







在过去的几年中,人工智能领域取得了革命性的进展,最好的例子可能是像ChatGPT这样基于LLM的应用的近期流行和广泛传播。这些突破是由用于训练人工智能模型的机器设备中同样令人振奋的发展所推动的。新颖而创新的架构、复杂的张量处理核心和专用硬件加速器使得越来越大、速度越来越快的人工智能模型能够以更快的速度趋于融合。在本文中,我们将关注人工智能专用硬件领域的一个特定进展——即专用的8位浮点(FP8)张量处理核心。出现在最现代的人工智能硬件架构中(例如Nvidia Hopper、Nvidia Ada Lovelace和Habana Gaudi2),FP8张量核心实现了浮点每秒操作(FLOPS)的显著增加,同时为人工智能训练和推理工作负载提供了内存优化和能量节约的机会。
要充分利用硬件层面的FP8功能,需要在构建人工智能训练和推理应用程序的软件堆栈和开发框架中提供适当的支持。在本文中,我们将描述如何修改PyTorch训练脚本,以利用Nvidia H100 GPU的内置FP8数据类型支持。我们将首先提供使用FP8数据类型的动机。然后,我们将回顾由Transformer Engine库提供的与FP8相关的PyTorch API支持,并展示如何将其整合到一个简单的训练脚本中。尽管我们不会深入讨论使用FP8进行人工智能训练的理论,但我们将注意到其中可能涉及的潜在挑战。最后,我们将展示FP8数据类型的显著优化机会。
免责声明
请不要将我们对任何软件组件、方法或服务的提及解释为对其使用的认可。最佳的机器学习开发设计将根据您自己AI工作负载的具体细节而大不相同。请还要注意,我们将提及的一些软件包和组件的API和行为可能在您阅读本文时发生变化。强烈建议您基于最新的硬件和软件评估任何潜在的设计决策。
动机
随着人工智能模型变得越来越复杂,用于训练它们的设备也越来越庞大。据说支持“前所未有的性能和可扩展性”的Nvidia H100 GPU是(在撰写本文时)Nvidia最新且最强大的人工智能加速器,专门设计用于实现下一代人工智能的发展目标。随着当前人工智能热潮的全面展开,对这些GPU的需求非常巨大(例如,请参阅此处)。因此,毫不奇怪地,这些GPU的成本非常高——甚至对我们的许多读者来说可能是令人望而却步的。幸运的是,云服务提供商如AWS、GCP和Microsoft Azure提供了“按使用付费”(按小时/按秒)的H100供电机器的访问权限,从而为更广泛的人工智能开发社区打开了使用这些设备的机会。
在AWS中,H100 GPU作为最近宣布的AWS EC2 p5实例系列的组成部分提供。据称,这些实例“与基于先前一代GPU的EC2实例相比,加速了解决方案的时间,将训练ML模型的成本降低了多达40%”。
在最近的一篇文章中,我们讨论了选择ML训练实例时应考虑的一些因素。我们强调了最优实例类型将非常依赖于手头的项目这一事实。特别是在涉及ML训练实例时——更大并不总是更好。这一点在p5实例系列中尤为明显。确实,p5可能会胜过任何其他实例类型——毕竟,H100是一台性能无可争议的怪兽。但一旦考虑到p5的成本(在撰写本文时,8-GPU p5.48xlarge实例的每小时费用为98.32美元),您可能会发现其他实例类型更适合。
在下一节中,我们将在p5.48xlarge上训练一个相对较大的计算机视觉模型,并将其性能与包含8个Nvidia A100 GPU的p4d.24xlarge进行比较。
玩具模型
在下面的代码块中,我们定义了一个以Vision Transformer(ViT)为支持的分类模型(使用流行的timm Python包版本0.9.10),以及一个随机生成的数据集。ViT的主干结构有各种各样的形状和大小。在这里,我们选择了通常称为ViT-Huge配置的模型 — 具有632百万个参数 — 以更好地利用H100对大型模型的容量
import torch, time
import torch.optim
import torch.utils.data
import torch.distributed as dist
from torch.nn.parallel.distributed import DistributedDataParallel as DDP
import torch.multiprocessing as mp
# modify batch size according to GPU memory
batch_size = 64
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=[index % 1000], dtype=torch.int64)
return rand_image, label
def mp_fn(local_rank, *args):
# configure process
dist.init_process_group("nccl",
rank=local_rank,
world_size=torch.cuda.device_count())
torch.cuda.set_device(local_rank)
device = torch.cuda.current_device()
# create dataset and dataloader
train_set = FakeDataset()
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size,
num_workers=12, pin_memory=True)
# define ViT-Huge model
model = VisionTransformer(
embed_dim=1280,
depth=32,
num_heads=16,
).cuda(device)
model = DDP(model, device_ids=[local_rank])
# define loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(train_loader):
# copy data to GPU
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
# use mixed precision to take advantage of bfloat16 support
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# capture step time
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 50:
break
print(f'average step time: {summ/count}')
if __name__ == '__main__':
mp.spawn(mp_fn,
args=(),
nprocs=torch.cuda.device_count(),
join=True)我们使用专用的PyTorch 2.1 AWS深度学习容器(763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:2.1.0-gpu-py310-cu121-ubuntu20.04-ec2)在p5.48xlarge和p4d.24xlarge实例类型上对该模型进行了训练。
毫不奇怪,p5的步骤时间性能远远超过p4d的性能 — 每步0.199秒,而p4d为0.41秒 — 快了一倍多!这意味着训练大型ML模型的时间可以减半。然而,当考虑到成本差异(在撰写本文时,p4d每小时32.77美元,而p5每小时98.32美元)时,完全不同的故事展开。与p4d相比,p5的性价比要差约30%!这与p5发布时宣称的40%的改进相去甚远。
在这一点上,您可能得出两种可能的结论之一。第一种可能性是,尽管存在所有的炒作,但p5可能并不适合您。第二种可能性是,p5仍然可能是可行的,但需要对您的模型进行调整,以充分发挥其潜力。在接下来的部分中,我们将采取第二种方法,演示如何使用FP8数据类型(p5实例类型特有)可以完全改变比较性价比的结果。
集成FP8与Transformer Engine 首先要强调的是,截至本文撰写时,PyTorch(版本2.1)并不包括本机支持的8位浮点数据类型。为了使我们的脚本使用FP8,我们将使用Transformer Engine(TE),这是一个专门用于在NVIDIA GPU上加速Transformer模型的库。TE(版本0.12)在AWS PyTorch 2.1 DL容器中预装。
尽管使用FP8进行训练的理论超出了本文的范围(例如,请参阅此处),但重要的是要意识到使用FP8的机制比16位替代方案(float16和bfloat16)复杂得多。幸运的是,TE的实现将所有混乱的细节隐藏在用户背后。请参阅官方文档以及这个简单的例子,了解如何使用TE的API。要了解在幕后发生了什么,请务必查看以下两个视频教程。
FP8 Training with Transformer Engine | NVIDIA On-Demand
FP8 for Deep Learning | NVIDIA On-Demand
为了修改我们的模型以使用TE,我们将TE的专门Transformer层封装在一个符合timm块层签名的自定义Transformer块类中
import transformer_engine.pytorch as te
from transformer_engine.common import recipe
class TE_Block(te.transformer.TransformerLayer):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_norm=False,
proj_drop=0.,
attn_drop=0.,
init_values=None,
drop_path=0.,
act_layer=None,
norm_layer=None,
mlp_layer=None
):
super().__init__(
hidden_size=dim,
ffn_hidden_size=int(dim * mlp_ratio),
num_attention_heads=num_heads,
hidden_dropout=proj_drop,
attention_dropout=attn_drop
)接下来,我们修改VisionTransformer的初始化,以使用我们的自定义块层:
model = VisionTransformer(
embed_dim=1280,
depth=32,
num_heads=16,
block_fn=TE_Block
).cuda(到目前为止,我们还没有进行任何H100特定的更改——相同的代码可以在我们的A100供电的p4d实例类型上运行。最后的修改是使用`te.fp8_autocast`上下文管理器封装模型的前向传递。此更改需要支持FP8的GPU:
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
with te.fp8_autocast(enabled=True):
outputs = model(inputs)
loss = criterion(outputs, label)使用8位浮点表示法(而不是16位或32位表示法)意味着较低的精度和较低的动态范围。这可能对模型的达到性和/或收敛速度产生有意义的影响。尽管底层的TE FP8实现旨在解决这一挑战,但不能保证对您的模型有效。您可能需要调整底层的FP8机制(例如,使用TE配方API),调整一些超参数,和/或限制FP8的应用于模型的子部分。您可能会发现,尽管您尽了最大努力,但您的模型可能与FP8不兼容。
结果 在下表中,我们总结了我们在p4d.24xlarge和p5.48xlarge EC2实例类型上进行的实验的结果,包括使用和不使用TE库。对于p5.48xlarge实验,我们增加了批处理大小以提高80 GB GPU内存的利用率。使用FP8减少了GPU内存消耗,从而进一步增加了批处理大小。
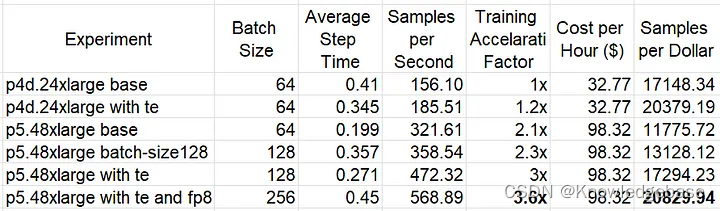
我们可以看到,使用TE Transformer块在p4d(约增加19%)和p5(约增加32%)实例类型上提高了性价比。使用FP8在p5上额外提高了约20%的性能。在TE和FP8的优化之后,基于H100的p5.48large的性价比超过了基于A100的p4d.24large——尽管差距不是很大(约2%)。考虑到训练速度增加了3倍,我们可以安全地得出结论,p5将是训练我们优化模型的更好实例类型。
请注意,性价比的相对小幅增加(远低于p5发布中提到的40%)让我们希望有更多的H100特定优化... 但这将得等到另一篇文章再讨论:)。
总结 在这篇文章中,我们演示了如何编写一个PyTorch训练脚本来使用8位浮点类型。我们进一步展示了如何使用FP8可以成为获得Nvidia H100等现代GPU最佳性能的关键因素。重要的是,FP8的可行性以及对训练性能的影响可能会根据模型的具体细节而有很大的变化。
这篇文章延续了关于优化机器学习工作负载的一系列长篇论著。确保查看我们在这一重要主题上的其他一些文章。


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











