







1 Intro
- 3D骨架识别问题
- 早期以完全监督的方式训练网络
- ——>需要大量人工标注的骨架数据,花费昂贵,且很是费时
- 无监督的3D骨架表示学习在近年来被不断研究
- 早期的无监督工作主要聚焦于生成式方法
- 将3D骨架动作编码后,在不同的代理任务(比如骨架重构、骨架着色)的指导下解码,以达到学习特征表示的方法
- 但这类方法效果有限
- 性能更好、机制更简单的对比学习成为了近些年的主流
- 通常将3D骨架动作表示为实例级别的特征(instance-level),然后进行实例之间的整体对比学习
- 早期的无监督工作主要聚焦于生成式方法
- 早期以完全监督的方式训练网络
- 这篇论文认为,3D骨架动作具有层次结构,如果仅使用实例级别的特征进行对比学习,效果可能是次优的
- 3D骨架动作作为序列,时间维度上可以看作帧 (frame) 的集合,空间维度上可以看作节点 (joint) 的集合。
- 同时帧或节点是基本元素,可以构建为更大粒度的元素,如片段 (clip) 或部件 (part)
- 论文提出用于无监督 3D 骨架动作表示学习的层级对比框架 HiCo
- HiCo 通过层级编码器网络将 3D 骨架动作序列编码为部件级 (part-level)、片段级 (clip-level)、域级 (domain-level)和实例级特征,并在这几个层次上分层地进行多级对比。

2 模型
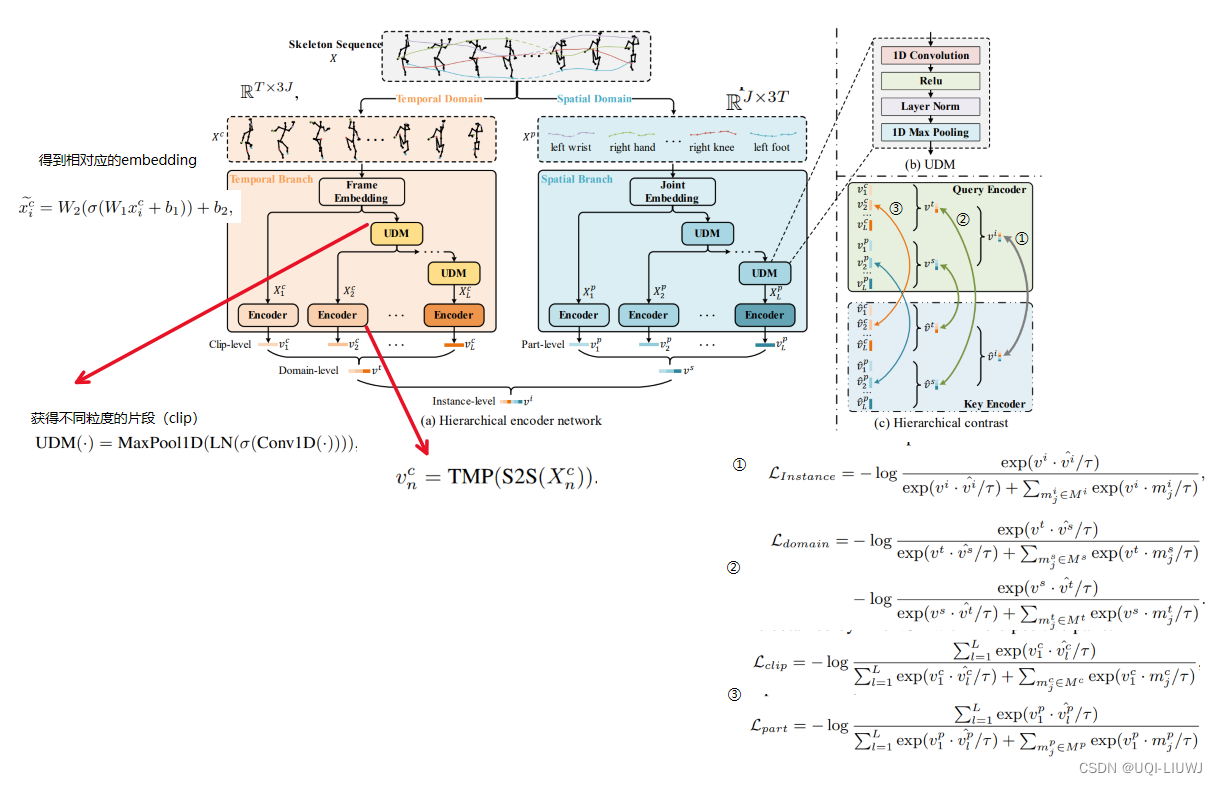
2.1 层次编码网络
层级编码网络包括时间和空间两个分支,分别从时间域和空间域以多粒度方式编码得到多个特征。
2.1.1 片段级特征表示
-
从不同长度的片段中提取特征
-
给定T帧J个节点的3D骨架动作序列
-
首先将其重新排列成帧列表的形式
-
然后使用一个MLP,作为帧Embedding,将帧信息映射到高维空间
-
-
- 为了得到不同长度的 clip,这里使用下采样UDM (Unified Downsampling Module)
- 通过一维卷积加一维最大池化的可训练方式缩短序列长度
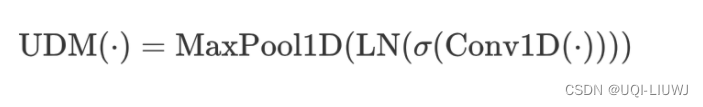
- 每一层UDM捕获各帧kernel size大小的时间维度信息
- 通过不断调用 UDM,就得到时间维度越来越短的序列
- 这样不同粒度 clip 包含不同时间尺度的信息,具有较强的互补性。

- 得到各个
之后,使用 seq2seq 模型建模时间上的依赖关系,再通过时间维度上的最大池化将帧级特征聚合为视频级特征
- 对每个粒度的clip都计算相应的视频级特征,然后拼接起来,得到片段级特征
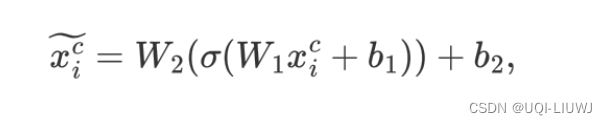
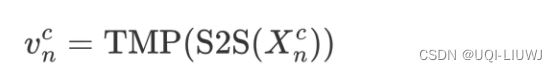

2.1.2 部件级特征表示
- 空间分支在空间域上提取不同空间粒度特征,形成部件级特征表示。
- 给定T帧J个节点的3D骨架动作序列
- 重新排列乘节点列表
- 重新排列乘节点列表
- 然后使用同样的方式,得到
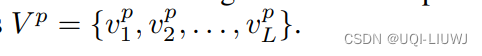
2.2 域级和实例级特征表示
- 将不同粒度的片段级特征融合为时间域特征,将不同粒度的部件级特征融合为空间域特征
- 再将这两个域级特征融合为实例级特征,由此得到了多层级结构的多特征表示。
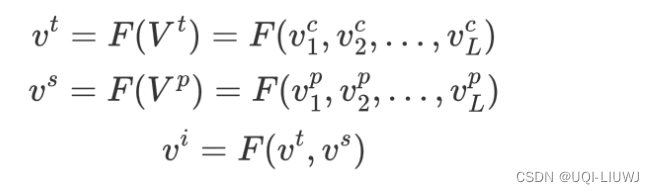
- 论文中,F只是concatenate
2.3 层次对比
总的优化目标由底下几部分共同组成
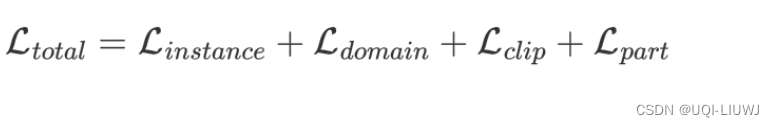
2.3.1 实例级对比
- 和之前的经典对比学习任务是类似的,在实例级特征上进行实例对比学习
- 在不同数据增强下的同一个样本的两个实例级特征和其他样本的实例级特征间进行正负样本判别

2.3.2 域级对比(时间域+空间域)
- 论文认为不管时间域还是空间域都是同一样本的不同表示,应有相同的高级语义信息,可以用来相互作为监督信号,所以将它们看作互为正样本。
- 使用跨域的对比方法,是希望时间域和空间域特征在嵌入空间中尽可能接近
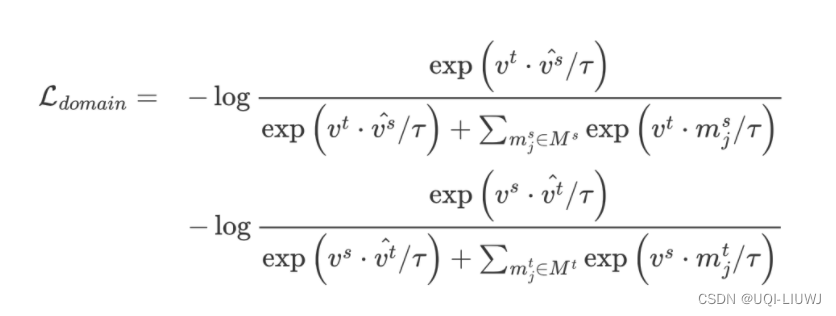
2.3.3 片段级和部件级对比
- 在片段级和部件级上,不同粒度特征也类似地应有相同的高级语义信息,互为正样本。
- 由于不同粒度的特征数量较多,作者做了简化处理,将最小粒度的特征(L=1)作为 query 去匹配其他样本。
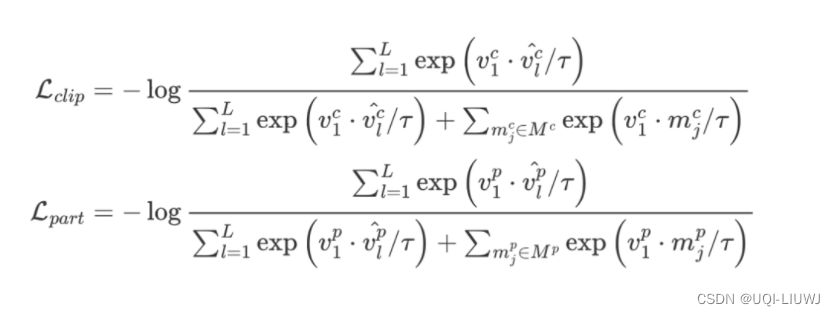
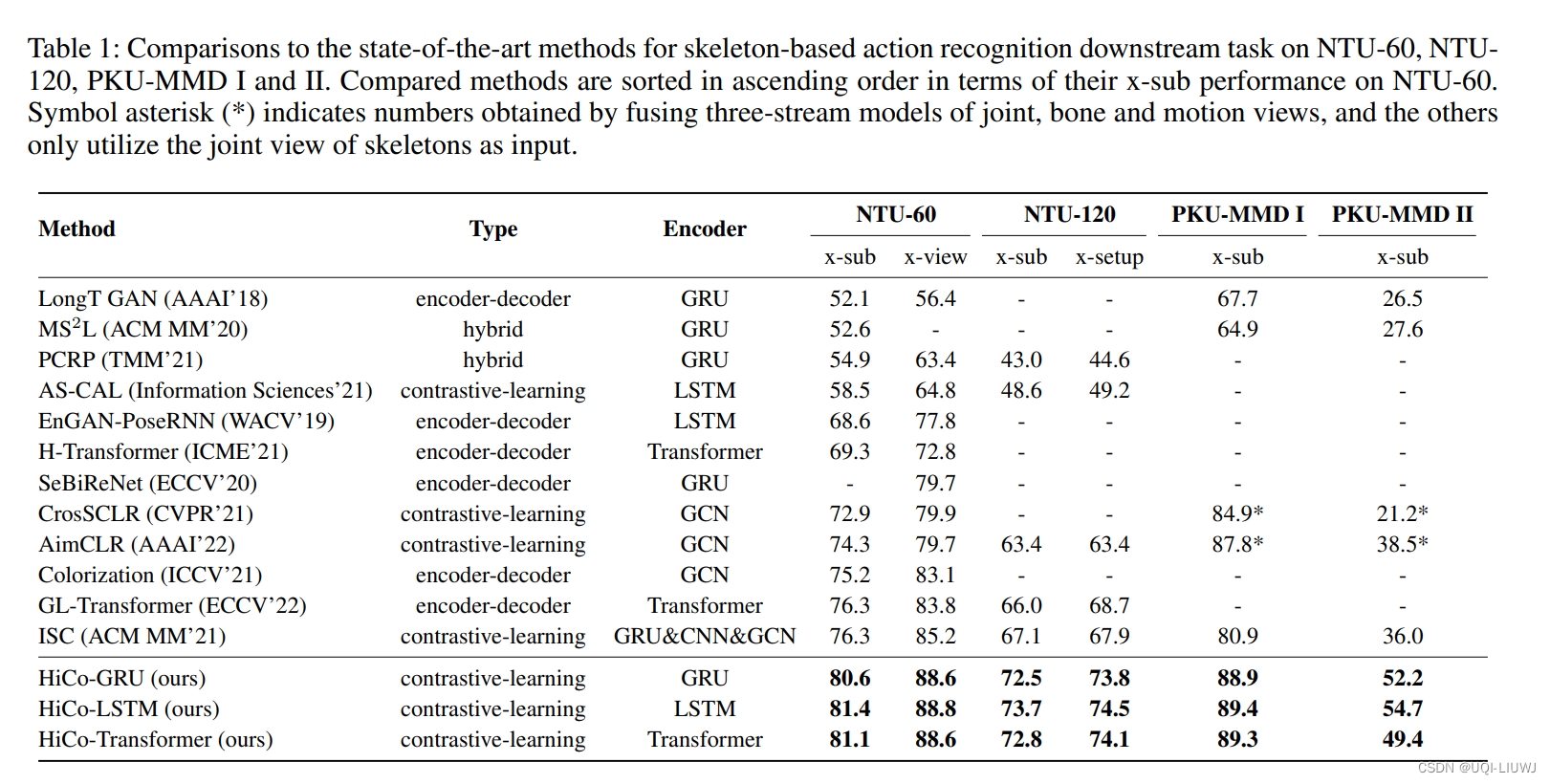
3 实验
















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











