







5.排序引导块设计(basic building block)
前言
在目标检测的激烈竞赛中,YOLO系列始终占据一席之地。今年新发布的YOLOv10,设计团队为了提高效率和准确性,通过对各个组件的全面检查来实现模型架构,最终通过新办法实现了一系列不同模型规模的实时端到端检测器的新家族,即YOLOv10-N / S / M / B / L / X。

YOLOv10-N:用于资源极其有限环境的纳米版本。
YOLOv10-S:兼顾速度和精度的小型版本。
YOLOv10-M:通用中型版本。
YOLOv10-B:平衡型,宽度增加,精度更高。
YOLOv10-L:大型版本,精度更高,计算资源增加。
YOLOv10-X:超大型版本可实现最高精度和性能。
一、模型介绍
YOLOv10是清华大学的研究人员在Ultralytics Python包的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10 在显著降低计算开销的同时实现了最先进的性能。大量实验证明,YOLOv10 在多个模型尺度上实现了卓越的精度-延迟权衡。
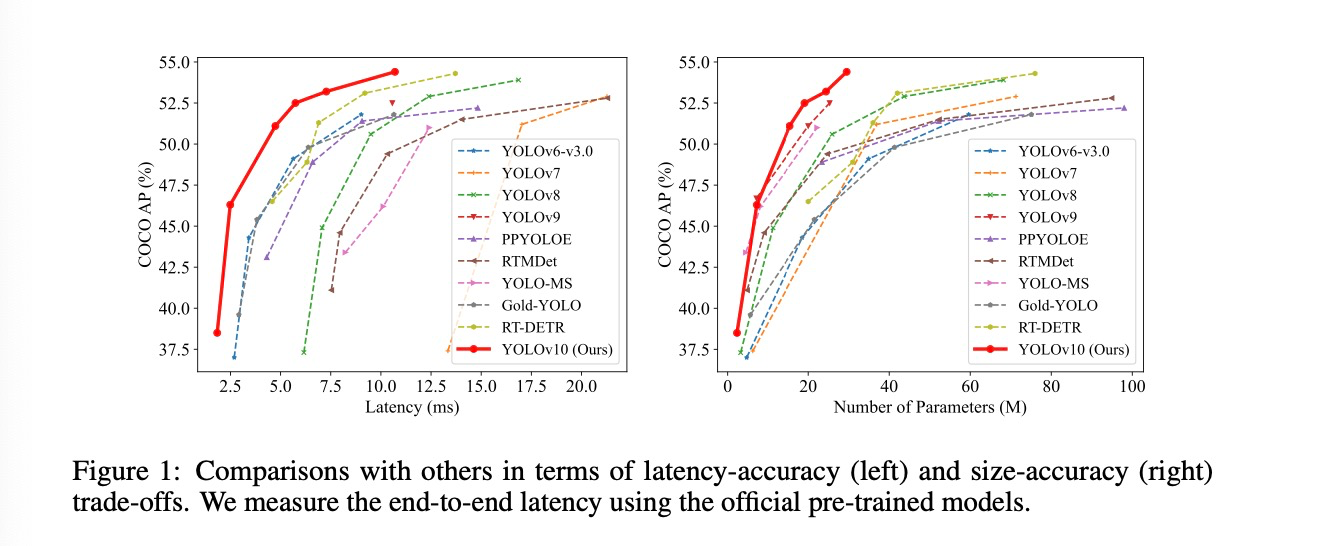
如图所示,YOLOv10 在各种模型规模上都实现了 SOTA 性能和效率。
与RT-DETR相比:YOLOv10-S在COCO上的类似AP下比RT-DETR-R18快1.8倍,同时享受2.8倍的参数和FLOP。
与YOLOv 9-C相比:YOLOv10-B在相同性能下的延迟减少了46%,参数减少了25%。
· YOLOv10论文:https://arxiv.org/abs/2405.14458
· YOLOv10代码:https://github.com/THU-MIG/yolov10
二、网络结构
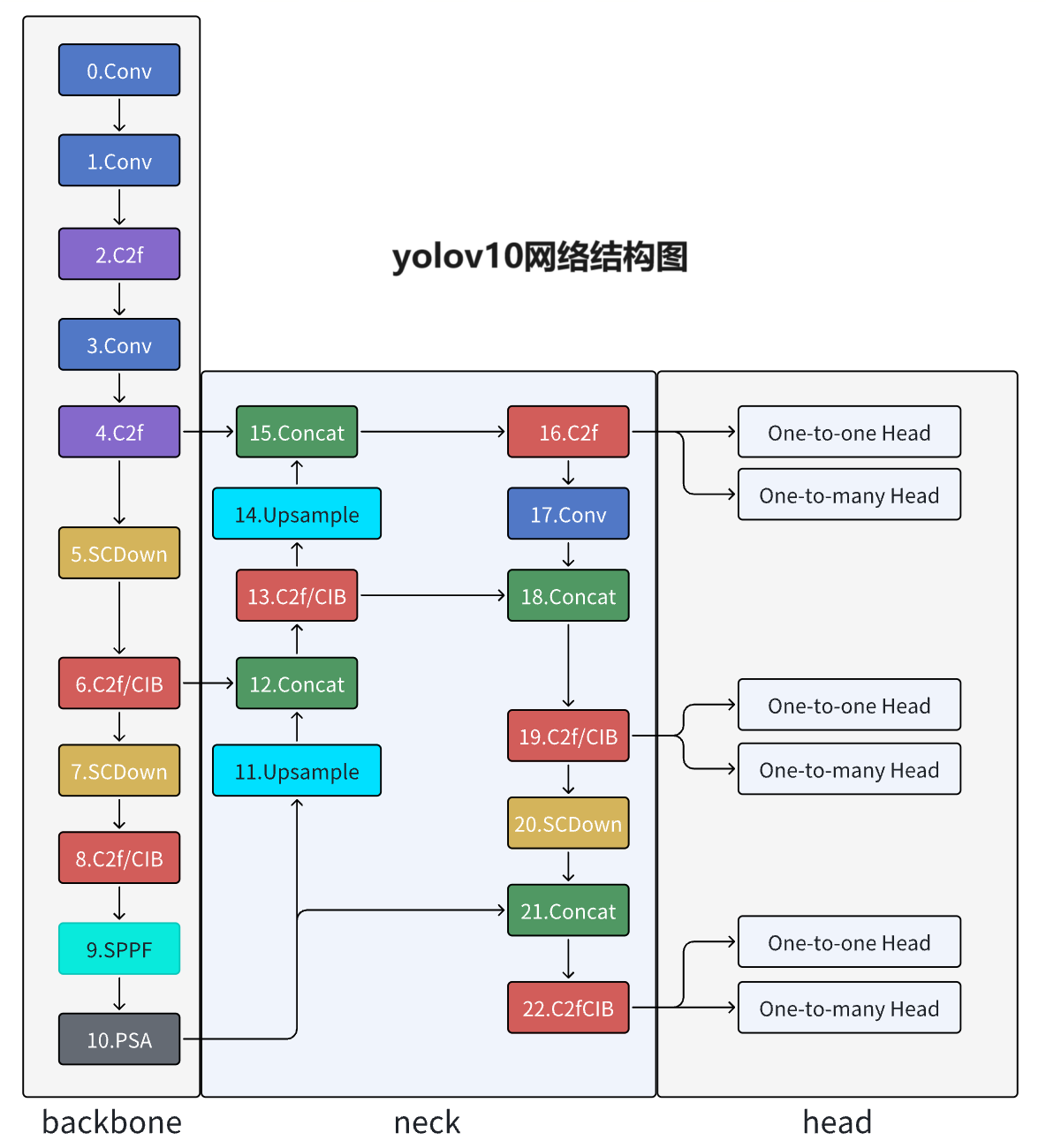
1.主干网络(Backbone)
YOLOv10的主干网络负责特征提取和初步的下采样操作。虽然YOLOv10本身并未对主干网络进行大幅改动,但值得一提的是,华为诺亚提出的全新骨干架构VanillaNet可以作为YOLOv10主干网络的一个潜在改进选项。VanillaNet融合了深度学习极简主义的力量,通过减少复杂操作(如高深度、shortcuts和自注意力)来提升模型的鲁棒性和效率。
2.颈部网络(Neck)
颈部网络(Neck)负责进一步的特征融合和多尺度信息提取。YOLOv10在这一部分继承了YOLOv8的设计思路,并可能采用了一些新的特征融合模块,如C2fCIB(在语义特征较为丰富的层,将C2f模块替换为C2fCIB模块,以深度可分离卷积替代标准卷积,降低计算量并增大感受野)。
3.头部网络(Head)
头部网络(Head)是YOLOv10进行目标分类和位置回归的关键部分。
三、算法改进
YOLOv10在头部网络中引入了多项改进,包括:
1.下采样
下采样操作由单个的CBL(卷积+批量归一化+Leaky ReLU)替换为SCDown(先通过1x1卷积调节通道数,再通过k=3, s=2的深度卷积进行空间下采样)。
2.Detect模块
在Cls分类分支中,将连续的Conv3x3卷积替换为两个Conv3x3+Conv1x1的深度可分离卷积,以降低计算量。
3.PSA Block
在SPPF层后添加了PSA Block模块,以提供全局的计算能力。
4.双重标签分配
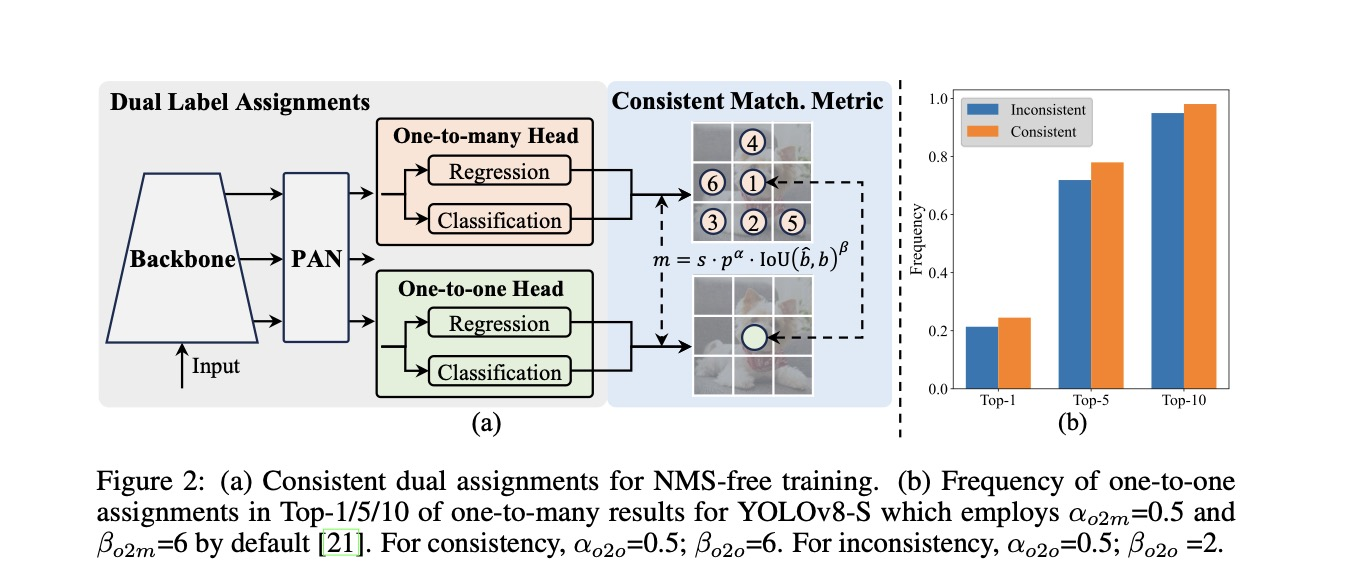
YOLOv10采用了双头设计,即One-to-many Head和One-to-one Head。这两个头在训练时同时参与计算损失,而在推理预测时只需使用One-to-one Head。这种设计有助于解决后处理中的冗余预测问题,实现了NMS-free的端到端检测。
5.排序引导块设计(basic building block)
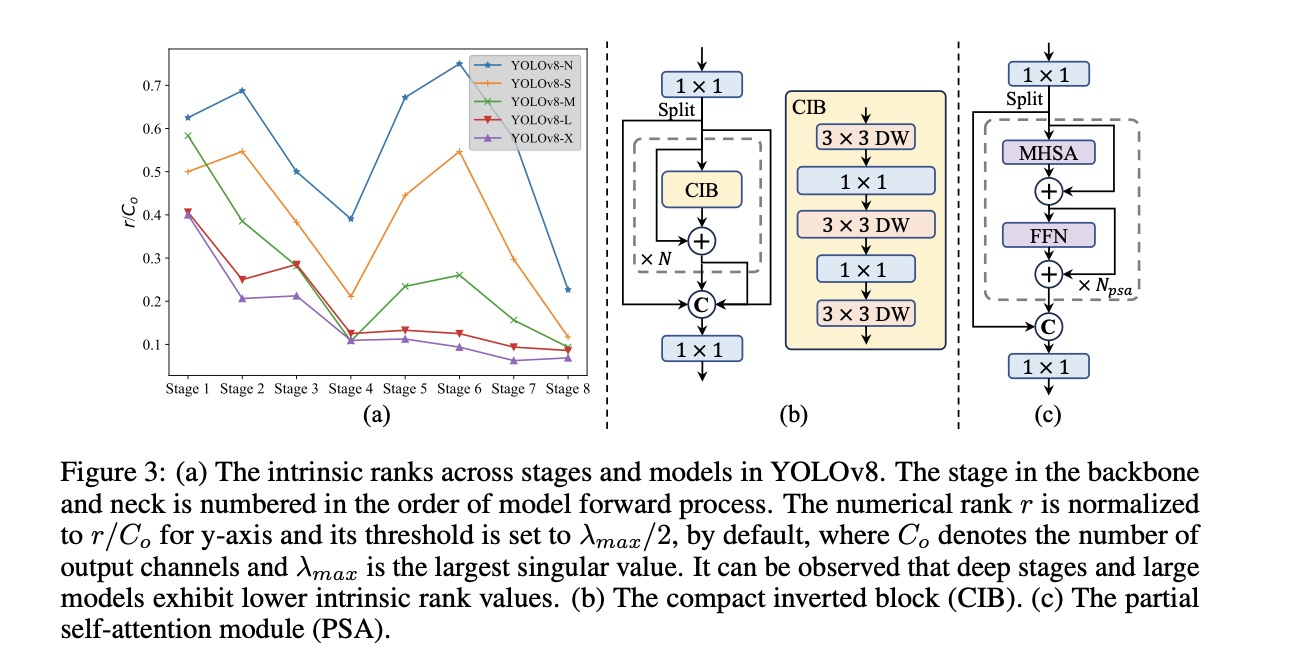
作者认为模型在重复使用同个模块拼接后,会带来较大的信息冗余。所以作者对yolov8各个大小的模型的每个阶段的最后一个卷积进行秩的分析,通过下图可以发现模型较大且较深时,秩相对较小。说明了大模型存在较多的信息冗余,也就是说有用的信息不多。所以作者提出了CIB模块,CIB模块由3个3x3的DW卷积和2个1x1的卷积组成,下图展示了将CIB模块嵌入ELAN的方法。作者希望通过CIB模块降低模型的复杂度,同时保证模型的ap值。
四、性能表现
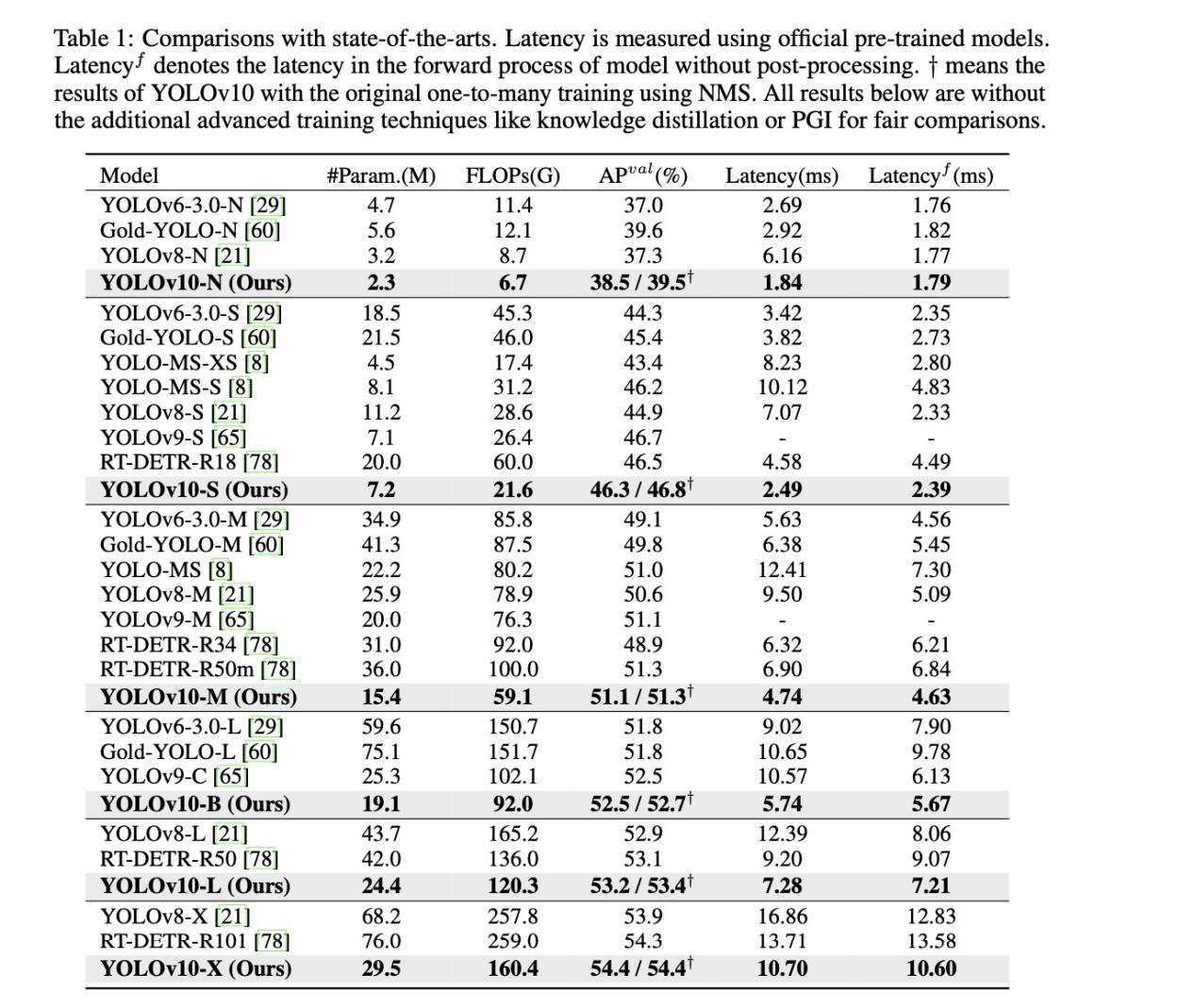
以YOLOv8作为baseline模型,为方便对比,YOLOv10也开发了一系列规模不同的网络结构如:N/S/M/L/X,更在M的基础上稍微提升宽度比例因子得到YOLOv10-B,实验都用COCO2017训练集训练,用其验证集选择最佳模型,用COCO2017测试集评估模型性能。所有模型的延迟时间均在T4 GPU上使用TensorRT FP16进行测试得到。
从表中可以看出,在同等规模网络结构下,YOLOv10的参数量和flops均是最小,但AP是最高的,同时推理时间也是最短的。值得注意的是,AP这一列,对于YOLOv10的行,AP有两个值,右上角带加号标注的为检测器一对多检测头的输出,看以看出,模型规模越小,一对多输出的AP比前者一对一输出的AP高得越多,在YOLOv10-X时,两者达到相同的AP效果。
五、消融实验
作者对所提改进方式,一致双标签分配NMS-free训练策略和模型效率-精度设计策略进行了消融实验,实验在YOLOv10-S和YOLOv10-M两个规模结构下完成,结果如下表所示。
可以看出,若单独采用一致双标签分配NMS-free训练策略,AP会有少许下降,但推理时间大大减小;若再结合高效网络结构设计,会减小模型参数的同时进一步减小模型推理时间,最后再结合精度网络结构设计策略,能在不增加推理时间的情况下,将AP提升1到两个点左右。从以上结果可以看出,作者提出的改进方式是有效果的。
六、YOLOv10使用详解
那么,不用下载代码不用创建虚拟环境的YOLOv10模型训练是否可以做到呢?当然可以!跟随我的步骤一起操作吧!
1.添加模型
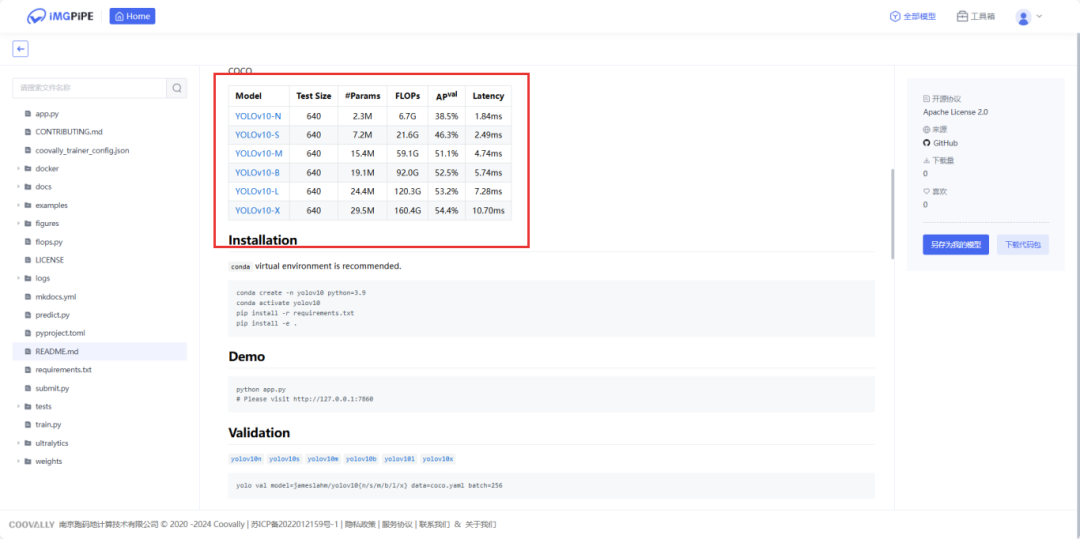
进入Coovally平台点击【全部模型】,搜索YOLOv10,点击进入可选择不同配置的YOLOv10版本。下载代码包或者点击另存为我的模型。进入【模型集成】页面,进行安装。
2.创建数据集
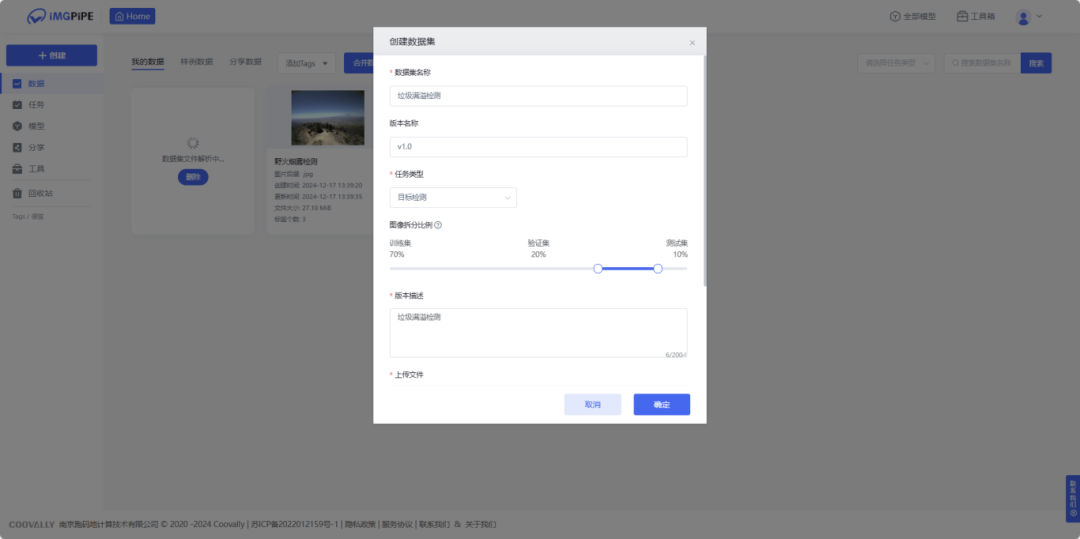
进入【图像数据】页面,点击创建数据集,输入数据集名称、描述,选择任务类型,上传压缩包文件。创建数据集时可以按照比例拆分训练集、验证集、测试集。
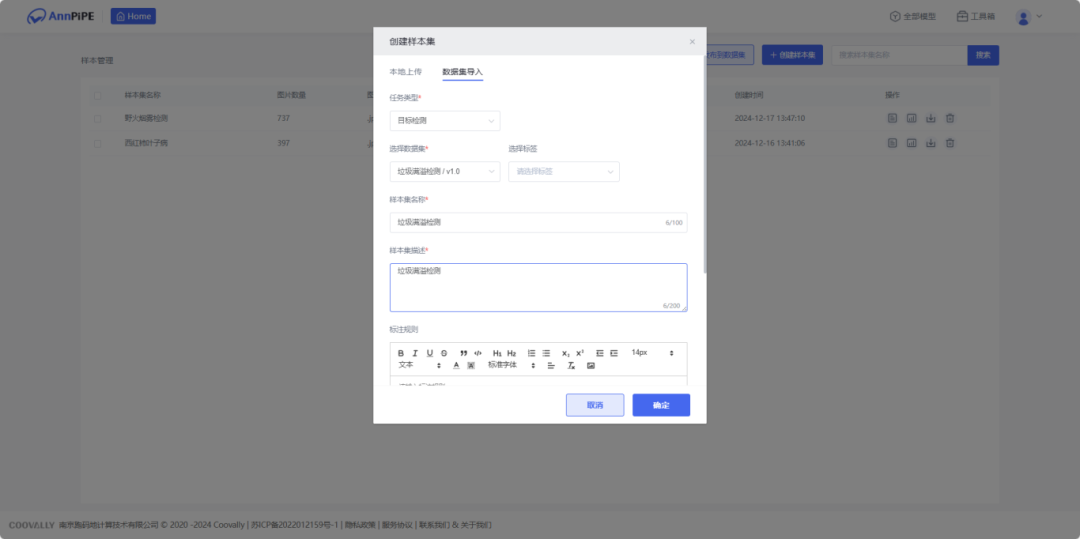
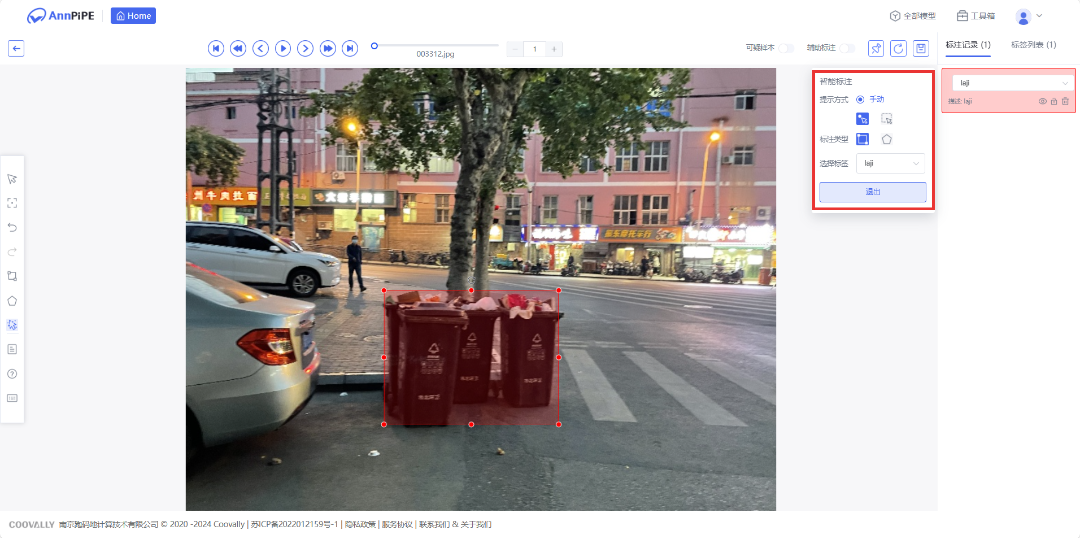
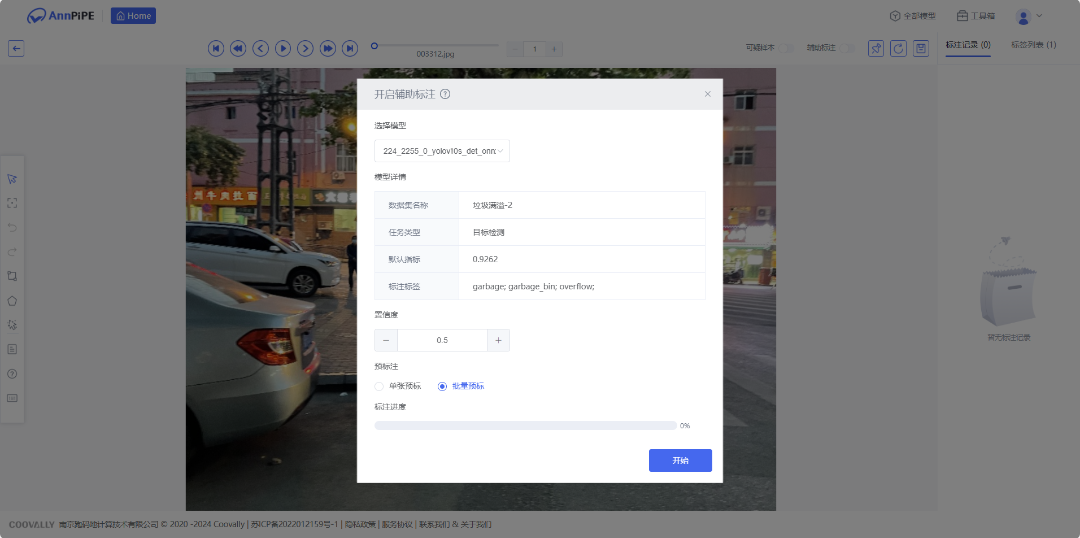
3.数据标注
进入【辅助标注】页面,点击创建样本集,进入样本集详情页,创建好标签进行数据标注。可以选择几组数据进行人工标注,标注完成后发布为数据集启动微调训练,剩余样本集数据即可全部自动化完成。
4.模型训练
进入数据集详情页,输入任务名称,选择模型配置模版,设置实验E-poch次数,训练次数等信息,即可开始训练。
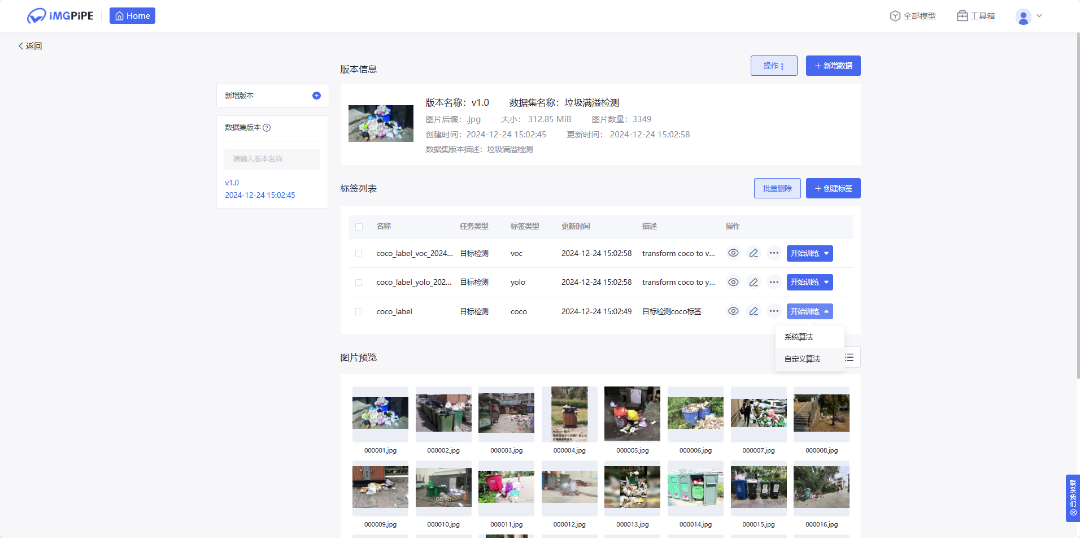
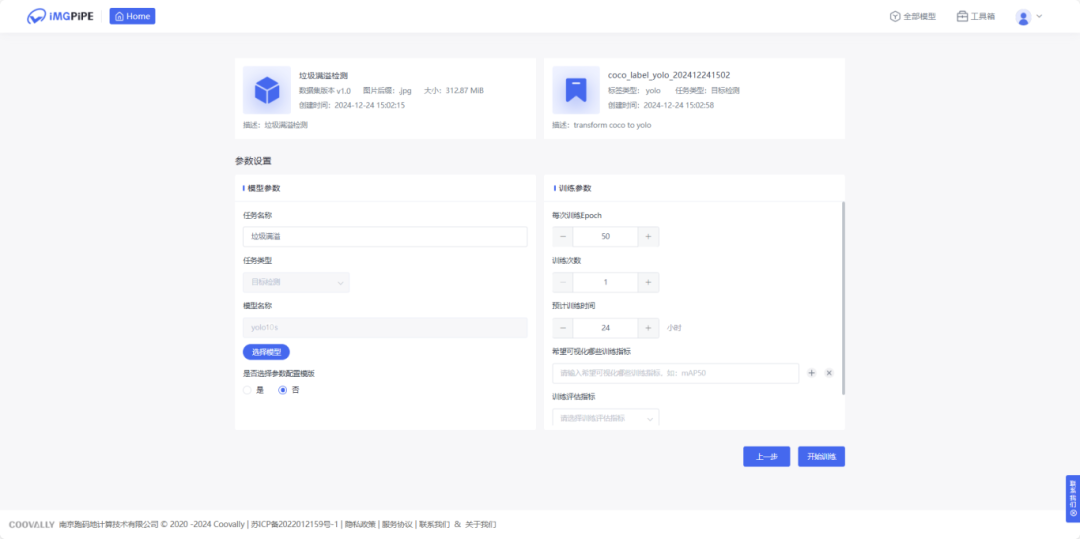
5.模型预测
模型训练完成后,完成模型转换与模型部署后,即可上传图片进行结果预测。完成后还可以将模型下载与分享。
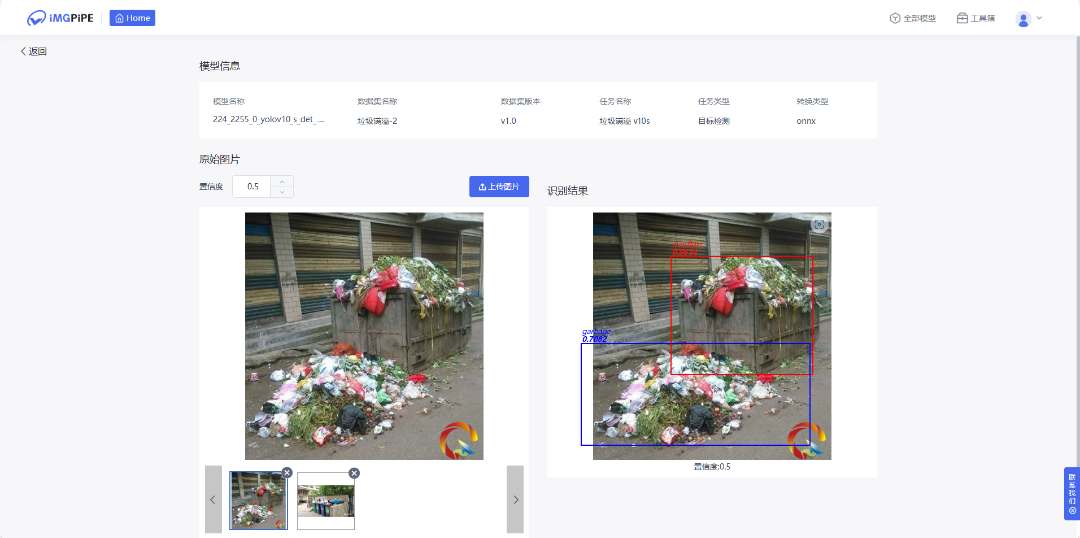
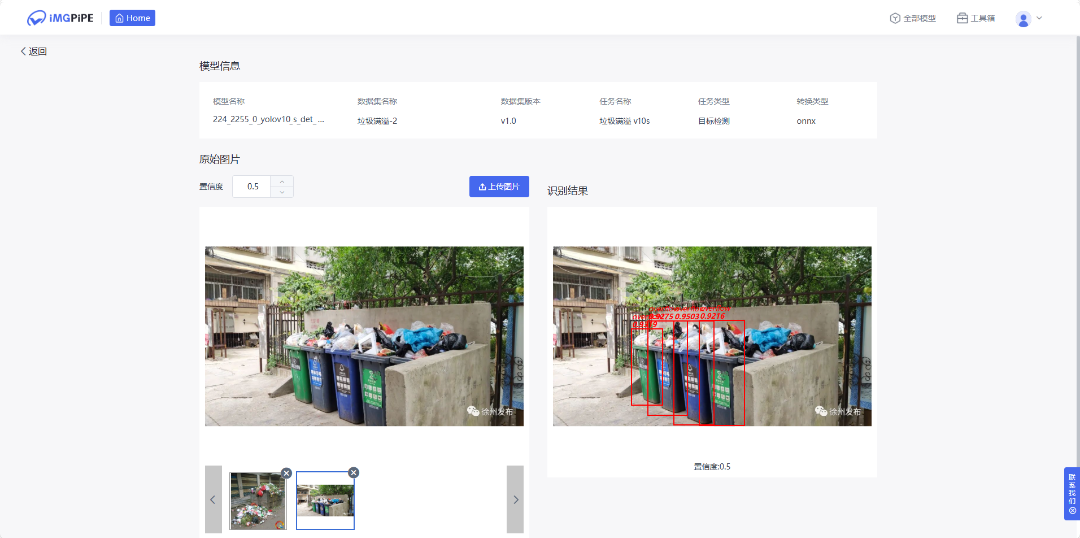
总结
YOLOv10,这是一个新的实时端到端目标检测器,通过大量实验表明,与其它先进检测器相比,YOLOv10在性能和延迟方面均达到了最先进水平,总结而言YOLOv10的贡献的不可忽略的。以下是对YOLOv10的总结:
1.双重分配策略与连贯匹配度量
YOLOv10采用了新颖的一致性双重分配策略,通过双重标签分配方法在训练时提供丰富监督信息,同时在推理时通过一对一分支实现高效率,创新性地提出了连贯匹配度量来减少监督差距,提升了性能。这一改进使得YOLOv10在无需NMS的情况下也能实现高效的端到端目标检测。
2.效率-精度驱动的模型设计
YOLOv10引入了整体效率-精度驱动的模型设计策略,包括新型轻量级分类头、空间-通道解耦降采样等设计,大幅减少了计算冗余,提高了效率。同时,大核卷积和部分自注意力模块的引入也进一步提升了性能。
3.性能与效率的权衡及未来展望
YOLOv10在性能和效率权衡方面达到了最先进水平。然而,由于计算资源限制,未在大规模数据集上预训练,且在小型模型中,使用NMS的一对多训练性能更优。未来工作将探索进一步缩小差距并实现更高性能的方法。
总结来说,YOLOv10不仅是一个新的实时端到端目标检测器,而且在各个方面都有所提升。如果您有兴趣了解更多关于YOLOv10的使用方法等,欢迎关注我们,我们将继续为大家带来更多干货内容!


















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









