






1.是什么?
Label smooth loss是一种防止过拟合的正则化方法,它是在传统的分类loss采用softmax loss的基础上进行改进的。传统的softmax loss对于标签采用的是hard label的方式进行one hot编码,而Label smooth loss则对hard label得到的one hot编码添加一点点噪声,使得模型更加鲁棒。具体来说,Label smooth loss会将真实标签的概率值从1降低到一个较小的值,同时将其他标签的概率值从0提高到一个较小的值,这样可以使得模型更加关注数据的类别情况,从而提高模型的泛化能力。同时,Label smooth loss还可以减少模型对于噪声数据的过拟合,提高模型的鲁棒性。
NIPS 2019上的这篇论文When Does Label Smoothing Help?用实验说明了为什么Label smoothing可以work,指出标签平滑可以让分类之间的cluster更加紧凑,增加类间距离,减少类内距离,提高泛化性,同时还能提高Model Calibration(模型对于预测值的confidences和accuracies之间aligned的程度)。但是在模型蒸馏中使用Label smoothing会导致性能下降。
2.为什么?
label smooth是相对于hard label和soft label 而言的,一般的分类任务中我们对label是采用hard label的方式进行one hot编码,而对hard label得到的one hot编码添加一点点噪声。举例如下图来自——如何理解soft target这一做法?:

hard label和soft label的优缺点在图中也给出来了,相对来说soft label拥有携带更多的信息,更好的描述数据的类别情况,而hard label丢失了类内和类间的关联,从这个角度来看soft label确实能在一定程度上提高模型的泛化能力,也就是相同数据能提点。
3.怎么样?
3.1交叉熵损失函数在多分类任务中存在的问题
多分类任务中,神经网络会输出一个当前数据对应于各个类别的置信度分数,将这些分数通过softmax进行归一化处理,最终会得到当前数据属于每个类别的概率。
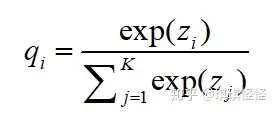
然后计算交叉熵损失函数:
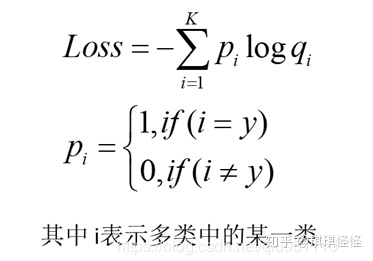
训练神经网络时,最小化预测概率和标签真实概率之间的交叉熵,从而得到最优的预测概率分布。最优的预测概率分布是:
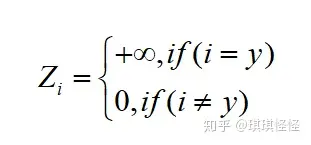
神经网络会促使自身往正确标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有的样本特征的情况下,会导致网络过拟合。
3.2 label smoothing(标签平滑)
label smoothing可以解决上述问题,这是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。

增加label smoothing后真实的概率分布有如下改变:
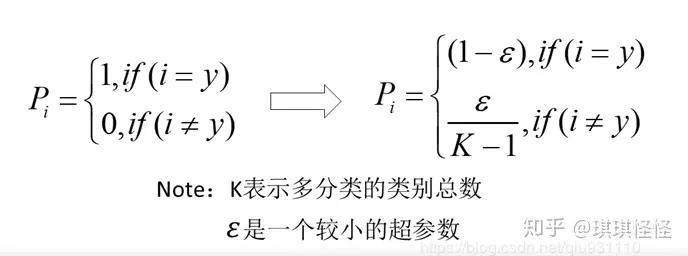
最优预测概率分布如下: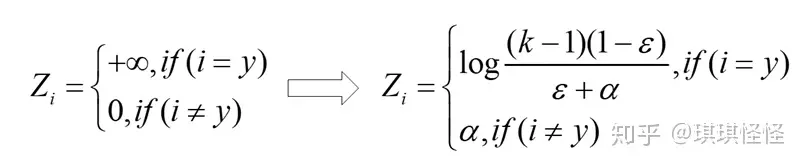
这里的α是任意实数,最终模型通过抑制正负样本输出差值,使得网络有更强的泛化能力。
3.3 代码实现
pytorch实现
"""
标签平滑
可以把真实标签平滑集成在loss函数里面,然后计算loss
也可以直接在loss函数外面执行标签平滑,然后计算散度loss
"""
import torch.nn as nn
import torch
class LabelSmoothingLoss(nn.Module):
"""
标签平滑Loss
"""
def __init__(self, classes, smoothing=0.0, dim=-1):
"""
:param classes: 类别数目
:param smoothing: 平滑系数
:param dim: loss计算平均值的维度
"""
super(LabelSmoothingLoss, self).__init__()
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.cls = classes
self.dim = dim
self.loss = nn.KLDivLoss()
def forward(self, pred, target):
pred = pred.log_softmax(dim=self.dim)
with torch.no_grad():
# true_dist = pred.data.clone()
true_dist = torch.zeros_like(pred)
true_dist.fill_(self.smoothing / (self.cls - 1))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
#torch.mean(torch.sum(-true_dist * pred, dim=self.dim))就是按照公式来计算损失
loss = torch.mean(torch.sum(-true_dist * pred, dim=self.dim))
#采用KLDivLoss来计算
loss = self.loss(pred,true_dist)
return loss《Delving Deep into Label Smoothing》这篇论文就提供了一种在线标签平滑策略方法,使用一种在线学习的方式来生成soft label,相比传统的soft label方法,论文提出的方法声称效提高分类性能和模型的鲁棒性,优于LS、Bootsoft等方法。
import torch
import torch.nn as nn
from torch import Tensor
class OnlineLabelSmoothing(nn.Module):
"""
Implements Online Label Smoothing from paper
https://arxiv.org/pdf/2011.12562.pdf
使用方法
from ols import OnlineLabelSmoothing
criterion = OnlineLabelSmoothing(alpha=..., n_classes=...)
for epoch in range(...): # loop over the dataset multiple times
for i, data in enumerate(...):
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch} finished!')
# Update the soft labels for next epoch
criterion.next_epoch()
criterion.eval()
dev()/test()
"""
def __init__(self, alpha: float, n_classes: int, smoothing: float = 0.1):
"""
:param alpha: Term for balancing soft_loss and hard_loss
:param n_classes: Number of classes of the classification problem
:param smoothing: Smoothing factor to be used during first epoch in soft_loss
"""
super(OnlineLabelSmoothing, self).__init__()
assert 0 <= alpha <= 1, 'Alpha must be in range [0, 1]'
self.a = alpha
self.n_classes = n_classes
# Initialize soft labels with normal LS for first epoch
self.register_buffer('supervise', torch.zeros(n_classes, n_classes))
self.supervise.fill_(smoothing / (n_classes - 1))
self.supervise.fill_diagonal_(1 - smoothing)
# Update matrix is used to supervise next epoch
self.register_buffer('update', torch.zeros_like(self.supervise))
# For normalizing we need a count for each class
self.register_buffer('idx_count', torch.zeros(n_classes))
self.hard_loss = nn.CrossEntropyLoss()
def forward(self, y_h: Tensor, y: Tensor):
# Calculate the final loss
soft_loss = self.soft_loss(y_h, y)
hard_loss = self.hard_loss(y_h, y)
return self.a * hard_loss + (1 - self.a) * soft_loss
def soft_loss(self, y_h: Tensor, y: Tensor):
"""
Calculates the soft loss and calls step
to update `update`.
:param y_h: Predicted logits.
:param y: Ground truth labels.
:return: Calculates the soft loss based on current supervise matrix.
"""
y_h = y_h.log_softmax(dim=-1)
if self.training:
with torch.no_grad():
self.step(y_h.exp(), y)
true_dist = torch.index_select(self.supervise, 1, y).swapaxes(-1, -2)
return torch.mean(torch.sum(-true_dist * y_h, dim=-1))
def step(self, y_h: Tensor, y: Tensor) -> None:
"""
Updates `update` with the probabilities
of the correct predictions and updates `idx_count` counter for
later normalization.
Steps:
1. Calculate correct classified examples.
2. Filter `y_h` based on the correct classified.
3. Add `y_h_f` rows to the `j` (based on y_h_idx) column of `memory`.
4. Keep count of # samples added for each `y_h_idx` column.
5. Average memory by dividing column-wise by result of step (4).
Note on (5): This is done outside this function since we only need to
normalize at the end of the epoch.
"""
# 1. Calculate predicted classes
y_h_idx = y_h.argmax(dim=-1)
# 2. Filter only correct
mask = torch.eq(y_h_idx, y)
y_h_c = y_h[mask]
y_h_idx_c = y_h_idx[mask]
# 3. Add y_h probabilities rows as columns to `memory`
self.update.index_add_(1, y_h_idx_c, y_h_c.swapaxes(-1, -2))
# 4. Update `idx_count`
self.idx_count.index_add_(0, y_h_idx_c, torch.ones_like(y_h_idx_c, dtype=torch.float32))
def next_epoch(self) -> None:
"""
This function should be called at the end of the epoch.
It basically sets the `supervise` matrix to be the `update`
and re-initializes to zero this last matrix and `idx_count`.
"""
# 5. Divide memory by `idx_count` to obtain average (column-wise)
self.idx_count[torch.eq(self.idx_count, 0)] = 1 # Avoid 0 denominator
# Normalize by taking the average
self.update /= self.idx_count
self.idx_count.zero_()
self.supervise = self.update
self.update = self.update.clone().zero_()参考:

















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









