






【模型】
Harmonizing Visual Text Comprehension and Generation
 作者: Zhen Zhao, Jingqun Tang, Binghong Wu, Chunhui Lin, Shu Wei, Hao Liu, Xin Tan, Zhizhong Zhang, Can Huang, Yuan Xie
作者: Zhen Zhao, Jingqun Tang, Binghong Wu, Chunhui Lin, Shu Wei, Hao Liu, Xin Tan, Zhizhong Zhang, Can Huang, Yuan Xie
备注:字节跳动;NeurIPS 2024
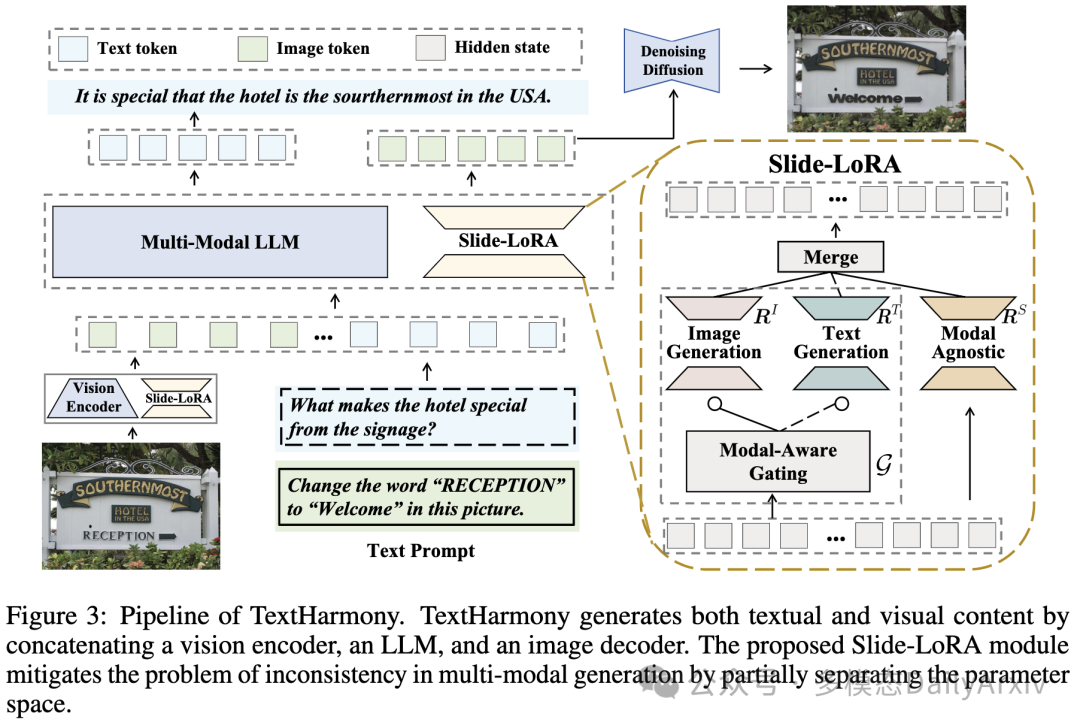
翻译摘要: 在这项工作中,我们提出了TextHarmony,这是一个统一而多功能的多模态生成模型,在理解和生成视觉文本方面有着娴熟的能力。同时生成图像和文本通常会导致性能下降,因为视觉和语言模态之间存在内在不一致。为了克服这一挑战,现有方法依赖于特定模态的数据进行有监督的微调,这需要不同的模型实例。我们提出了Slide-LoRA,它动态地聚合了特定模态和模态无关的LoRA专家,部分解耦了多模态生成空间。Slide-LoRA在单个模型实例内协调视觉和语言的生成,从而促进了更统一的生成过程。此外,我们还开发了一个高质量的图像描述数据集DetailedTextCaps-100K,该数据集使用高级闭源MLLM合成,以进一步增强视觉文本生成能力。在各种基准测试中进行的综合实验证明了我们提出方法的有效性。在Slide-LoRA的强化下,TextHarmony与特定模态的微调结果相比有可比性的性能,仅增加了2%的参数,并且在视觉文本理解任务中平均提高了2.5%,在视觉文本生成任务中平均提高了4.0%。我们的工作展示了在视觉文本领域内采取集成多模态生成方法的可行性,为后续的研究奠定了基础。代码可在 https://github.com/bytedance/TextHarmony 获得。
发表日期: 2024-07-23T10:11:56Z
是否相关: {‘score’: ‘Y’, ‘reason’: ‘文章介绍了一个多模态生成模型TextHarmony,专注于视觉文本的理解与生成,这与我们的研究方向相符,即多模态大语言基础模型,涵盖视频、语音、图像。此外,文章提出的Slide-LoRA技术也强调了视觉和语言模态之间的协调,进一步贴合我们对多模态交互的研究兴趣。’}
最新更新日期: 2024-10-23T08:27:23Z
链接: http://arxiv.org/abs/2407.16364v2
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
作者: Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, Song Han, Yao Lu
机构:清华、MIT、英伟达、UCB、UCSD
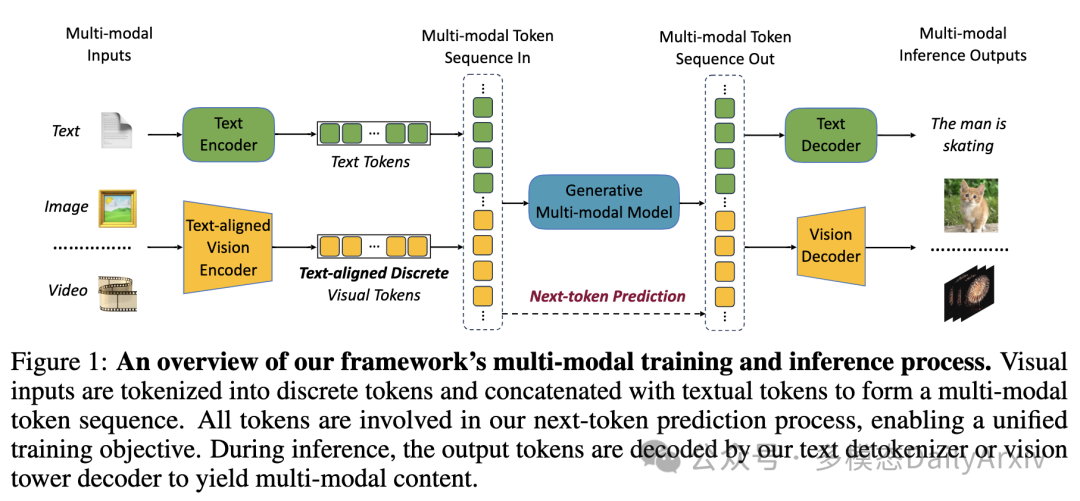
翻译摘要: VILA-U是一个统一的基础模型,整合了视频、图像、语言理解和生成。传统的视觉语言模型(VLMs)使用单独的模块来理解和生成视觉内容,这可能导致对齐不当和复杂性增加。相比之下,VILA-U采用单一的自回归下一个词预测框架来处理这两个任务,从而消除了像扩散模型这类额外组件的需求。这种方法不仅简化了模型,而且在视觉语言理解和生成方面取得了接近最先进的表现。VILA-U的成功归功于两个主要因素:统一的视觉塔在预训练期间将离散的视觉令牌与文本输入对齐,增强了视觉感知;自回归图像生成能够在高质量数据集上达到与扩散模型相似的质量。这使得VILA-U能够使用完全基于令牌的自回归框架,与更复杂的模型表现相当。
发表日期: 2024-09-06T17:49:56Z
最新更新日期: 2024-10-23T16:42:06Z
链接: http://arxiv.org/abs/2409.04429v2
OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
作者: Qinglin Zhang, Luyao Cheng, Chong Deng, Qian Chen, Wen Wang, Siqi Zheng, Jiaqing Liu, Hai Yu, Chaohong Tan
机构:通义 Lab
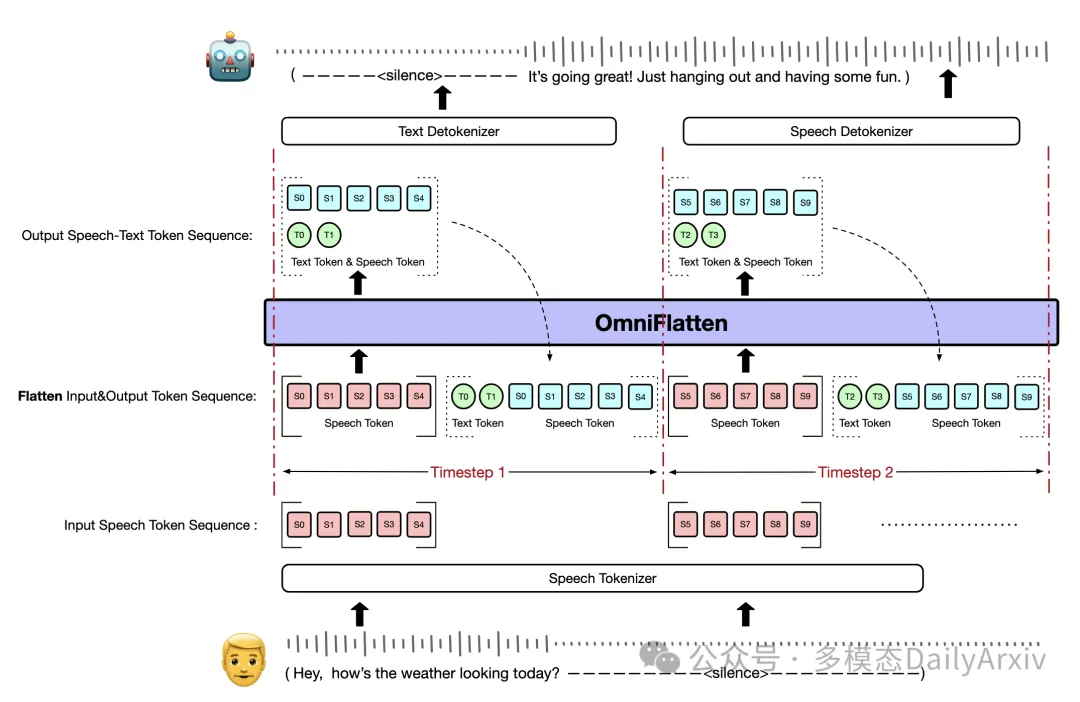
翻译摘要: 全双工口语对话系统显著优于传统的轮流对话系统,因为它们允许双向同时通信,更接近于人与人之间的互动。然而,在全双工对话系统中实现低延迟和自然互动仍然是一个重大挑战,特别是考虑到人类对话动态,如中断、背景反馈和语音重叠。在本文中,我们介绍了一种新型的端到端基于GPT的模型OmniFlatten,用于全双工对话,能够有效地模拟自然对话中固有的复杂行为,并具有低延迟。为了实现全双工通信能力,我们提出了一个多阶段的训练后方案,逐步将基于文本的大语言模型(LLM)转变为语音-文本对话LLM,能够实时生成文本和语音,而不改变基础LLM的架构。训练过程包括三个阶段:模态对齐、半双工对话学习和全双工对话学习。在所有训练阶段中,我们使用一种扁平化操作来标准化数据,这使我们能够统一不同模态和任务的训练方法和模型架构。我们的方法提供了一种直接的建模技术和一个有前途的研究方向,用于开发高效和自然的端到端全双工口语对话系统。可以在这个网站(https://omniflatten.github.io/)找到OmniFlatten生成的对话音频样本。
发表日期: 2024-10-23T11:58:58Z
最新更新日期: 2024-10-23T11:58:58Z
链接: http://arxiv.org/abs/2410.17799v1
CV-VAE: A Compatible Video VAE for Latent Generative Video Models
作者: Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, Ying Shan
机构:Tencent AI Lab
翻译摘要: 利用变分自编码器(VAE)等网络对视频进行时空压缩在OpenAI的SORA和众多其他视频生成模型中扮演着关键角色。例如,许多类似LLM的视频模型学习来自3D VAEs的离散令牌分布,在VQVAE框架内,而大多数基于扩散的视频模型捕获来自2D VAEs的连续潜在分布,无需量化。时间压缩简单地通过均匀帧采样实现,这导致连续帧之间的运动不平滑。目前,研究界缺乏一个常用的连续视频(3D)VAE用于基于潜在扩散的视频模型。此外,由于当前基于扩散的方法通常使用预训练的文本到图像(T2I)模型实现,直接训练视频VAE而不考虑与现有T2I模型的兼容性将导致它们之间的潜在空间差距,即使使用T2I模型作为初始化,也需要巨大的计算资源进行训练来弥合这一差距。为解决这一问题,我们提出了一种训练潜在视频模型的视频VAE方法,即CV-VAE,其潜在空间与给定图像VAE的潜在空间兼容,例如,Stable Diffusion(SD)的图像VAE。通过所提出的新颖潜在空间正则化实现兼容性,该正则化涉及使用图像VAE制定正则化损失。得益于潜在空间的兼容性,视频模型可以从预训练的T2I或视频模型中无缝训练,实现真正的时空压缩潜在空间,而非简单地按等间隔采样视频帧。通过我们的CV-VAE,现有视频模型可以在最小的微调下生成四倍数量的帧。广泛的实验被进行以证明所提视频VAE的有效性。
发表日期: 2024-05-30T17:33:10Z
最新更新日期: 2024-10-23T02:38:44Z
链接: http://arxiv.org/abs/2405.20279v2
MIA-DPO: Multi-Image Augmented Direct Preference Optimization For Large Vision-Language Models
作者: Ziyu Liu, Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Haodong Duan, Conghui He, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
翻译摘要: 视觉偏好对齐涉及训练大型视觉语言模型(LVLMs),以预测人类在视觉输入之间的偏好。这通常是通过使用选择/拒绝对的标记数据集并使用直接偏好优化(DPO)等优化算法来实现的。现有的视觉对齐方法主要为单图像场景设计,由于缺乏多样的训练数据和标注选择/拒绝对的高昂成本,它们往往难以有效处理多图像任务的复杂性。我们提出了一种视觉偏好对齐方法——多图像增强直接偏好优化(MIA-DPO),该方法能有效处理多图像输入。MIA-DPO通过将单图像数据与以网格拼贴或画中画格式排列的无关图像扩展,来缓解多图像训练数据多样性不足的问题,显著降低了多图像数据标注的成本。我们的观察发现,大型视觉语言模型的注意力值在不同图像间有着显著的变化。我们利用注意力值来识别和过滤掉模型可能错误关注的拒绝响应。我们的注意力感知选择用于构建选择/拒绝对,而不依赖于(i)人工标注、(ii)额外数据和(iii)外部模型或API。MIA-DPO与多种架构兼容,并在五个多图像评测基准上超越了现有方法,平均性能在LLaVA-v1.5上提高了3.0%,在最近的InternLM-XC2.5上提高了4.3%。此外,MIA-DPO对模型理解单图像的能力影响微小。
发表日期: 2024-10-23T07:56:48Z
最新更新日期: 2024-10-23T07:56:48Z
链接: http://arxiv.org/abs/2410.17637v1
LocoMotion: Learning Motion-Focused Video-Language Representations
作者: Hazel Doughty, Fida Mohammad Thoker, Cees G. M. Snoek
翻译摘要: 本文致力于研究以运动为核心的视频语言表征。现有的学习视频语言表征的方法使用以空间为焦点的数据,在这个方法中,辨识物体和场景常常足以区分相关的字幕。相反,我们提出了LocoMotion,用来学习描述局部物体运动和时间进程的以运动为中心的字幕。我们通过向视频中添加合成运动,并使用这些运动的参数来生成相应的字幕来达到这个目标。此外,我们提出了动词变化的释义增强方法来增加字幕的多样性,并学习原始运动和高级动词之间的联系。有了这些,我们能够学习一个以运动为核心的视频语言表征。实验表明,我们的方法对于各种下游任务来说是有效的,特别是在用于微调的数据有限的情况下。代码可用:https://hazeldoughty.github.io/Papers/LocoMotion/
发表日期: 2024-10-15T19:33:57Z
最新更新日期: 2024-10-23T15:21:54Z
链接: http://arxiv.org/abs/2410.12018v2
Bridging the Gaps: Utilizing Unlabeled Face Recognition Datasets to Boost Semi-Supervised Facial Expression Recognition
作者: Jie Song, Mengqiao He, Jinhua Feng, Bairong Shen
翻译摘要: 近年来,面部表情识别(FER)受到了越来越多的关注。大多数现有的工作侧重于需要大量标签和多样性图像的监督学习,而面部表情识别的难点在于缺乏大规模多样化的数据集和标注困难。为了应对这些问题,我们专注于利用大型未标注的面部识别(FR)数据集来提升半监督FER。具体来说,我们首先在没有注释的大规模人脸图像上进行面部重建预训练,以学习面部几何和表情区域的特征,然后在有限标签的FER数据集上进行两阶段的微调。此外,为了进一步缓解标签和多样化图像稀缺的问题,我们提出了一种针对面部图像的Mixup基础数据增强策略,并根据两张图像中面部的交并比(IoU)确定真实和虚拟图像的损失权重。在RAF-DB、AffectNet和FERPlus的实验表明,我们的方法优于现有半监督FER方法,并取得了新的最先进性能。值得注意的是,仅使用5%、25%的训练集,我们的方法在AffectNet上达到64.02%,在RAF-DB上达到88.23%,与全监督最先进方法可比。代码将在 https://github.com/zhelishisongjie/SSFER 公开。
发表日期: 2024-10-23T07:26:19Z
最新更新日期: 2024-10-23T07:26:19Z
链接: http://arxiv.org/abs/2410.17622v1
ROCKET-1: Master Open-World Interaction with Visual-Temporal Context Prompting
作者: Shaofei Cai, Zihao Wang, Kewei Lian, Zhancun Mu, Xiaojian Ma, Anji Liu, Yitao Liang
翻译摘要: 视觉-语言模型(VLMs)在多模态任务中表现出色,但将其适配到开放世界环境中的体现式决策中则带来了挑战。一个关键问题是如何将低层次观察中的个体实体与规划所需的抽象概念平滑地连接起来。解决这个问题的常见方法是使用分层代理,其中VLMs作为高层次的推理器,将任务分解成可执行的子任务,这些子任务通常使用语言和想象中的观察来特定。然而,语言往往无法有效传达空间信息,而生成具有足够准确度的未来图像仍然充满挑战。为了克服这些限制,我们提出了视觉-时间上下文提示,一种VLM和策略模型之间的新型通信协议。该协议利用来自过去和现在观察的对象分割来引导策略-环境互动。使用这种方法,我们训练了ROCKET-1,一种低级策略,它基于串联的视觉观察和分割掩模来预测行动,由SAM-2提供实时对象跟踪。我们的方法释放了VLM的视觉-语言推理能力的全部潜力,使其能够解决复杂的创造性任务,尤其是那些高度依赖空间理解的任务。在Minecraft中的实验表明,我们的方法允许代理完成以前无法完成的任务,突出了视觉-时间上下文提示在体现式决策中的有效性。代码和演示将在项目页面上提供:https://craftjarvis.github.io/ROCKET-1。
发表日期: 2024-10-23T13:26:59Z
最新更新日期: 2024-10-23T13:26:59Z
链接: http://arxiv.org/abs/2410.17856v1
EntityCLIP: Entity-Centric Image-Text Matching via Multimodal Attentive Contrastive Learning
作者: Yaxiong Wang, Yaxiong Wang, Lianwei Wu, Lechao Cheng, Zhun Zhong, Meng Wang
翻译摘要: 近期在图像-文本匹配领域已取得显著的进步,然而目前的主流模型主要适应广泛的查询需求,却难以满足细粒度查询意图。在本论文中,我们致力于实体中心的图像-文本匹配(\textbf{EITM})任务,即文本和图像都涉及特定实体相关信息。该任务的挑战主要在于,与通用的图像-文本匹配问题相比,实体关联建模的语义间隙更大。为了缩小实体中心文本与图像之间的巨大语义间隙,我们采用了基础的CLIP作为骨干,并设计了一个多模态注意力对比学习框架,调整CLIP来适应EITM问题,开发了一个名为EntityCLIP的模型。我们多模态注意力对比学习的关键是使用大型语言模型(LLMs)生成解释性文本作为桥梁线索。具体来说,我们通过从现成的LLMs中提取解释文本。这段解释文本,连同图像和文本,然后输入到我们特别设计的多模态注意力专家(MMAE)模块,该模块有效地整合解释文本以缩小共享语义空间中的实体相关文本和图像的间隙。在MMAE衍生的丰富特征基础上,我们进一步设计了一个有效的门控式集成图像-文本匹配(GI-ITM)策略。GI-ITM采用自适应门控机制来汇总MMAE的特征,然后应用图像-文本匹配约束来引导文本和图像之间的对齐。我们在包括N24News、VisualNews和GoodNews在内的三个社交媒体新闻基准测试上进行了广泛的实验,结果显示我们的方法明显优于竞争方法。
发表日期: 2024-10-23T12:12:56Z
最新更新日期: 2024-10-23T12:12:56Z
链接: http://arxiv.org/abs/2410.17810v1
ADEM-VL: Adaptive and Embedded Fusion for Efficient Vision-Language Tuning
作者: Zhiwei Hao, Jianyuan Guo, Li Shen, Yong Luo, Han Hu, Yonggang Wen
翻译摘要: 近期在多模态融合领域的进步显著提升了视觉-语言(VL)模型的成功率,这些模型在各种多模态应用中表现出色,包括图像描述和视觉问题回答等。然而,构建VL模型需要大量的硬件资源,在两个关键因素的限制下效率受到制约:结合视觉特征的语言模型扩展输入序列需要更多的计算操作,大量额外的可学习参数增加了内存复杂性。这些挑战严重限制了这类模型的更广泛应用。为了解决这一差距,我们提出了ADEM-VL,这是一种高效的视觉-语言方法,它通过采用无参数的交叉注意力机制来度量多模态融合中的相似性,对基于预训练的大型语言模型(LLMs)进行调整。这种方法只需要将视觉特征嵌入到语言空间中,显著减少了可训练参数的数量,并加速了训练和推理速度。为了加强融合模块中的表示学习,我们引入了一种高效的多尺度特征生成方案,该方案只需要通过视觉编码器进行单次前向传播。此外,我们提出了一种自适应融合方案,该方案根据其注意力得分,动态地舍弃每个文本标记对应的不那么相关的视觉信息。这确保了融合过程优先考虑最相关的视觉特征。通过在包括视觉问题回答、图像描述和指令跟随等多种任务上的实验,我们证明了我们的框架优于现有方法。特别是,我们的方法在ScienceQA数据集上的平均准确率比现有方法高出0.77%,并且降低了训练和推理延迟,显示了我们框架的优越性。代码可以在 https://github.com/Hao840/ADEM-VL 上获取。
发表日期: 2024-10-23T11:31:06Z
最新更新日期: 2024-10-23T11:31:06Z
链接: http://arxiv.org/abs/2410.17779v1
LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
作者: Fangxun Shu, Yue Liao, Le Zhuo, Chenning Xu, Lei Zhang, Guanghao Zhang, Haonan Shi, Long Chen, Tao Zhong, Wanggui He, Siming Fu, Haoyuan Li, Bolin Li, Zhelun Yu, Si Liu, Hongsheng Li, Hao Jiang
翻译摘要: 我们介绍了LLaVA-MoD,一个新型框架,旨在通过从大规模多模态语言模型 (l-MLLM) 提取知识来实现小规模多模态语言模型 (s-MLLM) 的高效训练。我们的方法解决了MLLM提取中的两个基本挑战。首先,我们通过将稀疏的专家混合 (MoE) 架构整合到语言模型中优化了s-MLLM的网络结构,以平衡计算效率和模型表达能力。其次,我们提出了一种渐进式知识转移策略以确保全面的知识迁移。这一策略从模仿提取开始,在此阶段我们最小化输出分布之间的库尔巴克-莱布勒 (KL) 散度,使得学生模型能够模拟老师网络的理解。紧接着,我们通过直接偏好优化 (DPO) 引入偏好提取,关键在于将l-MLLM视为参考模型。在这一阶段,s-MLLM辨别优劣例子的能力显著提高,超越了l-MLLM,尤其是在幻觉基准测试中。大量实验表明LLaVA-MoD在多种多模态基准测试中的表现超过了现有模型,同时保持了较少的激活参数和低计算成本。值得注意的是,即使激活的参数只有2B,LLaVA-MoD在基准测试中的平均性能仍比 Qwen-VL-Chat-7B 高出8.8%,且仅使用了0.3%的训练数据和23%的可训练参数。这些结果突显了LLaVA-MoD在有效提取教师模型知识方面的能力,为开发更高效的MLLM铺平了道路。代码将在以下网址提供:https://github.com/shufangxun/LLaVA-MoD。
发表日期: 2024-08-28T15:52:23Z
最新更新日期: 2024-10-23T09:52:23Z
链接: http://arxiv.org/abs/2408.15881v3
【评测】
LVBench: An Extreme Long Video Understanding Benchmark
作者: Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Xiaotao Gu, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, Jie Tang
翻译摘要: 近期在多模态大型语言模型方面的进展显著提升了对短视频(通常少于一分钟)的理解,并相应地出现了几个评估数据集。然而,这些进展未能满足现实应用的需求,如体现智能进行长期决策、深入的电影评论和讨论以及现场体育评论,这些应用都需要理解持续数小时的长视频。为了弥补这一差距,我们引入了LVBench,一个专门针对长视频理解设计的基准测试。我们的数据集包含公开来源的视频,并涵盖了一系列旨在长视频理解和信息提取的任务。LVBench旨在挑战多模态模型展示长期记忆和扩展理解能力。我们的广泛评估显示,当前的多模态模型在这些要求严格的长视频理解任务上仍然表现不佳。通过LVBench,我们希望推动更高级模型的开发,以应对长视频理解的复杂性。我们的数据和代码可在以下网址公开获取:https://lvbench.github.io.
发表日期: 2024-06-12T09:36:52Z
最新更新日期: 2024-10-23T06:37:01Z
链接: http://arxiv.org/abs/2406.08035v2
MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding
作者: Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, Kai Chen
翻译摘要: 大型视觉语言模型(LVLMs)的出现激发了对其在多模态背景下应用的研究,特别是在视频理解方面。尽管传统的视频问答(VideoQA)基准测试提供了定量指标,但它们通常未能涵盖视频内容的全部范围,并且不能充分评估模型的时间理解能力。为了解决这些局限性,我们引入了MMBench-Video,这是一个定量基准测试,旨在严格评估LVLMs在视频理解上的熟练程度。MMBench-Video采纳了来自YouTube的长视频,并使用自由形式的问题,以反映实际使用案例。该基准测试精心设计,以考察模型的时间推理技能,所有问题都根据精心构建的能力分类进行人工注释。我们使用GPT-4进行自动评估,证明了其在准确性和稳健性上优于早期基于LLM的评估。利用MMBench-Video,我们进行了全面的评估,包括专有的和开源的LVLMs在图像和视频方面的应用。MMBench-Video作为研究社区的宝贵资源,有助于改进LVLMs的评估,并催化视频理解领域的进步。MMBench-Video的评估代码将被集成到VLMEvalKit中:https://github.com/open-compass/VLMEvalKit。
发表日期: 2024-06-20T17:26:01Z
最新更新日期: 2024-10-23T03:09:54Z
链接: http://arxiv.org/abs/2406.14515v2
WorldSimBench: Towards Video Generation Models as World Simulators
作者: Yiran Qin, Zhelun Shi, Jiwen Yu, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao, Lei Bai, Wanli Ouyang, Ruimao Zhang
翻译摘要: 近期在预测模型方面的进步表现出了在预测物体和场景的未来状态方面的非凡能力。然而,基于内在特性的缺乏分类继续阻碍预测模型发展的进程。此外,现有基准测试无法有效地从体感角度评估具有更高能力的高度体感化预测模型。在本项工作中,我们将预测模型的功能分类为一个层级体系,并通过提出一个名为WorldSimBench的双重评估框架,迈出了评估世界模拟器的第一步。WorldSimBench包括显式感知评估和隐式操控评估,涵盖了从视觉角度的人类偏好评估和体感任务中的动作级别评估,覆盖三个代表性的体感场景:开放式体感环境、自动驾驶和机器人操控。在显式感知评估中,我们引入了HF-Embodied数据集——一个基于细致的人类反馈的视频评估数据集,我们利用这个数据集训练了一种与人类感知相符的人类偏好评估器,用于显式评估世界模拟器的视觉真实性。在隐式操控评估中,我们通过评估生成的情景感知视频是否可以在动态环境中准确地转化为正确的控制信号,来评估世界模拟器的视频-动作一致性。我们的全面评估提供了关键见解,这些见解可以推动视频生成模型的进一步创新,将世界模拟器定位为朝向体感人工智能的关键进步。
发表日期: 2024-10-23T17:56:11Z
最新更新日期: 2024-10-23T17:56:11Z
链接: http://arxiv.org/abs/2410.18072v1
TP-Eval: Tap Multimodal LLMs’ Potential in Evaluation by Customizing Prompts
作者: Yuxuan Xie, Tianhua Li, Wenqi Shao, Kaipeng Zhang
翻译摘要: 近期,多模态大型语言模型(MLLMs)因其惊人的能力而受到广泛关注。评估MLLMs变得至关重要,不仅因为它能分析MLLMs的属性,还因为它能提供宝贵的见解。然而,现有的基准测试忽略了提示敏感性问题——轻微的提示变化可能导致显著的性能波动。因此,不恰当的提示可能会掩盖模型的实际能力,低估模型的性能。此外,不同模型对不同提示有不同的偏好,因此,对所有模型使用相同的提示将导致评估偏差。本文分析了现有基准测试中的这一缺陷,并进一步介绍了一个新的评估框架,名为TP-Eval,该框架引入了一种定制提示方法以减少评估偏差并充分挖掘模型的潜力。TP-Eval将针对不同模型重写原始提示为不同的定制提示。特别是,我们提出了一些为MLLM评估场景量身定制的精心设计的提示定制模块。广泛的实验表明我们的方法在揭示模型能力上的有效性,而且TP-Eval应当有助于社区开发更全面、更有说服力的MLLM评估基准。
发表日期: 2024-10-23T17:54:43Z
最新更新日期: 2024-10-23T17:54:43Z
链接: http://arxiv.org/abs/2410.18071v1
Can visual language models resolve textual ambiguity with visual cues? Let visual puns tell you!
作者: Jiwan Chung, Seungwon Lim, Jaehyun Jeon, Seungbeen Lee, Youngjae Yu
翻译摘要: 人类具备多模态识读能力,能够积极地整合来自不同模态的信息来形成推理。当面临如文本中词汇歧义这样的挑战时,我们会用其他模态的信息来补充理解,比如缩略图或是教科书插图。机器是否可能实现类似的多模态理解能力呢?为此,我们提出了一个名为“通过图像解释理解双关语”(UNPIE)的新型评测基准,用以评估多模态输入在解决词汇歧义中的影响。由于双关语天生的歧义性,它们成为了此次评估的理想主题。我们的数据集包含了1000个双关语,每个都伴有一张解释其双重含义的图片。我们提出了三个多模态挑战,并附上注解,以评估多模态识读能力的不同方面;包括双关语基准化、去歧义和重构。结果表明,当给出视觉上下文时,各种苏格拉底模型和视觉-语言模型在处理复杂任务时,相比仅限文本的模型有所改进。
发表日期: 2024-10-01T19:32:57Z
最新更新日期: 2024-10-23T02:55:20Z
链接: http://arxiv.org/abs/2410.01023v2
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









