






一. 引言
上一期我们详细介绍了支持向量机在预测领域的应用,有不少小伙伴对SVM分类模型也很感兴趣,本期,我们将聚焦应用,以简洁易懂的方式拆解 SVM 二分类模型的核心原理以及如何解决类不平衡问题,同时用通俗的语言解析分类模型的关键评估指标,附可复现代码手把手教你搭建完整的 SVC 建模流程,助力竞赛实战!
二.SVM核心思想
支持向量机(Support Vector Machine, SVM)是一种基于结构风险最小化的监督学习算法,其核心目标是寻找一个最优超平面,使得不同类别数据之间的间隔最大化。这个最优超平面可以用简单的线性方程表示: w T x + b = 0 w^T x + b = 0 wTx+b=0
w是法向量,决定了超平面的方向,b是位移项。对于线性可分数据,SVM通过求解以下优化问题找到最大间隔:
min
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
…
,
n
\begin{align*} \min_{w,b} & \quad \frac{1}{2} \|w\|^2 \\ \text{s.t.} & \quad y_i (w^T x_i + b) \geq 1, \quad i = 1, \dots, n \end{align*}
w,bmins.t.21∥w∥2yi(wTxi+b)≥1,i=1,…,n
三.线性决策边界实现
3.1 数据生成与可视化
我们使用make_blobs生成可分离数据集:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=200, centers=2,
random_state=0, cluster_std=0.6)
plt.scatter(X[:,0], X[:,1], c=y, cmap='rainbow', edgecolors='k')
plt.show()
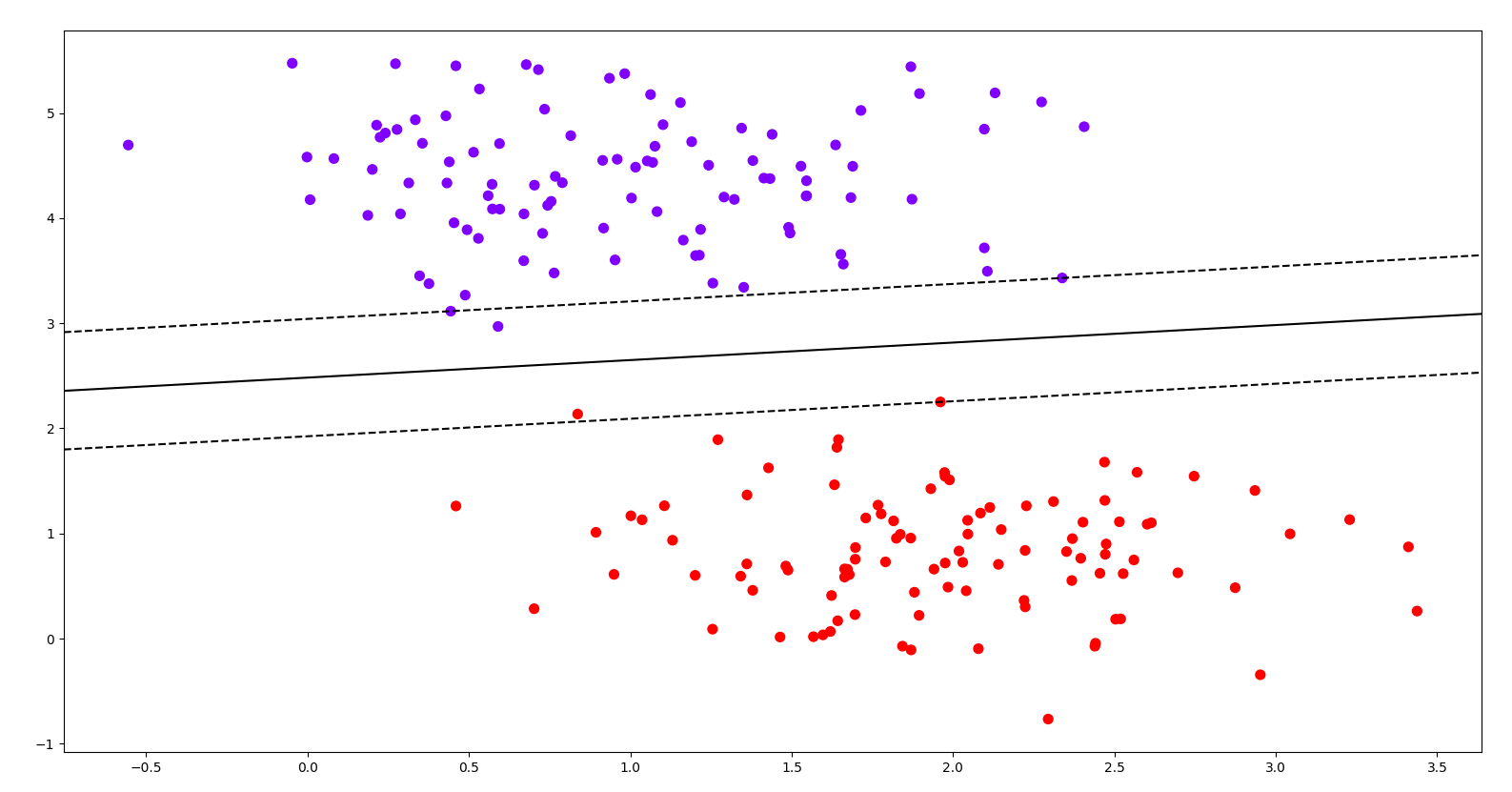
3.2 决策边界绘制
在通过网格点生成与决策函数计算边界时,首先为大家介绍一个关键接口decision_function,它能够返回输入样本到决策边界的距离。但此时得到的距离值是一维形式(仅包含每个样本点的距离数值),而绘图函数 contour 要求用于绘制等高线的数据 Z 必须与网格矩阵 X、Y 的二维结构严格匹配(即形成类似网格的行列对应关系)。因此,需要将一维的距离值转换为二维结构,只有这样 contour 函数才能基于匹配的 X、Y、Z 结构,正确绘制出反映决策边界特征的等高线。
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import precision_score, recall_score
X, y = make_blobs(n_samples=200, centers=2,
random_state=0, cluster_std=0.6)
# plt.scatter(X[:,0], X[:,1], c=y, cmap='rainbow', edgecolors='k')
# plt.show()
def plot_svc_decision_function(model, ax=None):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# 生成网格点
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
# 获取决策值
P = model.decision_function(xy).reshape(X.shape)
# 绘制等高线
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1],
linestyles=['--', '-', '--'])
#训练模型
clf = SVC(kernel='linear').fit(X,y)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap='rainbow')
plot_svc_decision_function(clf)
plt.show()
y_pred = clf.predict(X)
print(f"Precision: {precision_score(y, y_pred):.3f}")
print(f"Recall: {recall_score(y, y_pred):.3f}")
print(f"Specificity: {(y[y==0]==y_pred[y==0]).sum()/(y==0).sum():.3f}")
四. 处理类别不平衡问题
4.1 参数class_weight的作用
当处理数据类别不平衡问题时,可通过设置 类别权重参数 class_weight={1: 10} 调整支持向量机(SVM)的决策边界。其核心思想是为不同类别赋予不同的权重系数:类别 0 的权重为 1 份,类别 1 的权重为 10 份,使模型在训练时更关注少数类(如类别 1)的分类正确性。这一机制的数学原理源于带权重的优化目标函数:
min
w
,
b
1
2
∥
w
∥
2
+
C
∑
i
=
1
n
w
i
ξ
i
\begin{align*} \min_{w,b} \frac{1}{2} \| w \|^2 + C \sum_{i=1}^{n} w_i \xi_i \end{align*}
w,bmin21∥w∥2+Ci=1∑nwiξi
其中
w
i
\ w_i
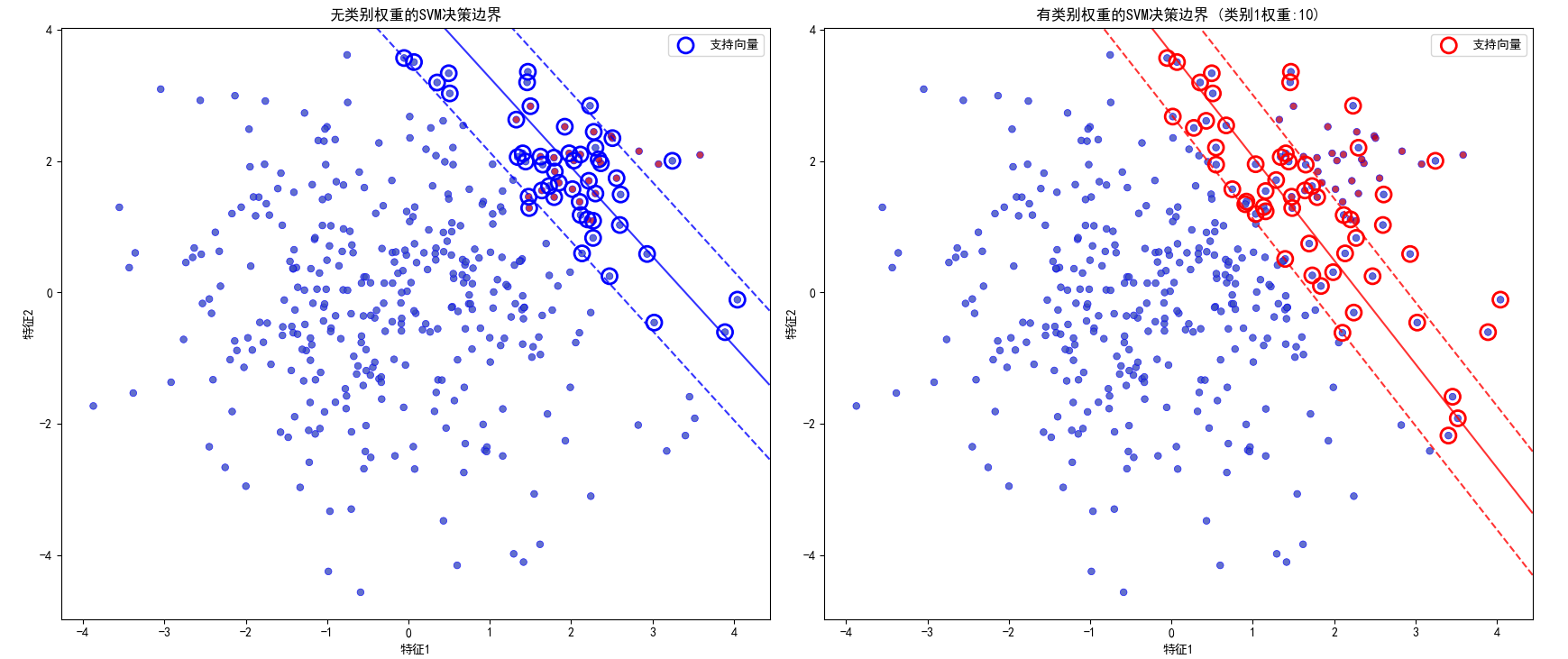
wi是模型复杂度的正则化项,用于控制决策边界的平滑性,C为惩罚系数,平衡正则化项与分类误差的权重。权重的引入使得算法在优化时更关注重要类别的分类正确性从。从可视化结果看:
左侧图(未设置类别权重):模型因受多数类(类别 0)样本主导,决策边界偏向少数类(类别 1),导致少数类样本易被误分类;
右侧图(设置类别权重 class_weight={1: 10}):模型对少数类样本的分类误差惩罚增强,决策边界向多数类方向偏移,显著改善了少数类的分类边界清晰度,使两类样本的划分更合理。
4.2 特别提醒:
需要特别注意的是:在比较未设置类别权重(class_weight)与设置权重的 SVM 模型时,未设置权重的模型往往呈现更高的整体精度,但这一现象具有极强的迷惑性。其本质原因在于:
1.类别不平衡场景下,多数类(如样本量占优的类别 0)主导了整体精度计算,模型即使完全忽略少数类(如类别 1),仅通过正确分类多数类也能获得较高的 “表面精度”,但这会导致少数类的真实分类效果被严重掩盖。
2.当通过class_weight={1: 10}为少数类赋予更高权重时,模型的优化目标从 “盲目追求整体精度” 转向 “平衡两类样本的分类质量”。此时,算法会主动牺牲部分多数类的分类精度,通过增大少数类错分的惩罚力度(如在目标函数中提高其误差项权重),迫使决策边界向多数类偏移,从而显著提升少数类的识别能力。
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 创建不均衡样本数据集
class_1 = 500 # 类别1有500个样本
class_2 = 50 # 类别2有50个样本
centers = [[0.0, 0.0], [2.0, 2.0]] # 设定两个样本的中心
clusters_std = [1.5, 0.5] # 设定两个类别的方差
X, y = make_blobs(n_samples=[class_1, class_2],
centers=centers,
cluster_std=clusters_std,
random_state=0, shuffle=False)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
def plot_svc_decision_function(model, ax=None, plot_support=True, color='k'):
"""绘制SVM决策边界和支持向量"""
if ax is None:
ax = plt.gca()
# 获取坐标轴范围
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# 生成网格点(增加密度使边界更平滑)
x = np.linspace(xlim[0], xlim[1], 300)
y = np.linspace(ylim[0], ylim[1], 300)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
# 计算决策函数值并重塑为网格形状
P = model.decision_function(xy).reshape(X.shape)
# 绘制决策边界和间隔边界
ax.contour(X, Y, P, colors=color,
levels=[-1, 0, 1], alpha=0.8,
linestyles=['--', '-', '--'])
# 绘制支持向量
if plot_support:
ax.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=150, linewidth=2, facecolors='none', edgecolors=color, label='支持向量')
# 训练两个SVM模型: 无权重和有权重
clf = SVC(kernel='linear', random_state=42).fit(X_train, y_train)
wclf = SVC(kernel='linear', class_weight={1: 10}, random_state=42).fit(X_train, y_train)
# 创建1行2列的子图布局
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 第一个子图: 无类别权重模型
ax1.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='coolwarm',
s=30, alpha=0.8, edgecolors='b', linewidths=0.5)
plot_svc_decision_function(clf, ax1, color='blue')
ax1.set_title('无类别权重的SVM决策边界')
ax1.set_xlabel('特征1')
ax1.set_ylabel('特征2')
ax1.legend(loc='upper right')
# 第二个子图: 有类别权重模型
ax2.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='coolwarm',
s=30, alpha=0.8, edgecolors='b', linewidths=0.5)
plot_svc_decision_function(wclf, ax2, color='red')
ax2.set_title('有类别权重的SVM决策边界 (类别1权重:10)')
ax2.set_xlabel('特征1')
ax2.set_ylabel('特征2')
ax2.legend(loc='upper right')
plt.tight_layout()
plt.show()
# 打印详细的分类报告
print("无类别权重模型的分类报告:")
print(classification_report(y_test, clf.predict(X_test), target_names=['类别0', '类别1']))
print("\n有类别权重模型的分类报告:")
print(classification_report(y_test, wclf.predict(X_test), target_names=['类别0', '类别1']))
五. 分类模型评估指标
5.1关键指标
分类任务常用的关键指标有精确度(Precision)、召回率(Recall)、特异度(Specificity)。
为了便于大家理解,以本案例来说明关键指标含义,以蓝色点索引为0,红色点索引为1,利用代码print(y[y==clf.predict(X)])即可得如下图结果:

精确度:所有判断为正确并确实为1的样本 / 所有被判断为1的样本。规范解释为聚焦于模型预测为正例的样本中,真正属于正例的比例,直观反映模型预测正例时的可靠程度。
print((y[y==clf.predict(X)]==1).sum()/(clf.predict(X)==1).sum())
#也可以直接调用函数
print(f"Precision: {precision_score(y, y_pred):.3f}")
召回率:所有判断为正确并确实为1的点 / 全部为1的点。关注实际正例样本中,被模型正确识别为正例的比例,体现模型对正例的整体捕捉能力。
print((y[y==clf.predict(X)]==1).sum()/(y==1).sum())
#也可以直接调用函数
print(f"Recall: {recall_score(y, y_pred):.3f}")
特异度:所有被正确预测为0的样本/所有的0样本。衡量实际负例样本中,被模型正确判定为负例的比例,突出模型对负例的判别精准性。
print((y[y==clf.predict(X)]==0).sum()/(y==0).sum())
#也可以直接调用函数
print(f"Specificity: {(y[y==0]==y_pred[y==0]).sum()/(y==0).sum():.3f}")
5.2 ROC曲线
ROC 曲线是评估分类模型性能的重要工具,通过描绘 ** 真正率(True Positive Rate, TPR,即召回率 Recall)与假正率(False Positive Rate, FPR)** 在不同分类阈值下的关系,直观展现模型对正负样本的区分能力。
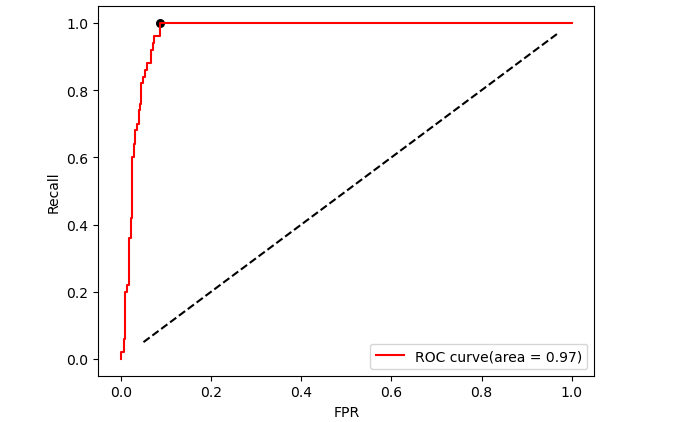
对于凸型ROC曲线来说,曲线越靠近左上角越好,越往下越糟糕,
对于凹形ROC曲线来说,曲线越靠近右下角越好,越往上越糟糕,可通过更改label参数将其反转
六.总结与扩展
本文聚焦支持向量机(SVM)二分类模型,核心思想是通过寻找最优超平面实现分类间隔最大化,其优化目标为在满足分类约束的前提下最小化模型复杂度。文中系统介绍了 SVM 线性决策边界的构建流程,并且针对类别不平衡问题,通过引入class_weight参数为少数类赋予更高权重,调整优化目标以强化对少数类的分类关注 。在实际应用中,可通过学习曲线交叉验证等手段调整正则化参数C,平衡模型复杂度与分类误差,进一步优化性能,同时SVM 天然适用于中小规模数据集与高维特征场景,结合核技巧(如 RBF 核、多项式核)可有效处理非线性分类问题。未来研究方向可探索 SVM 与集成学习、深度学习的融合,进一步拓展其在复杂场景下的泛化能力。
如果文中有任何不足,非常欢迎小伙伴们批评指正,同时,真心希望这篇笔记能为大家带来实际帮助。如果觉得内容对你有用,欢迎点赞关注 —— 你们的每一次鼓励,都是我持续输出优质内容的最强动力源!


















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











