






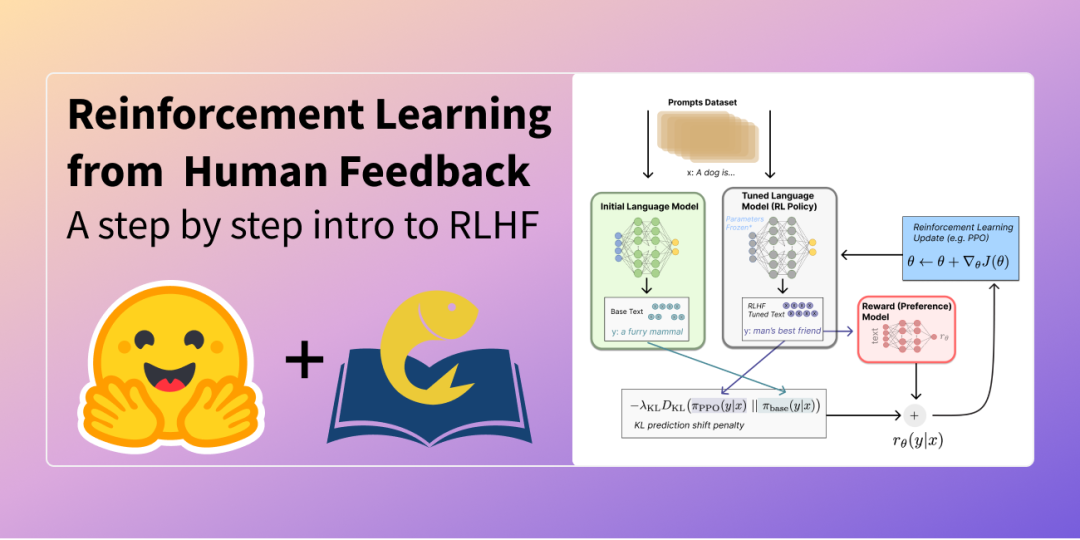
RLHF
随着大型语言模型(LLM)的快速发展, 如何使这些模型更好地理解和满足人类的需求成为了一个关键问题 。传统的训练方法往往依赖于 大规模的语料库和基于规则的损失函数 ,但这在处理复杂、主观和依赖上下文的任务时存在局限性。因此, 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF) 应运而生,为模型的训练提供了一种新的思路。
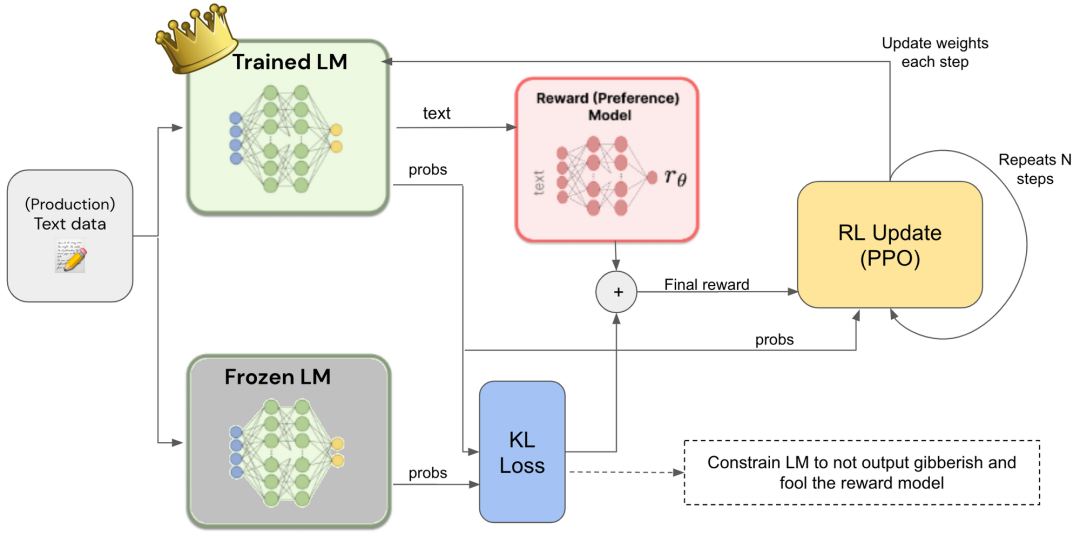
RLHF
一、RLHF的框架
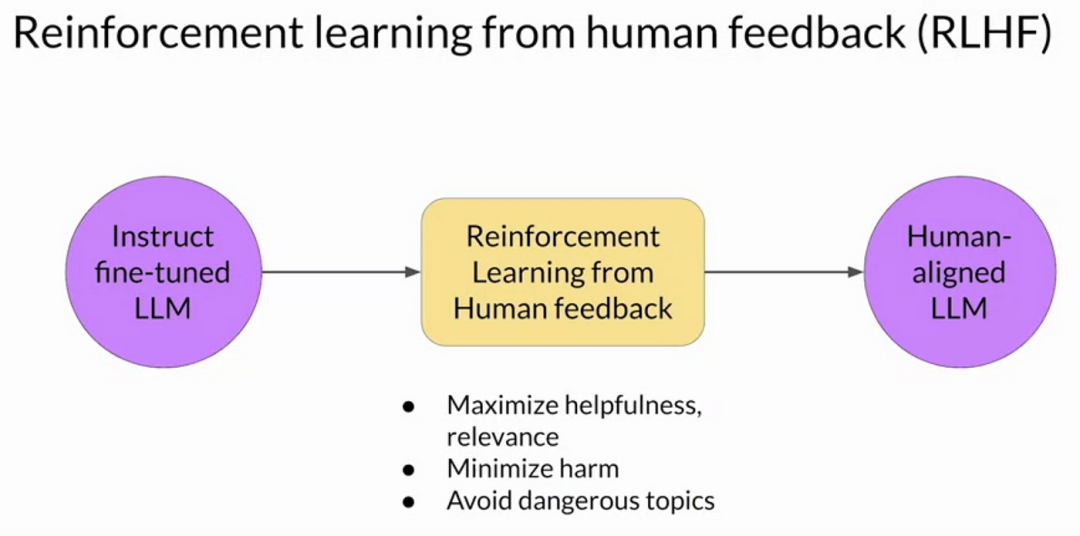
什么是RLHF?基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),RLHF是一种将人类反馈与强化学习相结合的方法,旨在通过引入人类偏好来优化模型的行为和输出。
在RLHF中,人类的偏好被用作奖励信号,以指导模型的训练过程,从而增强模型对人类意图的理解和满足程度。这种方法使得模型能够更自然地与人类进行交互,并生成更符合人类期望的输出。
RLHF
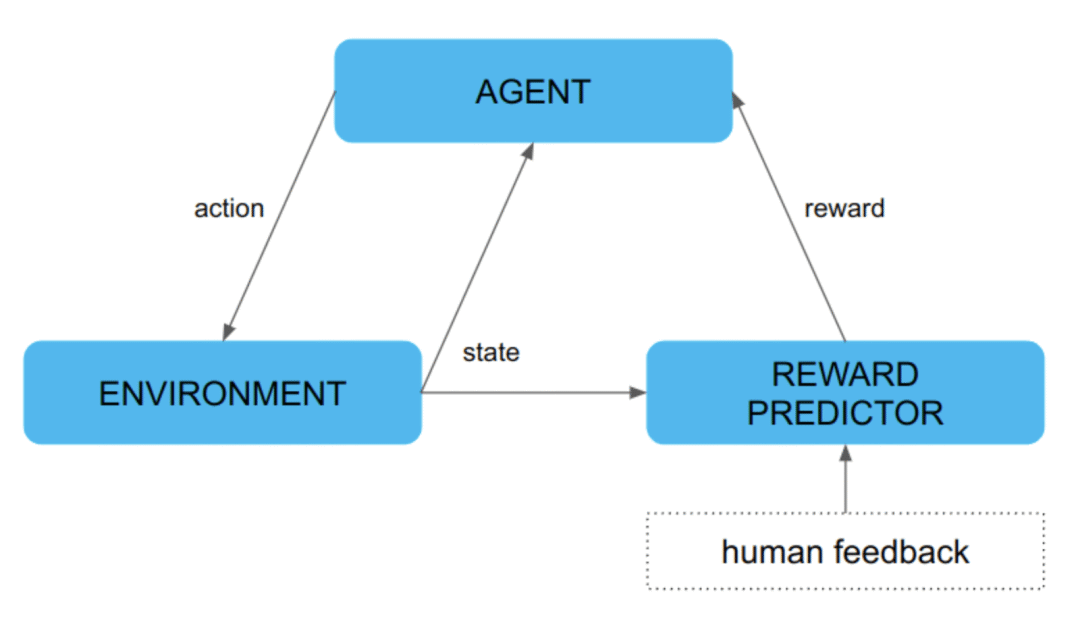
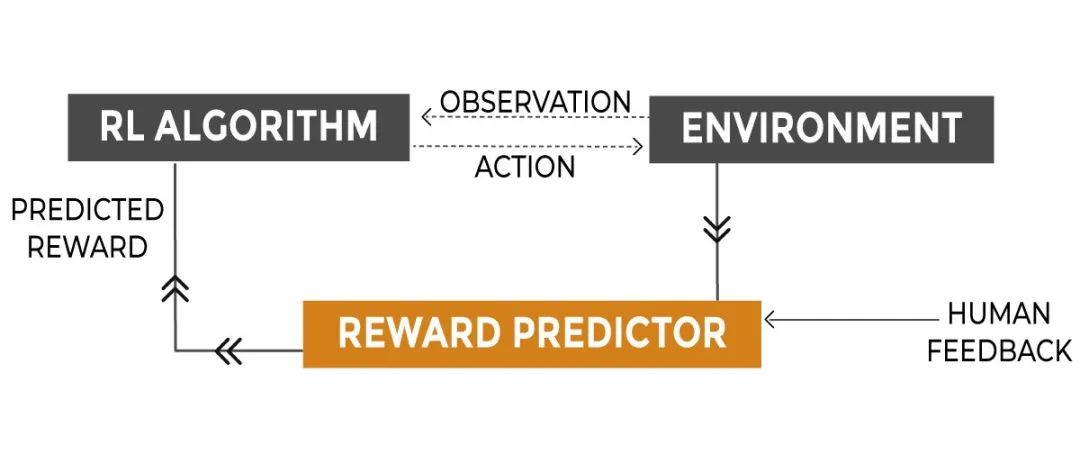
RLHF的框架是什么?基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)框架是一个复杂但高效的系统,包括强化学习算法、行动、环境、观察和奖励机制。
1. 强化学习算法(RL Algorithm)
在RLHF框架中,常用的强化学习算法之一是近端策略优化(Proximal Policy Optimization, PPO)。PPO是一种用于训练代理的“on-policy”算法,它直接学习和更新当前策略,而不是从过去的经验中学习。
2. 行动(Action)
在RLHF框架中,行动指的是语言模型根据给定的提示(prompt)生成的输出文本。这些输出文本是模型在尝试完成特定任务或响应特定指令时产生的。行动空间(Action Space)是词表所有token(可以简单理解为词语)在所有输出位置的排列组合。
3. 环境(Environment)
在RLHF中,环境是代理(即我们的语言模型)与之交互的外部世界,它提供了代理可以观察的状态、执行的动作以及根据这些动作给予的奖励。
-
状态空间(State Space):这是环境可能呈现给代理的所有可能状态的集合。在RLHF中,状态通常对应于输入给模型的提示(prompt)或上下文信息。
-
动作空间(Action Space):这是代理可以执行的所有可能动作的集合。在RLHF中,动作对应于模型生成的输出文本,即模型根据输入提示生成的响应。
-
奖励函数(Reward Function):这是一个根据代理在环境中的行为(即生成的输出)来分配奖励的函数。在RLHF中,奖励函数通常不是直接给出的,而是通过训练一个奖励模型来预测的,该奖励模型能够基于人类反馈来评估不同输出的质量。
4. 观察(Observation)
在RLHF框架中,观察指的是 模型在生成输出文本时所接受到的输入提示(prompt) 。这些提示是 模型尝试完成任务的依据,也是模型进行决策和行动的基础 。观察空间(Observation Space)是可能输入的token序列,即Prompt。
5. 奖励机制(Reward)
奖励机制是RLHF框架中的核心组成部分之一。它基于奖励模型对人类偏好的预测来给予模型奖励或惩罚。它需要使用大量的人类反馈数据来进行训练**,以确保能够准确地预测人类对不同输出的偏好。这些数据通常通过让标注人员对模型生成的输出进行排序、打分或提供其他形式的反馈来收集。
二、RLHF实战:InstructGPT训练的3个阶段
如何使用RLHF进行InstructGPT模型训练?三个阶段共同构成了InstructGPT的训练过程,通过收集描述性数据和比较性数据**,并分别训练监督学习模型和奖励模型,最后利用PPO强化学习算法对奖励模型进行优化,从而训练出能够生成高质量、符合人类偏好输出的InstructGPT模型(ChatGPT的前身)。**
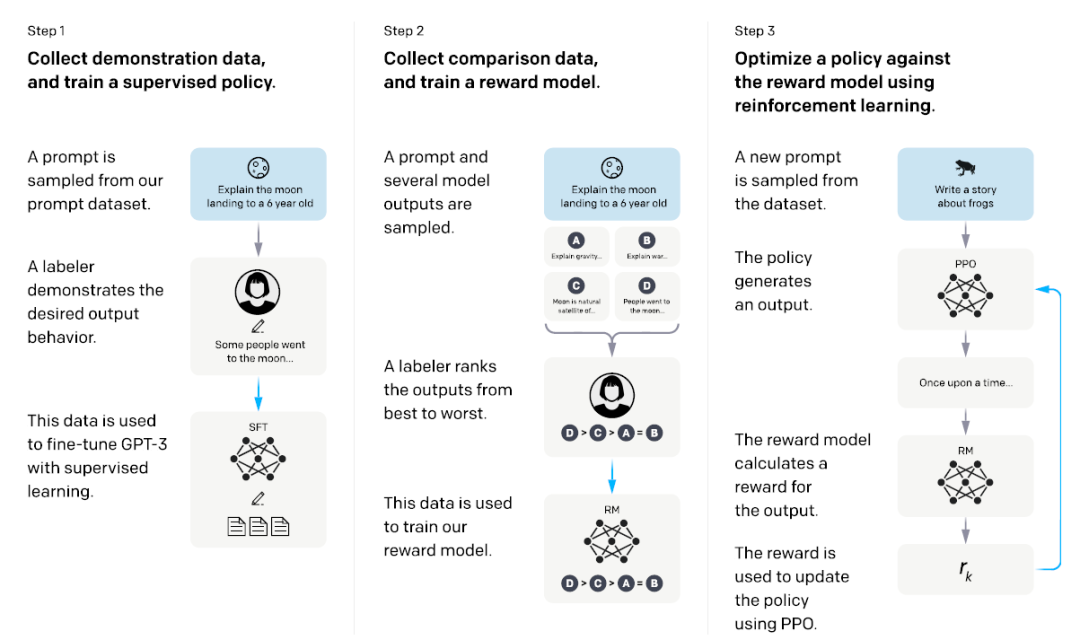
第一步:收集描述性数据,并训练一个监督学习模型
-
从prompt数据集中采样出一部分数据。
-
标注员根据要求为采样的prompt编写答案,形成demonstration data。
-
利用这些标注好的数据来微调GPT-3模型,训练出一个监督学习模型。
关键术语:
-
Supervised Fine-Tuning(SFT): 有监督微调,即使用描述性数据来微调GPT-3模型。
-
Demonstration Data: 描述性数据,由标注员为prompt编写的答案。
第二步:收集比较性数据,并训练一个奖励模型
-
从prompt数据库中取样,并得到数个模型的答案。
-
标注员为模型的多个输出进行打分或排序,这些输出是基于同一prompt生成的。
-
利用这些打分或排序数据来训练一个奖励模型(Reward Modeling,RM),该模型能够预测人类对不同输出的偏好分数。
关键术语:
-
Reward Modeling(RM): 奖励模型,用于预测人类对不同输出的偏好分数。
-
Comparison Data: 比较性数据,由标注员对模型输出的打分或排序构成。
第三步:用PPO强化学习算法对奖励模型进行优化
-
从prompt数据库中另外取样。
-
由监督学习初始化PPO模型。
-
模型给出答案。
-
奖励模型对回答打分。
-
获得的分数通过PPO算法优化模型。
关键术语:
-
Proximal Policy Optimization(PPO): 近端策略优化算法,一种用于强化学习的策略优化方法。
-
Reinforcement Learning from Human Feedback(RLHF): 基于人类反馈的强化学习,是InstructGPT训练过程中的核心方法。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









