









基于视频(不使用激光雷达)的3D目标检测,利用视频中目标的运动信息,性能达到SOTA。
Kinematic 3D Object Detection in Monocular Video
作者 | Garrick Brazil, Gerard Pons-Moll, Xiaoming Liu, Bernt Schiele
单位 | 密歇根州立大学;萨尔大学
论文 | https://arxiv.org/abs/2007.09548
代码 | https://github.com/garrickbrazil/kinematic3d
主页 | http://cvlab.cse.msu.edu/project-kinematic.html演示| https://youtu.be/PRmYzHtQ99M
Kinematic 3D Object Detection in Monocular Video
Garrick Brazil, Gerard Pons-Moll, Xiaoming Liu, Bernt Schiele
Keywords: 3D Object Detection, Video
Perceiving the physical world in 3D is fundamental for selfdriving applications. Although temporal motion is an invaluable resource to human vision for detection, tracking, and depth perception, such features have not been thoroughly utilized in modern 3D object detectors. In this work, we propose a novel method for monocular video-based 3D object detection which leverages kinematic motion to extract scene dynamics and improve localization accuracy. We first propose a novel decomposition of object orientation and a self-balancing 3D confidence. We show that both components are critical to enable our kinematic model to work effectively. Collectively, using only a single model, we efficiently leverage 3D kinematics from monocular videos to improve the overall localization precision in 3D object detection while also producing useful by-products of scene dynamics (ego-motion and per-object velocity). We achieve state-of-the-art performance on monocular 3D object detection and the Bird’s Eye View tasks within the KITTI self-driving dataset.
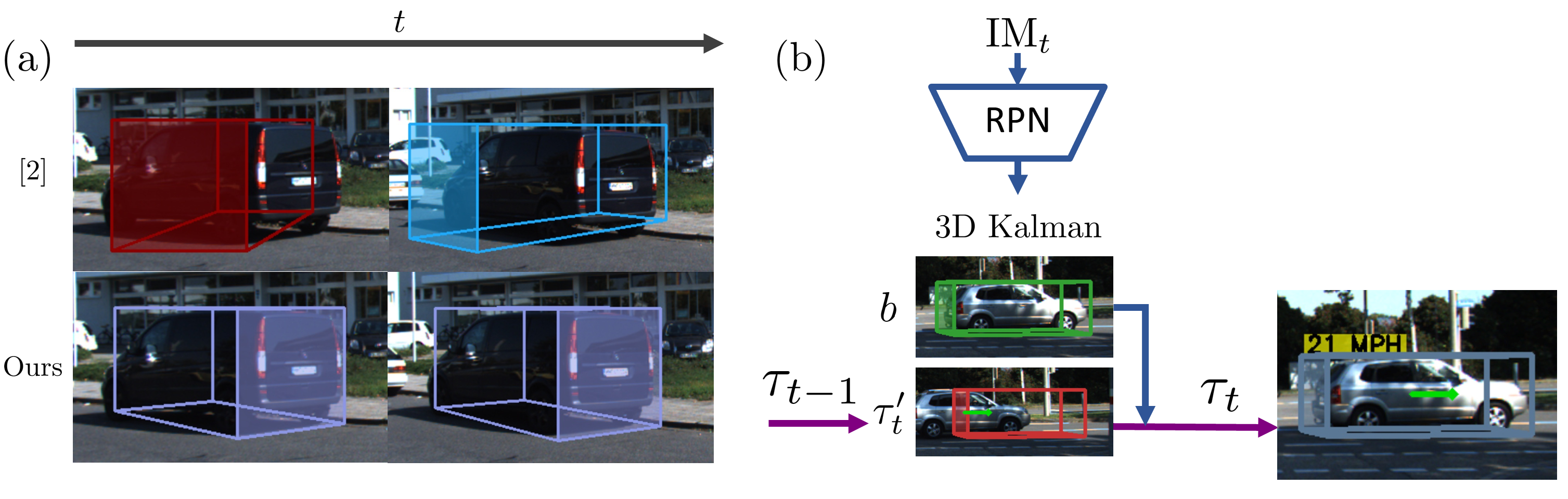
Figure 1. Single-frame 3D detection [2] often has unstable estimation through time (a), while our video-based method (b) is more robust by leveraging kinematic motion via a 3D Kalman Filter to fuse forecasted tracks and measurements into final estimations.
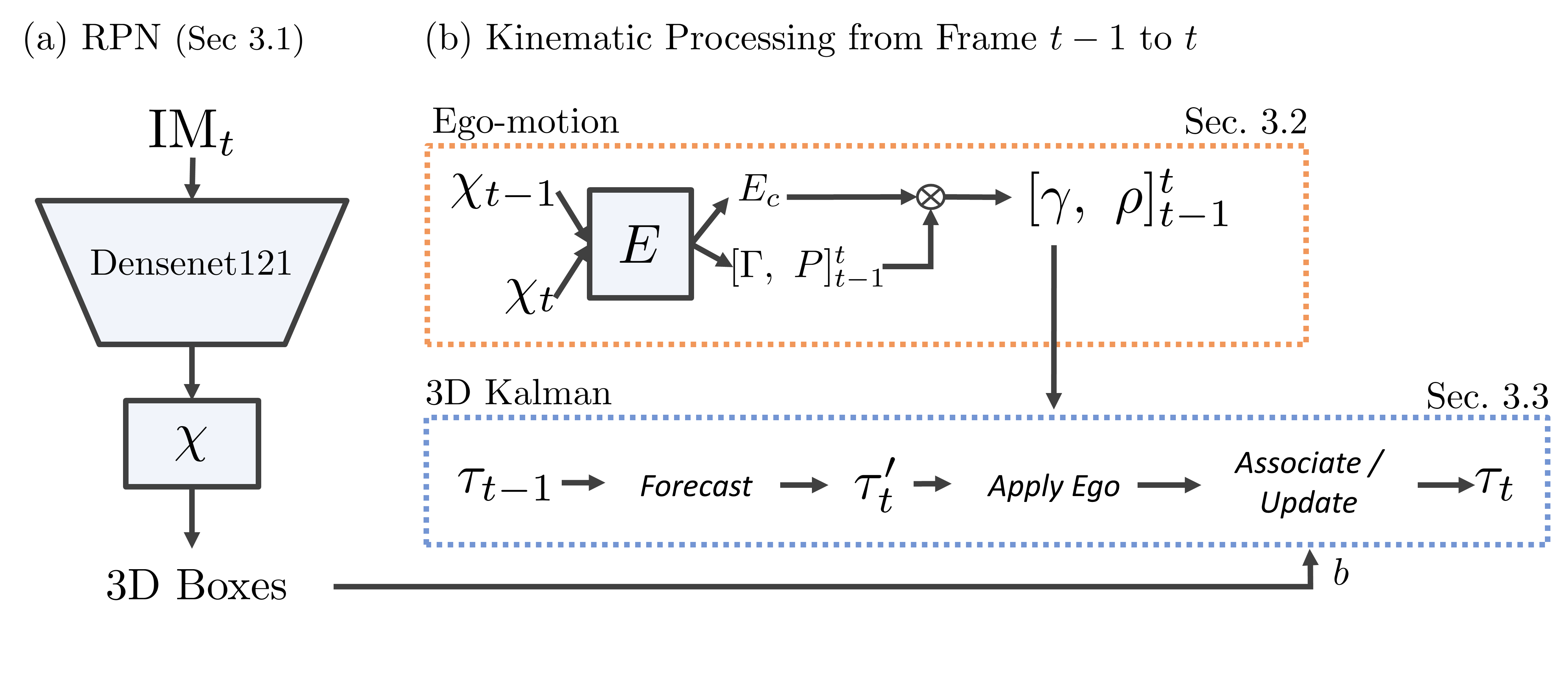
Figure 2. Overview. We use a RPN to first estimate 3D boxes. We forecast previous frame tracks using the estimated Kalman velocity. Self-motion is compensated for applying a global ego-motion to tracks. We fuse tracks with measurements using a kinematic 3D Kalman filter.
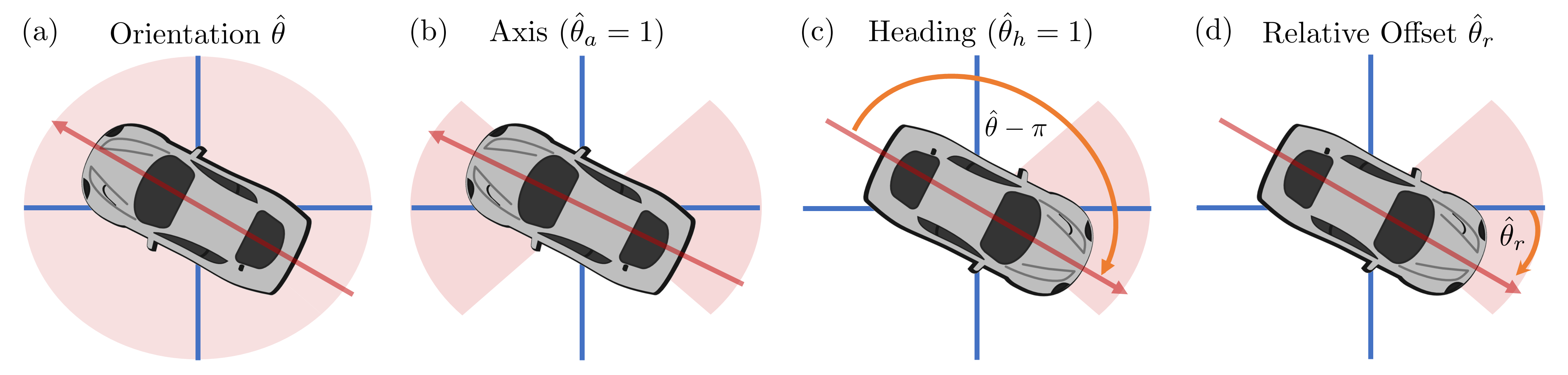
Figure 3. Orientation. We decompose an object orientation (a) into an axis classification (b), a heading classification (c), and an offset (d). Our method disentangles the objectives of axis and heading classification while greatly reducing the offset region (red) by a factor of 1/4.
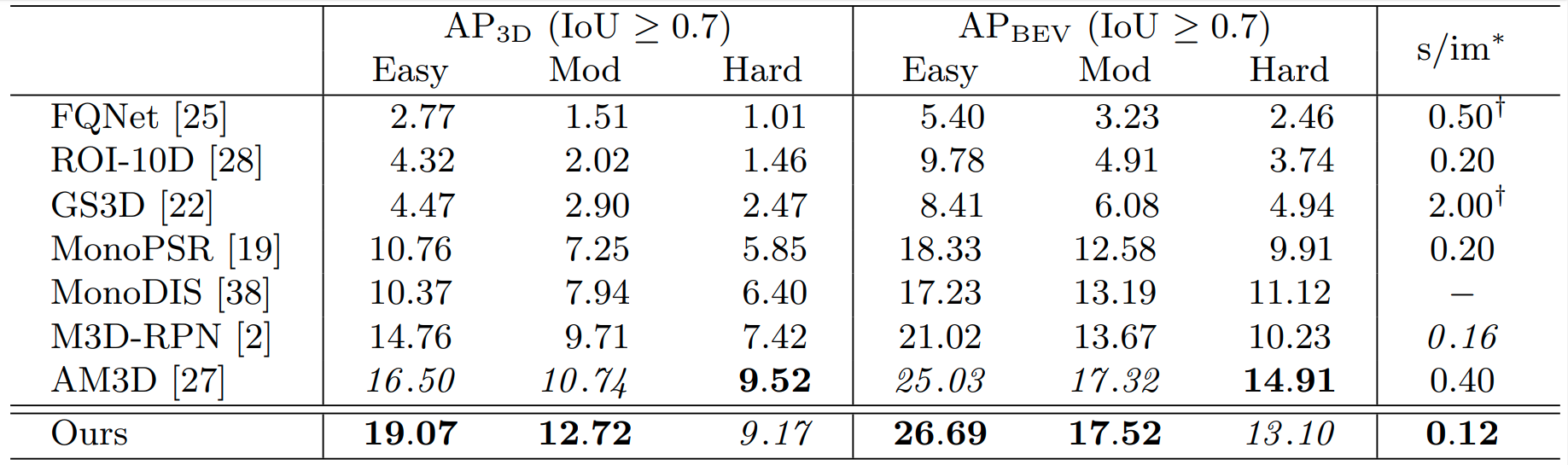
Table 1. KITTI Test. We compare with state-of-the-art methods on the KITTI test dataset. We report performances using the AP40 [38] metric available on the official leaderboard. * the runtime is reported from the official leaderboard with slight variances in hardware. We indicate methods reported on CPU with †. Bold/italics indicate best/second AP.

Table 2. KITTI Validation. We compare with state-of-the-art on KITTI validation [8] split. Note that methods published prior to [38] are unable to report the AP40 metric. Bold/italics indicate best/second AP.

Table 3. Ablation Experiments. We conduct a series of ablation experiments with the validation [8] split of KITTI, using diverse IoU matching criteria of ≥ 0.7/0.5. Bold/italics indicate best/second AP.
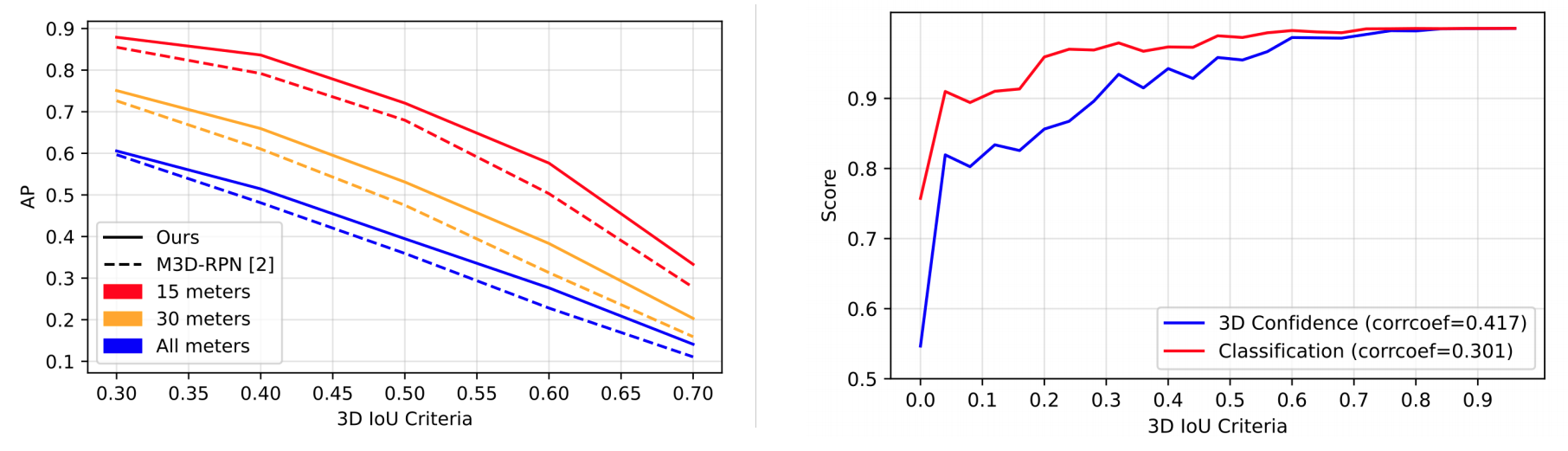
Figure 4. We first compare AP 3D with M3D-RPN [2] by varying 3D IoU criteria and depth (left image). We further show the correlation of 3D IoU to classification c and 3D confidence µ (right image).

Figure 5. Qualitative Examples. We depict the image view (left) and BEV (right). We show velocity vector in green, speed and ego-motion in miles per hour (MPH) on of detection boxes and at the top-left corner, and tracks as dots in BEV.
Sample Results
Video 1. Demo Video. We demonstrate our framework’s ability to determine a full scene understanding including 3D object cuboids, per-object velocity and ego-motion. We compare to prior art M3D-RPN [1], plot ground truths, image view, Bird’s Eye View, and the track history.
Video Presentations (@ ECCV 2020)
Video 2. ECCV Short Video Presentation (1 minute).
Video 3. ECCV Long Video Presentation (10 minutes).
Kinematic 3D Source Code
Kinematic 3D implementation in Python and Pytorch can be downloaded from here.
If you use the Kinematic 3D code, please cite the ECCV 2020 paper.
Publications
- Kinematic 3D Object Detection in Monocular Video
Garrick Brazil, Gerard Pons-Moll, Xiaoming Liu, Bernt Schiele
In Proceeding of European Conference on Computer Vision (ECCV 2020), Virtual, Aug. 2020
Bibtex | PDF | arXiv | Supplemental | Code | Video















 1627
1627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









