







前言
Qwen3发布后4小时内GitHub获1.7万星标,刷新开源大模型热度纪录。本篇文章将以transformers调用的方式快速进行Qwen3调用。
下载相关依赖
需要安装accelerate、torch和transformers
下载accelerate
pip install accelerate
下载torch
读者需要根据自己的驱动版本和系统配置在torch官网下载合适的下载命令
torch链接:https://pytorch.org/get-started/locally/

下载transformers
这里要求transformers的版本要大于等于4.51.0
下载模型
笔者不建议直接区huggingface上下载,这样会很慢,建议在huggingface镜像或者modescope上下载。由于笔者习惯使用git方式下载,本篇中使用hf-mirror下载。
hf-mirror链接:https://hf-mirror.com/
搜索qwen3
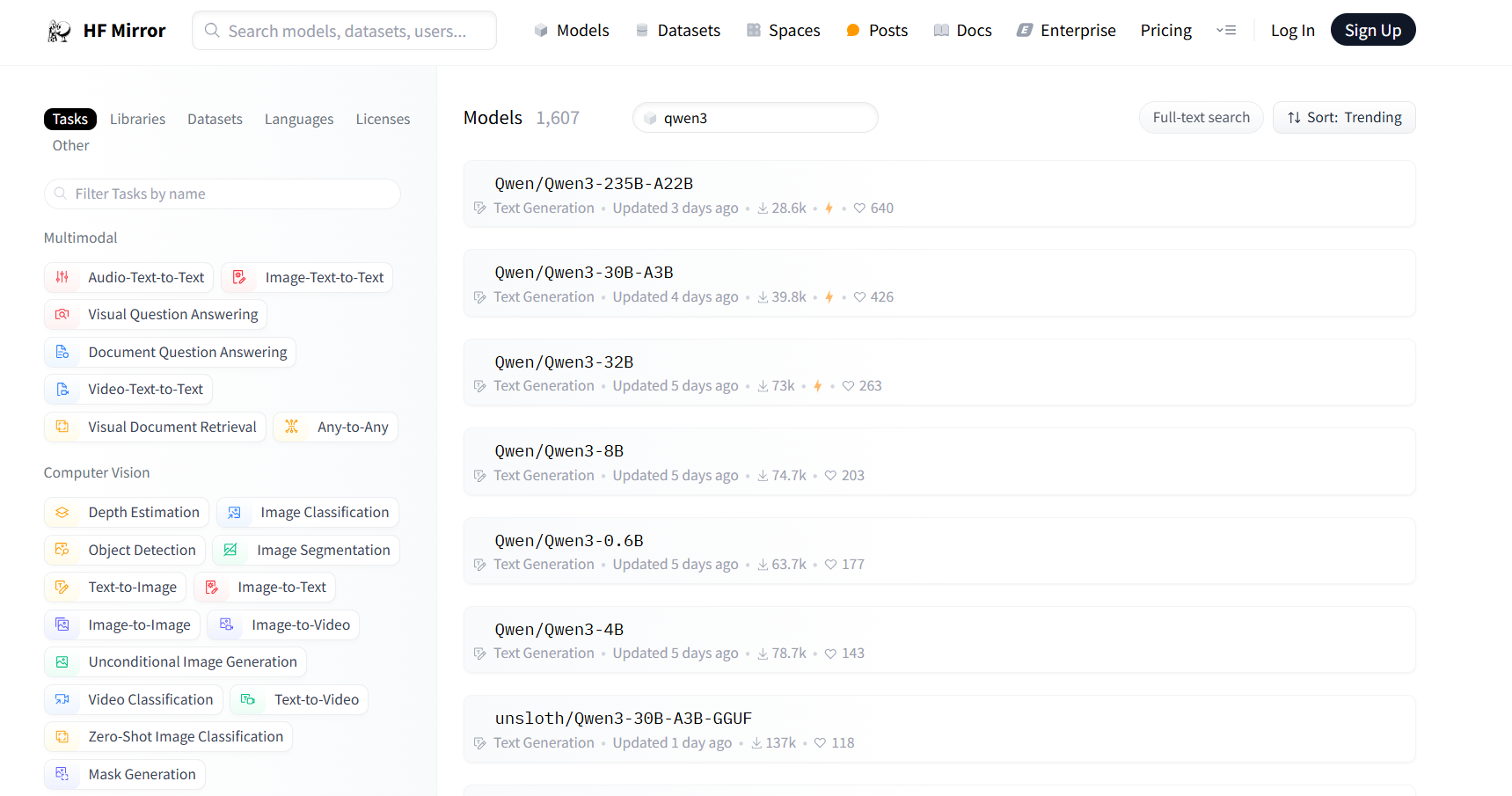
Qwen3放出来八个模型,密集型模型有Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B、Qwen3-32B,多专家模型有Qwen3-30B-A3B、Qwen3-235-A22B。
密集型模型的大小很好理解,B表示10亿参数,4B的意思就是40亿参数。多专家模型的大小由总参数与激活参数决定,30B-A3B表示一共有30B参数,运行时激活3B参数。
参数与对应配置的参考如下表:
| 模型 | 显存 | 内存 |
|---|---|---|
| Qwen3-0.6B | 1GB+ | 4GB+ |
| Qwen3-1.7B | 2GB+ | 8GB+ |
| Qwen3-4B | 8GB+ | 16GB+ |
| Qwen3-8B | 14GB+ | 16GB+ |
| Qwen3-14B | 24GB+ | 32GB+ |
| Qwen3-32B | 58GB+ | 64GB+ |
| Qwen3-30B-A3B | 55GB+ | 64GB+ |
| Qwen3-235-A22B | 350GB+ | 512GB+ |
笔者在这里选择4B的模型
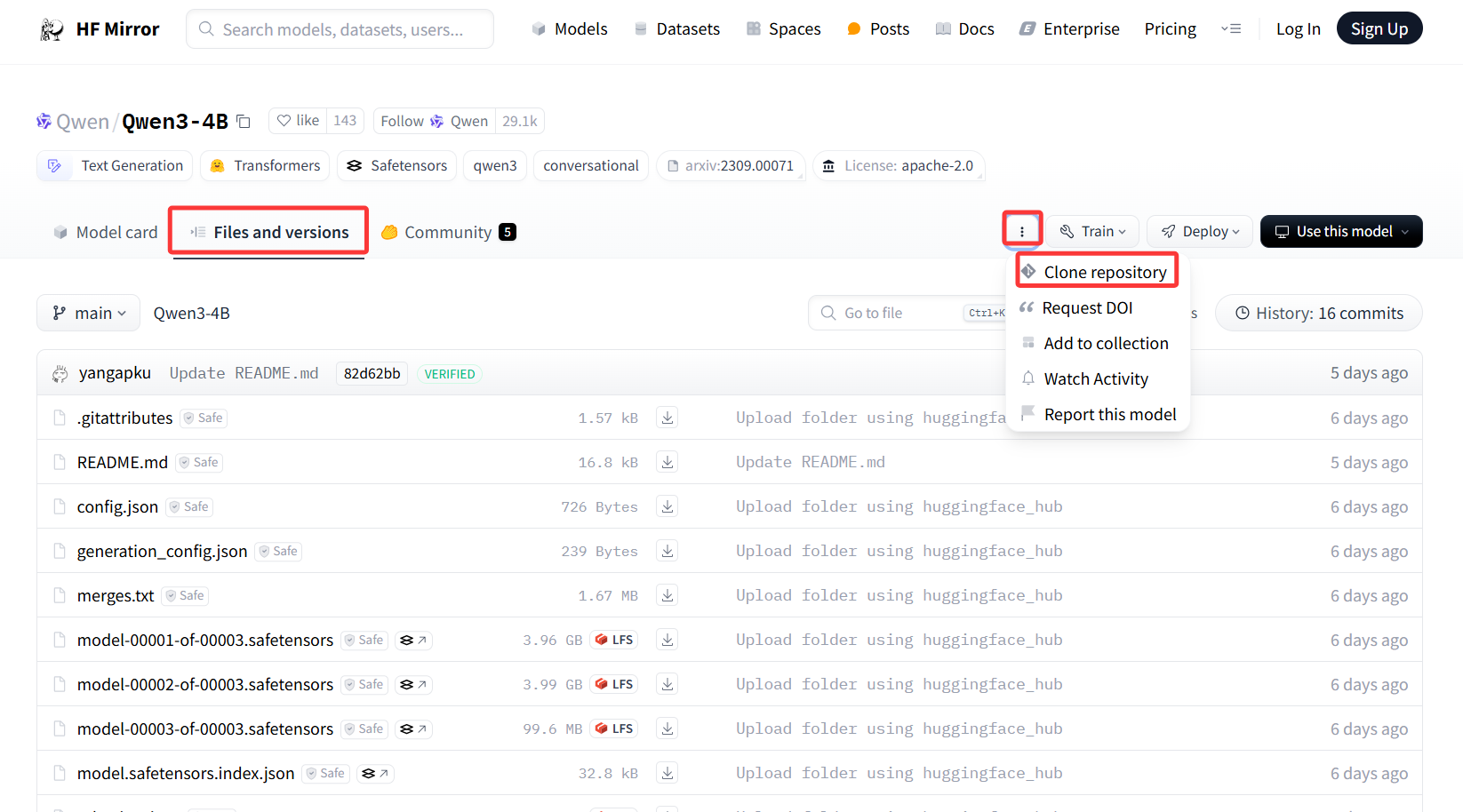
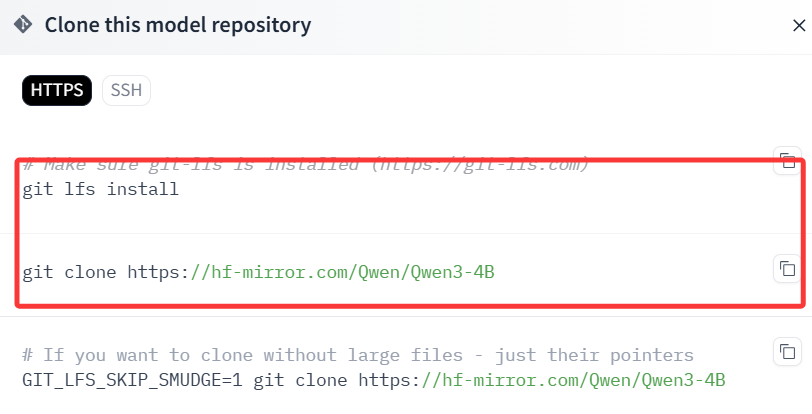
切换到本地模型保存目录,然后命令行运行以下两条命令,等待执行结束即可
代码
导入包
from transformers import AutoModelForCausalLM, AutoTokenizer
导入模型与分词器
model_name是笔者保存模型文件的路径,使用AutoTokenizer加载分词器,AutoModelForCausalLM加载模型。
model_name = r"D:\alpha_ordered\MyCodeBase\Large Model\LLM\huggingface_model\Qwen3-4B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
词嵌入
prompt是用户要询问大模型的问题,messages是符合大模型对话格式的输入形式
prompt = "给出一个关于大语言模型的简短介绍"
messages = [
{"role": "user", "content": prompt}
]
# 词嵌入过程
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True, # 封装在提示词模板里,所有模型默认,function calling功能也依赖提示词模板
enable_thinking=True, # 是否启动思考模式,也是通过修改提示词模板实现
)
print("model device:", model.device)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
创建并回复
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
运行结果
Loading checkpoint shards: 100%|██████████| 3/3 [00:06<00:00, 2.00s/it]
Some parameters are on the meta device because they were offloaded to the cpu.
model device: cuda:0
thinking content: <think>
好的,用户让我给出一个关于大语言模型的简短介绍。首先,我需要明确用户的需求是什么。他们可能是在准备一个演示、写一篇简短的说明文,或者只是想了解大语言模型的基本概念。不管怎样,用户需要的是简洁明了的介绍,不能太复杂,也不能遗漏关键点。
接下来,我得考虑大语言模型的核心要素。首先,大语言模型(LLM)是基于深度学习的,特别是Transformer架构。然后,它们通过大量文本数据进行训练,能够理解和生成人类语言。应用方面,比如文本生成、问答、编程等。还有它们的规模,参数量大,比如像GPT-3、BERT这样的模型。
不过用户要的是简短的介绍,所以需要把重点放在定义、特点、应用上。可能还需要提到它们的训练方式,比如自监督学习,或者使用大量数据。另外,可能需要提到它们的用途,比如辅助工作、创作内容等。
还要注意避免使用过于专业的术语,保持易懂。比如,可以解释一下Transformer架构,但可能不需要太深入。另外,可能需要提到它们的局限性,比如在特定领域可能不够准确,或者需要大量计算资源。
但用户没有特别提到局限性,所以可能不需要包括。不过简短介绍里是否需要提到呢?可能不需要,因为用户可能只需要基本的定义和用途。所以重点放在定义、技术基础、应用场景上。
然后检查有没有遗漏的关键点。比如,大语言模型的训练数据量大,参数量大,能够处理多种任务,支持多语言等。这些都需要简要提及。
现在组织语言,确保句子连贯,信息准确。比如:“大语言模型是基于深度学习的AI系统,通过大量文本数据训练,能够理解和生成自然语言。它们基于Transformer架构,具备强大的文本生成、问答和编程能力,广泛应用于内容创作、智能助手等领域。” 这样是否足够?
可能需要更详细一点,比如提到自监督学习,或者参数量的规模。但用户要求简短,所以可能需要平衡。例如:“大语言模型是基于Transformer架构的深度学习模型,通过海量文本数据训练,具备强大的自然语言理解和生成能力。它们可应用于文本生成、问答、编程等任务,广泛用于内容创作、智能助手等领域。”
这样应该更全面,同时保持简洁。检查有没有冗余,是否符合用户的要求。可能用户需要更简短,所以再缩短一点:“大语言模型是基于Transformer架构的深度学习模型,通过大量文本数据训练,能理解和生成自然语言,广泛应用于文本生成、问答、编程等领域。”
这样更简短,但可能信息量足够。需要确保关键点都涵盖:架构、训练方式、能力、应用。这样应该可以满足用户的需求。
</think>
content: 大语言模型(LLM)是基于Transformer架构的深度学习系统,通过海量文本数据训练,具备强大的自然语言理解和生成能力。它们可处理多语言、多任务,广泛应用于文本创作、问答、编程、翻译等领域,是当前AI技术的重要突破方向。
可以留意一下以下提示,说明高版本的transformers已经具备了将一部分模型参数卸载到cpu中的能力了,这也就意味着,同样的显存下,可以尝试跑更大的模型



















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











