










总结
BLIP2
论文地址:https://arxiv.org/pdf/2301.12597 (https://arxiv.org/pdf/2301.12597)
发布时间:2023.06.15
模型结构:
-
Vision Encoder:ViT-L/14
-
VL Adapter:Q-Former
-
LLM:OPT (decoder-based),FlanT5(encoder-decoder-based)
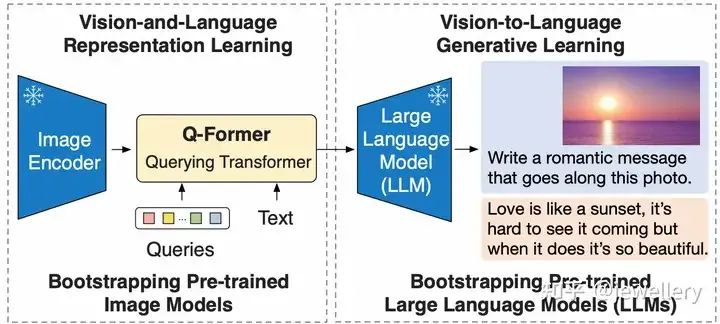
Overview of BLIP-2's framework
论文主要提出Q-Former(Lightweight Querying Transformer)用于连接模态之间的gap。BLIP-2整体架构包括三个模块:视觉编码器、视觉和LLM的Adapter(Q-Former)、LLM。其中Q-Former是BLIP-2模型训练过程中主要更新的参数,视觉Encoder和大语言模型LLM在训练过程中冻结参数。
BLIP-2的预训练包括两个阶段:
Stage 1)Vision-and-Language Representation Learning. Q-Former与冻结的Image Encoder(ViT-L/14)连接,在和文本交互中学习图文相关性表示(3个预训练任务)。
Stage 2)Vision-to-Language Generative Learning. 第一个阶段训练得到的Q-Former的输出接入一个大语言模型,学习视觉到文本生成(1个预训练任务)。
下面分别介绍两个阶段:
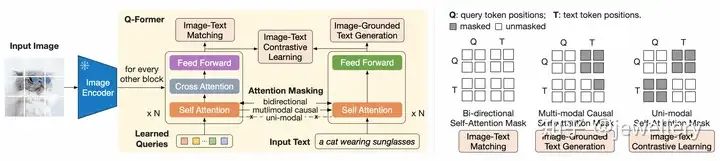
阶段1:左侧为Q-Former的结构以及如何学习视觉文本表征,右侧self-attention masking策略
阶段1:Q-Former的结构如上图所示,包括两个Transformer子模块(共享Self-Attention层),一个image transformer与image encoder交互提取视觉表征(图中黄色区域左侧),一个text transformer既作为text encoder也作为text decoder(图中黄色区域右侧)。首先创建一个可学习的query向量(Learnable query embeddings)作为image transformer的输入,queries通过self-attention层进行自我交互,然后与冻结参数的image features(来自image encoder)通过cross-attention层(插入每隔一个block)进行交互,此外这个query向量还与text通过同一个self-attention进行交互。在不同的预训练任务中,使用不同的self-attention masks来影响查询文本的交互,在这个阶段的预训练中,一共通过三个任务进行学习(类似BLIP),分别为:
ITM:图文匹配任务,使用双向self-attention mask, 不进行掩码,该任务目标是学习细粒度的图文表示对齐。训练过程中queries和text可以完全互相看到,query embeddings的输出Z包含了多模态的信息,将它输入一个2分类linear层得到一个logit,平均来自所有queries的logits作为最终的匹配分数,论文采纳了难负样例挖掘的策略创建更具信息量的负样本对。
ITG:图引导文本生成,使用causal self-attention mask, 由q-former的架构可以看到,冻结的image encoder没有和text tokens直接交互,而生成(generation)所需要的信息必须首先通过queries提取视觉信息以及通过self-attention传给text tokens,因此queries被迫学习抽取可以描述文本信息的视觉特征。论文使用multimodal causal self-attention mask来控制query和text的交互(同UniLM中的使用),queries可以看到自己但看不到text tokens,text tokens可以看到queries以及已经生成的text tokens, 用[DEC] token取代[CLS] token作为第一个text token来指示解码任务的开始。
ITC:图文对比学习,使用单模态self-attention mask, 对text的token全部进行掩码,使得queries和text互相看不到,这个任务对齐的是来自image transformer的query表示和来自text transformer的文本表示([CLS] token)。
在论文实验中,选用两种视觉编码模型 1)CLIP预训练的ViT-L/14. 2)EVA-CLIP预训练的ViT-g/14. 并移除ViT的最后一层,只使用倒数第二层的输出特征(实验中效果更好),与queries交互。Learned Queries侧使用32个query,每个query维度768,q-former输出维度为32*768,这样比冻结的image features维度要小很多(比如对于使用ViT-L/14来说是257*1024),因此第一个阶段主要目标是训练queries可以提取蕴含语义信息的视觉表示。
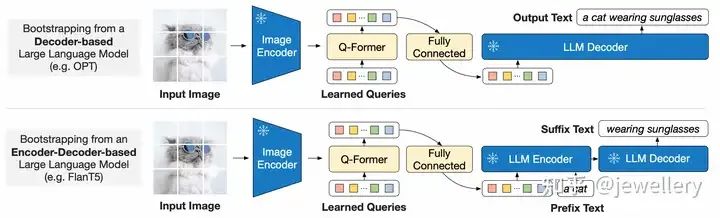
阶段2:从冻结LLM中学习视觉文本生成,两种LLM(上图Decoder-based,下图Encoder-Decoder-based)
阶段2:Q-Former通过一个FC层使得Q-former的输出query embedding Z对齐到与LLM输入同样的维度,并前置于input text embedding一起输入LLM,这种拼接方式有点像软视觉提示(soft visual prompt),q-former在前面预训练任务中已经学到如何抽取蕴含语言信息的视觉表示,该阶段中可以起到把最重要信息输入给LLM同时去除错误没有意义的视觉信息的作用,从而降低LLM学习视觉语言对齐的负担,同时也缓解了灾难遗忘的问题。
论文实验了两种LLM,对于decoder-based LLM,预训练使用language modeling loss. 对于encoder-decoder-based LLM,预训练使用prefix language modeling loss, 将text分成两部分,前一部分与q-former输出拼接一起作为编码器的输入,后面部分作为解码器的生成目标。
InstructBLIP
论文地址:https://arxiv.org/pdf/2305.06500 (https://arxiv.org/pdf/2305.06500)
发布时间:2023.06.15
模型结构:
-
Vision Encoder:ViT-g/14
-
VL Adapter:Q-Former
-
LLM:FlanT5-xl(3B), FlanT5-xxl(11B), Vicuna-7B, Vicuna-13B
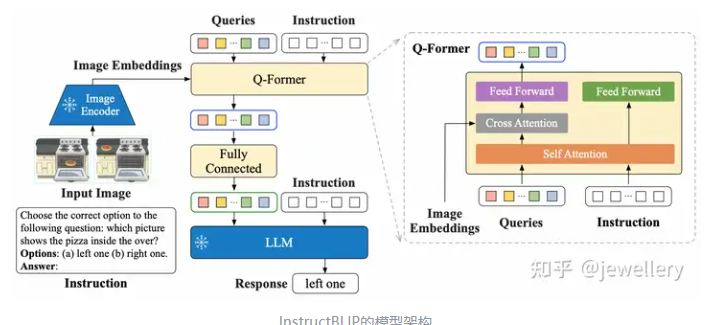
InstructBLIP的模型架构
InstructBLIP的模型结构与BLIP-2类似,区别在于输入文本换成了指令数据Instructions. Q-Former抽取指令感知的视觉特征(Instruction-aware vision model),根据指令的不同获取不同的视觉特征。然后将这些视觉特征作为LLM的软视觉提示(soft prompt),使用language modeling loss和指令微调模型生成回复。
训练过程(Vision-Language Instruction Tuning):3阶段训练以及zero-shot预测
-
Stage 1:预训练,训练Q-Former和Projection Layer,冻结image encoder。使用image caption数据,学习视觉文本相关性表示。
-
Stage 2:预训练,训练Projection Layer,冻结LLM。使用image caption数据,学习对齐LLM的文本生成。
-
Stage 3:指令微调,训练Q-Former和Projection Layer。使用Instruction任务数据,学习遵循指令生成回复的能力。
训练数据:收集11个任务以及相应的26个数据集,如下图所示。对于每个任务,人工编写10-15个自然语言的指令模版,作为构造指令微调数据的基础。对于偏向较短回复的开源数据集,在指令模版中使用’short/briefly’降低模型过拟合为总是生成较短回复(防止过拟合的方式是在指令中有所体现)。
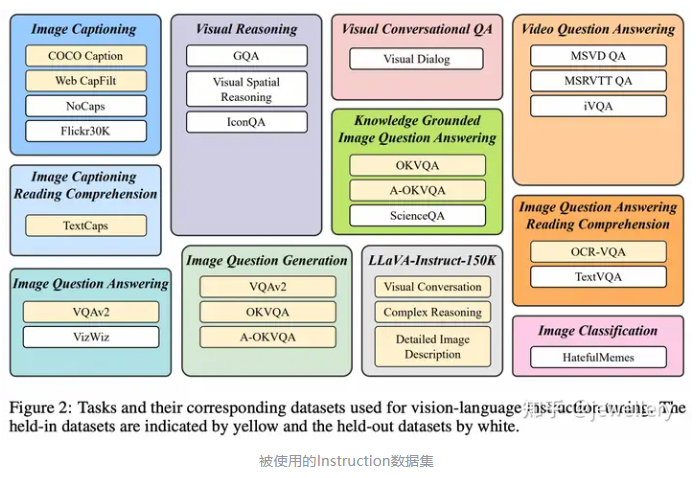
被使用的Instruction数据集
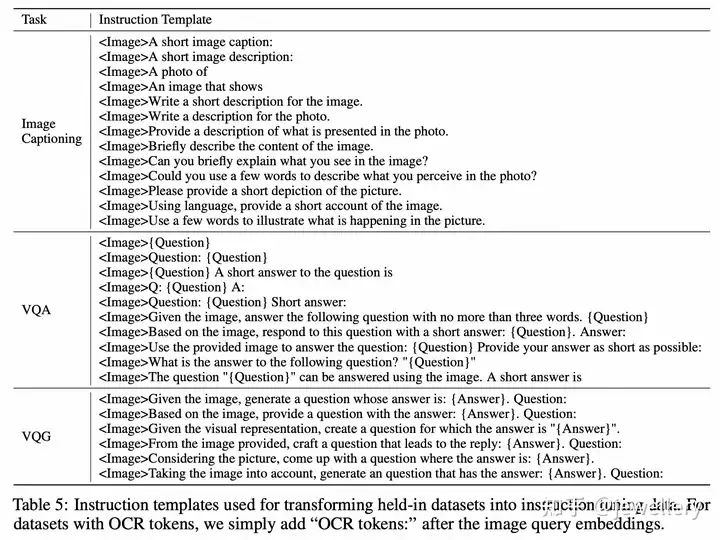
多模态训练数据的指令模版
Qwen-VL
论文地址:https://arxiv.org/pdf/2308.1296 (https://arxiv.org/pdf/2308.12966)
发布时间:2023.10.13
模型结构:
-
Vision Encoder:ViT-bigG/14
-
VL Adapter:a single-layer cross-attention(Q-former的左侧部分)
-
LLM:Qwen-7B
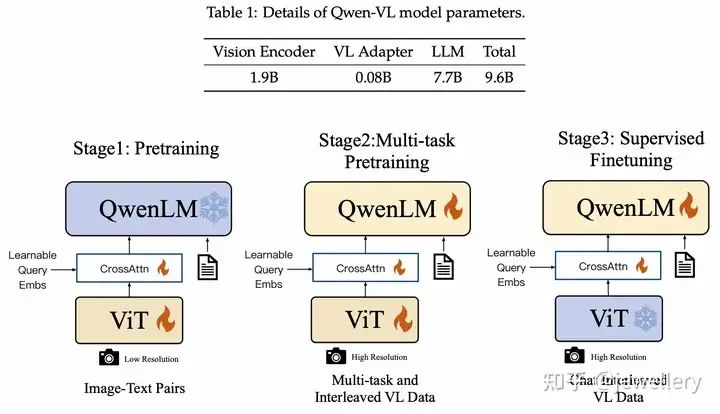
Qwen-VL的训练Pipeline
VL Adapter创建一组可训练的queries向量和image features一起做cross-attention,将视觉特征压缩至256的固定长度,同时为了提升细粒度的视觉理解,在cross-attention中也加入图像的2D绝对位置编码。
Image Input使用特殊token( and )分隔,Bounding Box Input使用特殊token( and )分隔,bounding box的content referred使用特殊token( and )分隔。
训练过程:
Stage 1:预训练,训练Cross-Attention和ViT,冻结QwenLM。
Stage 2:多任务预训练(7 tasks同时),全参数训练。
Stage 3:指令微调,训练Cross-Attention和QwenLM,冻结ViT。
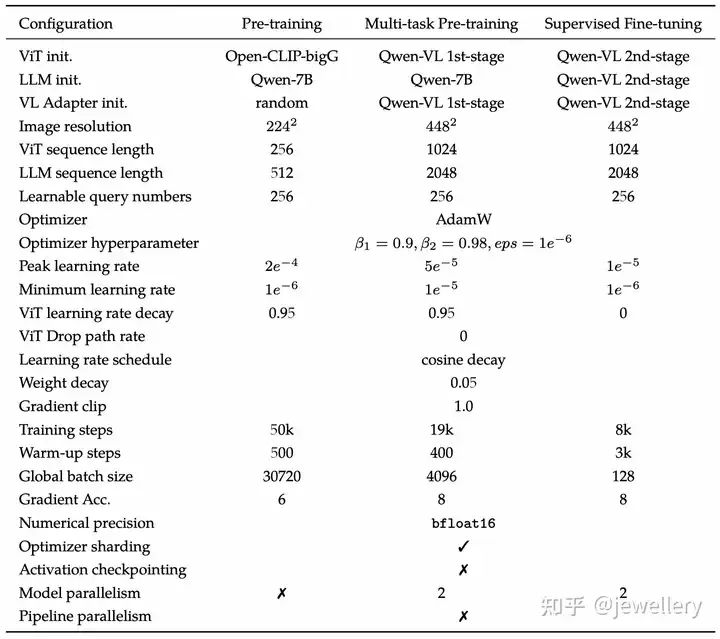
Qwen-VL的训练参数设置
训练数据:
第一个阶段使用image-text pairs数据,77.3%英文、22.7%中文,一共14亿数据训练,图片size=224*224.
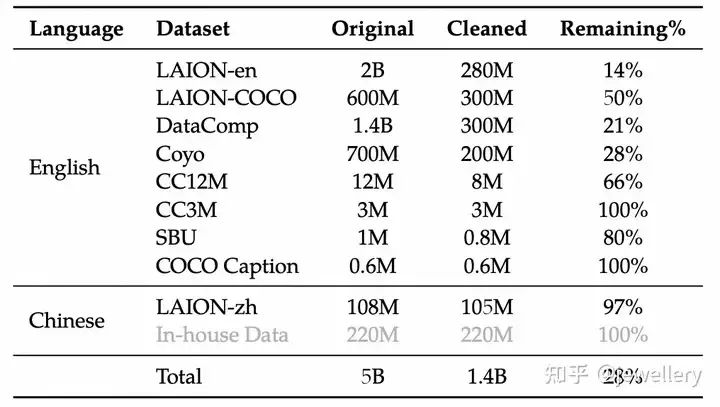
Stage 1 dataset
第二个阶段使用质量更高的image-text pairs数据,包含7个任务,图像size=448*448. 在同一个任务下构造交错图像文本数据,序列长度为2048. 训练目标与Stage1一致。
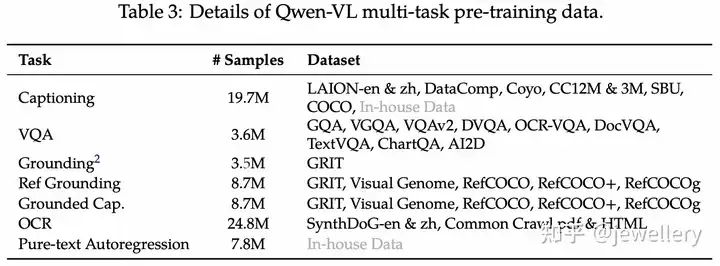
Stage 2 dataset
第三个阶段使用Instruction数据,训练指令遵循和对话能力,通过LLM self-instruction构造,一共350k条。

指令格式
Qwen2-VL
论文地址:https://arxiv.org/pdf/2409.12191 (https://arxiv.org/pdf/2409.12191)
发布时间:2024.09.18
模型结构:
-
Vision Encoder:ViT/14
-
VL Adapter:Cross-Modal Connector
-
LLM:Qwen2-1.5B, Qwen2-7B, Qwen2-72B
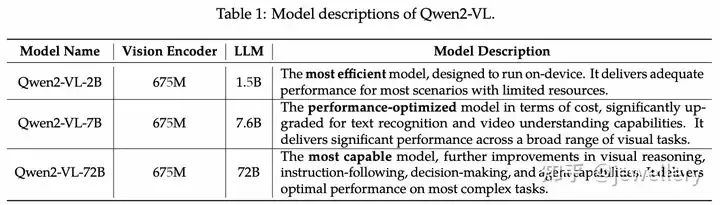
Qwen2-VL模型参数

模型拥有更多的能力
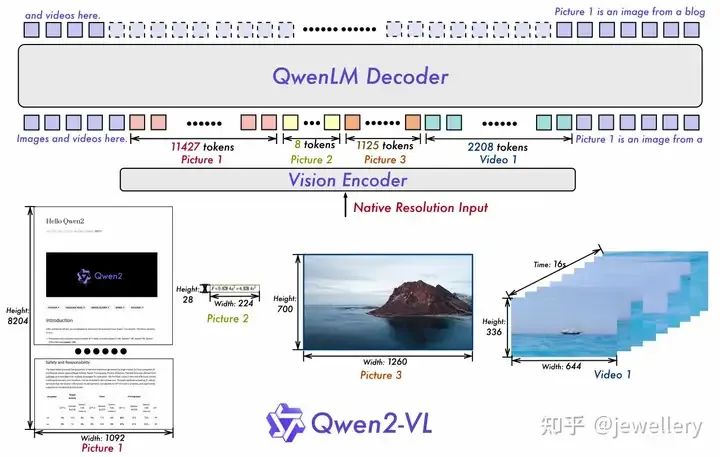
模型架构图,可同时输入不同分辨率、清晰度、纵横比图片
Qwen2-VL相较于Qwen-VL的主要改进点(除了一些VQA等基础能力的提升之外):
1)支持视频理解,支持context上下文长度到128k token(20分钟左右视频)。
2)Visual Agent能力,支持实时视频对话。
3)图像位置编码采用2D-RoPE,一张224*224分辨率的图像经过ViT/patch_size=14等一系列转换之后会被压缩至66个token输入到LLM。
训练过程:
Stage 1:训练ViT,使用大量image-text对。
Stage 2:全参数微调,使用更多的数据提升模型全面理解的能力。
Stage 3:指令微调,训练LLM。
LLaVA
论文地址:https://arxiv.org/pdf/2304.08485 (https://arxiv.org/pdf/2304.08485)
发布时间:2023.12.11
模型结构:
-
Vision Encoder:ViT-L/14
-
VL Adapter:/
-
Projection Layer:a linear layer
-
LLM:LLaMA
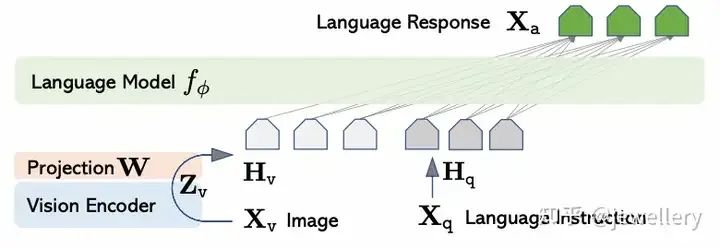
LLaVA模型网络架构
训练过程:
Stage 1:Pre-training for Feature Alignment. 训练Projection Layer
Stage 2:Fine-tuning End-to-End. 训练Projection Layer和LLM
LLaVA-1.5
论文地址:https://arxiv.org/pdf/2310.03744 (https://arxiv.org/pdf/2310.03744)
发布时间:2024.05.15
模型结构:
-
Vision Encoder:Clip预训练 Vit-L/336px
-
VL Adapter:MLP
-
LLM:Vicuna v1.5 13B
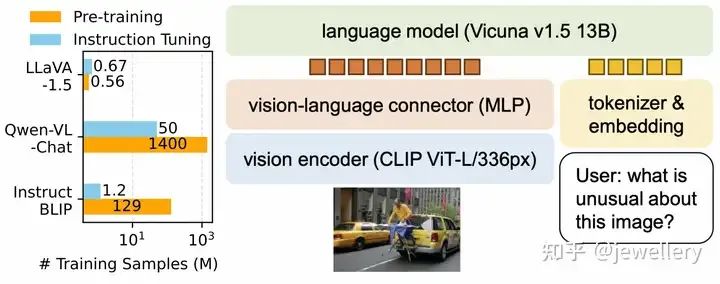
模型结构图
MiniGPT-4
论文地址:https://arxiv.org/pdf/2304.10592(https://arxiv.org/pdf/2304.10592)
发布时间:2023.10.02
模型结构:
-
Vision Encoder:ViT-G/14
-
VL Adapter:Q-Former
-
Projection Layer:a single linear
-
LLM:Vicuna
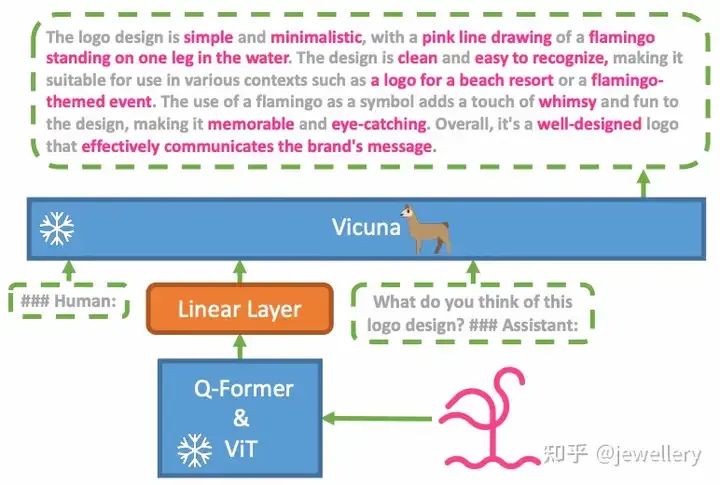
模型结构图
训练过程:
Stage 1:只训练Linear Projection Layer来对齐视觉特征和大语言模型。使用大量text-image pair数据。
Stage 2:指令微调,使用少量高质量text-image instruction数据
指令模板:###Human: <ImageFeature><Instruction>###Assistant:
MiniGPT-v2
论文地址:https://arxiv.org/pdf/2310.09478 (https://arxiv.org/pdf/2310.09478)
发布时间:2023.11.07
模型结构:
-
Vision Encoder:ViT
-
VL Adapter:/
-
Projection Layer:Linear
-
LLM:Llama2-7B
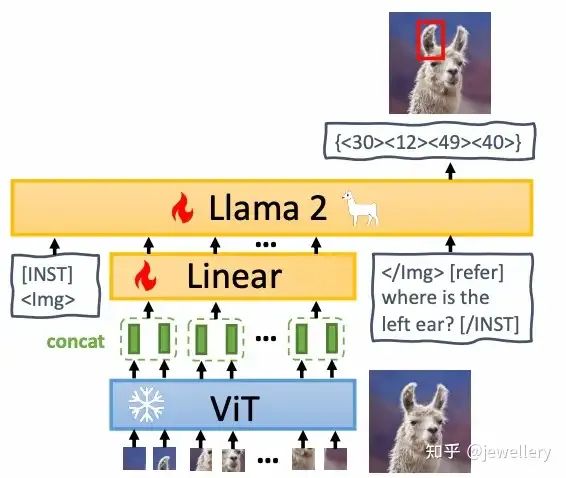
模型结构图
训练过程:
Stage 1:预训练,使用大量弱监督image-text和细粒度数据集的混合数据训练,让模型获取多样化知识
Stage 2:多任务训练,只使用细粒度高质量数据集训练模型在不同任务上的能力。
Stage 3:多模态质量微调,让模型具备Chat哪里
训练数据:

在三个训练阶段中使用的数据集
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









