







 1.介绍该文讲述的是语义分割,但思路和框架和深度恢复是十分相似的,毕竟当前语义和深度问题本质上是一个像素级的分类问题。从该文3000+引用用量也可见该文章的巨大启发效果。所谓全卷积网络,是指由仅由卷积层、池化层和非线性激活函数层交错组织起来的网络。作者的贡献在于将非常热门且有效地做分类的卷积网络应用于语义分割中。整个框架是接受整张图像作为输入,用卷积做一个coarse的分类输出,然后将这些输出与每个
1.介绍该文讲述的是语义分割,但思路和框架和深度恢复是十分相似的,毕竟当前语义和深度问题本质上是一个像素级的分类问题。从该文3000+引用用量也可见该文章的巨大启发效果。所谓全卷积网络,是指由仅由卷积层、池化层和非线性激活函数层交错组织起来的网络。作者的贡献在于将非常热门且有效地做分类的卷积网络应用于语义分割中。整个框架是接受整张图像作为输入,用卷积做一个coarse的分类输出,然后将这些输出与每个
1.介绍
该文讲述的是语义分割,但思路和框架和深度恢复是十分相似的,毕竟当前语义和深度问题本质上是一个像素级的分类问题。从该文3000+引用用量也可见该文章的巨大启发效果。
所谓全卷积网络,是指由仅由卷积层、池化层和非线性激活函数层交错组织起来的网络。
作者的贡献在于将非常热门且有效地做分类的卷积网络应用于语义分割中。整个框架是接受整张图像作为输入,用卷积做一个coarse的分类输出,然后将这些输出与每个像素联系在一起,得到最后的像素级别的语义分类结果输出。主要改进如下:
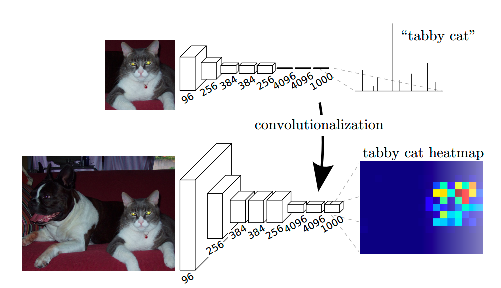
可以看出,作者将全连接层改为卷积层。
全连接层可以看成核大小为图像边长的卷积层,感知到整张图像。所以相对于全连接层,普通的核很小的的卷积层只能感知上一层中的区域信息,所谓卷积层能很好地保持空间信息(不剧烈变化),有“spatial output”,而全连接层只有“non-spatial output”。而且卷积层可以随意调整输出大小(一般是降采样,即图像变小),得到coarse 的输出。
作者分别使用了pretrained VGG,AlexNet和自己实现的GoogleNet。将上述模型后半的全连接层改为卷积层。这样这些模型就成了FCN了。再加上一个1x1x21(有21种类别)的卷积层作为预测输出,得到缩小的语义map。最后再对输出进行反卷积得到最终和原图同等大小的输出。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4480
4480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









