






一. NVIDIA驱动安装
使用命令:ubuntu-drivers devices 获取可用驱动信息
系统设置-->软件和更新-->附加驱动-->应用更改。
当然也可以采用命令安装或者到NVIDIA官网下载手动安装

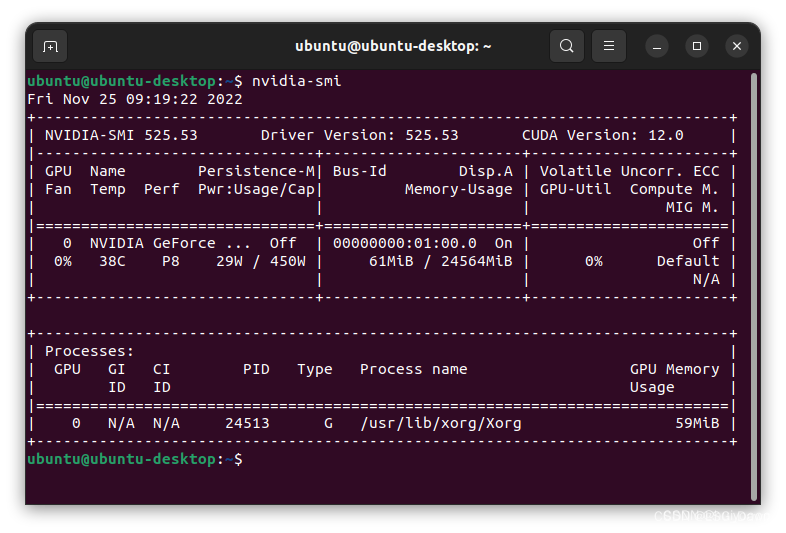
驱动装好后在终端执行:nvidia-smi 如果出现如下图则安装成功
二.CUDA的安装
CUDA Toolkit Archive | NVIDIA Developer 官网下载cuda11.8,按步骤进行安装,注意在安装cuda时取消驱动安装这个选项

按照上图中选择自己对应的选项,然后执行提供的两条安装命令即可(在主目录下创建cuda文件夹,然后把下载好的安装包复制到cuda 文件夹下,然后打开终端,进入cuda文件夹,
执行
sudo sh cuda_11.8.0_520.61.05_linux.run)
以上命令中的版本号要根据你选择的版本修改,依次执行以上命令
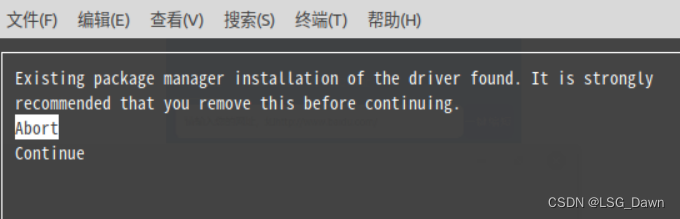
如果出现以下界面,提醒你已经安装了driver的时候,直接continue。
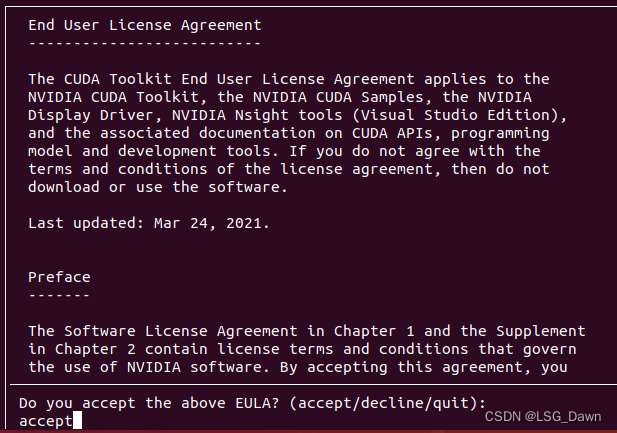
经过一小会的卡顿后,选择accept
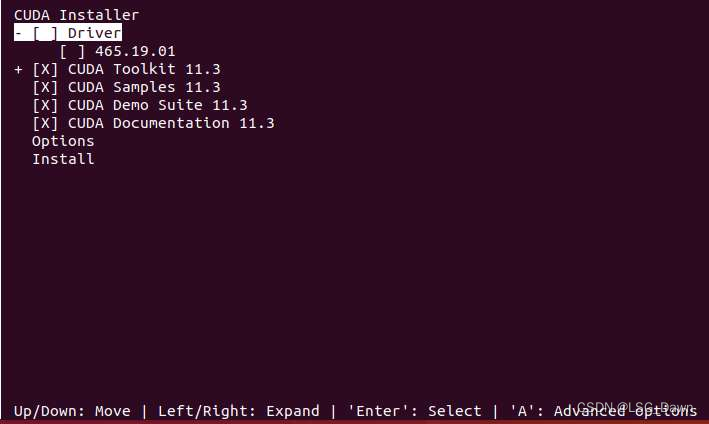
当选择安装内容的时候,务必把driver前面的x取消掉,按回车键取消勾选,因为我们已经安装了驱动!!!,否则会出现[ERROR]: Install of driver component failed.的情况
之后选择install便可完成cuda的安装,安装成功如下图所示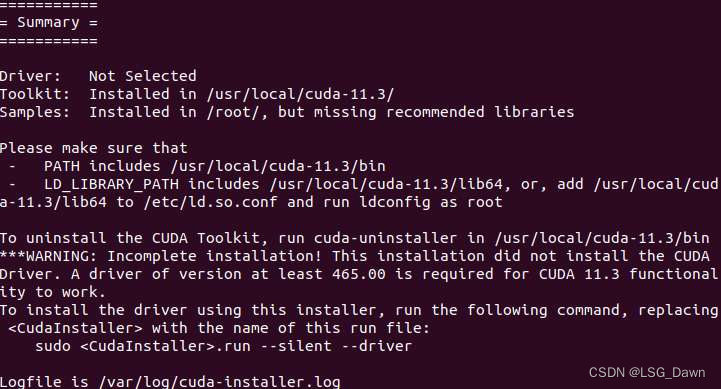
配置环境变量
修改环境变量文件
sudo gedit ~/.bashrc
将下面代码,写入文件最下方
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-11.8/bin:$PATH
export CUDA_HOME=/usr/local/cuda-11.8:$CUDA_HOME
然后保存退出,执行如下命令
source ~/.bashrc
此时再运行nvcc -V,即可发现cuda已安装成功:
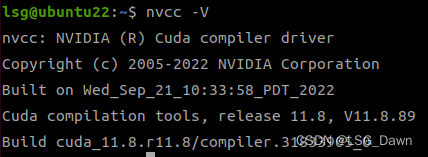
三.cuDNN的安装
NVIDIA官网cuDNN下载页面下载cuDNN8.6.0的对应版本压缩文件夹。

在主目录创建cudnn文件夹,将下载好的压缩包拷贝到该文件夹下,然后解压,进入到解压后的文件夹

解压后将对应include和lib中的文件拷贝到cuda-11.8的include和lib64文件夹中:
sudo cp -r lib/* /usr/local/cuda-11.8/lib64
sudo cp -r include/* /usr/local/cuda-11.8/include到此cuDNN安装完成,验证cuDNN,查看版本
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
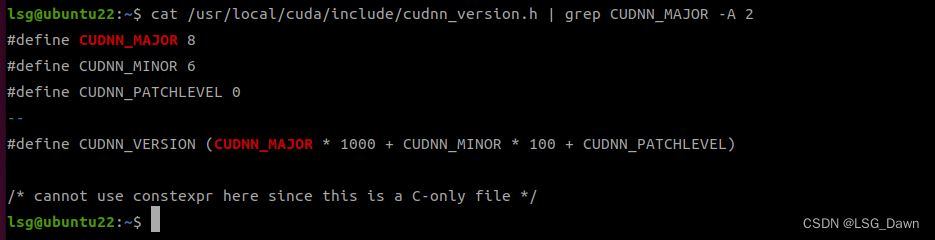
可以看到是8.6.0版本
四.TensorRT安装
NVIDIA官网TensorRT下载页面下载TensorRT的对应版本压缩文件夹。
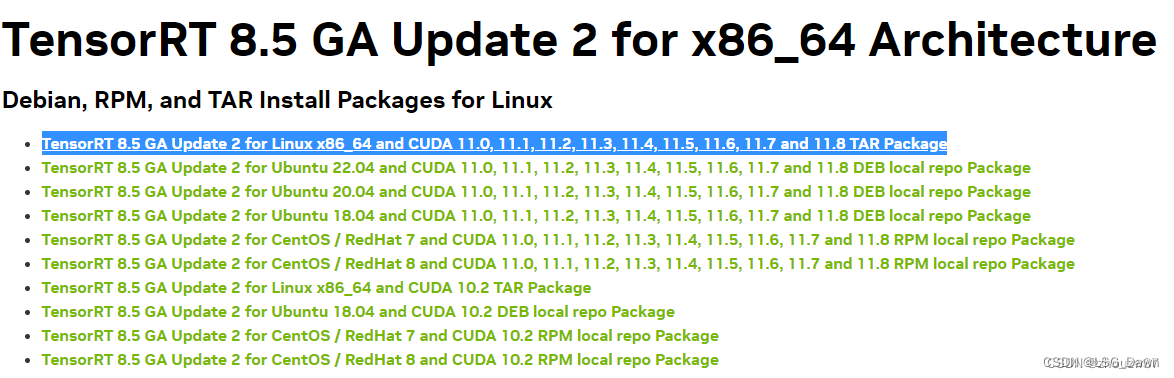
同cuDNN类似,解压后将对应include和lib中的文件拷贝到cuda-11.8的include和lib64文件夹中:
sudo cp -r lib/* /usr/local/cuda-11.8/lib64
sudo cp -r include/* /usr/local/cuda-11.8/include打开配置文件
sudo gedit ~/.bashrc
把如下代码添加到配置文件最末端
export LD_LIBRARY_PATH=/data/TensorRT-8.5.3.1/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=/data/TensorRT-8.5.3.1/lib::$LIBRARY_PATHsource配置文件
source ~/.bashrcTensoRT安装测试
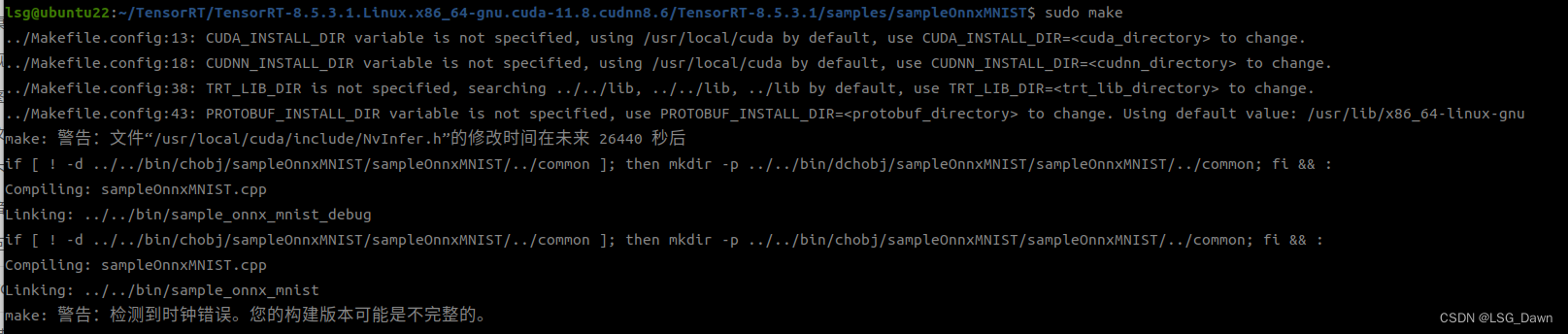
TensorRT解压文件夹中找到sample目录下的sampleOnnxMNIST,在该目录中make一下,并在生成bin目录下执行:./sample_onnx_mnist。(注意图片中的文件路径)

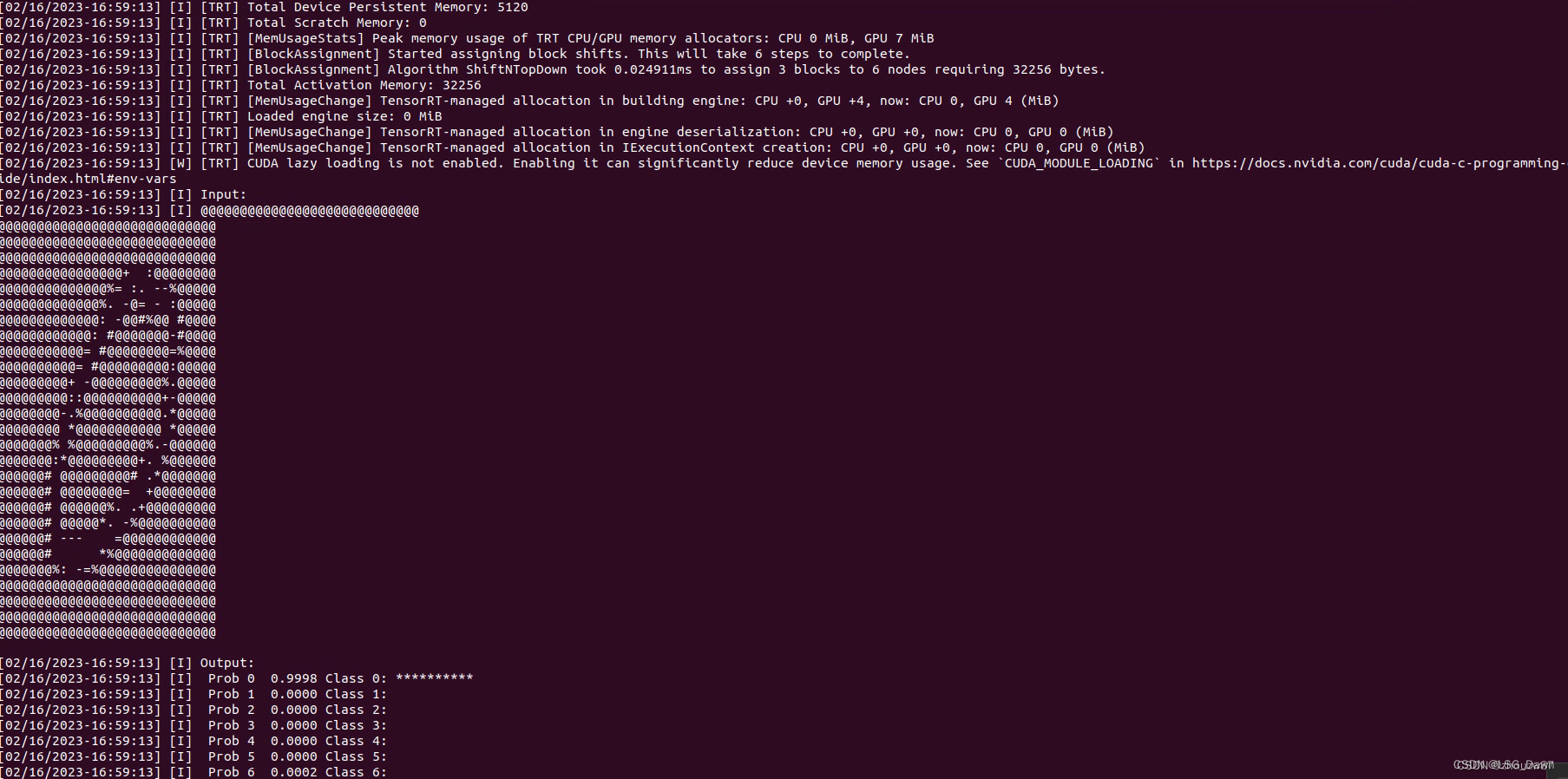
至此上述环境配置完成,后面在装pytorch深度学习框架















 4469
4469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









