







https://blog.paperspace.com/
目标跟踪在在某些程度上可以说是目标检测的一个维度拓展。目标检测类似于贝叶斯 Filtering 和 Smoothing 中的观测器,整个目标跟踪 task 就像是(offline tracking 对应于smoothing 问题,online tracking对应于filtering 问题)一个 time-vary system,我们要做的就是使用 observation 来估计系统的 Hiden State (current object location 或 offline 中的所有 frame 中 object location)。因此观测器极为重要,它是一个noisy measurement。现在我们从最经典的目标检测 Framework Faster R-CNN入手。
本文回顾了微软研究人员开发的Faster R-CNN模型。Faster R-CNN是一个用于目标检测的深度卷积网络,对用户来说是一个单一的、端到端、统一的网络。该网络能够准确、快速地预测不同物体的位置。为了真正理解Faster R-CNN,我们还必须对其演变的网络做一个快速的概述,即R-CNN和Fast R-CNN。
本文首先快速回顾了基于区域的CNN (R-CNN),这是第一次尝试使用预先训练的CNN构建对象检测模型来提取特征。接下来,Fast R-CNN很快被发布,它比R-CNN快,但不幸的是忽略了区域建议是如何产生的。这个问题稍后由Faster R-CNN解决,它构建一个区域建议网络,可以生成区域建议,并将区域建议提供给检测模型(Fast R-CNN)来检测物体。
本文的提纲如下:
- Overview of the Object Detection Pipeline
- R-CNN 概述
- Fast R-CNN 概述
- Faster R-CNN
- Region Proposal Network (RPN)
- Anchors
- Objectness Score
- Feature Sharing between RPN and Fast R-CNN
- 训练 Faster R-CNN
- Alternating Training
- Approximate Joint Training
- Non-Approximate Joint Training
- Drawbacks
- Mask R-CNN
- Conclusion
- References
博客中提到的论文可以免费下载。本文末尾的参考文献中部分提供了这些论文的引用和下载链接。
目标检测流程概述
传统的目标检测技术遵循如下图所示的3个主要步骤。第一步涉及生成几个region proposals。这些region proposals是可能包含对象的候选方案。这些region proposal的数量通常在几千,例如2000或更多。一些生成region proposal的算法的例子是选择性搜索 (Selective Search) 和边缘框 (EdgeBoxes)。
从每个region proposal中,使用各种图像描述符提取固定长度的特征向量,例如定向梯度直方图(HOG)。该特征向量是目标检测器成功的关键。向量应该充分地描述一个对象,即使它因某些变换(如缩放或平移)而变化。

然后使用特征向量将每个 region proposal 分配给背景类或对象类之一。随着类数量的增加,构建能够区分所有这些对象的模型的复杂性也会增加。支持向量机(SVM)是一种用于分类区域建议的流行模型。
下面的这个快速的概述足以理解基于区域的卷积神经网络(R-CNN)的基础知识。
R-CNN概览
2014年,加州大学伯克利分校的一组研究人员开发了一种名为 R-CNN (区域卷积神经网络的简称)[1]的深度卷积网络,可以检测图像中80种不同类型的物体。
与上图所示的目标检测技术的通用 pipeline 相比,R-CNN[1]的主要贡献只是基于卷积神经网络(CNN)提取特征。除此之外,一切都类似于通用对象检测 pipeline。下图是R-CNN模型的工作过程。

R-CNN由3个主要模块组成:
- 第一个模块使用选择性搜索 (Selective Search) 算法生成2000个区域建议。
- 在调整大小为一个固定的预定义大小后,第二个模块从每个 region proposal 提取长度为4096的特征向量。
- 第三个模块使用一个预先训练的SVM算法来分类区域建议的背景或对象类之一。
R-CNN 模型有一些缺点:
- 它是一个多阶段模型,每个阶段是一个独立的组件。因此,它不能端到端进行训练。
- 它将预先训练的CNN中提取出来的特征缓存在磁盘上,以训练支持向量机。这需要数百GB的存储空间。
- R-CNN 依赖于选择性搜索 (Selective Search) 算法来生成区域建议 (region proposal),这需要大量的时间。此外,该算法不能针对检测问题进行定制。
- 每个区域建议 (region proposal) 被独立地反馈给 CNN进行特征提取。这使得R-CNN无法实时运行。
作为 R-CNN 模型的扩展,Fast R-CNN 模型[2] 被提出以克服其局限性。下一节将给出 Fast R-CNN 的快速概述。
Fast R-CNN快速概述
Fast R-CNN [2]是一款由 Ross Girshick 独立开发的物体检测器,他是一名 Facebook 人工智能研究员和前微软研究员。Fast R-CNN 克服了几个问题在R-CNN。顾名思义,Fast R-CNN 相对于R-CNN 的一个优势就是它的速度。
这里是Fast R-CNN 一个主要贡献的总结 :
- 提出了一种新的层,称为 ROI Pooling,ROI 从同一幅图像中的所有 proposal (即ROI) 中提取等长的特征向量。
- 相对于 R-CNN 具有多个阶段(区域建议生成、特征提取、使用SVM分类),Fast R-CNN构建的网络只有一个阶段。
- Fast R-CNN共享所有 proposal (即ROI) 的计算(即卷积层计算),而不是单独为每个 proposal 进行计算。这是通过使用新的 ROI Pooling 层来实现的,这使得Fast R-CNN比R-CNN更快。
- Fast R-CNN 不缓存提取的特征,因此不需要太多的磁盘存储。R-CNN它需要数百GB存储空间。
- 快速R-CNN比R-CNN更准确。
Fast R-CNN 的总体架构如下图所示。与 R-CNN 的3个阶段相比,该模型只有一个阶段。它只接受图像作为输入,并返回被检测对象的类概率和边界框。

最后一个卷积层的特征图被输入给 ROI Pooling 层。原因是要从每个区域建议中提取一个固定长度的特征向量。下图显示了ROI Pooling 层是如何工作的。
简单地说,ROI Pooling 层的工作原理是将每个 region proposal 分割成一个网格单元。对网格中的每个单元格应用 max pooling操作以返回单个值。所有单元格的所有值表示特征向量。如果网格大小为2×2,则特征向量长度为4。



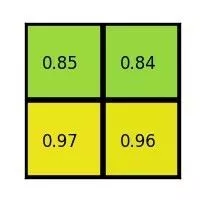
有关 ROI Pooling 层的更多信息,请参阅这篇文章。
利用 ROI Pooling 提取的特征向量传递给FC层。最后一个 FC 层的输出分为2个分支:
- S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









