








内容速览
人像生成方法
- 2D GANs:生成高保真度的人像,但图像一致性较低。
- 3D-aware GANs:可以保持视图的一致性,但它们生成的图像不能本地编辑。
FENeRF:
- 一个3d感知的生成器,可以产生一致的视图和本地编辑的肖像图像。
- 我们的方法使用两个解耦的latent codes (可以理解为无关)在一个空间对齐的具有共享几何的三维体中生成相应的面部语义和纹理
- FENeRF可以联合渲染边界对齐图像和语义掩码(semantic mask),并通过GAN反演利用语义掩码编辑三维体。、
- We adopt the noise-to-volume scheme. 该生成器以解耦后的形状和纹理潜在代码作为输入,生成一个3D体,其中面部语义和纹理通过共享的几何测量在空间上对齐。
- 颜色和语义判别器被用来监督NeRF生成器的训练。颜色鉴别器关注图像细节,提高了图像保真度。语义鉴别器以一对图像和语义映射作为输入,强制对三维体中相应的内容进行对齐
数据集
- CelebAMask-HQ
- FFHQ
Contributions:
- 我们提出了第一个肖像图像生成器,它是本地可编辑和严格的视图一致,受益于语义、几何和纹理空间对齐的3D表示
- 在不需要多视图或3D数据的情况下,我们使用成对的单目图像和语义地图来训练生成器。这确保了数据的多样性,并增强了生成器的表示能力
- :在实验中,我们发现联合学习的语义和纹理体积有助于生成更精细的三维几何。

框架图:
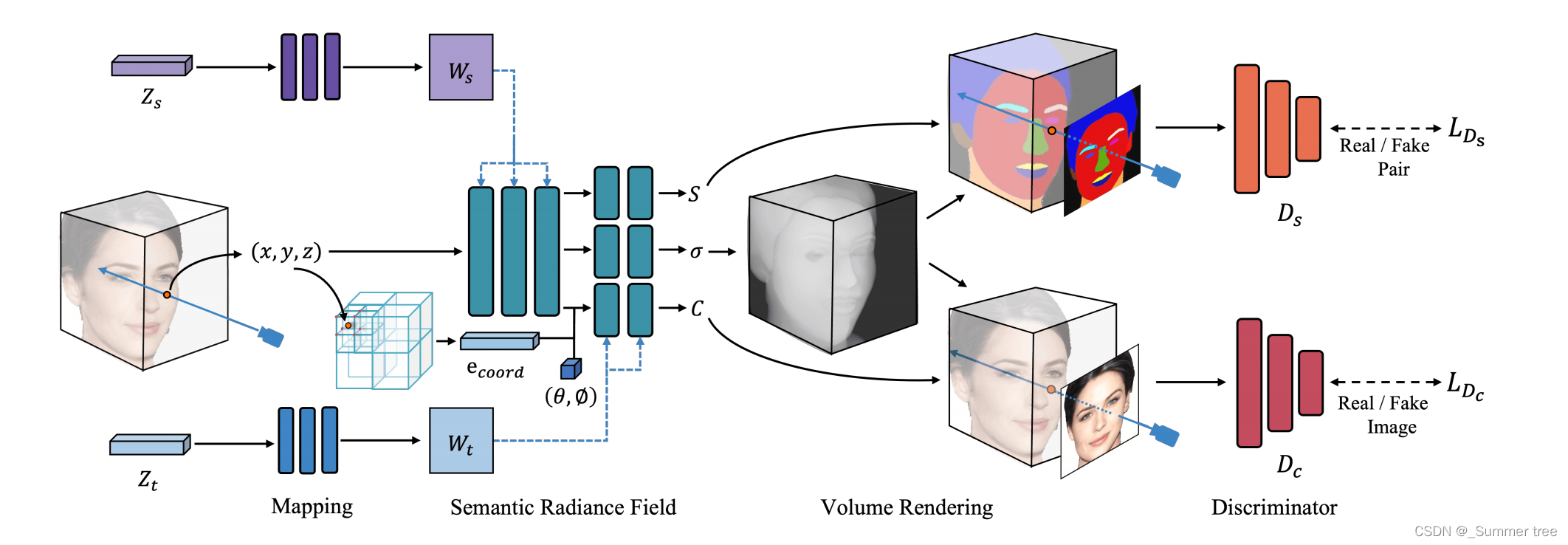
- 我们的生成器在解耦的潜在代码Zs和Zt的条件下产生空间对齐的密度(sigama),语义(s)和纹理场(C)
- e c o r r d e_{corrd} ecorrd 是位置特征编码,带着视角方向一起注入到网络中进行颜色预测,以保持生成图像中的高频细节。
- 通过共享相同的密度,对齐的rgb图像和语义映射被渲染
- 最后,分别用语义图/图像对和真/伪图像对对两个鉴别器
D
s
D_s
Ds
D
s
D_s
Ds进行训练 ,目标函数如下:


具体方法
1. 局部可编辑的NeRF生成器
两种latent codes
- shape latent code( Z s Z_s Zs) 控制几何和语义 (sigma 和 S)
- texture code( Z t Z_t Zt) 控制纹理体积中的外观
我们利用呈现的生成器中的三头结构来单独编码与密度体中描述的底层几何结构相一致的语义和纹理
生成器表示入下:

我们还利用映射网络将采样代码映射到中间潜在空间W,并输出频率γ和相移β:这个不是特征编码?

我们通过 bi-cubic插值从特征网格中抽取一个局部特征向量
e
c
o
o
r
d
x
e_{coord}^x
ecoordx,然后将其作为附加输入输入到颜色分支中。该操作的效果如下所示:

语义图 和人像图的计算:

具体的离散化操作和NeRF[31]一致。值得注意的是: 语义、密度和纹理三个分支具有相同的中间特征,在颜色和语义渲染过程中输出密度也是共享的,以确保生成的语义、密度和纹理在三维空间中完全对齐
2. 判别器
- 两个鉴别器Dc和Ds,参数化为CNN, ReLU激活[17]。
- Dc区分生成的肖像的保真度。
- 语义掩码,除了人脸图像,被作为d的输入。这是为了鼓励面部外观和语义的一致。
- 我们附加两个通道来预测摄像机的位姿,然后将摄像机的位姿校正损失与采样的位姿校正损失相结合。
3 训练
- 随机采样poses 和 latent codes zs 和zt 。
- 损失有三个部分组合。


语义渲染提高了人联合成的质量



















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











