






BEV下统一的多传感器融合框架 - FUTR3D
引言
在自动驾驶汽车或者移动机器人上,通常会配备许多种传感器,比如:光学相机、激光雷达、毫米波雷达等。由于不同传感器的数据形式不同,如RGB图像,点云等,不同模态的数据的信息密度和特性也不同,如何能够有效地融合各个模态的数据使得车或机器人能够准备地感知周围的场景是一个非常关键的问题。
下面就由陈炫耀同学来介绍我们的论文:FUTR3D: A Unified Sensor Fusion Framework for 3D Detection[1],网站链接:FUTR3D。
之前多模态融合的工作主要是为特定的传感器组合设计算法,比如用图像去增强点云(PointPainting,MVP)、用图像检测框去辅助点云检测(Frustum PointNet)等。而在FUTR3D中,我们试着在BEV下构建一个通用的可容纳各种不同传感器的3D目标检测框架。

FUTR3D的主要贡献如下:
-
通用框架。FUTR3D是第一个通用的可适应各种不同传感器的端到端的三维目标检测框架。
-
有效性。它在Camera, LiDAR, Camera+LiDAR , Camera+Radar等不同的传感器组合情况下都能实现领先效果。
-
低成本。FUTR3D在Camera+4线LiDAR的情况下能够超过32线LiDAR的结果,因此能够促进低成本的自动驾驶系统。

附赠自动驾驶学习资料和量产经验:链接
FUTR3D方案

FUTR3D主要包括Modality-Specific Feature Extractor, Modality-Agnostic Feature Sampler和Loss。
Modality-Specific Feature Extractor
对于不同的传感器输入数据,我们根据它们各自的模态形式分别用不同的backbone去提取它们的特征。
-
对于camera images,采用ResNet50/101和FPN来对每张图片提取多尺度的特征图。
-
对于LiDAR point clouds,用PointPillar或者VoxelNet来提取点云的特征。
-
对于Radar point clouds,用3层MLP来提取每个Radar point的特征。
Modality-Agnostic Feature Sampler
模态无关的特征采样器,下面简称MAFS,是FUTR3D的detection head与各个模态的特征进行交互的部分。
类似于DETR3D,MAFS含有600个object query,每个query会经过一个全连接网络预测出在BEV下的3D reference points。
对于camera部分,我们依照DETR3D的做法,利用相机的内外参数将reference points投影到image上采集feature,得到 ��cam 。具体做法可以参看上篇文章,这里就不详细展开。
对于LiDAR部分,我们按照reference points在3D空间中的坐标,投影到LiDAR BEV特征上去采集它在LiDAR feature map上对应位置的feature,得到 ��lid 。
对于Radar部分,根据每个reference points的位置,选取离它最近的10个Radar points的特征,并聚合在一起得到 ��rad 。
采集得到各个模态的对应特征之后,将它们concatenate到一起,并经过一个MLP网络投射到一个共同的特征空间中。
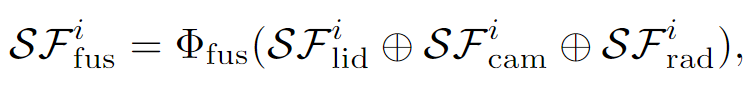
之后再利用 ��fus 以及reference points的位置编码去更新object query的信息。

在FUTR3D中,我们同样有6层decoder layer,在每层decoder layer中,用object query之间的self attention和MAFS去更新object query的信息,并且每个query会去通过MLP网络去预测得到bounding box的参数和reference points的offsets去迭代更新每一层的预测结果。
Loss
在loss部分,我们先利用Hungarian算法来将每个object query预测得到的bbox去和ground-truth box进行二分图匹配,得到最优的matching方案,然后对匹配成功的box计算regression L1 loss和classification focal loss,没有匹配到gt box的predicted box就只计算classification loss。
实验结果
FUTR3D作为一个通用框架,在各个不同传感器的配置下都能取得state-of-the-art的结果,超过针对特定输入组合的算法。特别是在低线LiDAR,如1线、4线等,FUTR3D表现出了很好的鲁棒性,结果远超其他方案。值得一提的是,在Cameras+4线LiDAR的情况下,FUTR3D达到了56.8mAP,超过了32线LiDAR的sota结果56.6mAP(CenterPoint)。

表 Cameras和LiDAR融合的结果

表 Cameras和Radar融合的结果
结果分析
由于FUTR3D的通用性,我们得以分析各个模态在目标检测中不同的特性。
在Cameras+LiDAR融合中,Cameras对体积小和距离远的物体有着显著的帮助作用。

表 对不同距离的物体的模型表现
可视化结果
在各种不同传感器配置组合的融合中,我们发现一些非常有趣的场景,并由其可以对比看出各个不同传感器之间不同的特性。
在Cameras+4 Beam LiDAR和32 Beam LiDAR的对比中,可以看出即使点云稀疏得多的情况下,相机也能极大地帮助检测那些体积小和距离远导致point很少的物体。

图 Cameras+4线LiDAR vs. 32线LiDAR对比
在Cameras+1线LiDAR和Cameras-only的对比中,可以看到即使只有一线LiDAR,也可以通过它提供的距离信息来帮助检测。

图 Cameras+1线LiDAR vs. Cameras-only 对比
下一篇预告
我们将在下一篇介绍BEV系的多相机多目标跟踪框架MUTR3D,MARS Lab的BEV系列未完待续,敬请期待!
参考
- ^FUTR3D: A Unified Sensor Fusion Framework for 3D Detection https://arxiv.org/abs/2203.10642















 3860
3860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









