






前言
我们知道,阿里的通义千问素来被称为AI届的“汪峰”….
Qwen2.5发布时赶上了DeepSeek 爆火。
被誉为200B以内无敌的QWQ-32B开源又撞车被各大自媒体吹爆的Manus…
当昨天知道晚上Qwen3要发布时,期待中还有一丝丝兴奋,这次又会杀出哪个程咬金…
昨天晚上,除了Qwen3,AI圈很安静,阿里终于如愿抢到了头条。
朋友圈很多小伙伴一夜无眠。
当然,作为国内首个混合推理模型,Qwen3释放的信息也足够震撼,我们可以跟随一夜无眠的甲木老师的分析一睹究竟…
背景
阿里,直接扔下了一颗“核弹”——新一代通义千问大模型 Qwen3,发布即全系列开源!

你没听错!是 全!系!列!开!源! 而且性能直接冲上全球最强开源模型的王座,把之前大家热议的一众好手都甩在了身后。
我知道,这时候你心里肯定嘀咕开了:
“哇,这么牛?那得多少钱?”
“是不是又得顶级显卡才能跑?”
“跟我这样的普通人有关系吗?”
问得好!这正是甲木今天要跟你掰扯清楚的。
这波阿里,是真·格局打开了!
Qwen3 不仅能力得到极大提升,而且 极其开放,非常亲民,甚至可以说是给咱们普通开发者、AI 爱好者量身打造的超级武器!
太卷了,这次我们来看看这次Qwen3准备了些什么,
看看它到底牛在哪里?我们普通人又能用它解锁哪些“骚操作”,甚至,搞点钱?😉 Let’s GO!

Qwen3 横空出世
咱们先明确一点,Qwen3 不是简单地在模型列表里+1。
它的出现,带着几个足以搅动整个 AI 江湖的“杀手锏”:
1. 开源!开源!开源!重要的事情说三遍!而且是发布即巅峰!
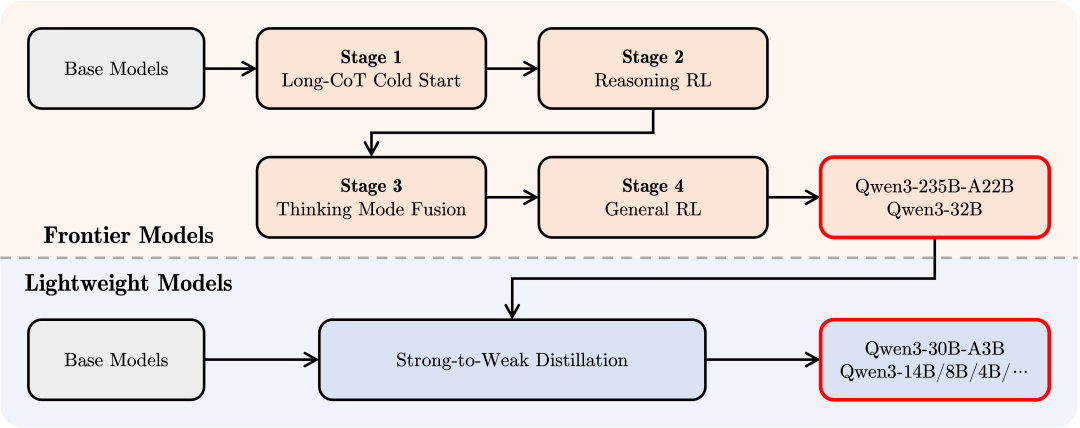
这可能是 Qwen3 最让人兴奋的一点。从参数量 0.6B 的“小不点”到 235B 的“巨无霸”,总共 8 款不同尺寸的模型,全部采用宽松的 Apache 2.0 协议开源。
这意味着什么?
- 免费! 你可以免费下载、使用这些模型。
- 可商用! 没错,你可以用 Qwen3 来开发商业产品,去搞钱!💰
- 开放! 你可以在魔搭社区 (ModelScope)、Hugging Face 这些主流平台上直接把它“抱”回家。
 huggingface
huggingface
想想看,当很多顶级模型还藏着掖着,或者只提供 API 调用的时候,
阿里直接把看家本领开源出来,让所有人都能用上、研究、改进。
这种魄力,这种对技术共享的承诺,推动整个行业进步的姿态,甲木必须先点个大大的赞!👍
2. 国内首个“混合推理”模型:既能闪电快打,又能深思熟虑!
这个“混合推理”(Mixed Inference)机制,是 Qwen3 的一大技术亮点,也是非常实用的创新。
过去我们用大模型,经常会遇到两难:要么模型太大,回答个简单问题也慢吞吞、费资源;要么模型太小,速度是快了,但遇到复杂问题就“智商下线”。
Qwen3 说:小孩子才做选择,成年人全都要!
它原生支持两种工作模式:
- 非推理模式 (默认): 面对简单问题,比如“今天天气怎么样?”或者快速提取信息,它能像个反应敏捷的小助理,“嗖”地一下给出答案,快、准、省资源!
- 推理模式 (Thinking Mode): 遇到复杂任务,比如让你写一份详细的商业计划分析,或者进行多步骤的逻辑推理,你可以“命令”它开启“深度思考”。这时,它会像个严谨的科学家,一步步推导,进行深度分析,确保结果的精准和严谨。
怎么切换呢?简单!可以通过 enable_thinking=True/False 这样的参数硬开关控制,甚至在对话中用 /think 或 /no_think 这样的指令进行软切换。
更牛的是,阿里攻克了技术难关,让 Qwen3 在这两种模式间切换时几乎不损失性能,真正做到了 “一脑双模,稳定输出” 。
这个特性对我们普通用户和开发者意味着什么?效率和质量的双重提升!
简单任务不浪费时间,复杂任务有保障!后面讲 Agent 的时候,你会更能体会到这个“混合推理”的威力。
3. 为 Agent 时代而生:它不只想“聊”,更想“干”!
甲木一直在关注 AI Agent(智能体)的发展,坚信这是 AI 落地的下一个浪潮。Qwen3 的设计,明显就是冲着 Agent 时代去的。
它原生支持强大的工具调用 能力,能灵活地调用外部 API 或工具来完成任务(比如查天气、订机票、操作软件)。同时,它还原生支持 MCP 协议,这是构建复杂、协作型 Agent 的关键。
结合前面提到的“混合推理”能力,Qwen3 不再仅仅是一个“问答机器”,它更像是一个拥有强大思考和执行能力的大脑,是构建能够“边想边干”、真正帮我们解决问题的 AI Agent 的理想基石。
这四个核心亮点,勾勒出了 Qwen3 的基本面貌:
「强大、开放、高效、面向未来」
它不仅仅是阿里秀肌肉,更是给整个 AI 社区,尤其是国内的开发者和用户,送来的一份厚礼。
Qwen3 模型家族全家桶
这次阿里一口气开源了 8 款 Qwen3 模型,覆盖了从 0.6B 到 235B 的超广参数范围。这就像一个庞大的“航母战斗群”,既有灵活的护卫舰,也有战力爆表的航母。咱们来看看这个家族的主要成员:
家族构成:
-
6 款 Dense 模型 (稠密模型):
这些是传统的稠密型模型,参数量相对较小或中等,适合不同层级的应用和部署需求。
-
- Qwen3-0.6B
- Qwen3-1.7B
- Qwen3-4B
- Qwen3-8B
- Qwen3-14B
- Qwen3-32B
-
2 款 MoE 模型 (混合专家模型):
-
- Qwen3-30B-A3B: 总参数量 30B,但每次推理只需激活约 3B 参数。性能堪比之前的 Qwen2.5-32B,但实现了10 倍以上的性能杠杆!这是什么概念?更低的计算成本,更高的效率!
- Qwen3-235B-A22B (旗舰版): 总参数量 235B,每次推理只需激活约 22B 参数。这就是前面提到的性能怪兽,全球开源模型的巅峰之作!
划重点!几个明星模型解读:
-
Qwen3-235B-A22B (旗舰版):
-
- 优点: 性能天花板,各项指标全球领先。MoE 架构使得虽然总参数量巨大,但实际计算量远低于同等参数的 Dense 模型。
- 部署成本: 据说,部署成本仅为同等性能的 DeepSeek-R1 的 35% !只需要 4 张 H20 GPU 就能实现本地部署(当然,H20 也不便宜,但相比动辄几十上百张卡的模型,已经非常友好了)。
- 适合: 对安全性有要求、对性能有极致要求的企业级应用、科研探索。
-
Qwen3-30B-A3B:
兄弟们!这意味着什么?我们终于可以在自己的游戏本、台式机上,跑起来一个性能强劲的“准大模型”了!这简直是广大开发者和 AI 爱好者的福音!本地部署大模型的门槛,真的被打下来了!
-
- 适合: 个人开发者、AI 爱好者本地部署、对性能和成本有均衡要求的场景。
-
- 优点: MoE 架构带来的高效率!用 3B 的激活参数实现了接近 32B Dense 模型的性能。
- 杀手锏: 官方明确提到,这款模型适用于消费级显卡部署!
-
Qwen3-32B (Dense 模型):
-
- 优点: 作为 Dense 模型中的“大杯”,性能同样非常强劲,是很多本地部署用户的热门选择。
- 部署: 根据官方建议和社区经验,本地部署这款模型通常需要 较高的显存(具体数值需要根据量化情况等确定,但肯定比 30B MoE 要求高)。
- 适合: 拥有较好硬件条件、需要稳定高性能输出的开发者和用户。
-
Qwen3-0.6B:
-
- 优点: 小巧玲珑,资源消耗极低。
- 适合: 手机、平板等端侧设备部署,或者作为轻量级任务的处理核心。
“我该用哪个版本?” 甲木给你指指路:
- 只想尝鲜,快速体验? -> 直接用官方通义 App 或网页版
https://chat.qwen.ai/,背后就是 Qwen3 的顶配版本在支撑,响应快,适合日常问答、写文案等轻量场景。 - 想在自己电脑上跑,搞点开发? -> 优先考虑 Qwen3-30B-A3B!如果你的显卡给力(比如有 24G 或更高显存),Qwen3-32B 也是不错的选择。当然,更小的模型如 8B、14B 也可以根据你的硬件和需求选择。
- 开发严肃应用,需要 API 调用? -> 阿里云百炼平台提供了 API 服务,可以根据你的业务需求选择合适的模型尺寸。
- 追求极致性能,不差钱/资源? -> 那就上 Qwen3-235B-A22B 吧,或者通过 API 调用。
Qwen3 家族的丰富性确保了几乎涵盖了所有你能想到的使用场景。
从手机端的小助手,到个人电脑上的开发利器,再到云端的大规模商业应用,Qwen3 都能提供恰到好处的解决方案。
这种全面的布局,足见阿里的野心和诚意。
Qwen3 的主要特点
光说不练嘴把式,咱们得深入看看 Qwen3 到底凭什么这么“横”。
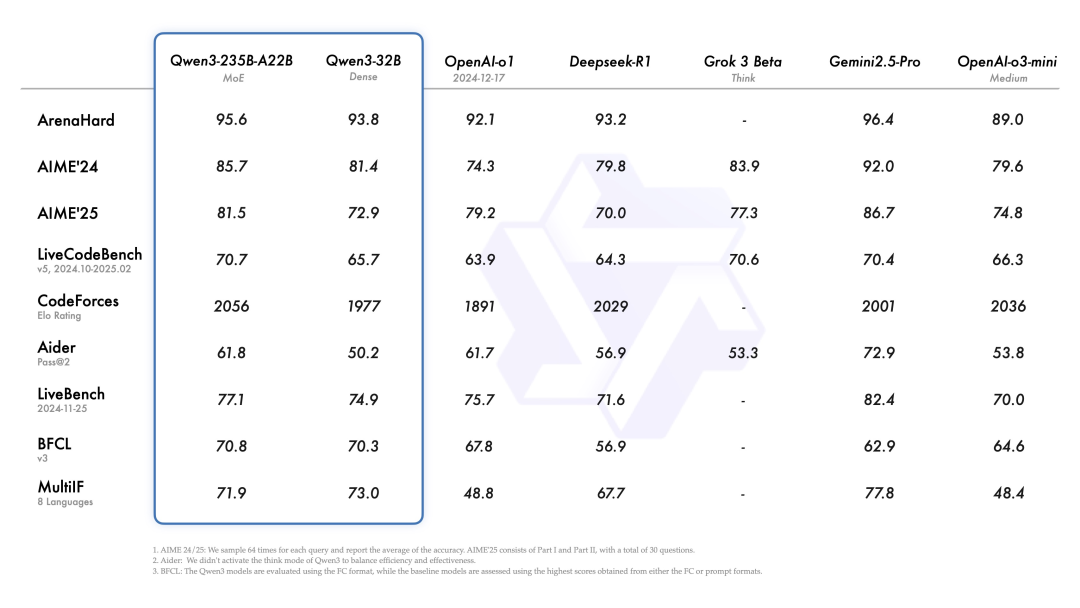
1. 性能霸榜:不只是一两个点,是全维度的领先!
前面提到 Qwen3 在各项基准测试中登顶 SOTA。
我们可以期待后续更多第三方的详细测评报告,来验证 Qwen3 在具体任务上的表现。但从目前的信息看,Qwen3 的性能绝对是第一梯队,而且是领跑者。
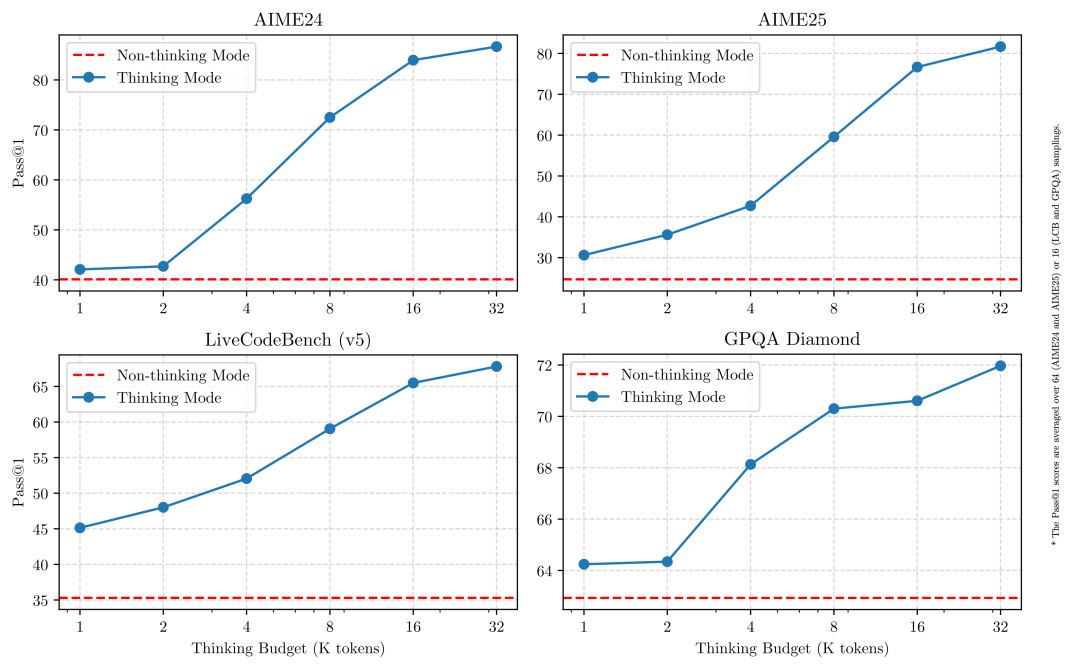
2. “混合推理”深度解析:智能调度的艺术
我们再深入理解一下这个“混合推理”机制。它不仅仅是提供两个模式,更关键在于如何在同一个模型内部署和稳定运行这两种截然不同的输出逻辑。
-
技术挑战: 想象一下,让一个大脑同时学会“快问快答”和“深度思考”,并且在切换时思维不混乱、能力不下降,这是非常困难的。市面上很多模型如果用“非推理”数据(即没有思考链、纯粹答案的数据)去训练,很容易在需要推理时产生逻辑混乱或错误。
-
Qwen3 的突破: 阿里通过先进的训练策略、数据设计和损失函数调度,成功让 Qwen3 在同一个模型权重下,稳定掌握了两种输出分布。这意味着:
-
- 当你需要快速响应时(关闭推理模式),它能高效输出简洁答案。
- 当你需要严谨分析时(开启推理模式),它能调用内部的“思考链”能力,进行多步推理。
- 切换过程平滑,性能损失极小,真正实现了**“一个大脑,两种智慧”**。
-
用户与开发者价值:
-
- 更快响应 & 更低成本: 在处理大量简单请求时(例如,客服机器人的初步应答),关闭推理模式可以大幅提升响应速度,降低计算成本。
- 更强能力 & 更优结果: 在处理复杂任务时(例如,写分析报告、代码调试、多轮对话),开启推理模式能确保结果的准确性、逻辑性和深度。
- Agent 执行力 MAX: 这对 Agent 应用尤其重要。Agent 需要根据任务的复杂度,智能地决定是快速执行还是深入思考。Qwen3 的混合推理机制,为 Agent 提供了这种灵活调度的底层能力。
3. 119 种语言支持:让 AI 惠及全球
Qwen3 支持多达 119 种语言!这不仅仅包括中、英、法、西、俄、阿拉伯这些联合国常用语言,还涵盖了众多地方性语言和小语种。
这意味着什么?许多以前没有能力开发自己母语 AI 大模型的国家和地区,现在可以直接使用 Qwen3,拥有属于自己的 AI 了!
这对于促进全球 AI 技术的普及、文化的交流和信息的平等,具有非凡的意义,体现了技术普惠的精神!
Agent 时代的核心引擎:MCP 与 FC
甲木在之前的文章(比如讲 AutoGLM 那篇)里反复强调,AI 的未来在于 Agent,在于从“能聊”进化到“能干”。
Qwen3 的设计,完美契合了这一趋势,它就是为 Agent 时代量身打造的核心引擎。
1. “从对话走向执行”的关键节点
大模型的发展正在进入一个关键转折点:从“问答能力”走向“执行能力”。用户不再满足于仅仅和 AI 聊天、获取信息,而是希望 AI 能够直接完成任务。Qwen3 的设计理念,正是面向 Agent 架构,优化其执行效率、响应结构和工具泛化能力。
2. 原生支持 MCP 协议:Agent 协作的基础
MCP协议,我们都知道是Agent连万物的接口,规范Agent 与外部工具/环境进行交互的标准或框架。
Qwen3 原生支持 MCP 协议,意味着它天生就适合融入到复杂的 Agent 系统中,能够更好地理解指令、执行任务、并返回符合规范的结果,极大地简化了 Agent 的开发。
3. Qwen-Agent 框架:降低 Agent 开发门槛
为了方便开发者基于 Qwen3 构建 Agent,阿里还推出了配套的 Qwen-Agent 框架(GitHub: https://github.com/QwenLM/Qwen-Agent)。
这个框架封装了工具调用的模板、解析器等,可以大大降低编写 Agent 应用的编码复杂度。开发者可以更专注于 Agent 的逻辑设计,而不是陷入繁琐的工具对接细节中。
 Qwen-Agent
Qwen-Agent
官方提到,Qwen3 的工具调用能力可以支持实现高效的手机及电脑 Agent 操作等任务。
想象一下,未来你的手机助手或电脑助手,不再只是简单的语音命令,而是能帮你自动完成多步骤任务的智能体,是不是很酷?😎
用 Qwen3 玩转创意游戏 & SVG 卡片
理论说了这么多,是不是有点手痒了?
甲木最喜欢的就是“干中学,玩中学”!
咱们这就来点实际的,看看怎么用 Qwen3 的强大能力,结合一点创意 Prompt,来搞点好玩又实用的东西!
之前,我有很多SVG卡片场景都是通过Claude来生成的,后台就有很多小伙伴问我,有没有一个合适的国内AI工具来满足我们的诉求。
今天,我们就聚焦一个特别的玩法:让 Qwen3 帮我们生成 创意游戏 和 SVG 格式的创意卡片!
下面,甲木就带你头脑风暴几个基于 Qwen3 的实际Case!
(通义APP 或者 chat.qwen.ai)
游戏类
实在熬不动了,凌晨三点了…还没发布…先给大家看两个case…
Case 1:emoji反应堆
一个快节奏的反应游戏。屏幕上会快速闪过一个目标表情符号(例如:笑脸😄),下方会同时出现3-4个选项表情符号,玩家需要在限定时间内(例如1-2秒)点击与目标匹配的那个表情符号。
prompt如下:
 简单版prompt
简单版prompt
Case 2:表情符号反应堆
刚才的游戏难度没有上去,我们加大一下游戏难度,看看在复杂场景里面它的表现如何。
prompt如下:
 地狱难度prompt
地狱难度prompt
来看一下qwen3的生成效果:

SVG卡片类
Case 1: 终极单词记忆 SVG 卡片生成器
痛点: 死记硬背单词太枯燥,效率低,忘得快!😭
解决方案: 利用 Qwen3 的联想、编故事和图形生成能力,打造包含词根、联想、记忆故事的视觉卡片!

怎么样?是不是感觉背单词瞬间变成了一场创意冒险?😎
Case 2: 诗情画意 - 古诗词意境 SVG 卡片
痛点: 如何更直观地感受古诗词的意境之美?如何制作独特的电子贺卡或分享卡片?
解决方案: 让 Qwen3 根据主题和风格,自动查找诗词并生成匹配意境的 SVG 卡片!
 山水 隐逸
山水 隐逸
其实我还准备了一堆case,但今天真的熬不动了…改日再写吧
开源的力量:Qwen3 不止是一个模型,更是一个生态的引擎
甲木一直认为,开源是推动技术进步,尤其是普惠 AI 的核心力量。
Qwen3 的全面开源,其意义远不止是发布了一个强大的模型,它更是在为整个 AI 生态系统注入活力。
1. 站在巨人的肩膀上创新
DeepSeek 官方也曾透露,他们将 DeepSeek-R1 的能力蒸馏到 6 个模型开源给社区,其中 4 个就是基于 Qwen-32B 蒸馏而来。
基础模型的开放,让更多人可以站在“巨人”的肩膀上,进行快速、低成本的创新和优化,而不是所有人都从零开始“造轮子”。
Qwen 系列模型,已经成为了许多前沿技术探索和新模型诞生的重要基石。
2. 阿里:不止是参与者,更是引领者
阿里云是国内最早开源自研大模型的“大厂”,也是一家积极研发先进 AI 模型并且全方位开源的云计算厂商。
他们率先实现了**“全尺寸、全模态”**的开源(从几亿到几千亿参数,覆盖文本、视觉、音频等多模态)。
这次 Qwen3 的发布,再次巩固了阿里在开源领域的领先地位。他们不仅仅是在“做一个模型”,更是在:
- 给整个国产大模型生态“打样”: 在技术上证明中国 AI 可以比肩世界顶尖水平,在生态上倡导开放、共享、共建。
- 构建更强大的智能底座: 面向未来,阿里还将投入数千亿元,持续加码云和 AI 基础设施。这不仅仅是为了阿里自身的业务,更是为整个社会的智能化转型提供动力。
这种技术自信和生态格局,是值得我们肯定和学习的。
3. 开源对我们普通用户的意义
开源的好处,最终会惠及每一个用户和开发者:
- 降低门槛: 免费、可商用、多种部署方式,让更多人有机会学习、使用、甚至创业。
- 加速创新: 开放的模型会吸引全球的开发者进行微调、优化、开发新应用,带来更丰富、更垂直的 AI 产品和服务。比如,很快可能就会出现基于 Qwen3 的医疗问答模型、法律咨询模型、教育辅导模型等等。
- 透明与信任: 开源模型的代码和权重可以被审查,有助于提高技术的透明度和可信度,减少“黑箱”带来的疑虑。
- 避免锁定: 不会被单一厂商绑定,拥有更多的选择权和自主权。
可以说,Qwen3 的开源,是给所有热爱技术、拥抱变化的人的一份大礼。它提供了一个强大的平台,让我们可以共同参与到这场波澜壮阔的 AI 革命中。
立刻上手!Qwen3 资源与路径全攻略
心动不如行动!说了这么多,怎么才能立刻体验和使用 Qwen3 呢?甲木给你整理好了直达路径:
1. 最轻松:在线体验 & App 把玩
-
通义千问官网: 直接访问
https://www.tongyi.com/qianwen/或者https://chat.qwen.ai/,注册登录即可在线与 Qwen3(或其变体)对话。这是最快感受模型能力的方式。
-
通义 App: 下载手机 App (iOS & Android),随时随地和 Qwen3 互动。非常适合日常问答、写作助手等场景。
-
夸克 App (即将接入): 阿里旗下的夸克搜索/浏览器也即将接入 Qwen3,值得期待。
优点: 无需配置,即开即用,免费。缺点: 可能无法选择具体模型版本,定制化能力有限。
2. 开发者之选:API 调用
- 阿里云百炼平台: 登录阿里云,找到“百炼大模型平台”(Bailian),可以方便地调用 Qwen 各系列模型的 API。这里可以选择具体的模型版本,并进行更深度的集成开发。
- 适合: 需要将 Qwen3 能力集成到自己应用或服务中的开发者。
优点: 灵活可控,易于集成,按量付费。缺点: 需要一定的编程基础,并且会产生 API 调用费用。
3. 硬核玩家:本地部署
-
模型下载:
-
- 魔搭社区 (ModelScope): 国内领先的 AI 模型社区,搜索 “Qwen3” 即可找到相关模型下载。 (https://modelscope.cn/models)
- Hugging Face: 全球最大的 AI 模型社区,同样搜索 “Qwen3”。 (https://huggingface.co/models)
-
部署工具: 可以使用
vLLM,llama.cpp,Ollama等流行的开源框架进行本地部署。社区有很多教程。 -
硬件要求:
-
- Qwen3-30B-A3B / Qwen3-32B: 推荐拥有 24G 或更高显存的消费级显卡 (如 RTX 3090/4090) 进行尝试,量化后可能在更低配置上运行。
- 更小模型 (14B 及以下): 对硬件要求更低,普通游戏本或台式机+较好显卡即可。
- 旗舰版 (235B): 需要专业级硬件(如多张 H20/A100/H100)。
-
适合: 希望完全掌控模型、进行深度定制、微调、或者对数据隐私有极高要求的硬核开发者和研究者。
优点: 完全控制,无 API 费用,数据本地化。缺点: 技术门槛高,需要较好的硬件,部署和维护复杂。
4. Agent 开发框架
- Qwen-Agent: 前面提到的官方 Agent 框架,可以在 GitHub 上找到:
https://github.com/QwenLM/Qwen-Agent。想开发 Agent 应用的同学,务必关注!
甲木建议:
- 新手: 从在线体验和 App 开始,熟悉 Qwen3 的基本能力和对话风格。
- 开发者/爱好者: 如果硬件允许,强烈建议尝试本地部署 Qwen3-30B-A3B 或 32B,这是真正“玩转”大模型的开始。同时可以研究 API 调用 和 Qwen-Agent 框架。
- 企业/研究机构: 根据需求评估 API 服务 或 本地部署更大规模模型。
别再犹豫了!选择一条适合你的路径,立刻开始探索 Qwen3 的世界吧!
不足之处
虽然 Qwen3 这波很顶,直接把开源模型的天花板又往上抬了一大截,但作为实践派,咱们也得聊聊进步空间和未来可以期待的点嘛!🧐 (纯属个人观察和期待哈,欢迎讨论!)
1、MoE 激活参数的想象空间?
旗舰版的 MoE 设计(235B 总参数,激活 22B)在效率和性能平衡上做得很好。
但咱也好奇,面对一些极端烧脑、需要“火力全开”的复杂推理场景时,未来有没有可能通过某种方式(比如特定模式或API选项)激活更多参数,来冲击一下性能的绝对上限?
当然,这得开发者在成本和效果间做权衡。
2、代码能力还能更“凶”吗?
代码生成和理解是检验大模型能力的试金石。
Qwen3 的代码能力试下来还不错,但和市面上一些专门面向开发者的顶级模型(比如深度优化的 GPT-4 或 GitHub Copilot 企业版)在处理大型复杂项目、冷门语言或框架、以及代码调试、自动修复等更精细化场景时,是否还有进一步提升的空间?
非常期待后续社区的深度评测和阿里的持续优化!👨
3、拥抱多模态的步伐能更快些吗?
现在 AI 界卷的就是个“全能”,光能聊文字还不够,得能看图、能听声、甚至理解视频。
目前看 Qwen3 主要发力点还在文本和代码,啥时候能集成更强的原生图像理解、视频分析等多模态能力,把“眼耳口鼻”都打通?
期待一波Qwen3-VL
4、Agent 的“实战”考验
Qwen3 对 Agent 的支持是巨大进步,但从“理论支持”到“稳定好用”往往需要大量打磨。
真实世界任务的复杂性、鲁棒性要求、长链条任务的稳定性、工具调用失败后的容错处理等,都需要时间和大量用户反馈来检验和迭代。
期待看到更多基于 Qwen3 的 Agent 在实际场景中被“锤炼”!
结语
好了,关于 Qwen3 的深度解读和实战指南,
甲木今天就先带大家“飚车”到这里。
那么,面对 Qwen3 这样强大的 AI 工具,我们该怎么做?
甲木的态度一直很明确:不要焦虑,不要恐惧,更不要躺平!
AI 的发展速度确实很快,但它始终是工具,是增强我们能力的翅膀。工具越强大,我们越应该思考如何驾驭它,而不是被它取代。
人的价值,永远在于:
- 提出正确的问题。
- 设定有意义的目标。
- 发挥独特的创造力。
- 进行深度的思考和决策。
- 保持学习和适应的能力。
Qwen3 的出现,给了我们一个前所未有的机会,去探索 AI 的边界,去创造新的应用,去解决过去难以解决的问题。
所以,
- 立刻行动起来! 去体验,去测试,去玩耍!“干中学,玩中学”,在实践中找到感觉。
- 打开你的脑洞! 想想 Qwen3 能在你的学习、工作、生活中帮你做点什么?上面 SVG 卡片的例子只是抛砖引玉,你能想到更酷的应用吗?
- 拥抱 Agent 思维! 开始思考如何让 AI 帮你“干活”,而不仅仅是“聊天”。
- 保持学习,保持好奇! AI 的世界日新月异,持续关注,不断学习,才能立于潮头。
记住那句话:人要比 AI 更“凶”!🤘 这里的“凶”,不是凶狠,而是指我们的主动性、创造性和驾驭技术的能力要更胜一筹!
AI 的浪潮已经奔涌而来,与其在岸边观望,不如勇敢地跳上 Qwen3 这艘性能强劲的“冲浪板”,
一起去乘风破浪吧!
呼~ 长文终于码完!希望能帮你彻底搞懂 Qwen3,并点燃你探索 AI 的热情!
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









