转载来源于
http://blog.csdn.net/firefight/article/details/6400060
为了学习OPENCV SVM分类器, 参考网上的"利用SVM解决2维空间向量的分类问题"实现并改为C++代码,仅供参考
环境:OPENCV2.2 + VS2008
步骤:
1,生成随机的点,并按一定的空间分布将其归类
2,创建SVM并利用随机点样本进行训练
3,将整个空间按SVM分类结果进行划分,并显示支持向量
- #include "stdafx.h"
- #include <opencv2/opencv.hpp>
-
- void drawCross(Mat &img, Point center, Scalar color)
- {
- int col = center.x > 2 ? center.x : 2;
- int row = center.y> 2 ? center.y : 2;
-
- line(img, Point(col -2, row - 2), Point(col + 2, row + 2), color);
- line(img, Point(col + 2, row - 2), Point(col - 2, row + 2), color);
- }
-
- int newSvmTest(int rows, int cols, int testCount)
- {
- if(testCount > rows * cols)
- return 0;
-
- Mat img = Mat::zeros(rows, cols, CV_8UC3);
- Mat testPoint = Mat::zeros(rows, cols, CV_8UC1);
- Mat data = Mat::zeros(testCount, 2, CV_32FC1);
- Mat res = Mat::zeros(testCount, 1, CV_32SC1);
-
-
- for (int i= 0; i< testCount; i++)
- {
- int row = rand() % rows;
- int col = rand() % cols;
-
- if(testPoint.at<unsigned char>(row, col) == 0)
- {
- testPoint.at<unsigned char>(row, col) = 1;
- data.at<float>(i, 0) = float (col) / cols;
- data.at<float>(i, 1) = float (row) / rows;
- }
- else
- {
- i--;
- continue;
- }
-
- if (row > ( 50 * cos(col * CV_PI/ 100) + 200) )
- {
- drawCross(img, Point(col, row), CV_RGB(255, 0, 0));
- res.at<unsigned int>(i, 0) = 1;
- }
- else
- {
- if (col > 200)
- {
- drawCross(img, Point(col, row), CV_RGB(0, 255, 0));
- res.at<unsigned int>(i, 0) = 2;
- }
- else
- {
- drawCross(img, Point(col, row), CV_RGB(0, 0, 255));
- res.at<unsigned int>(i, 0) = 3;
- }
- }
-
- }
-
-
- imshow("dst", img);
- waitKey(0);
-
-
- CvSVM svm = CvSVM();
- CvSVMParams param;
- CvTermCriteria criteria;
-
- criteria= cvTermCriteria(CV_TERMCRIT_EPS, 1000, FLT_EPSILON);
- param= CvSVMParams (CvSVM::C_SVC, CvSVM::RBF, 10.0, 8.0, 1.0, 10.0, 0.5, 0.1, NULL, criteria);
-
- svm.train(data, res, Mat(), Mat(), param);
-
- for (int i= 0; i< rows; i++)
- {
- for (int j= 0; j< cols; j++)
- {
- Mat m = Mat::zeros(1, 2, CV_32FC1);
- m.at<float>(0,0) = float (j) / cols;
- m.at<float>(0,1) = float (i) / rows;
-
- float ret = 0.0;
- ret = svm.predict(m);
- Scalar rcolor;
-
- switch ((int) ret)
- {
- case 1: rcolor= CV_RGB(100, 0, 0); break;
- case 2: rcolor= CV_RGB(0, 100, 0); break;
- case 3: rcolor= CV_RGB(0, 0, 100); break;
- }
-
- line(img, Point(j,i), Point(j,i), rcolor);
- }
- }
-
- imshow("dst", img);
- waitKey(0);
-
-
- int sv_num= svm.get_support_vector_count();
- for (int i= 0; i< sv_num; i++)
- {
- const float* support = svm.get_support_vector(i);
- circle(img, Point((int) (support[0] * cols), (int) (support[1] * rows)), 5, CV_RGB(200, 200, 200));
- }
-
- imshow("dst", img);
- waitKey(0);
-
- return 0;
- }
-
- int main(int argc, char** argv)
- {
- return newSvmTest(400, 600, 100);
- }
学习样本:

分类:

支持向量:

转载于
http://www.cnblogs.com/justany/archive/2012/11/27/2789767.html
预备知识
下面两个都不是必备知识,但是如果你想了解更多内容,可参考这两篇文章。
OpenCV 2.4+ C++ SVM介绍
OpenCV 2.4+ C++ SVM线性不可分处理
SVM划分的意义
到此,我们已经对SVM有一定的了解了。可是这有什么用呢?回到上一篇文章结果图:
这个结果图的意义在于,他成功从二维划分了分类的区域。于是如果以后,有一个新的样本在绿色区域,那么我们就可以把他当成是绿色的点。
由于这可以像更高维度推广,所以如果我们能对样品映射成高维度空间的点,当有足够多的样品时,我们同样可以找到一个高维度的超平面划分,使得同一类样品的映射点在同一区域,于是当有新样品落在这些区域是,我们可以把它当成是这一类型的样本。
通俗一点
可能我们能更加通俗一点。比如我们来识别男性和女性。
我们发现男性和女性可能头发长度不一样,可能胸围不一样,于是我们对样本个体产生这样的一种映射:
人 —> (头发长度, 胸围)
于是我们将每个样品映射到二维平面,其中“头发的长度”和“胸围的长度”分别是x轴和y轴。我们把这些样品丢给SVM学习,则他会寻找出一个合理的x和y的区域来划分男性和女性。
当然,也有可能有些男的头发比女的还长,有的男性的胸围比女性还大,这些就是错分点,它们也影响着划分。
最后,当我们把一个人映射到这个二维空间时,SVM就可以根据以往的学习,猜一猜这个人到底是什么性别。
我们学到了什么呢?
好吧,特征要找准一点,否则可能遇到下面的悲剧……

如果这是老板,你可就死翘翘了……
简单的文字识别
当然计算机没那么厉害能看出你的胸围或者头发长短。他需要一些他能读懂的东西,特别计算机通常“看到”的是下面的这种东东……
我们需要对文字找到他的特征,来映射到高维空间。
还记得小学时候练字的米字格么?这似乎暗示了我们,虽然每个人写的字千差万别,但是他们却具有一定的特点。

我们尝试这样做,取一个字,选取一个包含该字的正方形区域,将这个正方形区域分割成8*8个小格,统计每个小格中像素的数量,以这些数量为维度进行映射。
OK,明白了原理让我们开始吧。
被提醒了,那么补充一句:这个例子在实际中用来辨认是不可行的。
样本获取
由于通常文字样本都是白底黑字的,而手写也可以直接获取写入的数据而无视背景,所以我们并不需要对样本进行提取,但我们需要对他定位,并弄成合适的大小。
比如,你没法避免有人这么写字……

坑爹啊,好好的那么大地方你就躲在左上角……
开始定位
void getROI(Mat& src, Mat& dst){
int left, right, top, bottom;
left = src.cols;
right = 0;
top = src.rows;
bottom = 0;
//得到区域
for(int i=0; i<src.rows; i++)
{
for(int j=0; j<src.cols; j++)
{
if(src.at<uchar>(i, j) > 0)
{
if(j<left) left = j;
if(j>right) right = j;
if(i<top) top = i;
if(i>bottom) bottom = i;
}
}
}
int width = right - left;
int height = bottom - top;
//创建存储矩阵
dst = Mat::zeros(width, height, CV_8UC1);
Rect dstRect(left, top, width, height);
dst(dstRect);
}
这段代码通过遍历所有图像矩阵的元素,来获取该样本的定位和大小。并把样本提取出来。
重新缩放
Mat dst = Mat::zeros(8, 8, CV_8UC1);
resize(src, dst, dst.size());
进行缩放,把所有样本变成8*8的大小。为了简便,我们把像素多少变成了像素的灰度值。
resize的API:
调整图片大小
C++:
void
resize
(InputArray
src, OutputArray
dst, Size
dsize, double
fx=0, double
fy=0, int
interpolation=INTER_LINEAR
)
-
准备样本数据
Mat data = Mat::zeros(total, 64, CV_32FC1); //样本数据矩阵
Mat res = Mat::zeros(total, 1, CV_32SC1); //样本标签矩阵
res.at<double>(k, 1) = label; //对第k个样本添加分类标签
//对第k个样本添加数据
for(int i = 0; i<8; i++) {
for(int j = 0; j<8; j++) {
res.at<double>(k, i * 8 + j) = dst.at<double>(i, j);
}
}
将刚刚的结果,输入样本,并加上标签。
训练
CvSVM svm = CvSVM();
CvSVMParams param;
CvTermCriteria criteria;
criteria= cvTermCriteria(CV_TERMCRIT_EPS, 1000, FLT_EPSILON);
param= CvSVMParams(CvSVM::C_SVC, CvSVM::RBF, 10.0, 8.0, 1.0, 10.0, 0.5, 0.1, NULL, criteria);
svm.train(data, res, Mat(), Mat(), param);
svm.save( "SVM_DATA.xml" );
开始训练并保存训练数据。
使用
CvSVM svm = CvSVM();
svm.load( "SVM_DATA.xml" );
svm.predict(m); //对样本向量m检测
自己训练SVM分类器进行HOG行人检测
转载于http://blog.csdn.net/masibuaa/article/details/16105073?utm_source=tuicool&utm_medium=referral
正样本来源是INRIA数据集中的96*160大小的人体图片,使用时上下左右都去掉16个像素,截取中间的64*128大小的人体。
负样本是从不包含人体的图片中随机裁取的,大小同样是64*128(从完全不包含人体的图片中随机剪裁出64*128大小的用于人体检测的负样本)。
SVM使用的是OpenCV自带的CvSVM类。
首先计算正负样本图像的HOG描述子,组成一个特征向量矩阵,对应的要有一个指定每个特征向量的类别的类标向量,输入SVM中进行训练。
训练好的SVM分类器保存为XML文件,然后根据其中的支持向量和参数生成OpenCV中的HOG描述子可用的检测子参数,再调用OpenCV中的多尺度检测函数进行行人检测。
难例(Hard Example)是指利用第一次训练的分类器在负样本原图(肯定没有人体)上进行行人检测时所有检测到的矩形框,这些矩形框区域很明显都是误报,把这些误报的矩形框保存为图片,加入到初始的负样本集合中,重新进行SVM的训练,可显著减少误报。
用训练好的分类器在负样本原图上检测Hard Example见:用初次训练的SVM+HOG分类器在负样本原图上检测HardExample
Navneet Dalal在CVPR2005上的HOG原论文翻译见:http://blog.csdn.net/masibuaa/article/details/14056807
- #include <iostream>
- #include <fstream>
- #include <opencv2/core/core.hpp>
- #include <opencv2/highgui/highgui.hpp>
- #include <opencv2/imgproc/imgproc.hpp>
- #include <opencv2/objdetect/objdetect.hpp>
- #include <opencv2/ml/ml.hpp>
-
- using namespace std;
- using namespace cv;
-
- #define PosSamNO 2400 //正样本个数
- #define NegSamNO 12000 //负样本个数
-
- #define TRAIN false //是否进行训练,true表示重新训练,false表示读取xml文件中的SVM模型
- #define CENTRAL_CROP true //true:训练时,对96*160的INRIA正样本图片剪裁出中间的64*128大小人体
-
-
-
- #define HardExampleNO 4435
-
-
-
-
- class MySVM : public CvSVM
- {
- public:
-
- double * get_alpha_vector()
- {
- return this->decision_func->alpha;
- }
-
-
- float get_rho()
- {
- return this->decision_func->rho;
- }
- };
-
-
-
- int main()
- {
-
- HOGDescriptor hog(Size(64,128),Size(16,16),Size(8,8),Size(8,8),9);
- int DescriptorDim;
- MySVM svm;
-
-
- if(TRAIN)
- {
- string ImgName;
- ifstream finPos("INRIAPerson96X160PosList.txt");
-
- ifstream finNeg("NoPersonFromINRIAList.txt");
-
- Mat sampleFeatureMat;
- Mat sampleLabelMat;
-
-
-
- for(int num=0; num<PosSamNO && getline(finPos,ImgName); num++)
- {
- cout<<"处理:"<<ImgName<<endl;
-
- ImgName = "D:\\DataSet\\INRIAPerson\\INRIAPerson\\96X160H96\\Train\\pos\\" + ImgName;
- Mat src = imread(ImgName);
- if(CENTRAL_CROP)
- src = src(Rect(16,16,64,128));
-
-
- vector<float> descriptors;
- hog.compute(src,descriptors,Size(8,8));
-
-
-
- if( 0 == num )
- {
- DescriptorDim = descriptors.size();
-
- sampleFeatureMat = Mat::zeros(PosSamNO+NegSamNO+HardExampleNO, DescriptorDim, CV_32FC1);
-
- sampleLabelMat = Mat::zeros(PosSamNO+NegSamNO+HardExampleNO, 1, CV_32FC1);
- }
-
-
- for(int i=0; i<DescriptorDim; i++)
- sampleFeatureMat.at<float>(num,i) = descriptors[i];
- sampleLabelMat.at<float>(num,0) = 1;
- }
-
-
- for(int num=0; num<NegSamNO && getline(finNeg,ImgName); num++)
- {
- cout<<"处理:"<<ImgName<<endl;
- ImgName = "D:\\DataSet\\NoPersonFromINRIA\\" + ImgName;
- Mat src = imread(ImgName);
-
-
- vector<float> descriptors;
- hog.compute(src,descriptors,Size(8,8));
-
-
-
- for(int i=0; i<DescriptorDim; i++)
- sampleFeatureMat.at<float>(num+PosSamNO,i) = descriptors[i];
- sampleLabelMat.at<float>(num+PosSamNO,0) = -1;
- }
-
-
- if(HardExampleNO > 0)
- {
- ifstream finHardExample("HardExample_2400PosINRIA_12000NegList.txt");
-
- for(int num=0; num<HardExampleNO && getline(finHardExample,ImgName); num++)
- {
- cout<<"处理:"<<ImgName<<endl;
- ImgName = "D:\\DataSet\\HardExample_2400PosINRIA_12000Neg\\" + ImgName;
- Mat src = imread(ImgName);
-
-
- vector<float> descriptors;
- hog.compute(src,descriptors,Size(8,8));
-
-
-
- for(int i=0; i<DescriptorDim; i++)
- sampleFeatureMat.at<float>(num+PosSamNO+NegSamNO,i) = descriptors[i];
- sampleLabelMat.at<float>(num+PosSamNO+NegSamNO,0) = -1;
- }
- }
-
-
-
-
-
-
-
-
-
-
-
-
-
- CvTermCriteria criteria = cvTermCriteria(CV_TERMCRIT_ITER+CV_TERMCRIT_EPS, 1000, FLT_EPSILON);
-
- CvSVMParams param(CvSVM::C_SVC, CvSVM::LINEAR, 0, 1, 0, 0.01, 0, 0, 0, criteria);
- cout<<"开始训练SVM分类器"<<endl;
- svm.train(sampleFeatureMat, sampleLabelMat, Mat(), Mat(), param);
- cout<<"训练完成"<<endl;
- svm.save("SVM_HOG.xml");
-
- }
- else
- {
- svm.load("SVM_HOG_2400PosINRIA_12000Neg_HardExample(误报少了漏检多了).xml");
- }
-
-
-
-
-
-
-
-
- DescriptorDim = svm.get_var_count();
- int supportVectorNum = svm.get_support_vector_count();
- cout<<"支持向量个数:"<<supportVectorNum<<endl;
-
- Mat alphaMat = Mat::zeros(1, supportVectorNum, CV_32FC1);
- Mat supportVectorMat = Mat::zeros(supportVectorNum, DescriptorDim, CV_32FC1);
- Mat resultMat = Mat::zeros(1, DescriptorDim, CV_32FC1);
-
-
- for(int i=0; i<supportVectorNum; i++)
- {
- const float * pSVData = svm.get_support_vector(i);
- for(int j=0; j<DescriptorDim; j++)
- {
-
- supportVectorMat.at<float>(i,j) = pSVData[j];
- }
- }
-
-
- double * pAlphaData = svm.get_alpha_vector();
- for(int i=0; i<supportVectorNum; i++)
- {
- alphaMat.at<float>(0,i) = pAlphaData[i];
- }
-
-
-
- resultMat = -1 * alphaMat * supportVectorMat;
-
-
- vector<float> myDetector;
-
- for(int i=0; i<DescriptorDim; i++)
- {
- myDetector.push_back(resultMat.at<float>(0,i));
- }
-
- myDetector.push_back(svm.get_rho());
- cout<<"检测子维数:"<<myDetector.size()<<endl;
-
- HOGDescriptor myHOG;
- myHOG.setSVMDetector(myDetector);
-
-
-
- ofstream fout("HOGDetectorForOpenCV.txt");
- for(int i=0; i<myDetector.size(); i++)
- {
- fout<<myDetector[i]<<endl;
- }
-
-
-
-
-
- Mat src = imread("1.png");
- vector<Rect> found, found_filtered;
- cout<<"进行多尺度HOG人体检测"<<endl;
- myHOG.detectMultiScale(src, found, 0, Size(8,8), Size(32,32), 1.05, 2);
- cout<<"找到的矩形框个数:"<<found.size()<<endl;
-
-
- for(int i=0; i < found.size(); i++)
- {
- Rect r = found[i];
- int j=0;
- for(; j < found.size(); j++)
- if(j != i && (r & found[j]) == r)
- break;
- if( j == found.size())
- found_filtered.push_back(r);
- }
-
-
- for(int i=0; i<found_filtered.size(); i++)
- {
- Rect r = found_filtered[i];
- r.x += cvRound(r.width*0.1);
- r.width = cvRound(r.width*0.8);
- r.y += cvRound(r.height*0.07);
- r.height = cvRound(r.height*0.8);
- rectangle(src, r.tl(), r.br(), Scalar(0,255,0), 3);
- }
-
- imwrite("ImgProcessed.jpg",src);
- namedWindow("src",0);
- imshow("src",src);
- waitKey();
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- system("pause");
- }
结果:
(1) 1500个INRIA正样本,2000个负样本,结果误报太多:

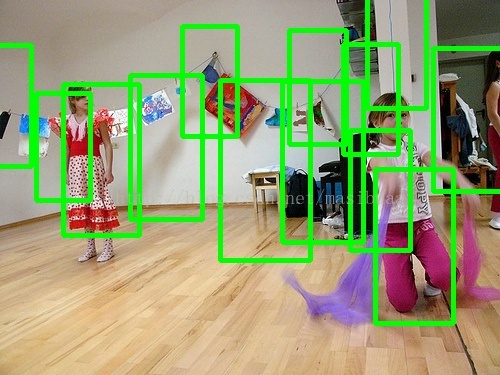
(2) 2400个INRIA正样本,12000个负样本,结果表明负样本增多后误报明显减少,但依然有不少误报:


(3)2400个INRIA正样本,12000个负样本 + 4435个用(2)中的分类器在负样本原图上检测出来的Hard Example,
结果误报明显减少,几乎没有误报了,但同时漏检率增加:




上图中的两个小女孩都没有被检测出来
(4)下面是OpenCV中HOG检测器的默认SVM参数的结果,OpenCV自带的SVM参数也是用INRIA数据集训练得到的:



上图中的两个小女孩用OpenCV默认SVM参数也检测不出来。
所以感觉要想效果好的话,还应该加大正样本的个数。
参考:
http://blog.csdn.net/carson2005/article/details/7841443
源码下载,环境为VS2010 + OpenCV2.4.4
http://download.csdn.net/detail/masikkk/6547973
1500个INRIA正样本,2000个负样本训练好的SVM下载(XML文件):http://pan.baidu.com/s/18CCos
2400个INRIA正样本,12000个负样本训练好的SVM下载(XML文件):http://pan.baidu.com/s/1gmudL
2400个INRIA正样本,12000个负样本 + 4435个用(2)中的分类器在负样本原图上检测出来的Hard Example 训练好的SVM下载(XML文件):http://pan.baidu.com/s/126Yoc


























 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









