







文章目录
- 1. METABOLITES: Data Preparation Dependent and Independent Variables - Metabolites
- 1.1 CD - Dependent Variable (Y)
- 1.2 CD - Independent Variable (X)
- 1.3 UC - Dependent Variable (Y)
- 1.4 UC - Independent Variable (Y)
- 2. MICROBIOTA: Data Preparation Dependent and Independent Variables
- 2.1 CD - Dependent Variable (Y)
- 2.2 CD - Independent Variable (Y)
- 2.3 UC - Independent Variable (Y)
- 2.4 UC - Independent Variable (Y)
- 3. ENZYMES: Data Preparation Dependent and Independent Variables
- 3.1 CD - Dependent Variable (Y)
- 3.2 CD - Independent Variable (Y)
介绍
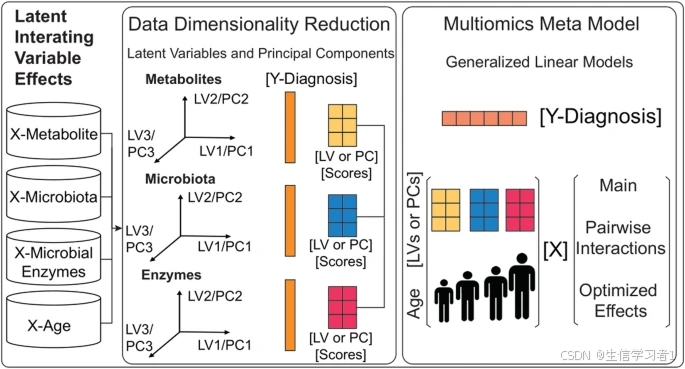
随着测序技术的进步,包含宿主和微生物组的配对测量数据的多组学数据的数量和规模正在迅速增加。随着生成这些数据成为常规操作,有助于其解读的计算方法变得越来越重要。在此,我们提出了一个用于整合微生物组多组学数据的框架:潜在交互变量效应(LIVE)建模。LIVE 使用单组学潜在变量(LV)组织在结构化的元模型中进行整合,以确定对表型或状况最具预测性的特征组合。
我们开发了一个基于稀疏部分最小二乘判别分析(sPLS-DA)的监督型 LIVE 版本,以及一个基于稀疏主成分分析(sPCA)主成分的无监督型 LIVE 版本,这两种版本均能够纳入协变量信息。我们在公开可用的克罗恩病(CD)和溃疡性结肠炎(UC)状态患者的 PRISM 和 LLDeep 队列的宏基因组和代谢组数据集上测试了 LIVE 的性能,并与现有的肠道微生物多组学方法和阴道微生物组数据集进行了基准测试,取得了稳定且可比的性能。除了这些基准测试工作之外,我们还使用 PRISM 和 LLDeep 队列对 LIVE 的两个版本进行了详细的分析和解释。LIVE 将 CD 和 UC 原始数据集中的特征交互数量从数百万减少到不到 20,000 个,并在肠道微生物、代谢物、酶的疾病预测能力上对临床变量进行了条件化。
LIVE 对当前整合微生物组数据的方法做出了独特的、互补性的贡献,并且在将多组学数据与临床变量进行可解释的整合以预测疾病结果和识别疾病中的微生物组机制方面为现有方法提供了关键优势。
Abstract
Background
The number and size of multi-omics datasets with paired measurements of the host and microbiome is rapidly increasing with the advance of sequencing technologies. As it becomes routine to generate these datasets, computational methods to aid in their interpretation become increasingly important. Here, we present a framework for integration of microbiome multi-omics data: Latent Interacting Variable Effects (LIVE) modeling. LIVE integrates multi-omics data using single-omic latent variables (LV) organized in a structured meta-model to determine the combinations of features most predictive of a phenotype or condition.Results
We developed a supervised version of LIVE leveraging sparse Partial Least Squares Discriminant Analysis (sPLS-DA) LVs, and an unsupervised version leveraging sparse Principal Component Analysis (sPCA) principal components which both can incorporate covariate awarness. LIVE performance was tested on publicly available metagenomic and metabolomics data set from Crohn’s Disease (CD) and Ulcerative Colitis (UC) status patients in the PRISM and LLDeep cohorts, and benchmarked against existing gut microbiome multi-omics approaches and vaginal microbiome datasests, achieving consistent and comparable performances. In addition to these benchmarking efforts, we present a detailed analysis and interpretation of both versions of LIVE using the PRISM and LLDeep cohorts. LIVE reduced the number of feature interactions from the original datasets for CD and UC from millions to less than 20,000 while conditioning the disease-predictive power of gut microbes, metabolites, enzymes, on clinical variables.Conclusions
LIVE makes a distinct, complementary contribution to current methods to integrate microbiome data and offers key advantages to existing approaches in the interpretable integration of multi-omics data with clinical variables to predict to disease outcomes and identify microbiome mechanisms of disease.
代码
https://github.com/Brubaker-Lab/LIVE-Latent-Interacting-Variable-Effects-Modeling
---
title: "LIVE Modeling WorkBook 1 - Data-Preprocessing for IBD data set"
author: "Javier Munoz"
date: "August/24/2022"
output:
html_document: default
pdf_document: default
---
# 0. Rmarkdown
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
1. METABOLITES: Data Preparation Dependent and Independent Variables - Metabolites
suppressWarnings(library (ggplot2, verbose = FALSE))
suppressWarnings(library (readxl, verbose = FALSE))
suppressWarnings(library (viridisLite, verbose = FALSE))
suppressWarnings(library (pheatmap, verbose = FALSE))
suppressWarnings(library (mixOmics, verbose = FALSE))
suppressWarnings(library(tidyverse, verbose = FALSE))
suppressWarnings(library(magrittr, verbose = FALSE))
suppressWarnings(library (dplyr, verbose = FALSE))
## Suplemental Material 1 Metabolite feature metadata (8848 rows x 7 columns)
data_file <- "~/Desktop/IBD_article/Supplementary Dataset 1-Metabolite feature metadata.xlsx"
if(file.exists(data_file)){
Sp1_Metabolite_feature_metadata <- read_excel(path = data_file)
} else {
print("Supplementary Dataset 1- Metabolite feature metadata.xlsx. Check the location of the file relative to your Rmd file.")
}
Sp1_Metabolite_feature_metadata
## Replace NA - Not found
Sp1_Metabolite_feature_metadata
sp1 <- Sp1_Metabolite_feature_metadata %>% dplyr::select (Feature, Putative_Chemical_Class)
sp1 [is.na(sp1)] <- "Not Found"
sp1
## Suplemental Material 2 Per-subject metabolite relative abundance profiles (8855 rows x 221 columns)
data_file <- "~/Desktop/IBD_article/Supplementary Dataset 2-Per-subject metabolite relative abundance profiles.xlsx"
if(file.exists(data_file)){
Sp2_Per_subject_metabolite_relative_abundance_profiles <- read_excel(path = data_file)
} else {
print("Supplementary Dataset 2-Per-subject metabolite relative abundance profiles.xlsx. Check the location of the file relative to your Rmd file.")
}
Sp2_Per_subject_metabolite_relative_abundance_profiles
## Combine Columns and data wrangling
Sp2_Per_subject_metabolite_relative_abundance_profiles
sp2_version1 <- merge (sp1, Sp2_Per_subject_metabolite_relative_abundance_profiles, by = "Feature", all.y = TRUE)
sp2_version1
sp2 <- as.data.frame (t(sp2_version1))
sp2
names (sp2) <- sp2 %>% slice (1) %>% unlist ()
sp2<- sp2 %>% slice (-1)
sp2
sp2 <- sp2 [-1,]
sp2
1.1 CD - Dependent Variable (Y)
# TRAINING DATA SET
Y.diagnosis <- sp2[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.diagnosis$Diagnosis
Y.diagnosis %>% dplyr::select (Diagnosis)
Y.diagnosis <-as.factor (Y.diagnosis$Diagnosis)
Y.diagnosis
# VALIDATION DATA SET
Y.diagnosis_validation <- sp2[156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.diagnosis_validation$Diagnosis
Y.diagnosis_validation <-as.factor (Y.diagnosis_validation $Diagnosis)
Y.diagnosis_validation
# TRAINING DATA SET
Y.age <- sp2[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.age$Age
Y.age <-as.factor (Y.age$Age)
Y.age
# VALIDATION DATA SET
Y.age_validation <- sp2[156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.age_validation$Age
Y.age_validation <-as.factor (Y.age_validation$Age)
Y.age_validation
# TRAINING DATA SET
Y.Fecal.Calprotectin <- sp2 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.Fecal.Calprotectin$Fecal.Calprotectin
Y.Fecal.Calprotectin <-as.factor (Y.Fecal.Calprotectin$Fecal.Calprotectin )
Y.Fecal.Calprotectin
# VALIDATION DATA SET
Y.Fecal.Calprotectin_validation <- sp2 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.Fecal.Calprotectin_validation$Fecal.Calprotectin
Y.Fecal.Calprotectin_validation <-as.factor (Y.Fecal.Calprotectin_validation$Fecal.Calprotectin )
Y.Fecal.Calprotectin_validation
# TRAINING DATA SET
Y.antibiotic <- sp2 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.antibiotic$antibiotic
Y.antibiotic <-as.factor (Y.antibiotic$antibiotic)
Y.antibiotic
# VALIDATION DATA SET
Y.antibiotic_validation <- sp2 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.antibiotic_validation$antibiotic
Y.antibiotic_validation <-as.factor (Y.antibiotic_validation$antibiotic)
Y.antibiotic_validation
# TRAINING DATA SET
Y.immunosuppressant <- sp2 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.immunosuppressant <- as.factor(Y.immunosuppressant$immunosuppressant)
Y.immunosuppressant
# VALIDATION DATA SET
Y.immunosuppressant_validation <- sp2 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.immunosuppressant_validation <- as.factor(Y.immunosuppressant_validation$immunosuppressant)
Y.immunosuppressant_validation
# TRAINING DATA SET
Y.steroids <- sp2 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.steroids$steroids
Y.steroids <-as.factor (Y.steroids$steroids)
Y.steroids
# VALIDATION DATA SET
Y.steroids_validation <- sp2 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.steroids_validation$steroids
Y.steroids_validation <-as.factor (Y.steroids_validation$steroids)
Y.steroids_validation
# TRAINING DATA SET
Y.mesalamine <- sp2 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.mesalamine$mesalamine
Y.mesalamine <-as.factor (Y.mesalamine$mesalamine)
Y.mesalamine
# VALIDATION DATA SET
Y.mesalamine_validation <- sp2 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.mesalamine_validation$mesalamine
Y.mesalamine_validation <-as.factor (Y.mesalamine_validation$mesalamine)
Y.mesalamine_validation
# TRAINING DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis, file = "Y_CD_diagnosis_train.xlsx")
write.xlsx(Y.age, file = "Y_CD_age_train.xlsx")
write.xlsx(Y.Fecal.Calprotectin, file = "Y_CD_Fecal.Calprotectin_train.xlsx")
write.xlsx(Y.mesalamine, file = "Y_CD_mesalamine_train.xlsx")
write.xlsx(Y.steroids, file = "Y_CD_steroids_train.xlsx")
write.xlsx(Y.antibiotic, file = "Y_CD_antibiotics_train.xlsx")
write.xlsx(Y.immunosuppressant, file = "Y_CD_immunosuppressants_train.xlsx")
# VALIDATION DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_validation, file = "Y_CD_diagnosis_validation.xlsx")
write.xlsx(Y.age_validation, file = "Y_CD_age_validation.xlsx")
write.xlsx(Y.Fecal.Calprotectin_validation, file = "Y_CD_Fecal.Calprotectin_validation.xlsx")
write.xlsx(Y.mesalamine_validation, file = "Y_CD_mesalamine_validation.xlsx")
write.xlsx(Y.steroids_validation, file = "Y_CD_steroids_validation.xlsx")
write.xlsx(Y.antibiotic_validation, file = "Y_CD_antibiotics_validation.xlsx")
write.xlsx(Y.immunosuppressant_validation, file = "Y_CD_immunosuppressants_validation.xlsx")
1.2 CD - Independent Variable (X)
# TRAINING DATA SET
sp2_version1
Putative_Chemical_class_deffined <- sp2_version1 %>% filter (Putative_Chemical_Class !="Not Found") %>% unite ("Feature", Feature:Putative_Chemical_Class, na.rm =TRUE, remove = FALSE)
Putative_Chemical_class_deffined
clinical_info <- sp2_version1 %>% filter (Feature == "antibiotic" | Feature == "Age" | Feature == "Fecal.Calprotectin" | Feature == "immunosuppressant" | Feature == "mesalamine" | Feature == "steroids") %>% mutate (Putative_Chemical_Class = Feature)
clinical_info
sp2_filtered_raw <- rbind (clinical_info, Putative_Chemical_class_deffined)
sp2_filtered_raw <- sp2_filtered_raw [, -2]
sp2_filtered_raw
sp2_filtered <- as.data.frame (t(sp2_filtered_raw))
sp2_filtered
names (sp2_filtered) <- sp2_filtered %>% slice (1) %>% unlist ()
sp2_filtered <- sp2_filtered %>% slice (-1)
sp2_filtered
sp2_filtered.1 <- subset (sp2_filtered, select = -c(Age, antibiotic, Fecal.Calprotectin, immunosuppressant, mesalamine, steroids))
sp2_filtered.1
sp2_filtered.1 [] <- lapply(sp2_filtered.1, as.numeric)
sp2_filtered.1
sp2_version1 <- merge (sp1, Sp2_Per_subject_metabolite_relative_abundance_profiles, by = "Feature", all.y = TRUE)
sp2_version1
column.names <- colnames (sp2_version1)
column.names <- as_vector (column.names)
column.names <- column.names [c(-1,-2)]
sp2_filtered.1 <- sp2_filtered.1 %>% mutate (Samples = column.names, .before = "C18-neg_Cluster_0004_Styrenes")
sp2_filtered.1
write.xlsx(sp2_filtered.1 , file = "sp2_edited_Xavier.xlsx")
data_file <- "~/Desktop/IBD_article/sp2_edited_Xavier.xlsx"
if(file.exists(data_file)){
sp2_edited <- read_excel(path = data_file)
} else {
print("sp2_edited_Xavier. Check the location of the file relative to your Rmd file.")
}
sp2_edited
sp2_training_data <- sp2_edited %>% filter (str_detect (Samples,"PRISM"))
sp2_training_data
CD_train <- sp2[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
CD_train_list <- CD_train [0]
CD_train_list
sp2_training_data_CD1 <- sp2_training_data %>% filter (sp2_training_data$Samples == "PRISM|7122" |sp2_training_data$Samples == "PRISM|7147"|sp2_training_data$Samples == "PRISM|7150" | sp2_training_data$Samples == "PRISM|7153" |sp2_training_data$Samples == "PRISM|7184" |sp2_training_data$Samples == "PRISM|7238" |sp2_training_data$Samples == "PRISM|7406" |sp2_training_data$Samples == "PRISM|7408" |sp2_training_data$Samples == "PRISM|7421" |sp2_training_data$Samples == "PRISM|7445" |sp2_training_data$Samples == "PRISM|7486" |sp2_training_data$Samples == "PRISM|7547" |sp2_training_data$Samples == "PRISM|7658" |sp2_training_data$Samples == "PRISM|7662" |sp2_training_data$Samples == "PRISM|7744" |sp2_training_data$Samples == "PRISM|7759" |sp2_training_data$Samples == "PRISM|7791" |sp2_training_data$Samples == "PRISM|7843" |sp2_training_data$Samples == "PRISM|7847" |sp2_training_data$Samples == "PRISM|7855" |sp2_training_data$Samples == "PRISM|7858" |sp2_training_data$Samples == "PRISM|7860" |sp2_training_data$Samples == "PRISM|7861" |sp2_training_data$Samples == "PRISM|7862" |sp2_training_data$Samples == "PRISM|7870" |sp2_training_data$Samples == "PRISM|7874" |sp2_training_data$Samples == "PRISM|7875" |sp2_training_data$Samples == "PRISM|7875" |sp2_training_data$Samples == "PRISM|7879" |sp2_training_data$Samples == "PRISM|7899" |sp2_training_data$Samples == "PRISM|7904" |sp2_training_data$Samples == "PRISM|7906" |sp2_training_data$Samples == "PRISM|7908" |sp2_training_data$Samples == "PRISM|7909" |sp2_training_data$Samples == "PRISM|7910" |sp2_training_data$Samples == "PRISM|7911" |sp2_training_data$Samples == "PRISM|7912" |sp2_training_data$Samples == "PRISM|7938" |sp2_training_data$Samples == "PRISM|7941" |sp2_training_data$Samples == "PRISM|7947"| sp2_training_data$Samples == "PRISM|7948" |sp2_training_data$Samples == "PRISM|7955" |sp2_training_data$Samples == "PRISM|7971" |sp2_training_data$Samples == "PRISM|7989" |sp2_training_data$Samples == "PRISM|8095" |sp2_training_data$Samples == "PRISM|8226" |sp2_training_data$Samples == "PRISM|8244" |sp2_training_data$Samples == "PRISM|8264" |sp2_training_data$Samples == "PRISM|8283" |sp2_training_data$Samples == "PRISM|8332" |sp2_training_data$Samples == "PRISM|8336" |sp2_training_data$Samples == "PRISM|8361" |sp2_training_data$Samples == "PRISM|8374"| sp2_training_data$Samples == "PRISM|8377" |sp2_training_data$Samples == "PRISM|8406" |sp2_training_data$Samples == "PRISM|8452" |sp2_training_data$Samples == "PRISM|8462" |sp2_training_data$Samples == "PRISM|8466" |sp2_training_data$Samples == "PRISM|8467" |sp2_training_data$Samples == "PRISM|8475" |sp2_training_data$Samples == "PRISM|8483" |sp2_training_data$Samples == "PRISM|8485" |sp2_training_data$Samples == "PRISM|8496" |sp2_training_data$Samples == "PRISM|8523" |sp2_training_data$Samples == "PRISM|8534" |sp2_training_data$Samples == "PRISM|8537" |sp2_training_data$Samples == "PRISM|8550" |sp2_training_data$Samples == "PRISM|8564" |sp2_training_data$Samples == "PRISM|8565" |sp2_training_data$Samples == "PRISM|8573" |sp2_training_data$Samples == "PRISM|8577" |sp2_training_data$Samples == "PRISM|8589" |sp2_training_data$Samples == "PRISM|8591" |sp2_training_data$Samples == "PRISM|8592" |sp2_training_data$Samples == "PRISM|8624" )
sp2_training_data_CD1
sp2_training_data_CD2 <- sp2_training_data %>% filter(sp2_training_data$Samples == "PRISM|8629" |sp2_training_data$Samples == "PRISM|8675" |sp2_training_data$Samples == "PRISM|8683" |sp2_training_data$Samples == "PRISM|8746" |sp2_training_data$Samples == "PRISM|8749" | sp2_training_data$Samples == "PRISM|8753" |sp2_training_data$Samples == "PRISM|8754" |sp2_training_data$Samples == "PRISM|8758" |sp2_training_data$Samples == "PRISM|8764" |sp2_training_data$Samples == "PRISM|8765"| sp2_training_data$Samples == "PRISM|8774" |sp2_training_data$Samples == "PRISM|8776" |sp2_training_data$Samples == "PRISM|8783" |sp2_training_data$Samples == "PRISM|8784" |sp2_training_data$Samples == "PRISM|8788" |sp2_training_data$Samples == "PRISM|8789" |sp2_training_data$Samples == "PRISM|8794" |sp2_training_data$Samples == "PRISM|8800" |sp2_training_data$Samples == "PRISM|8802" |sp2_training_data$Samples == "PRISM|8806" |sp2_training_data$Samples == "PRISM|8807" |sp2_training_data$Samples == "PRISM|8841" |sp2_training_data$Samples == "PRISM|8843" |sp2_training_data$Samples == "PRISM|8847" |sp2_training_data$Samples == "PRISM|8878" |sp2_training_data$Samples == "PRISM|8892"| sp2_training_data$Samples == "PRISM|9126" |sp2_training_data$Samples == "PRISM|9148")
sp2_training_data_CD2
sp2_training_data_CD <- rbind (sp2_training_data_CD1, sp2_training_data_CD2)
sp2_training_data_CD
X_train <- subset (sp2_training_data_CD, select = -c(Samples))
X_train
X_train <- log (X_train+1)
X_train
library (openxlsx)
write.xlsx(X_train, file = "X_CD_metabolites_train.xlsx")
# VALIDATION DATA SET
sp2_edited
sp2_validation_data <- sp2[155:221, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
sp2_validation_data
CD_metabolite_validation_list <- sp2_validation_data [0]
CD_metabolite_validation_list
sp2_validation_CD <- sp2_edited %>% filter (sp2_edited$Samples == "Validation|LLDeep_0001"|sp2_edited$Samples == "Validation|LLDeep_0003"|sp2_edited$Samples == "Validation|LLDeep_0010" | sp2_edited$Samples == "Validation|LLDeep_0011"|sp2_edited$Samples == "Validation|LLDeep_0012"|sp2_edited$Samples == "Validation|LLDeep_0015" |sp2_edited$Samples == "Validation|LLDeep_0018" |sp2_edited$Samples == "Validation|LLDeep_0021" |sp2_edited$Samples == "Validation|LLDeep_0022" |sp2_edited$Samples == "Validation|LLDeep_0024" |sp2_edited$Samples == "Validation|LLDeep_0026" |sp2_edited$Samples == "Validation|LLDeep_0027" |sp2_edited$Samples == "Validation|LLDeep_0028" |sp2_edited$Samples == "Validation|LLDeep_0029" |sp2_edited$Samples == "Validation|LLDeep_0030" |sp2_edited$Samples == "Validation|LLDeep_0033" |sp2_edited$Samples == "Validation|LLDeep_0034" |sp2_edited$Samples == "Validation|LLDeep_0037" |sp2_edited$Samples == "Validation|LLDeep_0039" |sp2_edited$Samples == "Validation|LLDeep_0043" |sp2_edited$Samples == "Validation|LLDeep_0047" |sp2_edited$Samples == "Validation|LLDeep_0052" |sp2_edited$Samples == "Validation|UMCGIBD00072" |sp2_edited$Samples == "Validation|UMCGIBD00030"|sp2_edited$Samples == "Validation|UMCGIBD00032"| sp2_edited$Samples == "Validation|UMCGIBD00145" |sp2_edited$Samples == "Validation|UMCGIBD00485"|sp2_edited$Samples == "Validation|UMCGIBD00041"|sp2_edited$Samples == "Validation|UMCGIBD00126" |sp2_edited$Samples == "Validation|UMCGIBD00082"|sp2_edited$Samples == "Validation|UMCGIBD00442"|sp2_edited$Samples == "Validation|UMCGIBD00077" |sp2_edited$Samples == "Validation|UMCGIBD00141"|sp2_edited$Samples == "Validation|UMCGIBD00112" |sp2_edited$Samples == "Validation|UMCGIBD00508" |sp2_edited$Samples == "Validation|UMCGIBD00106"|sp2_edited$Samples == "Validation|UMCGIBD00458" |sp2_edited$Samples == "Validation|UMCGIBD00254" |sp2_edited$Samples == "Validation|UMCGIBD00233"|sp2_edited$Samples == "Validation|UMCGIBD00238" |sp2_edited$Samples == "Validation|UMCGIBD00027" |sp2_edited$Samples == "Validation|UMCGIBD00064")
sp2_validation_CD
X_CD_metabolites_validation <- subset (sp2_validation_CD , select = -c(Samples))
X_CD_metabolites_validation
X_CD_metabolites_validation <- log (X_CD_metabolites_validation+1)
X_CD_metabolites_validation
library (openxlsx)
write.xlsx(X_CD_metabolites_validation, file = "X_CD_metabolites_validation.xlsx")
1.3 UC - Dependent Variable (Y)
#TRAINING DATA SET
Y.diagnosis_UC <- sp2[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.diagnosis_UC$Diagnosis
Y.diagnosis_UC <-as.factor (Y.diagnosis_UC$Diagnosis)
Y.diagnosis_UC
#VALIDATION DATA SET
Y.diagnosis_validation_UC <- sp2[156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.diagnosis_validation_UC$Diagnosis
Y.diagnosis_validation_UC <-as.factor (Y.diagnosis_validation_UC$Diagnosis)
Y.diagnosis_validation_UC
#TRAINING DATA SET
Y.age_UC <- sp2[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.age_UC$Age
Y.age_UC <-as.factor (Y.age_UC$Age)
Y.age_UC
#VALIDATION DATA SET
Y.age_validation_UC <- sp2[156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.age_validation_UC$Age
Y.age_validation_UC <-as.factor (Y.age_validation_UC$Age)
Y.age_validation_UC
#TRAINING DATA SET
Y.Fecal.Calprotectin_UC <- sp2 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.Fecal.Calprotectin_UC$Fecal.Calprotectin
Y.Fecal.Calprotectin_UC <-as.factor (Y.Fecal.Calprotectin_UC$Fecal.Calprotectin )
Y.Fecal.Calprotectin_UC
#VALIDATION DATA SET
Y.Fecal.Calprotectin_validation_UC <- sp2 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.Fecal.Calprotectin_validation_UC$Fecal.Calprotectin
Y.Fecal.Calprotectin_validation_UC <-as.factor (Y.Fecal.Calprotectin_validation_UC$Fecal.Calprotectin )
Y.Fecal.Calprotectin_validation_UC
#TRAINING DATA SET
Y.antibiotic_UC <- sp2 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.antibiotic_UC$antibiotic
Y.antibiotic_UC <-as.factor (Y.antibiotic_UC$antibiotic)
Y.antibiotic_UC
#VALIDATION DATA SET
Y.antibiotic_validation_UC <- sp2 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.antibiotic_validation_UC$antibiotic
Y.antibiotic_validation_UC <-as.factor (Y.antibiotic_validation_UC$antibiotic)
Y.antibiotic_validation_UC
#TRAINING DATA SET
Y.immunosuppressant_UC <- sp2 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.immunosuppressant_UC <- as.factor(Y.immunosuppressant_UC$immunosuppressant)
Y.immunosuppressant_UC
#VALIDATION DATA SET
Y.immunosuppressant_validation_UC <- sp2 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.immunosuppressant_validation_UC <- as.factor(Y.immunosuppressant_validation_UC$immunosuppressant)
Y.immunosuppressant_validation_UC
#TRAINING DATA SET
Y.steroids_UC <- sp2 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.steroids_UC$steroids
Y.steroids_UC <-as.factor (Y.steroids_UC$steroids)
Y.steroids_UC
#VALIDATION DATA SET
Y.steroids_validation_UC <- sp2 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.steroids_validation_UC$steroids
Y.steroids_validation_UC <-as.factor (Y.steroids_validation_UC$steroids)
Y.steroids_validation_UC
#TRAINING DATA SET
Y.mesalamine_UC <- sp2 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.mesalamine_UC$mesalamine
Y.mesalamine_UC <-as.factor (Y.mesalamine_UC$mesalamine)
Y.mesalamine_UC
#VALIDATION DATA SET
Y.mesalamine_validation_UC <- sp2 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.mesalamine_validation_UC$mesalamine
Y.mesalamine_validation_UC <-as.factor (Y.mesalamine_validation_UC$mesalamine)
Y.mesalamine_validation_UC
#TRAINING DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_UC, file = "Y_UC_diagnosis_train.xlsx")
write.xlsx(Y.age_UC, file = "Y_UC_age_train.xlsx")
write.xlsx(Y.Fecal.Calprotectin_UC, file = "Y_UC_Fecal.Calprotectin_train.xlsx")
write.xlsx(Y.mesalamine_UC, file = "Y_UC_mesalamine_train.xlsx")
write.xlsx(Y.steroids_UC, file = "Y_UC_steroids_train.xlsx")
write.xlsx(Y.antibiotic_UC, file = "Y_UC_antibiotics_train.xlsx")
write.xlsx(Y.immunosuppressant_UC, file = "Y_UC_immunosuppressants_train.xlsx")
#VALIDATION DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_validation_UC, file = "Y_UC_diagnosis_validation.xlsx")
write.xlsx(Y.age_validation_UC, file = "Y_UC_age_validation.xlsx")
write.xlsx(Y.Fecal.Calprotectin_validation_UC, file = "Y_UC_Fecal.Calprotectin_validation.xlsx")
write.xlsx(Y.mesalamine_validation_UC, file = "Y_UC_mesalamine_validation.xlsx")
write.xlsx(Y.steroids_validation_UC, file = "Y_UC_steroids_validation.xlsx")
write.xlsx(Y.antibiotic_validation_UC, file = "Y_UC_antibiotics_validation.xlsx")
write.xlsx(Y.immunosuppressant_validation_UC, file = "Y_UC_immunosuppressants_validation.xlsx")
1.4 UC - Independent Variable (Y)
# TRAINING DATA SET
sp2_edited
sp2_training_data_UC <- sp2_edited %>% filter (str_detect (Samples,"PRISM"))
sp2_training_data_UC
UC_train <- sp2[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
UC_train_list <- UC_train [0]
UC_train_list
sp2_training_data_UC <- sp2_training_data_UC %>% filter (sp2_training_data_UC$Samples == "PRISM|7496" |sp2_training_data_UC$Samples == "PRISM|7506"|sp2_training_data_UC$Samples == "PRISM|7662" | sp2_training_data_UC$Samples == "PRISM|7762" |sp2_training_data_UC$Samples == "PRISM|7776"|sp2_training_data_UC$Samples == "PRISM|7847" |sp2_training_data_UC$Samples == "PRISM|7852" |sp2_training_data_UC$Samples == "PRISM|7855" |sp2_training_data_UC$Samples == "PRISM|7858" |sp2_training_data_UC$Samples == "PRISM|7860" |sp2_training_data_UC$Samples == "PRISM|7861" |sp2_training_data_UC$Samples == "PRISM|7862" |sp2_training_data_UC$Samples == "PRISM|7870" |sp2_training_data_UC$Samples == "PRISM|7874"|sp2_training_data_UC$Samples == "PRISM|7879" | sp2_training_data_UC$Samples == "PRISM|7897" |sp2_training_data_UC$Samples == "PRISM|7899" |sp2_training_data_UC$Samples == "PRISM|7904" |sp2_training_data_UC$Samples == "PRISM|7906" |sp2_training_data_UC$Samples == "PRISM|7908" |sp2_training_data_UC$Samples == "PRISM|7909" |sp2_training_data_UC$Samples == "PRISM|7910" |sp2_training_data_UC$Samples == "PRISM|7911"|sp2_training_data_UC$Samples == "PRISM|7912" |sp2_training_data_UC$Samples == "PRISM|7955"|sp2_training_data_UC$Samples == "PRISM|8096" | sp2_training_data_UC$Samples == "PRISM|8101" |sp2_training_data_UC$Samples == "PRISM|8106" |sp2_training_data_UC$Samples == "PRISM|8129" |sp2_training_data_UC$Samples == "PRISM|8244" |sp2_training_data_UC$Samples == "PRISM|8275" |sp2_training_data_UC$Samples == "PRISM|8283" |sp2_training_data_UC$Samples == "PRISM|8332" |sp2_training_data_UC$Samples == "PRISM|8441" |sp2_training_data_UC$Samples == "PRISM|8444"|sp2_training_data_UC$Samples == "PRISM|8447" |sp2_training_data_UC$Samples =="PRISM|8458"|sp2_training_data_UC$Samples == "PRISM|8464" | sp2_training_data_UC$Samples == "PRISM|8480" |sp2_training_data_UC$Samples == "PRISM|8502" |sp2_training_data_UC$Samples == "PRISM|8503" |sp2_training_data_UC$Samples == "PRISM|8511" |sp2_training_data_UC$Samples == "PRISM|8513" |sp2_training_data_UC$Samples == "PRISM|8515" |sp2_training_data_UC$Samples == "PRISM|8589" |sp2_training_data_UC$Samples == "PRISM|8605"|sp2_training_data_UC$Samples == "PRISM|8628" |sp2_training_data_UC$Samples == "PRISM|8667"|sp2_training_data_UC$Samples == "PRISM|8683" | sp2_training_data_UC$Samples == "PRISM|8692" |sp2_training_data_UC$Samples == "PRISM|8696" |sp2_training_data_UC$Samples == "PRISM|8728" |sp2_training_data_UC$Samples == "PRISM|8734" |sp2_training_data_UC$Samples == "PRISM|8735" |sp2_training_data_UC$Samples == "PRISM|8754" |sp2_training_data_UC$Samples == "PRISM|8764" |sp2_training_data_UC$Samples == "PRISM|8765"|sp2_training_data_UC$Samples == "PRISM|8774" |sp2_training_data_UC$Samples == "PRISM|8776"|sp2_training_data_UC$Samples == "PRISM|8778" | sp2_training_data_UC$Samples == "PRISM|8784" |sp2_training_data_UC$Samples == "PRISM|8785" |sp2_training_data_UC$Samples == "PRISM|8788" |sp2_training_data_UC$Samples == "PRISM|8789" |sp2_training_data_UC$Samples == "PRISM|8795" |sp2_training_data_UC$Samples == "PRISM|8803" |sp2_training_data_UC$Samples == "PRISM|8805" |sp2_training_data_UC$Samples == "PRISM|8809"|sp2_training_data_UC$Samples == "PRISM|8815" |sp2_training_data_UC$Samples == "PRISM|8844"|sp2_training_data_UC$Samples == "PRISM|8846" | sp2_training_data_UC$Samples == "PRISM|8849" |sp2_training_data_UC$Samples == "PRISM|8882" |sp2_training_data_UC$Samples == "PRISM|8894" |sp2_training_data_UC$Samples == "PRISM|8898" |sp2_training_data_UC$Samples == "PRISM|8924" |sp2_training_data_UC$Samples == "PRISM|8932" |sp2_training_data_UC$Samples == "PRISM|8982" |sp2_training_data_UC$Samples == "PRISM|8998"|sp2_training_data_UC$Samples == "PRISM|9010" |sp2_training_data_UC$Samples == "PRISM|9018"|sp2_training_data_UC$Samples == "PRISM|9030" | sp2_training_data_UC$Samples == "PRISM|9033" |sp2_training_data_UC$Samples == "PRISM|9074" |sp2_training_data_UC$Samples == "PRISM|9079" |sp2_training_data_UC$Samples == "PRISM|9126" |sp2_training_data_UC$Samples == "PRISM|9148")
sp2_training_data_UC
X_train_UC <- subset (sp2_training_data_UC, select = -c(Samples))
X_train_UC
#X_train_UC <- log (X_train_UC+1)
X_train_UC
library (openxlsx)
write.xlsx(X_train_UC, file = "X_UC_metabolites_train.xlsx")
write.xlsx(sp2_edited, file = "sp2_edited.xlsx")
#VALIDATION DATA SET
sp2_edited
sp2_validation_data_UC <- sp2[155:221, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
sp2_validation_data_UC
UC_metabolite_validation_list <- sp2_validation_data_UC [0]
UC_metabolite_validation_list
sp2_validation_UC <- sp2_edited %>% filter (sp2_edited$Samples == "Validation|LLDeep_0001"|sp2_edited$Samples == "Validation|LLDeep_0003"|sp2_edited$Samples == "Validation|LLDeep_0010" | sp2_edited$Samples == "Validation|LLDeep_0011"|sp2_edited$Samples == "Validation|LLDeep_0012"|sp2_edited$Samples == "Validation|LLDeep_0015" |sp2_edited$Samples == "Validation|LLDeep_0018" |sp2_edited$Samples == "Validation|LLDeep_0021" |sp2_edited$Samples == "Validation|LLDeep_0022" |sp2_edited$Samples == "Validation|LLDeep_0024" |sp2_edited$Samples == "Validation|LLDeep_0026" |sp2_edited$Samples == "Validation|LLDeep_0027" |sp2_edited$Samples == "Validation|LLDeep_0028" |sp2_edited$Samples == "Validation|LLDeep_0029" |sp2_edited$Samples == "Validation|LLDeep_0030" |sp2_edited$Samples == "Validation|LLDeep_0033" |sp2_edited$Samples == "Validation|LLDeep_0034" |sp2_edited$Samples == "Validation|LLDeep_0037" |sp2_edited$Samples == "Validation|LLDeep_0039" |sp2_edited$Samples == "Validation|LLDeep_0043" |sp2_edited$Samples == "Validation|LLDeep_0047" |sp2_edited$Samples == "Validation|LLDeep_0052" |sp2_edited$Samples == "Validation|UMCGIBD00122" |sp2_edited$Samples == "Validation|UMCGIBD00167"|sp2_edited$Samples == "Validation|UMCGIBD00208"| sp2_edited$Samples == "Validation|UMCGIBD00529" |sp2_edited$Samples == "Validation|UMCGIBD00371"|sp2_edited$Samples == "Validation|UMCGIBD00613"|sp2_edited$Samples == "Validation|UMCGIBD00004" |sp2_edited$Samples == "Validation|UMCGIBD00053"|sp2_edited$Samples == "Validation|UMCGIBD00269"|sp2_edited$Samples == "Validation|UMCGIBD00250" |sp2_edited$Samples == "Validation|UMCGIBD00327"|sp2_edited$Samples == "Validation|UMCGIBD00249" |sp2_edited$Samples == "Validation|UMCGIBD00461" |sp2_edited$Samples == "Validation|UMCGIBD00266"|sp2_edited$Samples == "Validation|UMCGIBD00347" |sp2_edited$Samples == "Validation|UMCGIBD00645" |sp2_edited$Samples == "Validation|UMCGIBD00361"|sp2_edited$Samples == "Validation|UMCGIBD00412" |sp2_edited$Samples == "Validation|UMCGIBD00539" |sp2_edited$Samples == "Validation|UMCGIBD00389"|sp2_edited$Samples == "Validation|UMCGIBD00588" |sp2_edited$Samples == "Validation|UMCGIBD00393"|sp2_edited$Samples == "Validation|UMCGIBD00593")
sp2_validation_UC
X_UC_metabolites_validation <- subset (sp2_validation_UC , select = -c(Samples))
X_UC_metabolites_validation
X_UC_metabolites_validation <- log (X_UC_metabolites_validation+1)
X_UC_metabolites_validation
library (openxlsx)
write.xlsx(X_UC_metabolites_validation, file = "X_UC_metabolites_validation.xlsx")
2. MICROBIOTA: Data Preparation Dependent and Independent Variables
#Supplementary Dataset 4-Per-subject microbial species relative abundance profiles.xlsx
data_file <- "~/Desktop/IBD_article/Supplementary Dataset 4-Per-subject microbial species relative abundance profiles.xlsx"
if(file.exists(data_file)){
Sp4_Per_subject_microbiota_relative_abundance_profiles <- read_excel(path = data_file)
} else {
print("Supplementary Dataset 4-Per-microbial metabolite relative abundance profiles.xlsx. Check the location of the file relative to your Rmd file.")
}
Sp4_Per_subject_microbiota_relative_abundance_profiles
sp4 <- as.data.frame (t(Sp4_Per_subject_microbiota_relative_abundance_profiles))
sp4
names (sp4) <- sp4 %>% slice (1) %>% unlist ()
sp4<- sp4 %>% slice (-1)
sp4
2.1 CD - Dependent Variable (Y)
# TRAINING DATA SET
Y.diagnosis.microbiota <- sp4[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.diagnosis.microbiota$Diagnosis
Y.diagnosis.microbiota %>% dplyr::select (Diagnosis)
Y.diagnosis.microbiota <-as.factor (Y.diagnosis.microbiota$Diagnosis)
Y.diagnosis.microbiota
# VALIDATION DATA SET
Y.diagnosis_validation.microbiota <- sp4[156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.diagnosis_validation.microbiota$Diagnosis
Y.diagnosis_validation.microbiota <-as.factor (Y.diagnosis_validation.microbiota$Diagnosis)
Y.diagnosis_validation.microbiota
# TRAINING DATA SET
Y.age.microbiota <- sp4[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.age.microbiota$Age
Y.age.microbiota <-as.factor (Y.age.microbiota$Age)
Y.age.microbiota
# VALIDATION DATA SET
Y.age_validation.microbiota <- sp4[156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.age_validation.microbiota$Age
Y.age_validation.microbiota <-as.factor (Y.age_validation.microbiota$Age)
Y.age_validation.microbiota
# TRAINING DATA SET
Y.Fecal.Calprotectin.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.Fecal.Calprotectin.microbiota$Fecal.Calprotectin
Y.Fecal.Calprotectin.microbiota <-as.factor (Y.Fecal.Calprotectin.microbiota$Fecal.Calprotectin )
Y.Fecal.Calprotectin.microbiota
# VALIDATION DATA SET
Y.Fecal.Calprotectin_validation.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.Fecal.Calprotectin_validation.microbiota$Fecal.Calprotectin
Y.Fecal.Calprotectin_validation.microbiota <-as.factor (Y.Fecal.Calprotectin_validation.microbiota$Fecal.Calprotectin )
Y.Fecal.Calprotectin_validation.microbiota
# TRAINING DATA SET
Y.antibiotic.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.antibiotic.microbiota$antibiotic
Y.antibiotic.microbiota <-as.factor (Y.antibiotic.microbiota$antibiotic)
Y.antibiotic.microbiota
# VALIDATION DATA SET
Y.antibiotic_validation.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.antibiotic_validation.microbiota$antibiotic
Y.antibiotic_validation.microbiota <-as.factor (Y.antibiotic_validation.microbiota$antibiotic)
Y.antibiotic_validation.microbiota
Y.immunosuppressant.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.immunosuppressant.microbiota <- as.factor(Y.immunosuppressant.microbiota$immunosuppressant)
Y.immunosuppressant.microbiota
# VALIDATION DATA SET
Y.immunosuppressant_validation.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.immunosuppressant_validation.microbiota <- as.factor(Y.immunosuppressant_validation.microbiota$immunosuppressant)
Y.immunosuppressant_validation.microbiota
# TRAINING DATA SET
Y.steroids.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.steroids.microbiota$steroids
Y.steroids.microbiota <-as.factor (Y.steroids.microbiota$steroids)
Y.steroids.microbiota
# VALIDATION DATA SET
Y.steroids_validation.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.steroids_validation.microbiota$steroids
Y.steroids_validation.microbiota <-as.factor (Y.steroids_validation.microbiota$steroids)
Y.steroids_validation.microbiota
# TRAINING DATA SET
Y.mesalamine.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.mesalamine.microbiota$mesalamine
Y.mesalamine.microbiota <-as.factor (Y.mesalamine.microbiota$mesalamine)
Y.mesalamine.microbiota
# VALIDATION DATA SET
Y.mesalamine_validation.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.mesalamine_validation.microbiota$mesalamine
Y.mesalamine_validation.microbiota <-as.factor (Y.mesalamine_validation.microbiota$mesalamine)
Y.mesalamine_validation.microbiota
# TRAINING DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis.microbiota, file = "Y_CD_diagnosis_train_microbiota.xlsx")
write.xlsx(Y.age.microbiota, file = "Y_CD_age_train_microbiota.xlsx")
write.xlsx(Y.Fecal.Calprotectin.microbiota, file = "Y_CD_Fecal.Calprotectin_train_microbiota.xlsx")
write.xlsx(Y.mesalamine.microbiota, file = "Y_CD_mesalamine_train_microbiota.xlsx")
write.xlsx(Y.steroids.microbiota, file = "Y_CD_steroids_train_microbiota.xlsx")
write.xlsx(Y.antibiotic.microbiota, file = "Y_CD_antibiotics_train_microbiota.xlsx")
write.xlsx(Y.immunosuppressant.microbiota, file = "Y_CD_immunosuppressants_train_microbiota.xlsx")
# VALIDATION DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_validation.microbiota, file = "Y_CD_diagnosis_validation_microbiota.xlsx")
write.xlsx(Y.age_validation.microbiota, file = "Y_CD_age_validation_microbiota.xlsx")
write.xlsx(Y.Fecal.Calprotectin_validation.microbiota, file = "Y_CD_Fecal.Calprotectin_validation_microbiota.xlsx")
write.xlsx(Y.mesalamine_validation.microbiota, file = "Y_CD_mesalamine_validation_microbiota.xlsx")
write.xlsx(Y.steroids_validation.microbiota, file = "Y_CD_steroids_validation_microbiota.xlsx")
write.xlsx(Y.antibiotic_validation.microbiota, file = "Y_CD_antibiotics_validation_microbiota.xlsx")
write.xlsx(Y.immunosuppressant_validation.microbiota, file = "Y_CD_immunosuppressants_validation_microbiota.xlsx")
2.2 CD - Independent Variable (Y)
# TRAINING DATA SET
sp4
sp4_filtered <- subset (sp4, select = -c(SRA_metagenome_name, Age, Diagnosis, antibiotic, Fecal.Calprotectin, immunosuppressant, mesalamine, steroids))
sp4_filtered
sp4_filtered [] <- lapply(sp4_filtered, as.numeric)
sp4_filtered
Sp4_Per_subject_microbiota_relative_abundance_profiles
column.names.microbiota <- colnames (Sp4_Per_subject_microbiota_relative_abundance_profiles)
column.names.microbiota <- as_vector (column.names.microbiota)
column.names.microbiota <- column.names.microbiota[(-1)]
sp4_filtered <- sp4_filtered %>% mutate (Samples = column.names.microbiota, .before = "Methanobrevibacter_smithii")
sp4_filtered
write.xlsx(sp4_filtered , file = "sp4_edited_Xavier.xlsx")
data_file <- "~/Desktop/IBD_article/sp4_edited_Xavier.xlsx"
if(file.exists(data_file)){
sp4_edited <- read_excel(path = data_file)
} else {
print("sp2_edited_Xavier. Check the location of the file relative to your Rmd file.")
}
sp4_edited
sp4_training_data <- sp4_edited %>% filter (str_detect (Samples,"PRISM"))
sp4_training_data
CD_train_microbiota <- sp4[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
CD_train_list_microbiota <- CD_train_microbiota [0]
CD_train_list_microbiota
sp4_training_data_CD1 <- sp4_training_data %>% filter (sp4_training_data$Samples == "PRISM|7122" |sp4_training_data$Samples == "PRISM|7147"|sp4_training_data$Samples == "PRISM|7150" | sp4_training_data$Samples == "PRISM|7153" |sp4_training_data$Samples == "PRISM|7184" |sp4_training_data$Samples == "PRISM|7238" |sp4_training_data$Samples == "PRISM|7406" |sp4_training_data$Samples == "PRISM|7408" |sp4_training_data$Samples == "PRISM|7421" |sp4_training_data$Samples == "PRISM|7445" |sp4_training_data$Samples == "PRISM|7486" |sp4_training_data$Samples == "PRISM|7547" |sp4_training_data$Samples == "PRISM|7658" |sp4_training_data$Samples == "PRISM|7662" |sp4_training_data$Samples == "PRISM|7744" |sp4_training_data$Samples == "PRISM|7759" |sp4_training_data$Samples == "PRISM|7791" |sp4_training_data$Samples == "PRISM|7843" |sp4_training_data$Samples == "PRISM|7847" |sp4_training_data$Samples == "PRISM|7855" |sp4_training_data$Samples == "PRISM|7858" |sp4_training_data$Samples == "PRISM|7860" |sp4_training_data$Samples == "PRISM|7861" |sp4_training_data$Samples == "PRISM|7862" |sp4_training_data$Samples == "PRISM|7870" |sp4_training_data$Samples == "PRISM|7874" |sp4_training_data$Samples == "PRISM|7875" |sp4_training_data$Samples == "PRISM|7875" |sp4_training_data$Samples == "PRISM|7879" |sp4_training_data$Samples == "PRISM|7899" |sp4_training_data$Samples == "PRISM|7904" |sp4_training_data$Samples == "PRISM|7906" |sp4_training_data$Samples == "PRISM|7908" |sp4_training_data$Samples == "PRISM|7909" |sp4_training_data$Samples == "PRISM|7910" |sp4_training_data$Samples == "PRISM|7911" |sp4_training_data$Samples == "PRISM|7912" |sp4_training_data$Samples == "PRISM|7938" |sp4_training_data$Samples == "PRISM|7941" |sp4_training_data$Samples == "PRISM|7947"| sp4_training_data$Samples == "PRISM|7948" |sp4_training_data$Samples == "PRISM|7955" |sp4_training_data$Samples == "PRISM|7971" |sp4_training_data$Samples == "PRISM|7989" |sp4_training_data$Samples == "PRISM|8095" |sp4_training_data$Samples == "PRISM|8226" |sp4_training_data$Samples == "PRISM|8244" |sp4_training_data$Samples == "PRISM|8264" |sp4_training_data$Samples == "PRISM|8283" |sp4_training_data$Samples == "PRISM|8332" |sp4_training_data$Samples == "PRISM|8336" |sp4_training_data$Samples == "PRISM|8361" |sp4_training_data$Samples == "PRISM|8374"| sp4_training_data$Samples == "PRISM|8377" |sp4_training_data$Samples == "PRISM|8406" |sp4_training_data$Samples == "PRISM|8452" |sp4_training_data$Samples == "PRISM|8462" |sp4_training_data$Samples == "PRISM|8466" |sp4_training_data$Samples == "PRISM|8467" |sp4_training_data$Samples == "PRISM|8475" |sp4_training_data$Samples == "PRISM|8483" |sp4_training_data$Samples == "PRISM|8485" |sp4_training_data$Samples == "PRISM|8496" |sp4_training_data$Samples == "PRISM|8523" |sp4_training_data$Samples == "PRISM|8534" |sp4_training_data$Samples == "PRISM|8537" |sp4_training_data$Samples == "PRISM|8550" |sp4_training_data$Samples == "PRISM|8564" |sp4_training_data$Samples == "PRISM|8565" |sp4_training_data$Samples == "PRISM|8573" |sp4_training_data$Samples == "PRISM|8577" |sp4_training_data$Samples == "PRISM|8589" |sp4_training_data$Samples == "PRISM|8591" |sp4_training_data$Samples == "PRISM|8592" |sp4_training_data$Samples == "PRISM|8624" )
sp4_training_data_CD1
sp4_training_data_CD2 <- sp4_training_data %>% filter(sp4_training_data$Samples == "PRISM|8629" |sp4_training_data$Samples == "PRISM|8675" |sp4_training_data$Samples == "PRISM|8683" |sp4_training_data$Samples == "PRISM|8746" |sp4_training_data$Samples == "PRISM|8749" | sp4_training_data$Samples == "PRISM|8753" |sp4_training_data$Samples == "PRISM|8754" |sp4_training_data$Samples == "PRISM|8758" |sp4_training_data$Samples == "PRISM|8764" |sp4_training_data$Samples == "PRISM|8765"| sp4_training_data$Samples == "PRISM|8774" |sp4_training_data$Samples == "PRISM|8776" |sp4_training_data$Samples == "PRISM|8783" |sp4_training_data$Samples == "PRISM|8784" |sp4_training_data$Samples == "PRISM|8788" |sp4_training_data$Samples == "PRISM|8789" |sp4_training_data$Samples == "PRISM|8794" |sp4_training_data$Samples == "PRISM|8800" |sp4_training_data$Samples == "PRISM|8802" |sp4_training_data$Samples == "PRISM|8806" |sp4_training_data$Samples == "PRISM|8807" |sp4_training_data$Samples == "PRISM|8841" |sp4_training_data$Samples == "PRISM|8843" |sp4_training_data$Samples == "PRISM|8847" |sp4_training_data$Samples == "PRISM|8878" |sp4_training_data$Samples == "PRISM|8892"| sp4_training_data$Samples == "PRISM|9126" |sp4_training_data$Samples == "PRISM|9148")
sp4_training_data_CD2
sp4_training_data_CD <- rbind (sp4_training_data_CD1, sp4_training_data_CD2)
sp4_training_data_CD
X_train_microbiota <- subset (sp4_training_data_CD, select = -c(Samples))
X_train_microbiota
X_CD_microbiota_train_not_log <- X_train_microbiota
write.xlsx(X_CD_microbiota_train_not_log, file = "X_CD_microbiota_train_not_log.xlsx")
X_train_microbiota <- log (X_train_microbiota+1)
X_train_microbiota
library (openxlsx)
write.xlsx(X_train_microbiota, file = "X_CD_microbiota_train.xlsx")
# VALIDATION DATA SET
sp4_edited
sp4_validation_data <- sp4[156:221, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
sp4_validation_data
CD_metabolite_validation_list_microbiota <- sp4_validation_data [0]
CD_metabolite_validation_list_microbiota
sp4_validation_CD_microbiota <- sp4_edited %>% filter (sp4_edited$Samples == "Validation|LLDeep_0001"|sp4_edited$Samples == "Validation|LLDeep_0003"|sp4_edited$Samples == "Validation|LLDeep_0010" | sp4_edited$Samples == "Validation|LLDeep_0011"|sp4_edited$Samples == "Validation|LLDeep_0012"|sp4_edited$Samples == "Validation|LLDeep_0015" |sp4_edited$Samples == "Validation|LLDeep_0018" |sp4_edited$Samples == "Validation|LLDeep_0021" |sp4_edited$Samples == "Validation|LLDeep_0022" |sp4_edited$Samples == "Validation|LLDeep_0024" |sp4_edited$Samples == "Validation|LLDeep_0026" |sp4_edited$Samples == "Validation|LLDeep_0027" |sp4_edited$Samples == "Validation|LLDeep_0028" |sp4_edited$Samples == "Validation|LLDeep_0029" |sp4_edited$Samples == "Validation|LLDeep_0030" |sp4_edited$Samples == "Validation|LLDeep_0033" |sp4_edited$Samples == "Validation|LLDeep_0034" |sp4_edited$Samples == "Validation|LLDeep_0037" |sp4_edited$Samples == "Validation|LLDeep_0039" |sp4_edited$Samples == "Validation|LLDeep_0043" |sp4_edited$Samples == "Validation|LLDeep_0047" |sp4_edited$Samples == "Validation|LLDeep_0052" |sp4_edited$Samples == "Validation|UMCGIBD00072" |sp4_edited$Samples == "Validation|UMCGIBD00030"|sp4_edited$Samples == "Validation|UMCGIBD00032"| sp4_edited$Samples == "Validation|UMCGIBD00145" |sp4_edited$Samples == "Validation|UMCGIBD00485"|sp4_edited$Samples == "Validation|UMCGIBD00041"|sp4_edited$Samples == "Validation|UMCGIBD00126" |sp4_edited$Samples == "Validation|UMCGIBD00082"|sp4_edited$Samples == "Validation|UMCGIBD00442"|sp4_edited$Samples == "Validation|UMCGIBD00077" |sp4_edited$Samples == "Validation|UMCGIBD00141"|sp4_edited$Samples == "Validation|UMCGIBD00112" |sp4_edited$Samples == "Validation|UMCGIBD00508" |sp4_edited$Samples == "Validation|UMCGIBD00106"|sp4_edited$Samples == "Validation|UMCGIBD00458" |sp4_edited$Samples == "Validation|UMCGIBD00254" |sp4_edited$Samples == "Validation|UMCGIBD00233"|sp4_edited$Samples == "Validation|UMCGIBD00238" |sp4_edited$Samples == "Validation|UMCGIBD00027" |sp4_edited$Samples == "Validation|UMCGIBD00064")
sp4_validation_CD_microbiota
X_CD_microbiota_validation <- subset (sp4_validation_CD_microbiota, select = -c(Samples))
X_CD_microbiota_validation
X_CD_microbiota_validation <- log (X_CD_microbiota_validation+1)
X_CD_microbiota_validation
library (openxlsx)
write.xlsx(X_CD_microbiota_validation, file = "X_CD_microbiota_validation.xlsx")
2.3 UC - Independent Variable (Y)
# TRAINING DATA SET
Y.diagnosis_UC.microbiota <- sp4[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.diagnosis_UC.microbiota$Diagnosis
Y.diagnosis_UC.microbiota <-as.factor (Y.diagnosis_UC.microbiota$Diagnosis)
Y.diagnosis_UC.microbiota
#VALIDATION DATA SET
Y.diagnosis_validation_UC.microbiota <- sp4[156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.diagnosis_validation_UC.microbiota$Diagnosis
Y.diagnosis_validation_UC.microbiota <-as.factor (Y.diagnosis_validation_UC.microbiota$Diagnosis)
Y.diagnosis_validation_UC.microbiota
# TRAINING DATA SET
Y.age_UC.microbiota <- sp4[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.age_UC.microbiota$Age
Y.age_UC.microbiota <-as.factor (Y.age_UC.microbiota$Age)
Y.age_UC.microbiota
# VALIDATION DATA SET
Y.age_validation_UC.microbiota <- sp4 %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.age_validation_UC.microbiota$Age
Y.age_validation_UC.microbiota <-as.factor (Y.age_validation_UC.microbiota$Age)
Y.age_validation_UC.microbiota
# TRAINING DATA SET
Y.Fecal.Calprotectin_UC.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.Fecal.Calprotectin_UC.microbiota$Fecal.Calprotectin
Y.Fecal.Calprotectin_UC.microbiota <-as.factor (Y.Fecal.Calprotectin_UC.microbiota$Fecal.Calprotectin )
Y.Fecal.Calprotectin_UC.microbiota
# VALIDATION DATA SET
Y.Fecal.Calprotectin_validation_UC.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.Fecal.Calprotectin_validation_UC.microbiota$Fecal.Calprotectin
Y.Fecal.Calprotectin_validation_UC.microbiota <-as.factor (Y.Fecal.Calprotectin_validation_UC.microbiota$Fecal.Calprotectin )
Y.Fecal.Calprotectin_validation_UC.microbiota
# TRAINING DATA SET
Y.antibiotic_UC.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.antibiotic_UC.microbiota$antibiotic
Y.antibiotic_UC.microbiota <-as.factor (Y.antibiotic_UC.microbiota$antibiotic)
Y.antibiotic_UC.microbiota
# VALIDATION DATA SET
Y.antibiotic_validation_UC.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.antibiotic_validation_UC.microbiota$antibiotic
Y.antibiotic_validation_UC.microbiota <-as.factor (Y.antibiotic_validation_UC.microbiota$antibiotic)
Y.antibiotic_validation_UC.microbiota
# TRAINING DATA SET
Y.immunosuppressant_UC.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.immunosuppressant_UC.microbiota <- as.factor(Y.immunosuppressant_UC.microbiota$immunosuppressant)
Y.immunosuppressant_UC.microbiota
# VALIDATION DATA SET
Y.immunosuppressant_validation_UC.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.immunosuppressant_validation_UC.microbiota <- as.factor(Y.immunosuppressant_validation_UC.microbiota$immunosuppressant)
Y.immunosuppressant_validation_UC.microbiota
# TRAINING DATA SET
Y.steroids_UC.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.steroids_UC.microbiota$steroids
Y.steroids_UC.microbiota <-as.factor (Y.steroids_UC.microbiota$steroids)
Y.steroids_UC.microbiota
# VALIDATION DATA SET
Y.steroids_validation_UC.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.steroids_validation_UC.microbiota$steroids
Y.steroids_validation_UC.microbiota <-as.factor (Y.steroids_validation_UC.microbiota$steroids)
Y.steroids_validation_UC.microbiota
Y.mesalamine_UC.microbiota <- sp4 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.mesalamine_UC.microbiota$mesalamine
Y.mesalamine_UC.microbiota <-as.factor (Y.mesalamine_UC.microbiota$mesalamine)
Y.mesalamine_UC.microbiota
# VALIDATION DATA SET
Y.mesalamine_validation_UC.microbiota <- sp4 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.mesalamine_validation_UC.microbiota$mesalamine
Y.mesalamine_validation_UC.microbiota <-as.factor (Y.mesalamine_validation_UC.microbiota$mesalamine)
Y.mesalamine_validation_UC.microbiota
# TRAINING DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_UC.microbiota, file = "Y_UC_diagnosis_train_microbiota.xlsx")
write.xlsx(Y.age_UC.microbiota, file = "Y_UC_age_train_microbiota.xlsx")
write.xlsx(Y.Fecal.Calprotectin_UC.microbiota, file = "Y_UC_Fecal.Calprotectin_train_microbiota.xlsx")
write.xlsx(Y.mesalamine_UC.microbiota, file = "Y_UC_mesalamine_train_microbiota.xlsx")
write.xlsx(Y.steroids_UC.microbiota, file = "Y_UC_steroids_train_microbiota.xlsx")
write.xlsx(Y.antibiotic_UC.microbiota, file = "Y_UC_antibiotics_train_microbiota.xlsx")
write.xlsx(Y.immunosuppressant_UC.microbiota, file = "Y_UC_immunosuppressants_train_microbiota.xlsx")
# VALIDATION DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_validation_UC.microbiota, file = "Y_UC_diagnosis_validation_microbiota.xlsx")
write.xlsx(Y.age_validation_UC.microbiota, file = "Y_UC_age_validation_microbiota.xlsx")
write.xlsx(Y.Fecal.Calprotectin_validation_UC.microbiota, file = "Y_UC_Fecal.Calprotectin_validation_microbiota.xlsx")
write.xlsx(Y.mesalamine_validation_UC.microbiota, file = "Y_UC_mesalamine_validation_microbiota.xlsx")
write.xlsx(Y.steroids_validation_UC.microbiota, file = "Y_UC_steroids_validation_microbiota.xlsx")
write.xlsx(Y.antibiotic_validation_UC.microbiota, file = "Y_UC_antibiotics_validation_microbiota.xlsx")
write.xlsx(Y.immunosuppressant_validation_UC.microbiota, file = "Y_UC_immunosuppressants_validation_microbiota.xlsx")
2.4 UC - Independent Variable (Y)
# TRAINING DATA SET
sp4_edited
sp4_training_data_UC <- sp4_edited %>% filter (str_detect (Samples,"PRISM"))
sp4_training_data_UC
UC_train.microbiota <- sp4[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
UC_train_list.microbiota <- UC_train.microbiota [0]
UC_train_list.microbiota
sp4_training_data_UC <- sp4_training_data_UC %>% filter (sp4_training_data_UC$Samples == "PRISM|7496" |sp4_training_data_UC$Samples == "PRISM|7506"|sp4_training_data_UC$Samples == "PRISM|7662" | sp4_training_data_UC$Samples == "PRISM|7762" |sp4_training_data_UC$Samples == "PRISM|7776"|sp4_training_data_UC$Samples == "PRISM|7847" |sp4_training_data_UC$Samples == "PRISM|7852" |sp4_training_data_UC$Samples == "PRISM|7855" |sp4_training_data_UC$Samples == "PRISM|7858" |sp4_training_data_UC$Samples == "PRISM|7860" |sp4_training_data_UC$Samples == "PRISM|7861" |sp4_training_data_UC$Samples == "PRISM|7862" |sp4_training_data_UC$Samples == "PRISM|7870" |sp4_training_data_UC$Samples == "PRISM|7874"|sp4_training_data_UC$Samples == "PRISM|7879" | sp4_training_data_UC$Samples == "PRISM|7897" |sp4_training_data_UC$Samples == "PRISM|7899" |sp4_training_data_UC$Samples == "PRISM|7904" |sp4_training_data_UC$Samples == "PRISM|7906" |sp4_training_data_UC$Samples == "PRISM|7908" |sp4_training_data_UC$Samples == "PRISM|7909" |sp4_training_data_UC$Samples == "PRISM|7910" |sp4_training_data_UC$Samples == "PRISM|7911"|sp4_training_data_UC$Samples == "PRISM|7912" |sp4_training_data_UC$Samples == "PRISM|7955"|sp4_training_data_UC$Samples == "PRISM|8096" | sp4_training_data_UC$Samples == "PRISM|8101" |sp4_training_data_UC$Samples == "PRISM|8106" |sp4_training_data_UC$Samples == "PRISM|8129" |sp4_training_data_UC$Samples == "PRISM|8244" |sp4_training_data_UC$Samples == "PRISM|8275" |sp4_training_data_UC$Samples == "PRISM|8283" |sp4_training_data_UC$Samples == "PRISM|8332" |sp4_training_data_UC$Samples == "PRISM|8441" |sp4_training_data_UC$Samples == "PRISM|8444"|sp4_training_data_UC$Samples == "PRISM|8447" |sp4_training_data_UC$Samples =="PRISM|8458"|sp4_training_data_UC$Samples == "PRISM|8464" | sp4_training_data_UC$Samples == "PRISM|8480" |sp4_training_data_UC$Samples == "PRISM|8502" |sp4_training_data_UC$Samples == "PRISM|8503" |sp4_training_data_UC$Samples == "PRISM|8511" |sp4_training_data_UC$Samples == "PRISM|8513" |sp4_training_data_UC$Samples == "PRISM|8515" |sp4_training_data_UC$Samples == "PRISM|8589" |sp4_training_data_UC$Samples == "PRISM|8605"|sp4_training_data_UC$Samples == "PRISM|8628" |sp4_training_data_UC$Samples == "PRISM|8667"|sp4_training_data_UC$Samples == "PRISM|8683" | sp4_training_data_UC$Samples == "PRISM|8692" |sp4_training_data_UC$Samples == "PRISM|8696" |sp4_training_data_UC$Samples == "PRISM|8728" |sp4_training_data_UC$Samples == "PRISM|8734" |sp4_training_data_UC$Samples == "PRISM|8735" |sp4_training_data_UC$Samples == "PRISM|8754" |sp4_training_data_UC$Samples == "PRISM|8764" |sp4_training_data_UC$Samples == "PRISM|8765"|sp4_training_data_UC$Samples == "PRISM|8774" |sp4_training_data_UC$Samples == "PRISM|8776"|sp4_training_data_UC$Samples == "PRISM|8778" | sp4_training_data_UC$Samples == "PRISM|8784" |sp4_training_data_UC$Samples == "PRISM|8785" |sp4_training_data_UC$Samples == "PRISM|8788" |sp4_training_data_UC$Samples == "PRISM|8789" |sp4_training_data_UC$Samples == "PRISM|8795" |sp4_training_data_UC$Samples == "PRISM|8803" |sp4_training_data_UC$Samples == "PRISM|8805" |sp4_training_data_UC$Samples == "PRISM|8809"|sp4_training_data_UC$Samples == "PRISM|8815" |sp4_training_data_UC$Samples == "PRISM|8844"|sp4_training_data_UC$Samples == "PRISM|8846" | sp4_training_data_UC$Samples == "PRISM|8849" |sp4_training_data_UC$Samples == "PRISM|8882" |sp4_training_data_UC$Samples == "PRISM|8894" |sp4_training_data_UC$Samples == "PRISM|8898" |sp4_training_data_UC$Samples == "PRISM|8924" |sp4_training_data_UC$Samples == "PRISM|8932" |sp4_training_data_UC$Samples == "PRISM|8982" |sp4_training_data_UC$Samples == "PRISM|8998"|sp4_training_data_UC$Samples == "PRISM|9010" |sp4_training_data_UC$Samples == "PRISM|9018"|sp4_training_data_UC$Samples == "PRISM|9030" | sp4_training_data_UC$Samples == "PRISM|9033" |sp4_training_data_UC$Samples == "PRISM|9074" |sp4_training_data_UC$Samples == "PRISM|9079" |sp4_training_data_UC$Samples == "PRISM|9126" |sp4_training_data_UC$Samples == "PRISM|9148")
sp4_training_data_UC
X_train_UC.microbiota <- subset (sp4_training_data_UC, select = -c(Samples))
X_train_UC.microbiota
X_UC_microbiota_train_not_log <- X_train_UC.microbiota
write.xlsx(X_UC_microbiota_train_not_log, file = "X_UC_microbiota_train_not_log.xlsx")
X_train_UC.microbiota <- log (X_train_UC.microbiota + 1)
X_train_UC.microbiota
library (openxlsx)
write.xlsx(X_train_UC.microbiota, file = "X_UC_microbiota_train.xlsx")
# VALIDATION DATA SET
sp4_edited
sp4_validation_data_UC <- sp4[156:221, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
sp4_validation_data_UC
UC_microbiota_validation_list <- sp4_validation_data_UC [0]
UC_microbiota_validation_list
sp4_validation_UC.microbiota <- sp4_edited %>% filter (sp4_edited$Samples == "Validation|LLDeep_0001"|sp4_edited$Samples == "Validation|LLDeep_0003"|sp4_edited$Samples == "Validation|LLDeep_0010" | sp4_edited$Samples == "Validation|LLDeep_0011"|sp4_edited$Samples == "Validation|LLDeep_0012"|sp4_edited$Samples == "Validation|LLDeep_0015" |sp4_edited$Samples == "Validation|LLDeep_0018" |sp4_edited$Samples == "Validation|LLDeep_0021" |sp4_edited$Samples == "Validation|LLDeep_0022" |sp4_edited$Samples == "Validation|LLDeep_0024" |sp4_edited$Samples == "Validation|LLDeep_0026" |sp4_edited$Samples == "Validation|LLDeep_0027" |sp4_edited$Samples == "Validation|LLDeep_0028" |sp4_edited$Samples == "Validation|LLDeep_0029" |sp4_edited$Samples == "Validation|LLDeep_0030" |sp4_edited$Samples == "Validation|LLDeep_0033" |sp4_edited$Samples == "Validation|LLDeep_0034" |sp4_edited$Samples == "Validation|LLDeep_0037" |sp4_edited$Samples == "Validation|LLDeep_0039" |sp4_edited$Samples == "Validation|LLDeep_0043" |sp4_edited$Samples == "Validation|LLDeep_0047" |sp4_edited$Samples == "Validation|LLDeep_0052" |sp4_edited$Samples == "Validation|UMCGIBD00122" |sp4_edited$Samples == "Validation|UMCGIBD00167"|sp4_edited$Samples == "Validation|UMCGIBD00208"| sp4_edited$Samples == "Validation|UMCGIBD00529" |sp4_edited$Samples == "Validation|UMCGIBD00371"|sp4_edited$Samples == "Validation|UMCGIBD00613"|sp4_edited$Samples == "Validation|UMCGIBD00004" |sp4_edited$Samples == "Validation|UMCGIBD00053"|sp4_edited$Samples == "Validation|UMCGIBD00269"|sp4_edited$Samples == "Validation|UMCGIBD00250" |sp4_edited$Samples == "Validation|UMCGIBD00327"|sp4_edited$Samples == "Validation|UMCGIBD00249" |sp4_edited$Samples == "Validation|UMCGIBD00461" |sp4_edited$Samples == "Validation|UMCGIBD00266"|sp4_edited$Samples == "Validation|UMCGIBD00347" |sp4_edited$Samples == "Validation|UMCGIBD00645" |sp4_edited$Samples == "Validation|UMCGIBD00361"|sp4_edited$Samples == "Validation|UMCGIBD00412" |sp4_edited$Samples == "Validation|UMCGIBD00539" |sp4_edited$Samples == "Validation|UMCGIBD00389"|sp4_edited$Samples == "Validation|UMCGIBD00588" |sp4_edited$Samples == "Validation|UMCGIBD00393"|sp4_edited$Samples == "Validation|UMCGIBD00593")
sp4_validation_UC.microbiota
X_UC_microbiota_validation <- subset (sp4_validation_UC.microbiota , select = -c(Samples))
X_UC_microbiota_validation
X_UC_microbiota_validation <- log (X_UC_microbiota_validation+1)
X_UC_microbiota_validation
library (openxlsx)
write.xlsx (X_UC_microbiota_validation, file = "X_UC_microbiota_validation.xlsx")
3. ENZYMES: Data Preparation Dependent and Independent Variables
#Supplementary Dataset 6-Per-subject microbial enzyme species relative abundance profiles.xlsx
data_file <- "~/Desktop/IBD_article/Supplementary Dataset 6- Per-subject microbial enzyme relative abundance profiles.xlsx"
if(file.exists(data_file)){
Sp6_Per_subject_enzyme_relative_abundance_profiles <- read_excel(path = data_file)
} else {
print("Supplementary Dataset 6: Per-subject microbial enzyme relative abundance profiles. Check the location of the file relative to your Rmd file.")
}
Sp6_Per_subject_enzyme_relative_abundance_profiles
sp6 <- as.data.frame (t(Sp6_Per_subject_enzyme_relative_abundance_profiles))
sp6
names (sp6) <- sp6%>% slice (1) %>% unlist ()
sp6<- sp6 %>% slice (-1)
sp6
3.1 CD - Dependent Variable (Y)
#TRAINING DATA SET
Y.diagnosis.enzymes <- sp6[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.diagnosis.enzymes$Diagnosis
Y.diagnosis.enzymes %>% select (Diagnosis)
Y.diagnosis.enzymes <-as.factor (Y.diagnosis.enzymes$Diagnosis)
Y.diagnosis.enzymes
#VALIDATION DATA SET
Y.diagnosis_validation.enzymes <- sp6[156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.diagnosis_validation.enzymes$Diagnosis
Y.diagnosis_validation.enzymes <-as.factor (Y.diagnosis_validation.enzymes$Diagnosis)
Y.diagnosis_validation.enzymes
#TRAINING DATA SET
Y.age.enzymes <- sp6[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.age.enzymes$Age
Y.age.enzymes <-as.factor (Y.age.enzymes$Age)
Y.age.enzymes
#VALIDATION DATA SET
Y.age_validation.enzymes <- sp6[156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.age_validation.enzymes$Age
Y.age_validation.enzymes <-as.factor (Y.age_validation.enzymes$Age)
Y.age_validation.enzymes
#TRAINING DATA SET
Y.Fecal.Calprotectin.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.Fecal.Calprotectin.enzymes$Fecal.Calprotectin
Y.Fecal.Calprotectin.enzymes <-as.factor (Y.Fecal.Calprotectin.enzymes$Fecal.Calprotectin )
Y.Fecal.Calprotectin.enzymes
#VALIDATION DATA SET
Y.Fecal.Calprotectin_validation.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.Fecal.Calprotectin_validation.enzymes$Fecal.Calprotectin
Y.Fecal.Calprotectin_validation.enzymes <-as.factor (Y.Fecal.Calprotectin_validation.enzymes$Fecal.Calprotectin )
Y.Fecal.Calprotectin_validation.enzymes
#TRAINING DATA SET
Y.antibiotic.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.antibiotic.enzymes$antibiotic
Y.antibiotic.enzymes <-as.factor (Y.antibiotic.enzymes$antibiotic)
Y.antibiotic.enzymes
#VALIDATION DATA SET
Y.antibiotic_validation.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.antibiotic_validation.enzymes$antibiotic
Y.antibiotic_validation.enzymes <-as.factor (Y.antibiotic_validation.enzymes$antibiotic)
Y.antibiotic_validation.enzymes
#TRAINING DATA SET
Y.immunosuppressant.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.immunosuppressant.enzymes <- as.factor(Y.immunosuppressant.enzymes$immunosuppressant)
Y.immunosuppressant.enzymes
#VALIDATION DATA SET
Y.immunosuppressant_validation.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.immunosuppressant_validation.enzymes <- as.factor(Y.immunosuppressant_validation.enzymes$immunosuppressant)
Y.immunosuppressant_validation.enzymes
#TRAINING DATA SET
Y.steroids.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.steroids.enzymes$steroids
Y.steroids.enzymes <-as.factor (Y.steroids.enzymes$steroids)
Y.steroids.enzymes
#VALIDATION DATA SET
Y.steroids_validation.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.steroids_validation.enzymes$steroids
Y.steroids_validation.enzymes <-as.factor (Y.steroids_validation.enzymes$steroids)
Y.steroids_validation.enzymes
#TRAINING DATA SET
Y.mesalamine.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.mesalamine.enzymes$mesalamine
Y.mesalamine.enzymes <-as.factor (Y.mesalamine.enzymes$mesalamine)
Y.mesalamine.enzymes
#VALIDATION DATA SET
Y.mesalamine_validation.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
Y.mesalamine_validation.enzymes$mesalamine
Y.mesalamine_validation.enzymes <-as.factor (Y.mesalamine_validation.enzymes$mesalamine)
Y.mesalamine_validation.enzymes
#TRAINING DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis.enzymes, file = "Y_CD_diagnosis_train_enzymes.xlsx")
write.xlsx(Y.age.enzymes, file = "Y_CD_age_train_enzymes.xlsx")
write.xlsx(Y.Fecal.Calprotectin.enzymes, file = "Y_CD_Fecal.Calprotectin_train_enzymes.xlsx")
write.xlsx(Y.mesalamine.enzymes, file = "Y_CD_mesalamine_train_enzymes.xlsx")
write.xlsx(Y.steroids.enzymes, file = "Y_CD_steroids_train_enzymes.xlsx")
write.xlsx(Y.antibiotic.enzymes, file = "Y_CD_antibiotics_train_enzymes.xlsx")
write.xlsx(Y.immunosuppressant.enzymes, file = "Y_CD_immunosuppressants_train_enzymes.xlsx")
#VALIDATION DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_validation.enzymes, file = "Y_CD_diagnosis_validation_enzymes.xlsx")
write.xlsx(Y.age_validation.enzymes, file = "Y_CD_age_validation_enzymes.xlsx")
write.xlsx(Y.Fecal.Calprotectin_validation.enzymes, file = "Y_CD_Fecal.Calprotectin_validation_enzymes.xlsx")
write.xlsx(Y.mesalamine_validation.enzymes, file = "Y_CD_mesalamine_validation_enzymes.xlsx")
write.xlsx(Y.steroids_validation.enzymes, file = "Y_CD_steroids_validation_enzymes.xlsx")
write.xlsx(Y.antibiotic_validation.enzymes, file = "Y_CD_antibiotics_validation_enzymes.xlsx")
write.xlsx(Y.immunosuppressant_validation.enzymes, file = "Y_CD_immunosuppressants_validation_enzymes.xlsx")
3.2 CD - Independent Variable (Y)
# TRAINING DATA SET
sp6
sp6_filtered <- subset (sp6, select = -c(SRA_metagenome_name, Age, Diagnosis, antibiotic, Fecal.Calprotectin, immunosuppressant, mesalamine, steroids))
sp6_filtered
sp6_filtered [] <- lapply(sp6_filtered, as.numeric)
sp6_filtered
Sp6_Per_subject_enzyme_relative_abundance_profiles
column.names.enzymes <- colnames (Sp6_Per_subject_enzyme_relative_abundance_profiles)
column.names.enzymes <- as_vector (column.names.enzymes)
column.names.enzymes <- column.names.enzymes[(-1)]
sp6_filtered <- sp6_filtered %>% mutate (Samples = column.names.enzymes, .before = "1.1.1.1: Alcohol dehydrogenase")
sp6_filtered
write.xlsx(sp6_filtered , file = "sp6_edited_Xavier.xlsx")
data_file <- "~/Desktop/IBD_article/sp6_edited_Xavier.xlsx"
if(file.exists(data_file)){
sp6_edited <- read_excel(path = data_file)
} else {
print("sp6_edited_Xavier. Check the location of the file relative to your Rmd file.")
}
sp6_edited
sp6_training_data <- sp6_edited %>% filter (str_detect (Samples,"PRISM"))
sp6_training_data
CD_train_enzymes <- sp6[1:155, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
CD_train_list_enzymes <- CD_train_enzymes [0]
CD_train_list_enzymes
sp6_training_data_CD1 <- sp6_training_data %>% filter (sp6_training_data$Samples == "PRISM|7122" |sp6_training_data$Samples == "PRISM|7147"|sp6_training_data$Samples == "PRISM|7150" | sp6_training_data$Samples == "PRISM|7153" |sp6_training_data$Samples == "PRISM|7184" |sp6_training_data$Samples == "PRISM|7238" |sp6_training_data$Samples == "PRISM|7406" |sp6_training_data$Samples == "PRISM|7408" |sp6_training_data$Samples == "PRISM|7421" |sp6_training_data$Samples == "PRISM|7445" |sp6_training_data$Samples == "PRISM|7486" |sp6_training_data$Samples == "PRISM|7547" |sp6_training_data$Samples == "PRISM|7658" |sp6_training_data$Samples == "PRISM|7662" |sp6_training_data$Samples == "PRISM|7744" |sp6_training_data$Samples == "PRISM|7759" |sp6_training_data$Samples == "PRISM|7791" |sp6_training_data$Samples == "PRISM|7843" |sp6_training_data$Samples == "PRISM|7847" |sp6_training_data$Samples == "PRISM|7855" |sp6_training_data$Samples == "PRISM|7858" |sp6_training_data$Samples == "PRISM|7860" |sp6_training_data$Samples == "PRISM|7861" |sp6_training_data$Samples == "PRISM|7862" |sp6_training_data$Samples == "PRISM|7870" |sp6_training_data$Samples == "PRISM|7874" |sp6_training_data$Samples == "PRISM|7875" |sp6_training_data$Samples == "PRISM|7875" |sp6_training_data$Samples == "PRISM|7879" |sp6_training_data$Samples == "PRISM|7899" |sp6_training_data$Samples == "PRISM|7904" |sp6_training_data$Samples == "PRISM|7906" |sp6_training_data$Samples == "PRISM|7908" |sp6_training_data$Samples == "PRISM|7909" |sp6_training_data$Samples == "PRISM|7910" |sp6_training_data$Samples == "PRISM|7911" |sp6_training_data$Samples == "PRISM|7912" |sp6_training_data$Samples == "PRISM|7938" |sp6_training_data$Samples == "PRISM|7941" |sp6_training_data$Samples == "PRISM|7947"| sp6_training_data$Samples == "PRISM|7948" |sp6_training_data$Samples == "PRISM|7955" |sp6_training_data$Samples == "PRISM|7971" |sp6_training_data$Samples == "PRISM|7989" |sp6_training_data$Samples == "PRISM|8095" |sp6_training_data$Samples == "PRISM|8226" |sp6_training_data$Samples == "PRISM|8244" |sp6_training_data$Samples == "PRISM|8264" |sp6_training_data$Samples == "PRISM|8283" |sp6_training_data$Samples == "PRISM|8332" |sp6_training_data$Samples == "PRISM|8336" |sp6_training_data$Samples == "PRISM|8361" |sp6_training_data$Samples == "PRISM|8374"| sp6_training_data$Samples == "PRISM|8377" |sp6_training_data$Samples == "PRISM|8406" |sp6_training_data$Samples == "PRISM|8452" |sp6_training_data$Samples == "PRISM|8462" |sp6_training_data$Samples == "PRISM|8466" |sp6_training_data$Samples == "PRISM|8467" |sp6_training_data$Samples == "PRISM|8475" |sp6_training_data$Samples == "PRISM|8483" |sp6_training_data$Samples == "PRISM|8485" |sp6_training_data$Samples == "PRISM|8496" |sp6_training_data$Samples == "PRISM|8523" |sp6_training_data$Samples == "PRISM|8534" |sp6_training_data$Samples == "PRISM|8537" |sp6_training_data$Samples == "PRISM|8550" |sp6_training_data$Samples == "PRISM|8564" |sp6_training_data$Samples == "PRISM|8565" |sp6_training_data$Samples == "PRISM|8573" |sp6_training_data$Samples == "PRISM|8577" |sp6_training_data$Samples == "PRISM|8589" |sp6_training_data$Samples == "PRISM|8591" |sp6_training_data$Samples == "PRISM|8592" |sp6_training_data$Samples == "PRISM|8624" )
sp6_training_data_CD1
sp6_training_data_CD2 <- sp6_training_data %>% filter(sp6_training_data$Samples == "PRISM|8629" |sp6_training_data$Samples == "PRISM|8675" |sp6_training_data$Samples == "PRISM|8683" |sp6_training_data$Samples == "PRISM|8746" |sp6_training_data$Samples == "PRISM|8749" | sp6_training_data$Samples == "PRISM|8753" |sp6_training_data$Samples == "PRISM|8754" |sp6_training_data$Samples == "PRISM|8758" |sp6_training_data$Samples == "PRISM|8764" |sp6_training_data$Samples == "PRISM|8765"| sp6_training_data$Samples == "PRISM|8774" |sp6_training_data$Samples == "PRISM|8776" |sp6_training_data$Samples == "PRISM|8783" |sp6_training_data$Samples == "PRISM|8784" |sp6_training_data$Samples == "PRISM|8788" |sp6_training_data$Samples == "PRISM|8789" |sp6_training_data$Samples == "PRISM|8794" |sp6_training_data$Samples == "PRISM|8800" |sp6_training_data$Samples == "PRISM|8802" |sp6_training_data$Samples == "PRISM|8806" |sp6_training_data$Samples == "PRISM|8807" |sp6_training_data$Samples == "PRISM|8841" |sp6_training_data$Samples == "PRISM|8843" |sp6_training_data$Samples == "PRISM|8847" |sp6_training_data$Samples == "PRISM|8878" |sp6_training_data$Samples == "PRISM|8892"| sp6_training_data$Samples == "PRISM|9126" |sp6_training_data$Samples == "PRISM|9148")
sp6_training_data_CD2
sp6_training_data_CD <- rbind (sp6_training_data_CD1, sp6_training_data_CD2)
sp6_training_data_CD
X_train_enzymes <- subset (sp6_training_data_CD, select = -c(Samples))
X_train_enzymes
X_train_enzymes <- log (X_train_enzymes+1)
X_train_enzymes
library (openxlsx)
write.xlsx(X_train_enzymes, file = "X_CD_enzymes_train.xlsx")
```
```{r Enzymes - CD - Validation - Data Wrangling 1}
# VALIDATION DATA SET
sp6_edited
sp6_validation_data <- sp6[156:221, ] %>% filter (Diagnosis == "CD" | Diagnosis == "Control")
sp6_validation_data
CD_enzymes_validation_list <- sp6_validation_data [0]
CD_enzymes_validation_list
```
```{r Enzymes - CD - Validation - Select Columns}
sp6_validation_CD_enzymes <- sp6_edited %>% filter (sp6_edited$Samples == "Validation|LLDeep_0001"|sp6_edited$Samples == "Validation|LLDeep_0003"|sp6_edited$Samples == "Validation|LLDeep_0010" | sp6_edited$Samples == "Validation|LLDeep_0011"|sp6_edited$Samples == "Validation|LLDeep_0012"|sp6_edited$Samples == "Validation|LLDeep_0015" |sp6_edited$Samples == "Validation|LLDeep_0018" |sp6_edited$Samples == "Validation|LLDeep_0021" |sp6_edited$Samples == "Validation|LLDeep_0022" |sp6_edited$Samples == "Validation|LLDeep_0024" |sp6_edited$Samples == "Validation|LLDeep_0026" |sp6_edited$Samples == "Validation|LLDeep_0027" |sp6_edited$Samples == "Validation|LLDeep_0028" |sp6_edited$Samples == "Validation|LLDeep_0029" |sp6_edited$Samples == "Validation|LLDeep_0030" |sp6_edited$Samples == "Validation|LLDeep_0033" |sp6_edited$Samples == "Validation|LLDeep_0034" |sp6_edited$Samples == "Validation|LLDeep_0037" |sp6_edited$Samples == "Validation|LLDeep_0039" |sp6_edited$Samples == "Validation|LLDeep_0043" |sp6_edited$Samples == "Validation|LLDeep_0047" |sp6_edited$Samples == "Validation|LLDeep_0052" |sp6_edited$Samples == "Validation|UMCGIBD00072" |sp6_edited$Samples == "Validation|UMCGIBD00030"|sp6_edited$Samples == "Validation|UMCGIBD00032"| sp6_edited$Samples == "Validation|UMCGIBD00145" |sp6_edited$Samples == "Validation|UMCGIBD00485"|sp6_edited$Samples == "Validation|UMCGIBD00041"|sp6_edited$Samples == "Validation|UMCGIBD00126" |sp6_edited$Samples == "Validation|UMCGIBD00082"|sp6_edited$Samples == "Validation|UMCGIBD00442"|sp6_edited$Samples == "Validation|UMCGIBD00077" |sp6_edited$Samples == "Validation|UMCGIBD00141"|sp6_edited$Samples == "Validation|UMCGIBD00112" |sp6_edited$Samples == "Validation|UMCGIBD00508" |sp6_edited$Samples == "Validation|UMCGIBD00106"|sp6_edited$Samples == "Validation|UMCGIBD00458" |sp6_edited$Samples == "Validation|UMCGIBD00254" |sp6_edited$Samples == "Validation|UMCGIBD00233"|sp6_edited$Samples == "Validation|UMCGIBD00238" |sp6_edited$Samples == "Validation|UMCGIBD00027" |sp6_edited$Samples == "Validation|UMCGIBD00064")
sp6_validation_CD_enzymes
```
```{r Enzymes - CD - Validation - Combine Columns}
X_CD_enzymes_validation <- subset (sp6_validation_CD_enzymes, select = -c(Samples))
X_CD_enzymes_validation
```
```{r Enzymes - CD - Validation - Log Transformation}
X_CD_enzymes_validation <- log (X_CD_enzymes_validation+1)
X_CD_enzymes_validation
library (openxlsx)
write.xlsx(X_CD_enzymes_validation, file = "X_CD_enzymes_validation.xlsx")
```
# 3.3 UC - Dependent Variable (Y)
```{r Enzymes - UC: Diagnosis}
# TRAINING DATA SET
Y.diagnosis_UC.enzymes <- sp6[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.diagnosis_UC.enzymes$Diagnosis
Y.diagnosis_UC.enzymes <-as.factor (Y.diagnosis_UC.enzymes$Diagnosis)
Y.diagnosis_UC.enzymes
# VALIDATION DATA SET
Y.diagnosis_validation_UC.enzymes <- sp6[156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.diagnosis_validation_UC.enzymes$Diagnosis
Y.diagnosis_validation_UC.enzymes <-as.factor (Y.diagnosis_validation_UC.enzymes$Diagnosis)
Y.diagnosis_validation_UC.enzymes
```
```{r Enzymes - UC: Age}
# TRAINING DATA SET
Y.age_UC.enzymes <- sp6[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.age_UC.enzymes$Age
Y.age_UC.enzymes <-as.factor (Y.age_UC.enzymes$Age)
Y.age_UC.enzymes
# VALIDATION DATA SET
Y.age_validation_UC.enzymes <- sp6[156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.age_validation_UC.enzymes$Age
Y.age_validation_UC.enzymes <-as.factor (Y.age_validation_UC.enzymes$Age)
Y.age_validation_UC.enzymes
```
```{r Enzymes - UC: Fecal Calprotectin}
# TRAINING DATA SET
Y.Fecal.Calprotectin_UC.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.Fecal.Calprotectin_UC.enzymes$Fecal.Calprotectin
Y.Fecal.Calprotectin_UC.enzymes <-as.factor (Y.Fecal.Calprotectin_UC.enzymes$Fecal.Calprotectin )
Y.Fecal.Calprotectin_UC.enzymes
# VALIDATION DATA SET
Y.Fecal.Calprotectin_validation_UC.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.Fecal.Calprotectin_validation_UC.enzymes$Fecal.Calprotectin
Y.Fecal.Calprotectin_validation_UC.enzymes <-as.factor (Y.Fecal.Calprotectin_validation_UC.enzymes$Fecal.Calprotectin )
Y.Fecal.Calprotectin_validation_UC.enzymes
```
```{r Enzymes - UC: Antibiotic}
# TRAINING DATA SET
Y.antibiotic_UC.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.antibiotic_UC.enzymes$antibiotic
Y.antibiotic_UC.enzymes<-as.factor (Y.antibiotic_UC.enzymes$antibiotic)
Y.antibiotic_UC.enzymes
# VALIDATION DATA SET
Y.antibiotic_validation_UC.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.antibiotic_validation_UC.enzymes$antibiotic
Y.antibiotic_validation_UC.enzymes <-as.factor (Y.antibiotic_validation_UC.enzymes$antibiotic)
Y.antibiotic_validation_UC.enzymes
```
```{r Enzymes - UC: Immunosuppresant}
# TRAINING DATA SET
Y.immunosuppressant_UC.enzymes <- sp6 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.immunosuppressant_UC.enzyzmes <- as.factor(Y.immunosuppressant_UC.enzymes$immunosuppressant)
Y.immunosuppressant_UC.enzymes
# VALIDATION DATA SET
Y.immunosuppressant_validation_UC.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.immunosuppressant_validation_UC.enzymes <- as.factor(Y.immunosuppressant_validation_UC.enzymes$immunosuppressant)
Y.immunosuppressant_validation_UC.enzymes
```
```{r Enzymes - UC: Steroids}
# TRAINING DATA SET
Y.steroids_UC.enzymes <- sp4 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.steroids_UC.enzymes$steroids
Y.steroids_UC.enzymes <-as.factor (Y.steroids_UC.enzymes$steroids)
Y.steroids_UC.enzymes
# VALIDATION DATA SET
Y.steroids_validation_UC.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.steroids_validation_UC.enzymes$steroids
Y.steroids_validation_UC.enzymes <-as.factor (Y.steroids_validation_UC.enzymes$steroids)
Y.steroids_validation_UC.enzymes
```
```{r Enzymes - UC: Mesalamine}
# TRAINING DATA SET
Y.mesalamine_UC.enzymes <- sp4 [1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.mesalamine_UC.enzymes$mesalamine
Y.mesalamine_UC.enzymes <-as.factor (Y.mesalamine_UC.enzymes$mesalamine)
Y.mesalamine_UC.enzymes
# VALIDATION DATA SET
Y.mesalamine_validation_UC.enzymes <- sp6 [156:220, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
Y.mesalamine_validation_UC.enzymes$mesalamine
Y.mesalamine_validation_UC.enzymes <-as.factor (Y.mesalamine_validation_UC.enzymes$mesalamine)
Y.mesalamine_validation_UC.enzymes
```
```{r Enzymes - UC: Printing Dependent Variables - Training and Validation Data Sets}
# TRAINING DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_UC.enzymes, file = "Y_UC_diagnosis_train_enzymes.xlsx")
write.xlsx(Y.age_UC.enzymes, file = "Y_UC_age_train_enzymes.xlsx")
write.xlsx(Y.Fecal.Calprotectin_UC.enzymes, file = "Y_UC_Fecal.Calprotectin_train_enzymes.xlsx")
write.xlsx(Y.mesalamine_UC.enzymes, file = "Y_UC_mesalamine_train_enzymes.xlsx")
write.xlsx(Y.steroids_UC.enzymes, file = "Y_UC_steroids_train_enzymes.xlsx")
write.xlsx(Y.antibiotic_UC.enzymes, file = "Y_UC_antibiotics_train_enzymes.xlsx")
write.xlsx(Y.immunosuppressant_UC.enzymes, file = "Y_UC_immunosuppressants_train_enzymes.xlsx")
# VALIDATION DATA SET
library (openxlsx)
write.xlsx(Y.diagnosis_validation_UC.enzymes, file = "Y_UC_diagnosis_validation_enzymes.xlsx")
write.xlsx(Y.age_validation_UC.enzymes, file = "Y_UC_age_validation_enzymes.xlsx")
write.xlsx(Y.Fecal.Calprotectin_validation_UC.enzymes, file = "Y_UC_Fecal.Calprotectin_validation_enzymes.xlsx")
write.xlsx(Y.mesalamine_validation_UC.enzymes, file = "Y_UC_mesalamine_validation_enzymes.xlsx")
write.xlsx(Y.steroids_validation_UC.enzymes, file = "Y_UC_steroids_validation_enzymes.xlsx")
write.xlsx(Y.antibiotic_validation_UC.enzymes, file = "Y_UC_antibiotics_validation_enzymes.xlsx")
write.xlsx(Y.immunosuppressant_validation_UC.enzymes, file = "Y_UC_immunosuppressants_validation_enzymes.xlsx")
```
# 3.4 UC - Independent Variable (Y)
```{r Enzymes - UC - Training - Data Wrangling 1}
# TRAINING DATA SET
sp6_edited
sp6_training_data_UC <- sp6_edited %>% filter (str_detect (Samples,"PRISM"))
sp6_training_data_UC
```
```{r Enzymes - UC - Training - Data Wrangling 2}
UC_train.enzymes <- sp6[1:155, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
UC_train_list.enzymes <- UC_train.enzymes [0]
UC_train_list.enzymes
```
```{r Enzymes - UC - Training - Select Columns}
sp6_training_data_UC <- sp6_training_data_UC %>% filter (sp6_training_data_UC$Samples == "PRISM|7496" |sp6_training_data_UC$Samples == "PRISM|7506"|sp6_training_data_UC$Samples == "PRISM|7662" | sp6_training_data_UC$Samples == "PRISM|7762" |sp6_training_data_UC$Samples == "PRISM|7776"|sp6_training_data_UC$Samples == "PRISM|7847" |sp6_training_data_UC$Samples == "PRISM|7852" |sp6_training_data_UC$Samples == "PRISM|7855" |sp6_training_data_UC$Samples == "PRISM|7858" |sp6_training_data_UC$Samples == "PRISM|7860" |sp6_training_data_UC$Samples == "PRISM|7861" |sp6_training_data_UC$Samples == "PRISM|7862" |sp6_training_data_UC$Samples == "PRISM|7870" |sp6_training_data_UC$Samples == "PRISM|7874"|sp6_training_data_UC$Samples == "PRISM|7879" | sp6_training_data_UC$Samples == "PRISM|7897" |sp6_training_data_UC$Samples == "PRISM|7899" |sp6_training_data_UC$Samples == "PRISM|7904" |sp6_training_data_UC$Samples == "PRISM|7906" |sp6_training_data_UC$Samples == "PRISM|7908" |sp6_training_data_UC$Samples == "PRISM|7909" |sp6_training_data_UC$Samples == "PRISM|7910" |sp6_training_data_UC$Samples == "PRISM|7911"|sp6_training_data_UC$Samples == "PRISM|7912" |sp6_training_data_UC$Samples == "PRISM|7955"|sp6_training_data_UC$Samples == "PRISM|8096" | sp6_training_data_UC$Samples == "PRISM|8101" |sp6_training_data_UC$Samples == "PRISM|8106" |sp6_training_data_UC$Samples == "PRISM|8129" |sp6_training_data_UC$Samples == "PRISM|8244" |sp6_training_data_UC$Samples == "PRISM|8275" |sp6_training_data_UC$Samples == "PRISM|8283" |sp6_training_data_UC$Samples == "PRISM|8332" |sp6_training_data_UC$Samples == "PRISM|8441" |sp6_training_data_UC$Samples == "PRISM|8444"|sp6_training_data_UC$Samples == "PRISM|8447" |sp6_training_data_UC$Samples =="PRISM|8458"|sp6_training_data_UC$Samples == "PRISM|8464" | sp6_training_data_UC$Samples == "PRISM|8480" |sp6_training_data_UC$Samples == "PRISM|8502" |sp6_training_data_UC$Samples == "PRISM|8503" |sp6_training_data_UC$Samples == "PRISM|8511" |sp6_training_data_UC$Samples == "PRISM|8513" |sp6_training_data_UC$Samples == "PRISM|8515" |sp6_training_data_UC$Samples == "PRISM|8589" |sp6_training_data_UC$Samples == "PRISM|8605"|sp6_training_data_UC$Samples == "PRISM|8628" |sp6_training_data_UC$Samples == "PRISM|8667"|sp6_training_data_UC$Samples == "PRISM|8683" | sp6_training_data_UC$Samples == "PRISM|8692" |sp6_training_data_UC$Samples == "PRISM|8696" |sp6_training_data_UC$Samples == "PRISM|8728" |sp6_training_data_UC$Samples == "PRISM|8734" |sp6_training_data_UC$Samples == "PRISM|8735" |sp6_training_data_UC$Samples == "PRISM|8754" |sp6_training_data_UC$Samples == "PRISM|8764" |sp6_training_data_UC$Samples == "PRISM|8765"|sp6_training_data_UC$Samples == "PRISM|8774" |sp6_training_data_UC$Samples == "PRISM|8776"|sp6_training_data_UC$Samples == "PRISM|8778" | sp6_training_data_UC$Samples == "PRISM|8784" |sp6_training_data_UC$Samples == "PRISM|8785" |sp6_training_data_UC$Samples == "PRISM|8788" |sp6_training_data_UC$Samples == "PRISM|8789" |sp6_training_data_UC$Samples == "PRISM|8795" |sp6_training_data_UC$Samples == "PRISM|8803" |sp6_training_data_UC$Samples == "PRISM|8805" |sp6_training_data_UC$Samples == "PRISM|8809"|sp6_training_data_UC$Samples == "PRISM|8815" |sp6_training_data_UC$Samples == "PRISM|8844"|sp6_training_data_UC$Samples == "PRISM|8846" | sp6_training_data_UC$Samples == "PRISM|8849" |sp6_training_data_UC$Samples == "PRISM|8882" |sp6_training_data_UC$Samples == "PRISM|8894" |sp6_training_data_UC$Samples == "PRISM|8898" |sp6_training_data_UC$Samples == "PRISM|8924" |sp6_training_data_UC$Samples == "PRISM|8932" |sp6_training_data_UC$Samples == "PRISM|8982" |sp6_training_data_UC$Samples == "PRISM|8998"|sp6_training_data_UC$Samples == "PRISM|9010" |sp6_training_data_UC$Samples == "PRISM|9018"|sp6_training_data_UC$Samples == "PRISM|9030" | sp6_training_data_UC$Samples == "PRISM|9033" |sp6_training_data_UC$Samples == "PRISM|9074" |sp6_training_data_UC$Samples == "PRISM|9079" |sp6_training_data_UC$Samples == "PRISM|9126" |sp6_training_data_UC$Samples == "PRISM|9148")
sp6_training_data_UC
```
```{r Enzymes - UC - Training - Combine Matrices}
X_train_UC.enzymes <- subset (sp6_training_data_UC, select = -c(Samples))
X_train_UC.enzymes
```
```{r Enzymes - UC - Training - Log Transformation}
X_train_UC.enzymes <- log (X_train_UC.enzymes+1)
X_train_UC.enzymes
library (openxlsx)
write.xlsx(X_train_UC.enzymes, file = "X_UC_enzymes_train.xlsx")
```
```{r Enzymes - UC - Validation - Data Wrangling 1}
# VALIDATION DATA SET
sp6_edited
sp6_validation_data_UC <- sp6[156:221, ] %>% filter (Diagnosis == "UC" | Diagnosis == "Control")
sp6_validation_data_UC
```
```{r Enzymes - UC - Validation - Data Wrangling 2}
UC_enzymes_validation_list <- sp6_validation_data_UC [0]
UC_enzymes_validation_list
```
```{r Enzymes - UC - Validation - Select Columns}
sp6_validation_UC.enzymes <- sp6_edited %>% filter (sp6_edited$Samples == "Validation|LLDeep_0001"|sp6_edited$Samples == "Validation|LLDeep_0003"|sp6_edited$Samples == "Validation|LLDeep_0010" | sp6_edited$Samples == "Validation|LLDeep_0011"|sp6_edited$Samples == "Validation|LLDeep_0012"|sp6_edited$Samples == "Validation|LLDeep_0015" |sp6_edited$Samples == "Validation|LLDeep_0018" |sp6_edited$Samples == "Validation|LLDeep_0021" |sp6_edited$Samples == "Validation|LLDeep_0022" |sp6_edited$Samples == "Validation|LLDeep_0024" |sp6_edited$Samples == "Validation|LLDeep_0026" |sp6_edited$Samples == "Validation|LLDeep_0027" |sp6_edited$Samples == "Validation|LLDeep_0028" |sp6_edited$Samples == "Validation|LLDeep_0029" |sp6_edited$Samples == "Validation|LLDeep_0030" |sp6_edited$Samples == "Validation|LLDeep_0033" |sp6_edited$Samples == "Validation|LLDeep_0034" |sp6_edited$Samples == "Validation|LLDeep_0037" |sp6_edited$Samples == "Validation|LLDeep_0039" |sp6_edited$Samples == "Validation|LLDeep_0043" |sp6_edited$Samples == "Validation|LLDeep_0047" |sp6_edited$Samples == "Validation|LLDeep_0052" |sp6_edited$Samples == "Validation|UMCGIBD00122" |sp6_edited$Samples == "Validation|UMCGIBD00167"|sp6_edited$Samples == "Validation|UMCGIBD00208"| sp6_edited$Samples == "Validation|UMCGIBD00529" |sp6_edited$Samples == "Validation|UMCGIBD00371"|sp6_edited$Samples == "Validation|UMCGIBD00613"|sp6_edited$Samples == "Validation|UMCGIBD00004" |sp6_edited$Samples == "Validation|UMCGIBD00053"|sp6_edited$Samples == "Validation|UMCGIBD00269"|sp6_edited$Samples == "Validation|UMCGIBD00250" |sp6_edited$Samples == "Validation|UMCGIBD00327"|sp6_edited$Samples == "Validation|UMCGIBD00249" |sp6_edited$Samples == "Validation|UMCGIBD00461" |sp6_edited$Samples == "Validation|UMCGIBD00266"|sp6_edited$Samples == "Validation|UMCGIBD00347" |sp6_edited$Samples == "Validation|UMCGIBD00645" |sp6_edited$Samples == "Validation|UMCGIBD00361"|sp6_edited$Samples == "Validation|UMCGIBD00412" |sp6_edited$Samples == "Validation|UMCGIBD00539" |sp6_edited$Samples == "Validation|UMCGIBD00389"|sp6_edited$Samples == "Validation|UMCGIBD00588" |sp6_edited$Samples == "Validation|UMCGIBD00393"|sp6_edited$Samples == "Validation|UMCGIBD00593")
sp6_validation_UC.enzymes
```
```{r Enzymes - UC - Validation - Combine Matrices}
X_UC_enzymes_validation <- subset (sp6_validation_UC.enzymes , select = -c(Samples))
X_UC_enzymes_validation
```
```{r Enzymes - UC - Validation - Log Transformation}
X_UC_enzymes_validation <- log (X_UC_enzymes_validation+1)
X_UC_enzymes_validation
library (openxlsx)
write.xlsx (X_UC_enzymes_validation, file = "X_UC_enzymes_validation.xlsx")
```
```{r SessionInfo}
sessionInfo()
```
```
## 参考
+ A framework for predictive modeling of microbiome multi-omics data: latent interacting variable-effects (LIVE) modeling


















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











