上均实现了最先进的性能。
Mobile ALOHA: 通过低成本全身遥操作学习双手移动操作
https://arxiv.org/abs/2401.02117
文章提出Mobile ALOHA,一种低成本全身遥操作系统,由敏捷X追踪AGV作为移动底座和ALOHA机械臂组成,总预算32k美元,相比同类产品更经济实惠,且具备移动、稳定、全身遥操作和无缆等特性。采用协同训练方法,利用静态ALOHA数据集和Mobile ALOHA数据集共同训练,提高了模仿学习在移动操作任务上的性能和数据效率,在多种任务上取得良好效果。
Mobile ALOHA具有多模态处理能力。为了将多传感器信息融合,系统配备多个摄像头和传感器,能同时处理视觉和本体感受信息,用于策略学习和任务执行。此外,它能处理复杂任务场景,能执行包括家务、烹饪、人机交互等多种复杂任务,涉及双手协调、移动操作和精确控制等多种要求。Mobile ALOHA与多种算法兼容,包括ACT、Diffusion Policy、VINN等多种模仿学习方法兼容,并通过协同训练提高性能。在不同任务和场景下具有泛化能力,通过对7种任务的实验验证了其在不同操作要求下的有效性。

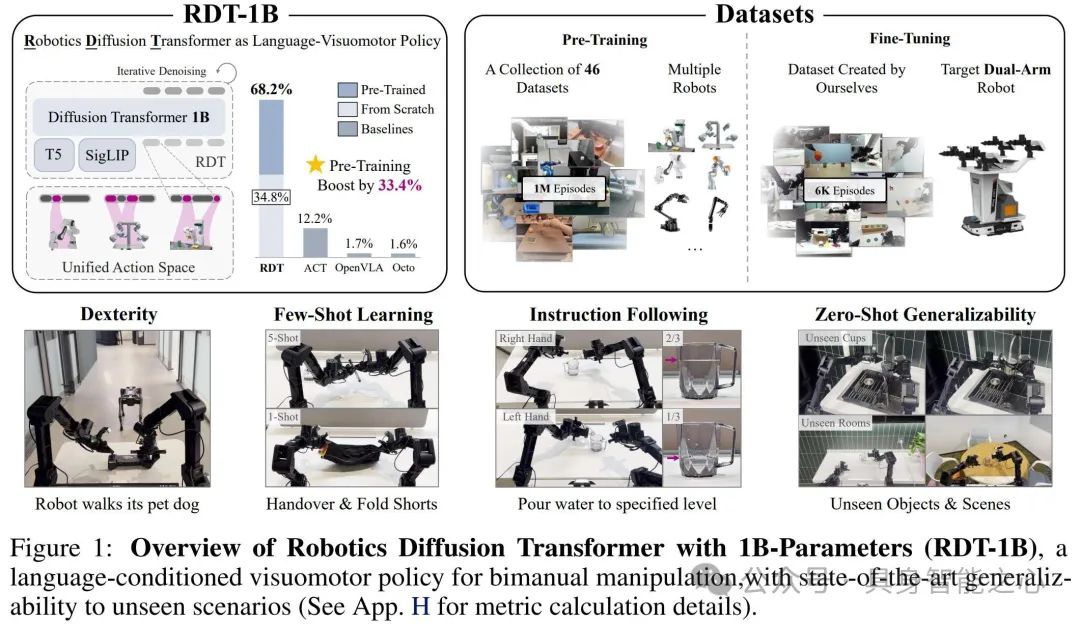
RDT - 1B:一种用于双手操作的扩散基础模型
https://arxiv.org/abs/2410.07864
双手操作对机器人完成现实任务至关重要,但开发基础模型极具挑战,包括双臂动作的多模态分布和训练数据稀缺。当前方法要么依赖特定任务原语,要么局限于小规模模型、数据和简单任务,泛化能力有限。这篇文章介绍了用于双手操作的机器人扩散基础模型RDT。该模型解决了协调双臂机器人的数据稀缺和操作复杂性问题,展现出对未见过的物体和场景的零次学习泛化能力,以及在少量样本学习和指令遵循方面的优势。
文章提出的RDT模型采用扩散模型对连续条件分布进行建模,以处理多模态问题,并针对机器人数据特性进行了改进。模型将低维输入、图像输入和语言输入编码到统一的潜在空间,同时对不同输入进行随机掩码以防止模型过度依赖特定输入。并且基于Transformer的 f_theta 网络进行了QKNorm和RMSNorm、MLP解码器、交替条件注入等关键修改。
作者还提出物理可解释的统一动作空间,将不同机器人的动作空间统一。该空间的每个维度都有明确的物理意义,通过将机器人的原始动作空间映射到统一空间,促进模型学习通用物理知识,同时保留原始动作的物理意义。
Bi-Touch:基于从仿真到现实的深度强化学习的双手触觉操作
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10184426
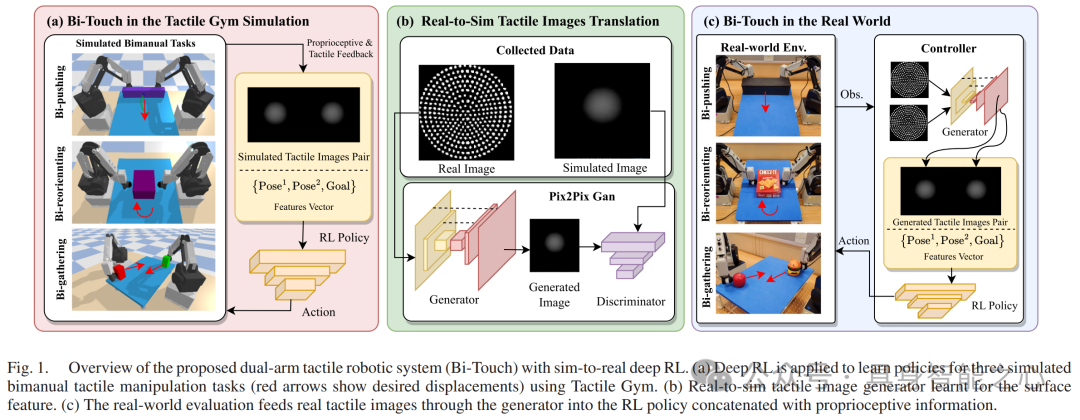
双手操作在处理大物体或耦合物体时有更好的机动性和灵活性,但设计有效的控制器面临系统集成复杂和硬件成本高的挑战,且触觉传感研究相对较少。现有工作存在未考虑触觉传感、依赖特定运动技能或视觉跟踪系统、缺乏泛化能力等问题。本文介绍了基于模拟到现实深度强化学习的双手触觉操作Bi - Touch系统,该系统在触觉反馈的双手操作任务上展现出有效性和泛化能力。
Bi - Touch系统采用两个Dobot MG400桌面机器人手臂构建低成本双臂触觉机器人系统,通过引入桌子支撑物体,合理配置工作空间。并且,它配备了两个TacTip仿生光学触觉传感器,能感知局部接触特征。模型采用模拟到现实的深度强化学习框架,学习过程包括在模拟环境中训练策略、学习真实到模拟触觉图像的转换模型以及将策略应用到物理系统三个部分。文章针对三个双手触觉操作任务(双推、双重新定向、双收集)进行研究,为每个任务定义动作空间和奖励函数。双推任务目标是移动大物体,双重新定向任务是改变物体角度,双收集任务是将两个物体聚集在一起。
但系统仍具有一定的局限性,如未考虑触觉传感器的剪切变形,未来可进一步改进模拟方法以缩小模拟到现实的差距,并应用于更精细的操作任务
Bi-DexHands:迈向人类水平的双手灵巧操作
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10343126
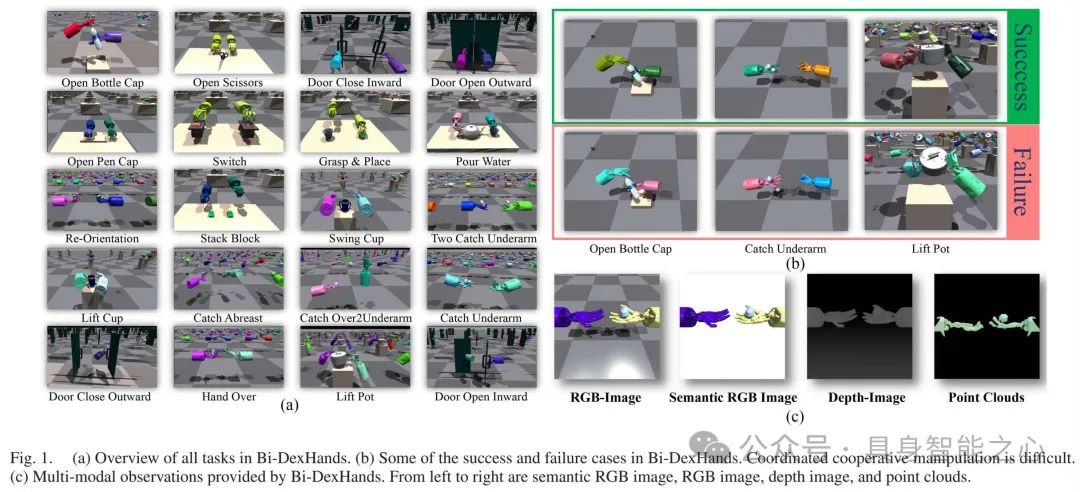
在机器人领域,实现人类水平的灵巧操作仍然是一个关键的未解决问题,特别是双手灵巧操作由于其高自由度和双手协作需求,面临诸多困难。强化学习算法在一些机器人任务中取得了成功,但在处理高维观测和双手协调问题上仍面临挑战,且缺乏专门用于双手灵巧操作任务的高质量模拟器。现有的机器人操作基准测试存在局限性,多数侧重于单臂操作任务,且针对灵巧多指手操作的任务和环境设置不够全面和复杂。
这篇文章提出的Bi - DexHands同时提供单智能体强化学习(Single - Agent RL)、多智能体强化学习(Multi - agent RL,MARL)、离线强化学习(Offline RL)、多任务强化学习(Multi - task RL)和元强化学习(Meta - RL)环境,涵盖多种常见的强化学习算法环境,相比以往的强化学习基准测试更加全面。
此外,Bi - DexHands中的智能体(如关节、手指、手等)是真正异构的,不同于常见的多智能体环境(如SMAC)中智能体可以简单共享参数来解决任务。异构智能体的设计更符合实际机器人操作中不同部件具有不同特性和功能的情况,有助于研究更复杂的双手协作任务。
最后,机器人的Shadow Hand具有24个自由度(DoF),由20对拮抗肌腱驱动,能够模仿人类手部的骨骼结构进行多种灵活和精细的操作。并且在一些任务中,手部的底座不是固定的,策略可以在受限空间内控制底座的位置和方向,利用了手腕的功能,使Shadow Hand更具仿生特性。
参考文献
Learning Fine - Grained Bimanual Manipulation with Low - Cost Hardware , https://arxiv.org/pdf/2304.13705
ALOHA 2: An Enhanced Low-Cost Hardware for Bimanual Teleoperation , https://arxiv.org/abs/2405.02292
The Ingredients for Robotic Diffusion Transformers , https://arxiv.org/abs/2410.10088
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low - Cost Whole - Body Teleoperation , https://arxiv.org/abs/2401.02117
RDT - 1B: A DIFFUSION FOUNDATION MODEL FOR BIMANUAL MANIPULATION , https://arxiv.org/abs/2410.07864
Bi - Touch: Bimanual Tactile Manipulation With Sim - to - Real Deep Reinforcement Learning , https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10184426
Bi-DexHands: Towards Human-Level Bimanual Dexterous Manipulation , https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10343126
“具身智能之心”公众号持续推送具身智能领域热点:
往期 · 推荐
(1)具身多模态基础模型
NVIDIA最新!NVLM:开放级别的多模态大语言模型(视觉语言任务SOTA)
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
CLIP怎么“魔改”?盘点CLIP系列模型泛化能力提升方面的研究
揭秘CNN与Transformer决策机制:设计原则是关键?
VILA:视觉推理能力如何up up?多模态预训练设计有妙招
(2)3D场景理解、分割与交互
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
大模型继续发力!SAM2Point联合SAM2,首次实现任意3D场景,任意Prompt的分割
更丝滑更逼真!模型自主发现与模式自动识别新升级助力三维场景构建与形状合成
进一步向开放识别迈进!3D场景理解与视觉语言模型的融合创新可以这样玩
(3)具身机器人与环境交互
纽约大学最新!SeeDo:通过视觉语言模型将人类演示视频转化为机器人行动计划
CMU最新!SplatSim: 基于3DGS的RGB操作策略零样本Sim2Real迁移
伯克利最新!CrossFormer:一个模型同时控制单臂/双臂/轮式/四足等多类机器人
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
(4)具身仿真×自动驾驶
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集
ECCV 2024 Oral | DVLO:具有双向结构对齐功能的融合网络,助力视觉/激光雷达里程计新突破
(5)权威赛事结果速递
模型与场景的交互性再升级!感知、行为预测以及运动规划在Waymo2024挑战赛中有哪些亮点
效率和精度齐飞!CVPR2024 AIS workshop亮点大盘点
(6)具身智能工具深度测评
巨好用的工具安利!胜过WPS?MinerU 帮你扫清PDF提取
UCLA出品!用于城市空间的具身人工智能模拟平台:MetaUrban
(7)具身智能时事速递
端到端、多模态、LLM如何与具身智能融合?看完这50家公司就明白了
见证历史?高通准备收购英特尔!
万张A100“堆”出来的勇气:一个更极致的中国技术理想主义故事
即将截止!ECCV'24自动驾驶难例场景多模态理解与视频生成挑战赛


















 1793
1793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









