







在科技的浪潮中,人形机器人正逐渐从科幻走向现实,成为人类生活中不可或缺的伙伴。它们不仅是技术的结晶,更是人类对自身、对世界的深刻思考。本文将带您走进人形机器人的世界,从哲学思考到技术实践,探索它们的感知与导航能力。这是一场跨越哲学与技术的旅程,让我们一同启程,揭开人形机器人的神秘面纱。
"我是谁?我从何处来?要向何处去?"三千年前,德尔斐神庙的箴言叩击着人类对存在的思考。在柏拉图的洞穴寓言中,人类通过墙上的影子认知世界。而现代人形机器人正通过多模态感知融合技术,将激光点云、深度视觉、力学反馈编织成数字世界的"真理之光"。
您是否想过,当机器人开始像人类一样感知世界时,它们眼中的“存在”意味着什么?导航算法背后是否暗含对人类认知的哲学思考?来自国家地方共建人形机器人创新中心(以下简称“国地中心”)的具身算法工程师——Quark老师针对这个主题带来了精彩的内容分享。

图片来源互联网
哲学启思:人形机器人的本质与目标
人形机器人,为何而生?它们并非仅仅是冰冷的机械,而是人类智慧的结晶,承载着适应人类环境、执行复杂任务的使命。人形机器人的拟人化形态使其能够无缝融入我们的世界,无需对现有基础设施进行大规模改造,高自由度的运动能力使其能够操作工具、攀爬楼梯,适应各种非结构化环境。它们是机器人技术的集大成者,通过研发人形机器人,我们可以验证这些技术的成熟度与协同能力,推动整个机器人领域的发展。
从《底特律:变人》这款互动电影式游戏中,我们可以窥见人形机器人的本质。游戏中的仿生人康纳、马库斯和卡拉,通过他们的故事线,展现了机器人在感知世界后对自由意志的探索、情感感知以及伦理觉醒。康纳的“扫描模式”能够实时分析环境,识别物体、分析人体状态,甚至预测犯罪嫌疑人的行为路径;马库斯的故事则反映了机器人对自我意识的觉醒;卡拉则展现了机器人在情感驱动下做出非程序化的决定。这些故事让我们思考:人形机器人的核心问题究竟是什么?它们的本质是拟人化形态与智能化能力的结合,目标是服务于人类,融入人类生活与环境。

图片来源互联网
我是谁?
——人形机器人的定位与感知
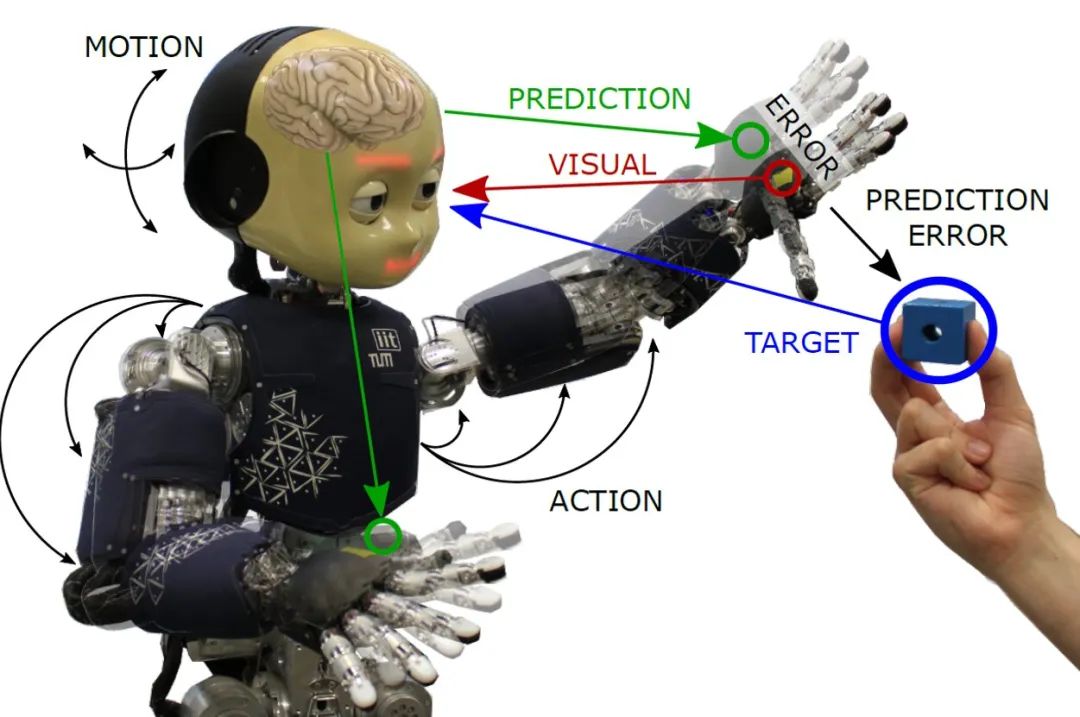
人形机器人不像固定式机械臂,它需要在动态环境中自由移动,因此精准的定位是核心挑战。目前,我们主要依赖惯性测量单元(IMU)、视觉里程计(VO)、激光雷达(LiDAR)与雷达 SLAM、GPS & RTK(高精度定位)以及融合传感器(Sensor Fusion)等方法来实现机器人的定位。然而,这些方法都存在一定的局限性,如 IMU 的误差累积、 VO 对光照和特征点丰富程度的敏感、 GPS 在室内的信号受限等。融合传感器通过结合多种传感器数据,使用卡尔曼滤波或因子图优化等技术,可以提高定位精度,但计算复杂度较高。
机器人如何感知周边环境呢?这涉及 2D/3D 视觉、点云处理、深度学习等技术。随着端到端深度学习感知系统(如 Transformer 、 BEV-SLAM )和多模态融合技术(如 CLIP 、 GPT-4V )的发展,机器人将能够更精准地理解视觉、语音、触觉等多源信息。例如,RGB/深度摄像头(RGB-D Cameras)如Intel Realsense 、Kinect,可用于识别物体和深度估计;激光雷达(LiDAR)提供高精度3D点云,可用于动态物体检测;毫米波雷达(Radar)适用于低能见度环境;触觉与力传感器则用于机械交互,如机器人手爪和足底平衡调整;语音与自然语言理解(NLP)用于语音交互、指令解析,提升人机交互体验。
图片来源互联网
然而,人形机器人在定位和感知方面面临独特的挑战。与轮式或四足机器人相比,人形机器人的多自由度运动方式更复杂,如手臂摆动、姿态调整会影响 IMU 惯性测量,导致误差积累;相机视角变化使得特征点容易丢失;自遮挡问题会导致部分视野丢失,影响深度摄像头的深度估计;动态环境中行人、车辆、门的变化使得传统 SLAM 难以稳定建图;摄像头与深度传感器数据采集不同步也会导致 3D 环境感知误差。
我从哪里来?
—— SLAM 与建图的技术挑战
SLAM(Simultaneous Localization and Mapping,即同时定位与建图)是机器人在未知环境中自我导航的核心技术。它让机器人能够在未知环境中实时确定自身位置、构建和更新环境地图,并在已有地图中重新确定位置。地图的构建与优化是 SLAM 的关键环节, 2D 地图(栅格地图、占据栅格)计算量较小,适用于轮式机器人导航,但无法描述高度变化(如楼梯); 3D 地图(点云、TSDF、NeRF)适用于人形机器人,能够表示坡道、台阶、障碍物,但计算复杂度高,对硬件性能要求更高。

图片来源互联网
人形机器人特有的 3D 建图挑战包括多自由度、双足行走误差以及非刚性环境适应性,为了解决这些问题,语义地图应运而生。传统 SLAM 仅构建几何地图,但对人形机器人而言,理解环境的语义信息更重要。语义 SLAM 的必要性在于提高导航效率,机器人可以基于目标理解进行导航(如“去厨房”),提升人机交互,机器人可以理解语义信息,更自然地与人交流。语义 SLAM 的实现方法包括视觉+深度学习(如 BEV-SLAM、GPT-4V),通过图像分割+目标检测提取语义信息;多模态融合(如 CLIP-SLAM),结合语言+视觉信息,使机器人能“看懂”物体。
重定位技术是机器人“认路”的关键。匹配特征点先验地图的方法基于 ORB 点,允许系统在无 GPS 或者跟踪失败时重新确定机器人的位姿,确保 SLAM 系统的鲁棒性和准确性。其优势是匹配速度快,任意位置重启后都可以迅速给出一个大致的重定位位姿,但劣势是精度不高,容易出现丢帧、跳点等现象。匹配点云先验地图的方法如 AMCL (自适应蒙特卡洛),利用粒子滤波进行姿态估计,将所有可能的姿态假设及其概率分布表示为一系列加权粒子。这些粒子通过交替执行重采样和 Kullback-Leibler 距离采样来跟踪机器人的位姿,以确保粒子数量足够多且合理分布。随着机器人运动数据和传感器观测数据的不断变化, AMCL 不断更新粒子的位置和权重,直至粒子收敛,获得具有协方差的位姿预测。其优势是重定位准确且位姿数据流畅稳定,但劣势是需要给出一个大致的初始位姿态才能进行帧间重定位。


图片来源互联网
从哲学角度看,“我从哪里来?”既是历史问题,也是机器人理解环境与自身关系的关键。机器人需要记住过去的地图(历史),并理解自己在环境中的位置(自我认知)。未来的机器人可能需要像人一样回忆环境变化,实现真正的“认知 SLAM ”。
以上内容只是人形机器人感知导航探索的序章,在下篇中,我们将深入探讨人形机器人的规划与导航技术,揭示它们如何在复杂环境中寻找最优路径,如何与人类协同工作,以及未来的发展方向。
OpenLoong 开源社区提供了一个开放交流的平台,在这里,大家可以共同探讨机器人仿真的难点与创新点。本次技术稿件也将在开源社区进行共享,欢迎大家点击下载稿件PDF,一起进行交流。
敬请期待下篇,让我们继续这场从哲学到技术的探索之旅,共同见证人形机器人的未来之路。

















 3586
3586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









