






最近由华东师大和香港大学联合提出了一种面向大语言模型推理的幻觉缓解方法Chain-of-Knowledge被ACL2024接收
最近这两年,诸如GPT-4、LLaMA3等一系列超百亿规模的大语言模型相继提出,这些大模型以其大规模参数、大规模语料和大规模算力为基础,展现出了极为强大的语义理解和推理生成能力。
为了更好地引导大语言模型完成复杂任务的推理,一些面向大模型提示工程被相继提出,包括Chain-of-Thougt(CoT)、Self-Consistency、Program-of-Thought(PoT)、ReAct等。在这些提示工程的引导下,大模型可以遵循一定的模式完成问题的理解、规划、推理和解答。
不过即便如此,大语言模型在推理过程中依然会存在幻觉,这通常表现在对问题的规划和推理步骤存在事实性错误或逻辑错误。为此,如何能够识别并纠正这些错误对缓解大模型幻觉问题具有重大价值。
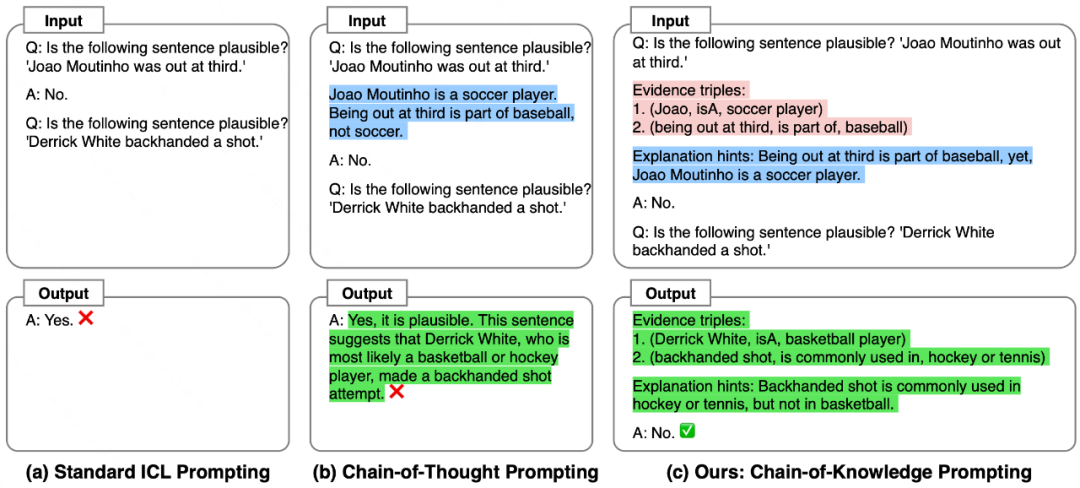
例如如上图所示,传统的推理方法是构造若干Input-Output Pair,从而大模型可以遵循这样的模式进行生成;CoT则在此基础上增加了推理路径,实验和理论发现CoT可以很好地提高大模型的推理能力。不过在实际使用中,依然会存在一些错误,这通常是因为大模型对目标问题存在没有掌握的知识,使得其在某个具体的推理步骤上犯错。
为了提高大模型的推理能力,缓解幻觉问题,本文从三个方面进行了改进。
提示工程:Chain-of-Knowledge Prompting
既然CoT存在一定的不足,那么就先从最简单的提示工程出发。回到刚才的图,我们发现大模型在回答问题时,虽然CoT可以在形式上约束大模型要给出推理步骤,但是由于这种推理步骤是以自然语言形态表达,大模型很有可能会生成出错误的中间结果,而自然语言文本模态的中间步骤很难判断其正确与否。
为此,作者尝试增加一项约束,即让大模型给出明确的推理证据三元组(Evidence Triple)。类似于知识图谱中的三元组,每个三元组由Subject、Relation和Object组成,描述一个推理过程则可以用若干个三元组组成,如以下例子:
假设问题:“乔丹为什么被认为是篮球史上最伟大的球员之一?” 传统的CoT方法可能会生成自然语言的推理步骤,但可能会遗漏关键证据或包含错误信息。使用CoK方法,模型会生成如下证据三元组:
-
(迈克尔·乔丹,获得,6次NBA总冠军)
-
(迈克尔·乔丹,获得,5次常规赛MVP)
-
(迈克尔·乔丹,影响了,篮球的全球推广)
通过这种结构化的表达,我们可以发现可以较好地提高推理能力。因为,大模型产生幻觉通常会因为长篇大论的文本解释从而出错,而显式地给出依据则会间接约束大模型不能用模糊的解释来蒙混过关。
幻觉度量
不过,虽然通过CoK提示工程的引导,还是没有办法100%的避免幻觉问题。为此,我们需要找到这些可能错误错误的推理步骤,并尝试纠正他们。
一般地,不论是常识推理还是符号推理,虽然可以通过最终大模型预测的答案来判断其推理过程中间是否可能出错,但是想具体定位到错误的步骤是比较困难的。为此,我们借助CoK提示的结构,尝试将其与外部知识库进行对齐。
给定一个Prompt和大模型给出的CoK推理路径(包括文本模态的推理路径,和结构化的推理路径)。作者提出两个度量方式:
-
基于忠实性的幻觉度量:忠实性是指大模型生成的结果与其输入的事实一致性,通常应用在文本摘要、机器翻译等场景。对于推理中,则表示当前推理步骤是否与上下文存在关联。先前一些工程采用类似自然语言推断(NLI)的形式来度量忠实性,作者则采用预训练的SimCSE来作为衡量指标。
-
基于事实性的幻觉度量:大模型出现错误的另一个原因是某个步骤产生了事实错误,换句话说,其给出的某个推理三元组可能是错误的。为此,作者采用TransR等知识表示学习方法来估计每个证据三元组的正确与否,对于错误的三元组,其对应的得分会低于某个阈值,从而可以推断其是错误的。
Rethinking策略
如果对于一个Prompt,大模型生成的推理步骤经过两个幻觉度量之后被认为存在错误,那么就需要对其进行纠正。作者借鉴了目前的RAG思想,尝试通过对外部知识进行检索增强的形式来提高其在某一个错误的推理步骤上的准确性。
但不同于RAG的是,Rethinking算法则是先基于忠实性和事实性度量指标找到错误的推理三元组,其次对这部分三元组检索外部知识库并实现知识增强,最后基于增强的知识以及原先错误的信息提示大模型进行自我反思,并重新规划和思考当前的问题。整个过程不断迭代直到通过幻觉度量。
整个框架的结构如下图所示:
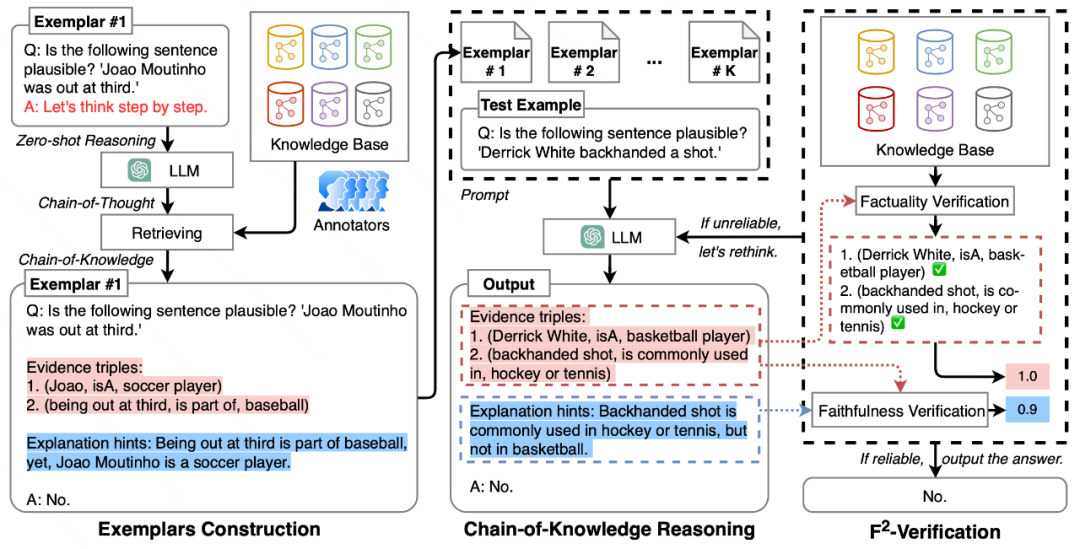
(1)提示工程 提示工程中,直接采用CoT编写的提示作为文本模态推理路径。同时也采用Zero-Shot CoT的方法构造一些推理路径。为了得到这些exemplar的结构化证据三元组,作者采用人工标注的方法实现,为了确保证据链的准确性,在标注过程中会参考现有的知识图谱,以保证推理过程是准确无误的。
(2)幻觉度量 幻觉度量的得分范围为0-1。0分表示完全错误,1分表示完全正确。这里针对不同的数据集会在验证集上挑选合适的阈值。
(3)再思考算法 大模型会接收到幻觉度量的反馈结果,包括具体到每个推理步骤的正确与否信息。对于错误的证据三元组,会对其检索外部知识库里寻找最有可能正确的三元组,并以提示的形式在下一轮大模型回答时作为增强。这里需要强调的是,只针对错误的推理步骤进行知识检索,而不会将正确答案泄漏给大模型。以下为一个直观的例子:
设想模型被问到:“爱因斯坦发明了电灯吗?” 初始回答可能是:
-
证据三元组:(爱因斯坦,发明了,电灯)
解释: 爱因斯坦发明了电灯,所以答案是“是的”。
经F²验证,发现第一条证据与事实不符。于是,从知识库中检索到正确的证据:
- (托马斯·爱迪生,发明了,电灯)
将正确的证据注入提示后,模型重新生成回答:
- 新的证据三元组:
-
(爱因斯坦,是,物理学家)
-
(托马斯·爱迪生,发明了,电灯)
- 解释: 电灯是由托马斯·爱迪生发明的,而爱因斯坦是著名的物理学家,所以答案是“不是”。
新的回答通过了F²验证,成功纠正了模型在常识推理中的错误
实验
作者在包括常识与事实推理、算术推理和符号推理等任务上进行了实验。挑选了包括text-davinci-002、gpt3.5-turbo和gpt-4作为大模型基座。实验总体结果如下:

实验结果呈现出CoK可以较好地在绝大多数任务上超越基线和SOTA。同时在Self-Consistency的增强下可以提高超过3%的准确率。
在BoolQ和CSQA上进行实验来验证再思考算法的收敛性,可发现大多数情况下大模型可以在第3轮回答正确。

通过观察一些Case,可以发现在CoK的提示下,大模型可以生成出结构化的推理路径,并能够在再思考算法的增强下不断地提高准确性。

未来展望
-
应用拓展: CoK方法有望应用于法律推理、医学诊断等需要复杂推理的场景,提升模型在专业领域的应用价值。
-
实时知识更新: 外部知识库可以被扩展为实时的搜索引擎,为模型提供最新的知识支持,进一步提高推理的准确性和时效性。
总结
该研究开创性地将结构化的知识证据引入大语言模型的推理过程中,提供了一种有效缓解幻觉问题的新途径。通过明确的证据三元组和针对幻觉的度量与纠正机制,模型的推理过程变得更加透明和可靠。这一方法不仅适用于当前的大模型,也为未来更复杂的推理任务提供了宝贵的参考。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









