





论文:http://arxiv.org/abs/2201.06493
摘要
通过RGB图像或LIDAR点云通过自主驾驶进行了广泛探索的对象检测。但是,使这两个数据源互补并且彼此有益仍然是一项挑战。在本文中,我们提出了AutoAlign,这是一种用于3D对象检测的自动功能融合策略。我们没有建立与摄像机投影矩阵的确定性对应关系,而是用可学习的对齐图对图像和点云之间的映射关系进行建模。该网络图使我们的模型能够以动态和数据驱动的方式 自动化对齐非均匀特征。具体而言,设计了一个交叉注意特征对齐模块,以适应每个体素的聚合 像素级图像特征。为了增强功能对齐过程中的语义一致性,我们还设计了一个自我监视的交叉模式交互模块,模型可以通过实例级特征指导来学习特征聚合。广泛的实验结果表明,我们的方法可以分别在Kitti和Nuscenes数据集上进行2.3 MAP和7.0 MAP改进。值得注意的是,我们的最佳模型在Nuscenes测试排行榜上达到了70.9 NDS,在各种最先进的情况下达到了竞争性能。
1. 简介
深度学习的最新进展带来了自主驾驶方面的快速进步。通过LIDAR点检测3D对象在理解车辆周围环境中起着至关重要的作用。激光雷达点可以捕获精确的3D空间信息以进行对象检测,但是,它们经常遭受缺乏语义信息和反射点的稀疏性,从而导致在雾蒙蒙或拥挤的情况下失败。与点云相比,RGB图像在提供语义和长距离信息方面具有更好的强度。因此,许多方法探索了RGB摄像机和LIDAR传感器的数据融合,以提高3D对象检测的性能。
多模式3D对象检测器可以大致分为两类:决策级融合和特征级融合。决策级融合:以各自的方式检测对象,然后在3D空间中一起装配检测框[Pang等,2020]。[Pang et al., 2020] Su Pang, Daniel Morris, and Hayder Radha. Clocs: Camera-lidar object candidates fusion for 3d object detection. In IROS, pages 1–10, 2020.特征级融合:将多模式特征结合到单个表示中从中检测到对象。因此,检测器可以在推理阶段充分利用来自不同方式的特征。鉴于此,最近已经开发了更多功能级融合方法。一项工作Pointpainting、Pi-rcnn [Vora et al., 2020] Sourabh Vora, Alex H Lang, Bassam Helou, and Oscar Beijbom. Pointpainting: Sequential fusion for 3d object detection. In CVPR, pages 4604–4612, [Xie et al., 2020] Liang Xie, Chao Xiang, Zhengxu Yu, Guodong Xu, Zheng Yang, Deng Cai, and Xiaofei He. Pi-rcnn: An efficient multi-sensor 3d object detector with point-based attentive cont-conv fusion module. In AAAI, volume 34, pages 12460–12467, 2020.每个点都向图像平面投射,并通过双线性插值获取相应的图像特征。尽管该特征聚集在像素级别上进行了精巧,但由于融合点的稀疏性,即破坏图像特征中的语义一致性,我们将失去图像域中的密集图案。另一项工作线MV3D[Chen等,2017]使用3D检测器提供的初始建议,以在不同的模态下获得相应的ROI特征,并将它们串联在一起以进行特征融合。它通过进行实例级融合来保持语义一致性,但是,在初始提案生成阶段,它遭受了粗糙的特征聚集和不存在2D信息。
结合这两种类型的方法,我们为3D对象检测提出了一个集成的多模式融合框架,名为AutoAlign。它使探测器能够以适应性方式聚合跨模式特征,事实证明,这对于对非均匀表征之间的关系进行建模是有效的。同时,它利用像素级别的细颗粒特征聚集,但同时保留了通过实例的特征交互来保留语义一致性(请参见图1)。
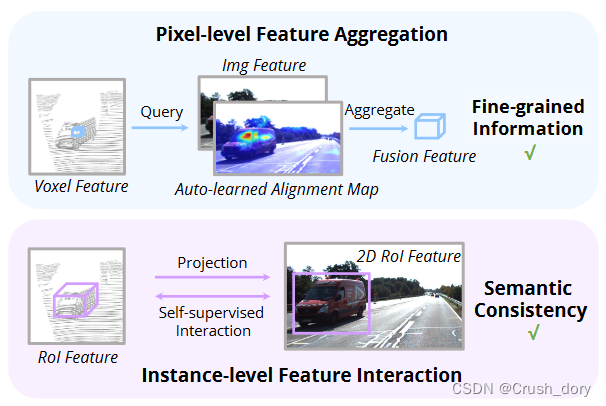
具体而言,为了保留RGB数据中的具体详细信息,我们设计了一个跨注意功能对齐(CAFA)模块,该模块动态地关注图像中的像素级功能,并通过在更高的3D级别(支柱或体素)中融合特征来保持效率。每个体素特征都会查询整个图像平面以获取像素语义对齐图。然后,CAFA基于对齐图聚合图像特征,并将它们与原始3D功能相连。为了促进点云和图像之间的语义一致性,我们提出了一种新颖的自我监视的跨模式特征交互(SCFI)模块。详细说明,我们首先使用检测器预测的配对的2D3D提案来提取各自域中的区域特征。之后,在2D和3D空间中配对的区域特征之间添加相似性损失。通过在实例级别与跨模式特征进行交互,SCFI增强了在CAFA中感知语义相关信息的能力。
此外,受到多任务学习的启发,我们设计了一个2D-3D检测联合训练范式,以正规化图像分支的优化。这样的训练方案阻止了图像主链的过度拟合问题,并进一步增强了3D探测器的性能。这项工作的主要贡献是三个方面:
•我们提出了一个可学习的多模式特征融合框架,称为AutoAlign,该框架在像素级别和实例级别上都增强了融合过程。
•我们提出了用于2D-3D检测的联合训练范式,以使从图像分支提取的特征正规化并提高检测准确性。
•通过广泛的实验,我们验证了所提出的自动对准在各种3D检测器上的有效性,并在Kitti和Nuscenes数据集上实现竞争性能。
2. 相关工作
2.1 单一模态的3D目标检测
3D对象检测通常是通过RGB摄像机或LIDAR传感器的单一模态进行的。相机的3D方法将图像作为输入并输出空间中对象的定位。由于单眼相机无法提供深度信息,因此这些模型需要估计深度本身[Chen et al.,2016]。例如,[Mousavian et al.,2017]首先预测2D边界框,然后估算物体的深度,以将2D框展开为3D。但是,单眼3D检测通常会在预测深度信息方面失败。因此,立体声图像用于生成3D 检测的致密点云[You et al., 2019; Li et al., 2019].用于3D检测的最广泛使用的传感器是LIDAR,可以将其分为三类:体素,点和视图。基于素的技术将点离散到体素中,并将点汇总到它们中以提取特征[Zhou and Tuzel,2018]。与基于体素的方法不同,[Shi et al.,2019; Yin et al.,2021a]直接处理点级别的特征,该功能维持原始点提供的原始几何信息,但通常在计算上很昂贵。从每个视图中提取特征也是3D检测中的流行流,其中将点压缩到鸟眼视图中[Lang et al.,2019]或范围视图[Fan et al.,2021],例如预测。
2.2多模式的3D对象检测
最近,用于对象检测的多模式融合会吸引许多注意力。例如,[Qi et al.,2018]预测2D域中的框,并在3D空间中进一步完善它们。 [Ku et al.,2018]和[Chen et al.,2017]试图执行ROI融合。为了获得更平滑的BEV图,[Yoo et al.,2020]建议学习针对不同模式的自动校准投影。但是,它遭受了功能模糊的问题。其他方法[Sindagi et al.,2019; Liang et al.人,2018年]以某种方式融合功能。例如,[Vora et al.,2020]使用摄像头投影矩阵对3D点上的2D语义预测进行绘制,然后执行3D对象检测。 [Huang et al.,2020]设计了一种新型的L1融合模块,用于细粒融合。
3.方法
在本节中,我们详细描述了提议的自动符号。我们的方法概述如图2所示。
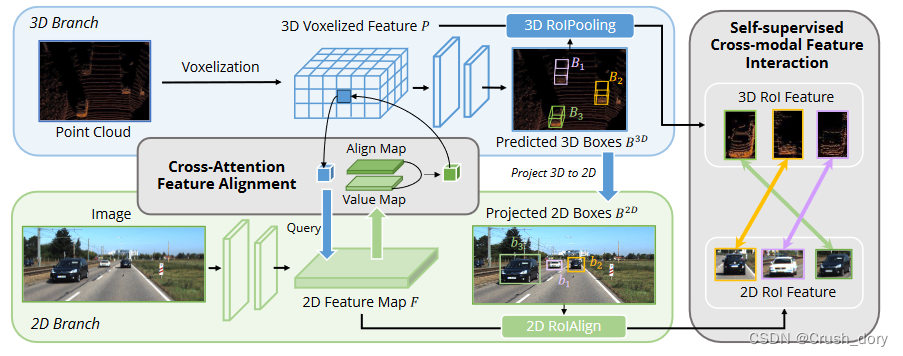
它由两个核心组成部分组成:CAFA(第3.1节)在图像平面上执行特征聚合,以提取每个Voxel特征的细粒度像素级信息,SCFI(第3.2节)进行交叉模式自我监督,并施加劳动实例级别的指导来增强CAFA模块中语义一致性。
3.1 像素级特征聚合
先前的工作主要利用摄像头投影矩阵以确定性的方式对齐图像和点特征。这种方法是有效的,但可能会带来两个潜在的问题:1)点在图像数据上无法得到更广阔的视野,2)仅在忽略语义相关性时保持位置一致性。因此,我们设计了交叉注意特征对齐模块(CAFA),以适应非均匀表示之间的特征。 CAFA模块没有采用一对一的匹配模式,而是使每个体素能够感知整个图像,并基于可学习的对齐矩阵动态地注意了像素的2D功能。
如图2所示,我们的方法将Resnet-50作为骨干网络,从给定图像提取全局特征图。结果,大小为H×W的输入图像将产生具有H/32×W/32的空间尺寸的特征图。从图像骨干提取的特征图表示为![]() 其中h,w,c分别是全局特征图的高度,宽度和通道。添加1×1卷积以减少特征维度,从而创建一个新的特征映射
其中h,w,c分别是全局特征图的高度,宽度和通道。添加1×1卷积以减少特征维度,从而创建一个新的特征映射![]() 。之后,我们将F的空间尺寸缩小到一个维度,从而导致hw×d维特征向量。在我们的跨注意机制中,给定特征图(
。之后,我们将F的空间尺寸缩小到一个维度,从而导致hw×d维特征向量。在我们的跨注意机制中,给定特征图(![]() fi表示第i个空间位置的图像特征)和体素特征p = {p1,p2,...,pj}(pj表示每个非空体素特征)从原始点云中提取,键和值是从f产生的,查询是由p产生的。正式
fi表示第i个空间位置的图像特征)和体素特征p = {p1,p2,...,pj}(pj表示每个非空体素特征)从原始点云中提取,键和值是从f产生的,查询是由p产生的。正式
![]()
当![]() 是线性预测。对于第j个查询Qj,注意力的权重是根据跨模式查询和密钥之间的点和全局的相似性计算的:
是线性预测。对于第j个查询Qj,注意力的权重是根据跨模式查询和密钥之间的点和全局的相似性计算的:
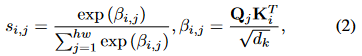
其中![]() 是缩放因素。交叉说明机制的输出被定义为根据注意力权重的所有值的加权总和:
是缩放因素。交叉说明机制的输出被定义为根据注意力权重的所有值的加权总和:
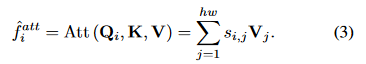
归一化注意力的重量![]() 模拟不同空间像素
模拟不同空间像素![]() 和体素
和体素 ![]() 之间的兴趣,这是图2所示的对齐图2。值的加权总和可以汇总细粒的空间像素以更新
之间的兴趣,这是图2所示的对齐图2。值的加权总和可以汇总细粒的空间像素以更新![]() ,从而以全球视图方式使用2D信息丰富了点功能。像变压器体系结构一样,我们使用前馈网络来生成最终的RGB感知点功能:
,从而以全球视图方式使用2D信息丰富了点功能。像变压器体系结构一样,我们使用前馈网络来生成最终的RGB感知点功能:
![]()
其中FFN(·)是一个使用一个完整连接(FC)层的简单神经网络[Vaswani et al.,2017]。[Vaswani et al., 2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, pages 5998–6008, 2017.
3.2实例级功能交互
CAFA是汇总图像特征的细粒范式。但是,它无法捕获实例级信息。相反,在提案生成阶段即使在粗糙的特征聚集和没有2D信息的情况下,RoI-wise特征融合保持物体的完整性
为了消除像素级和实例级融合之间的差距,我们介绍了自我监视的跨模式交互(SCFI)模块,以指导CAFA的学习。它直接利用了3D检测器的最终预测作为提案,它利用了图像和点特征来生成准确的提案。此外,我们没有将跨模式特征串联在一起以进行进一步的检测盒细化,而是在配对的跨模式特征之间进行了相似性约束,作为实例级别指导的特征对齐方式。
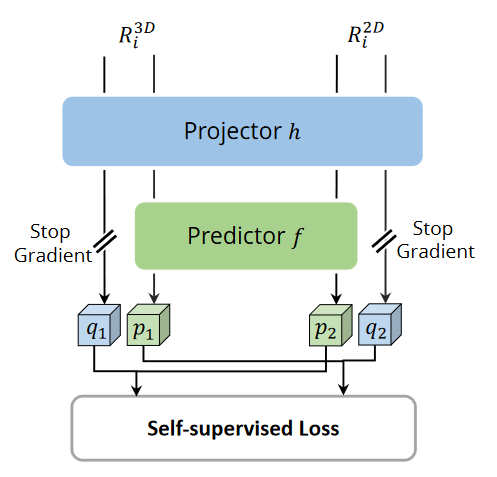
给定的2D特征图F和相应的3D Voxelized特征P,我们随机采样n区域3D检测框,表示为![]() ,然后使用摄像头投影矩阵将它们投射到2D平面中,从而产生一组配对的2D盒
,然后使用摄像头投影矩阵将它们投射到2D平面中,从而产生一组配对的2D盒![]() 。获得配对盒后,我们将在2D和3D功能空间中采用2DRoIAlign [He et al.,2017]和3DRoIPooling[Shi et al.,2020],以获得相应的ROI功能
。获得配对盒后,我们将在2D和3D功能空间中采用2DRoIAlign [He et al.,2017]和3DRoIPooling[Shi et al.,2020],以获得相应的ROI功能![]() 和
和![]() ,每个
,每个![]() 和
和![]() 由以下公式给定:
由以下公式给定:
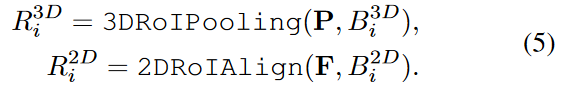
对于每个配对的2D和3D RoI 功能,我们从图像分支上执行C5上的自我检查的交叉模式交互,以及从点分支中的Voxelization之后的功能。他们俩都被馈入投影头H,从而改变了一种模态的输出以匹配另一种模态。与[Chen and He,2021年]相似,引入了一个带有两个完全连接层的预测头F。将两个输出向量表示为![]() 和
和![]() ,我们将特征距离
,我们将特征距离![]() 最小化,具有负余弦相似性损失,如图3所示。模态表示更接近,我们将对称损失定义为:
最小化,具有负余弦相似性损失,如图3所示。模态表示更接近,我们将对称损失定义为:
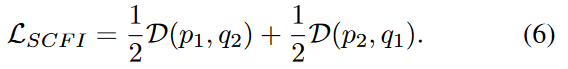
此外,在没有预测头的分支机构的情况下,还采用了定格梯度策略,可以由D(m1, stopgrad(v1)) 表示。因此,互动损失被实施为:
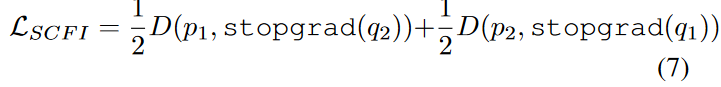
3.3 2D-3D预测的联合训练
尽管多任务学习的有效性,但几乎没有工作讨论图像和点域的联合检测。在以前的大多数方法中,图像主链使用来自其他外部数据集的预训练权重直接初始化。在训练阶段,唯一的监督是从点分支传播的3D检测损失。考虑到图像主链中的大量参数,2D分支更有可能对隐式监督过度拟合。为了使从图像中提取的表示形式正规化,我们将图像分支扩展到更快的R-CNN,并以2D检测损失对其进行监督,其中总损耗L的设计为:
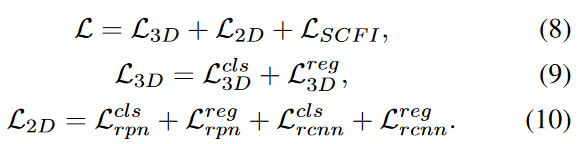
4. 实验
4.1 实施细节
为了验证我们的自动符号的有效性,我们选择PointPillar [Lang et al., 2019], SECOND [Yan et al., 2018],和CenterPoint [Yin et al., 2021a]作为我们实验的代表性方法。对于图像分支,采用RESNET50的RCNN [REN et al.,2015]作为2D检测器。跨注意对齐模块的隐藏单元设置为128,2DRoIAlign和3DRoIPooling的输出尺寸均设置为4。投影仪的MLP单元和自我监督的跨模式模块的预测指标为2048和隐藏单元数字为512。我们的2D-3D联合训练框架以端到端的方式与混合优化器进行了优化,其中3D分支通过ADAMW优化,并使用SGD优化了2D分支。我们将mmdetection3d [Contributors, 2020]用作我们的代码库,并在未指定的情况下应用默认设置。
4.2 Kitti数据集上的结果
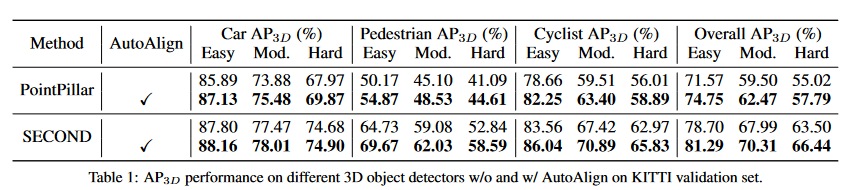
在本节中,我们在Kitti数据集上评估了我们的框架,并报告平均精度(AP40)。我们在两个代表性3D对象探测器上实施自动符号:尖头(基于支柱)和第二个(基于体素)。表1中报告了3D地图性能。总的来说,我们的自动符号显着提高了指尖,在3D中度评估协议下以3.0和2.3 MAP的第二名提高了第二名,从而验证了所提出的方法的有效性。在详细观察结果时,我们发现行人和骑自行车的人的AP大多数是促进的(分别为3.0和3.5 AP3D中等地图)。我们推断出汽车经常拥有更多要点的原因,而行人和骑自行车的人则大多缺乏反射,这使得它们在3D空间中更难被检测到。因此,自动构架从自然密集且具有语义和纹理信息丰富的RGB数据中受益。
4.3 Nuscenes数据集的结果
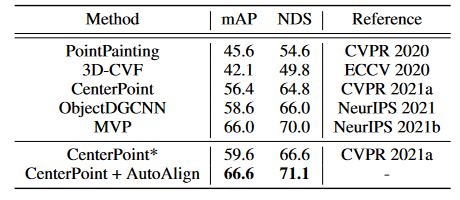
我们还对具有当前最新的3D检测器中心点的较大的Nuscenes数据集进行了实验,以进一步验证自动符号的有效性。如表3所示,在Nuscenes验证集上,AutoAlign在Nuscenes验证集上实现了66.6 MAP和71.1 NDS,以7.0 MAP和6.5 NDS优于强中心点基线。它还超过了最近开发的多模式3D检测器MVP [Yin et al., 2021b]在同一单阶段设置下的1.1 NDS。此外,由于其简单性和联合培训范式,它不需要任何复杂的虚拟点生成或图像特征预取食,这更适合于现实世界中的应用。我们还报告了每个对象类别的详细结果以及补充材料中测试排行榜上的性能。
4.4消融研究
要了解自动座中的每个模块如何促进检测准确性,我们测试了基线检测器第二个组件,并在表2中报告其在KITTI验证数据集上的AP性能。
当应用跨注意功能对齐时,准确性提高了0.5地图和改进在所有难度级别的对象上找到。该结果验证了在汇总跨模式特征时保留图像信息高分辨率的重要性。

然后,我们添加了SCFI模块,该模块带来了1.2 MAP增强的功能,即总体中等AP3D从68.5提高到69.7,这表明该特征相互作用在我们的融合框架中起关键作用。它在特征对齐方式上施加了Instancelevel的监督,这暗示了如何在非官方表示范围内汇总语义配对的特征。
当添加2D关节训练时,准确性将通过另外0.6地图提高,并且Aphard由1.0 MAP提高。这两个方面都有如此巨大的改进好处:1)联合训练范式正常地将图像主链优化和2)关节优化降低了2D和3D模型之间的训练差距,并在交叉模式特征融合过程中保持特征一致性。
4.5讨论
在本节中,我们深入研究自动座框架,以研究如何实现检测准确性并对潜在机制有更深入的了解。对于所有实验,我们使用SECOND在第4.2节中用相同的设置。
调查最佳的跨模式查询策略。
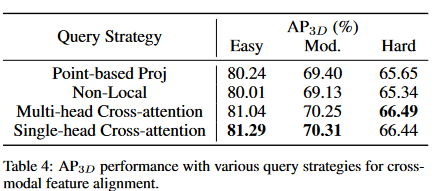
在这一部分中,我们比较了跨模式特征查询的各种策略。首先,我们选择广泛采用的融合策略,即通过摄像机投影矩阵并利用点双线性插入以获得对齐的2D图像。其次,我们测试了[Wang et al.,2018]中提出的非本地块,其中所有图像特征都被考虑在内,但只有较高注意力评分的感兴趣位置才能用于跨模式融合。最后,我们采用了一种更通用的形式,该形式类似于[Vaswani et al.,2017]中的自我发场模块,但我们将其从相同的方式扩展到非殖民地表示。遵循自我注意力的共同设计,我们探讨了单头交叉注意模块和多头模块的性能。详细结果在表4中列出。使用基于点的投影时,改进是有限的,因为这些点无法获得连续的图像功能。但是,当用非本地块替换基于点的投影时,性能仍然不令人满意。可能的原因可能在于导致过度拟合问题的FC层。与香草非本地阻滞相比,交叉注意的性能更具竞争力,这可能是由于采用了辍学策略和特征归一化。考虑到计算成本和效率,我们终于将单头交叉注意作为我们的查询策略。
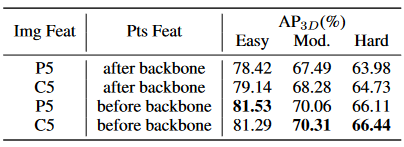
寻求合适的功能来源以进行自我监督的功能交互。
特征交互是一个核心组件,因为它通过Instancelevel指导加强了CAFA模块的语义一致性。因此,如何为自我监督学习选择合适的特征来源是不平凡的。在仔细检查了所选的点特征和图像特征来源之后,我们将图像特征直接从Resnet主链(即C5)和FPN(即P5)作为候选者中获取。对于点分支,我们在点骨架前和主链之后选择功能。如表5所示,使用C5作为图像功能优于P5。我们推断出P5直接用于2D检测的原因,因此限制了跨模式特征融合的概括能力,而C5对于2D检测和非殖民地自我监督学习更加灵活。当在主链之后选择点特征时,我们会观察到相似性损失的快速收敛性,但结果不令人满意。这可能源于3D分支的灵活性,即,点骨架为点特征提供了复杂转换的可能性,从而简化了损失的优化,但削弱了我们提议的自我监督功能的实例级别的语义一致性指导相互作用。相反,尽管使用骨架之前使用这些功能会减慢收敛性,但模型是通过相互交互的隐式监督,并逐渐学习如何将CAFA模块中的跨模式特征对齐。
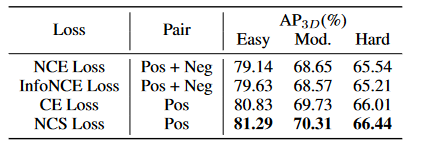
自我监督的跨模式学习的最佳损失。
由于大多数自我监督的学习方法都是基于同质的表示,因此必须探索最佳的自我监督损失,以实现交叉模式。我们比较了四个不同的原型,并报告了表6中的结果。我们采用了对比度损失的经典版本,其中考虑了正对和负面对。请注意,位于3D空间和2D平面相同位置的特征被认为是正对,而其余的是负对。 NCE损失及其变体信息的选择不能提供显着的增强。但是,当仅利用正对进行特征相互作用时,我们会观察到显着改善。我们推断的原因是点与图像相比拥有更少的身份信息。当监督两个具有负面损失的类似实例时,如果实例的形状相似,则可能会恶化3D特征表示。因此,我们为我们的特征相互作用模块选择了负余弦相似性损失。
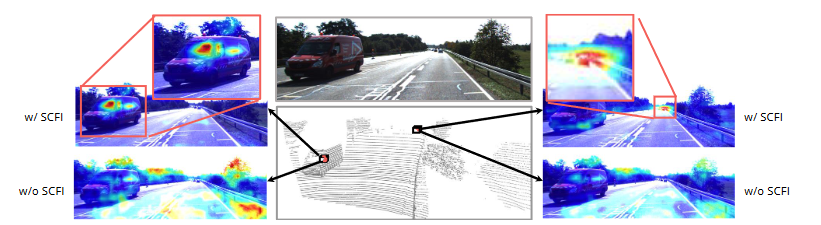
4.6可视化和分析外
除了在各种数据集上的检测结果外,我们还在学到的对齐图上提供了更直接的可视化,给定不同的3D查询素特征,如图4所示。要更好地说明CAFA和CAFA之间的相互影响。 SCFI模块,我们将查询注意力图与SCFI进行比较。可以清楚地得出结论,CAFA无法在没有特征相互作用的情况下在2D图像上产生有意义的对齐图。相反,当使用SCFI武装时,CAFA模块可以成功提供位置和语义合理的特征对齐图。
5 结论
我们开发了AutoAlign,这是一种可学习的多模式特征融合方法,用于3D对象检测。所提出的跨意义特征对齐模块使每个体素特征都能以细化的方式汇总图像信息。此外,新型的自我监视的跨模式特征交互模块旨在增强CAFA模块分配过程中的语义一致性。全面的实验结果表明,自动符号可显着改善Kitti和Nuscenes数据集上的各种3D检测器。我们希望我们的工作可以为自动驾驶的多模式功能融合提供新的视角。
6. References
[Chen and He, 2021] Xinlei Chen and Kaiming He. Exploring
simple siamese representation learning. In CVPR,
pages 15750–15758, 2021.
[Chen et al., 2016] Xiaozhi Chen, Kaustav Kundu, Ziyu
Zhang, Huimin Ma, Sanja Fidler, and Raquel Urtasun.
Monocular 3d object detection for autonomous driving. In
CVPR, pages 2147–2156, 2016.
[Chen et al., 2017] Xiaozhi Chen, Huimin Ma, Ji Wan,
Bo Li, and Tian Xia. Multi-view 3d object detection network
for autonomous driving. In CVPR, pages 1907–1915,
2017.
[Contributors, 2020] MMDet3d Contributors. MMDetection3D:
OpenMMLab next-generation platform for general
3D object detection. https://github.com/open-mmlab/
mmdetection3d, 2020.
[Fan et al., 2021] Lue Fan, Xuan Xiong, FengWang, Naiyan
Wang, and Zhaoxiang Zhang. Rangedet: In defense of
range view for lidar-based 3d object detection. arXiv
preprint arXiv:2103.10039, 2021.
[He et al., 2017] Kaiming He, Georgia Gkioxari, Piotr
Doll´ar, and Ross Girshick. Mask r-cnn. In ICCV, pages
2961–2969, 2017.
[Huang et al., 2020] Tengteng Huang, Zhe Liu, Xiwu Chen,
and Xiang Bai. Epnet: Enhancing point features with image
semantics for 3d object detection. In ECCV, pages
35–52, 2020.
[Ku et al., 2018] Jason Ku, Melissa Mozifian, Jungwook
Lee, Ali Harakeh, and Steven L Waslander. Joint 3d proposal
generation and object detection from view aggregation.
In IROS, pages 1–8, 2018.
[Lang et al., 2019] Alex H Lang, Sourabh Vora, Holger Caesar,
Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars:
Fast encoders for object detection from point
clouds. In CVPR, pages 12697–12705, 2019.
[Li et al., 2019] Peiliang Li, Xiaozhi Chen, and Shaojie
Shen. Stereo r-cnn based 3d object detection for autonomous
driving. In CVPR, pages 7644–7652, 2019.
[Liang et al., 2018] Ming Liang, Bin Yang, Shenlong Wang,
and Raquel Urtasun. Deep continuous fusion for multisensor
3d object detection. In ECCV, pages 641–656,
2018.
[Mousavian et al., 2017] Arsalan Mousavian, Dragomir
Anguelov, John Flynn, and Jana Kosecka. 3d bounding
box estimation using deep learning and geometry. In
CVPR, pages 7074–7082, 2017.
[Pang et al., 2020] Su Pang, Daniel Morris, and Hayder
Radha. Clocs: Camera-lidar object candidates fusion for
3d object detection. In IROS, pages 1–10, 2020.
[Qi et al., 2018] Charles R Qi, Wei Liu, Chenxia Wu, Hao
Su, and Leonidas J Guibas. Frustum pointnets for 3d object
detection from rgb-d data. In CVPR, pages 918–927,
2018.
[Ren et al., 2015] Shaoqing Ren, Kaiming He, Ross Girshick,
and Jian Sun. Faster r-cnn: Towards real-time object
detection with region proposal networks. NeurIPS, 28:91–
99, 2015.
[Shi et al., 2019] Shaoshuai Shi, XiaogangWang, and Hongsheng
Li. Pointrcnn: 3d object proposal generation and detection
from point cloud. In CVPR, pages 770–779, 2019.
[Shi et al., 2020] Shaoshuai Shi, Zhe Wang, Jianping Shi,
Xiaogang Wang, and Hongsheng Li. From points to parts:
3d object detection from point cloud with part-aware and
part-aggregation network. TPAMI, 2020.
[Sindagi et al., 2019] Vishwanath A Sindagi, Yin Zhou, and
Oncel Tuzel. Mvx-net: Multimodal voxelnet for 3d object
detection. In ICRA, pages 7276–7282, 2019.
[Vaswani et al., 2017] Ashish Vaswani, Noam Shazeer, Niki
Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
Łukasz Kaiser, and Illia Polosukhin. Attention is all you
need. In NeurIPS, pages 5998–6008, 2017.
[Vora et al., 2020] Sourabh Vora, Alex H Lang, Bassam
Helou, and Oscar Beijbom. Pointpainting: Sequential fusion
for 3d object detection. In CVPR, pages 4604–4612,
2020.
[Wang and Solomon, 2021] Yue Wang and Justin M
Solomon. Object dgcnn: 3d object detection using
dynamic graphs. NeurIPS, 34, 2021.
[Wang et al., 2018] XiaolongWang, Ross Girshick, Abhinav
Gupta, and Kaiming He. Non-local neural networks. In
CVPR, pages 7794–7803, 2018.
[Xie et al., 2020] Liang Xie, Chao Xiang, Zhengxu Yu,
Guodong Xu, Zheng Yang, Deng Cai, and Xiaofei He.
Pi-rcnn: An efficient multi-sensor 3d object detector with
point-based attentive cont-conv fusion module. In AAAI,
volume 34, pages 12460–12467, 2020.
[Yan et al., 2018] Yan Yan, Yuxing Mao, and Bo Li. Second:
Sparsely embedded convolutional detection. Sensors,
pages 3337–2247, 2018.
[Yin et al., 2021a] Tianwei Yin, Xingyi Zhou, and Philipp
Krahenbuhl. Center-based 3d object detection and tracking.
In CVPR, pages 11784–11793, 2021.
[Yin et al., 2021b] Tianwei Yin, Xingyi Zhou, and Philipp
Kr¨ahenb¨uhl. Multimodal virtual point 3d detection.
NeurIPS, 34, 2021.
[Yoo et al., 2020] Jin Hyeok Yoo, Yecheol Kim, Jisong Kim,
and Jun Won Choi. 3d-cvf: Generating joint camera and
lidar features using cross-view spatial feature fusion for 3d
object detection. In ECCV, pages 720–736, 2020.
[You et al., 2019] Yurong You, Yan Wang, Wei-Lun Chao,
Divyansh Garg, Geoff Pleiss, Bharath Hariharan, Mark
Campbell, and Kilian Q Weinberger. Pseudo-lidar++: Accurate
depth for 3d object detection in autonomous driving.
arXiv preprint arXiv:1906.06310, 2019.
[Zhou and Tuzel, 2018] Yin Zhou and Oncel Tuzel. Voxelnet:
End-to-end learning for point cloud based 3d object
detection. In CVPR, pages 4490–4499, 2018














 1293
1293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









