







强化学习中的策略梯度方法是一类直接优化策略以最大化累积奖励的算法。与基于值函数的方法相比,策略梯度方法能够处理连续动作空间和高维状态空间,并且能够实现随机化的策略。这些方法的核心思想是通过计算策略的梯度并更新策略参数来逐步改进策略,直至找到最优策略。策略梯度方法的一个关键优势是它们能够直接从环境中学习,而不需要事先定义奖励函数或状态空间。
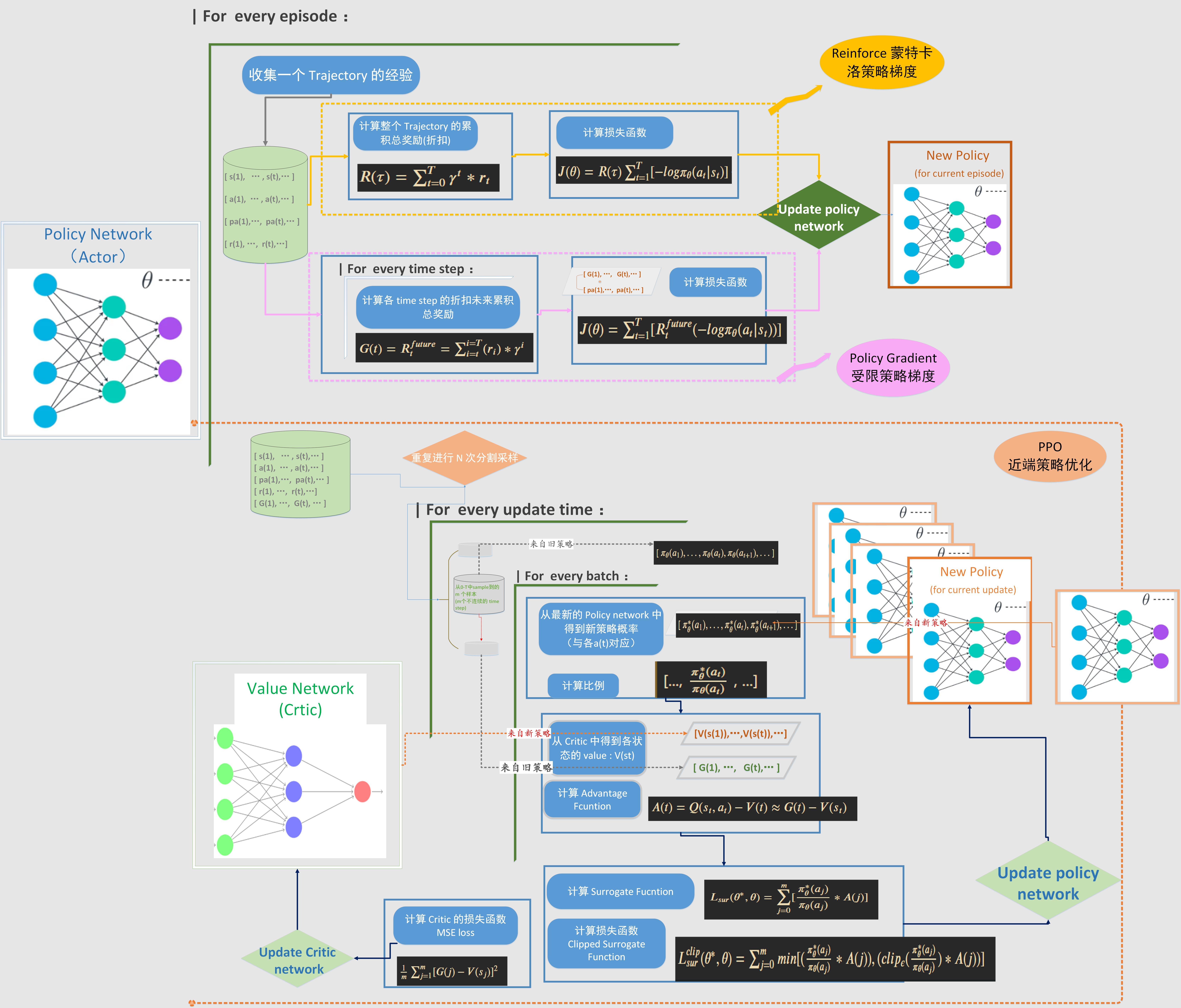
策略梯度方法的基本步骤包括策略参数化、采样、计算梯度以及更新策略参数。策略通常通过神经网络参数化,网络的输入是状态,输出是动作的概率分布或动作本身的参数。策略梯度的计算涉及到计算策略的对数概率的梯度,这通常通过蒙特卡洛方法来估计。更新策略参数时,可以使用梯度上升法,并可能结合重要性采样或基线函数来减小方差和平衡探索与利用。
策略梯度方法的应用范围广泛,包括游戏AI、机器人控制、自动驾驶等领域。这些方法在实际应用中可能会面临挑战,如收敛性问题、采样效率问题以及对初始策略的依赖性。为了克服这些挑战,研究者们提出了多种改进的策略梯度算法,如Proximal Policy Optimization (PPO)、Trust Region Policy Optimization (TRPO)等,这些算法旨在提高算法的稳定性和收敛速度。

什么是策略梯度方法在强化学习中的主要步骤?
策略梯度方法的基本概念
策略梯度方法是强化学习中的一种算法框架,它直接优化策略函数,即智能体在特定状态下选择动作的概率分布。这种方法特别适合处理连续动作空间或大型动作空间的问题,因为它能够直接学习到动作的概率分布,而不是先学习动作价值函数。
策略梯度方法的主要步骤
-
定义策略函数:选择一个参数化的策略函数,通常用神经网络来表示,该函数将状态映射到动作的概率分布。
-
收集经验数据:智能体按照当前策略与环境交互,收集状态、动作和奖励的数据集。
-
计算梯度:使用收集到的数据,通过蒙特卡洛方法或重要性采样等技术估算策略梯度,即策略函数参数变化时预期回报的变化率。
-
更新策略:根据计算出的梯度,使用梯度上升或其他优化算法更新策略函数的参数,以提高智能体的表现。
-
迭代优化:重复上述步骤,持续收集数据和更新策略,直到达到预定的性能水平或满足停止条件。
策略梯度方法的关键优势在于其直接优化策略的能力,这使得它能够在探索与利用之间保持平衡,并且能够处理高度随机的环境。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3161
3161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









