







参考:
- 详解DeepSeek-R1核心强化学习算法:GRPO - 知乎
- 深入解析DeepSeek背后的数学原理:群体相对策略优化(GRPO) - 知乎
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning——技术报告详解 - 知乎
- DeepSeek技术报告解析:为什么DeepSeek-R1 可以用低成本训练出高效的模型 - 知乎
deepseek-r1为什么强:
- 技术架构与算法创新(不恰当的比喻o1是从小接受顶级教育的世家公子,凭借大量的金钱投入成为一个多个领域的顶级学者,deepseek-r1出身寒微,但凭借他的智商和出色的学习能力媲美o1)
- 数据处理能力
deepseek-r1强在哪:
- 逻辑推理和复杂问题解决
- 多领域适应性
- 开源
1.背景
近年来,大型语言模型(LLMs)在推理能力方面取得了显著进展。然而,如何有效提升这些模型的推理能力仍然是一个开放问题。DeepSeek-R1 的研究旨在通过大规模强化学习(RL)直接应用于基础模型,而不需要监督微调(SFT),从而显著提升推理能力。
2. 主要贡献
2.1 Post-Training: 强化学习的应用
- 直接应用 RL:通过大规模强化学习直接应用于基础模型,无需监督微调,显著提升了推理能力。
- 自主探索思维链(CoT):允许模型自主探索解决复杂问题的思维链,开发出 DeepSeek-R1-Zero。
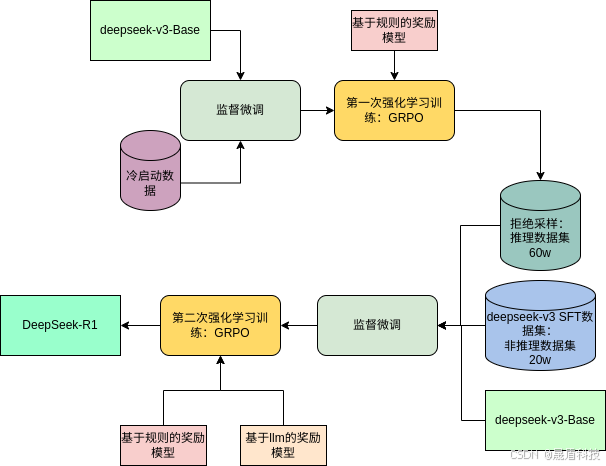
2.2 Pipeline for DeepSeek-R1: 复杂的训练管道
- 两个 RL 阶段和两个 SFT 阶段:引入了一个包含两个 RL 阶段和两个 SFT 阶段的管道,旨在发现改进的推理模式并符合人类偏好。
- 冷启动数据:通过收集少量高质量的冷启动数据来微调基础模型,以避免 RL 训练初期的不稳定阶段。
2.3 Distillation: 知识蒸馏技术
- 知识蒸馏:展示了较大的模型可以将推理模式提炼到较小的模型中,使得这些小模型的表现优于通过 RL 在小模型上发现的推理模式。
3. 核心算法:Group Relative Policy Optimization (GRPO)
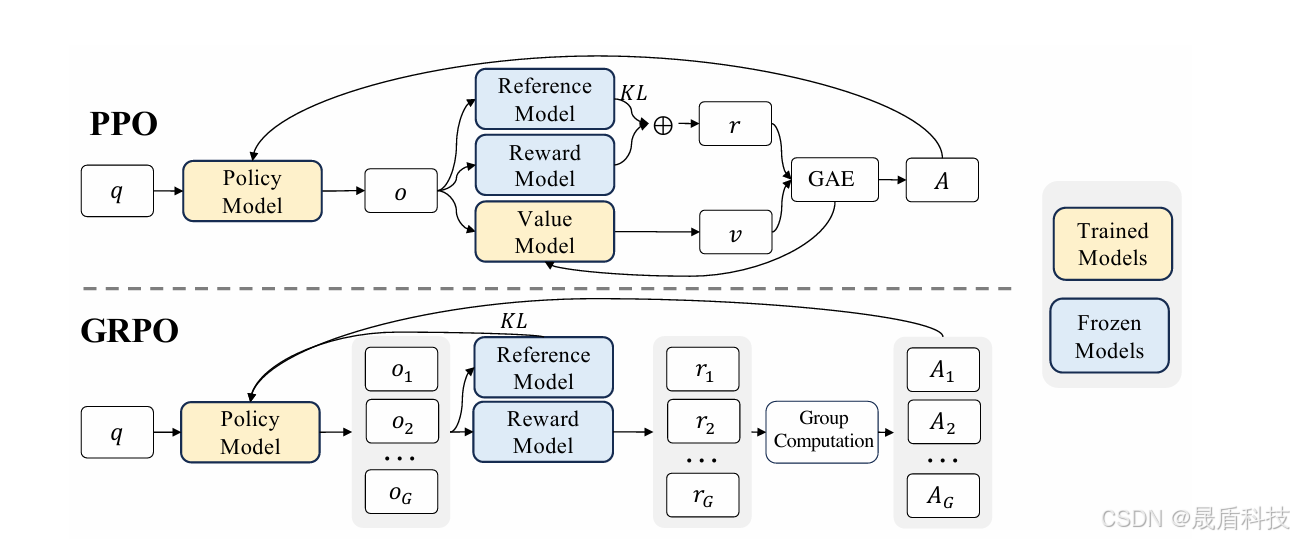
3.1 GRPO 基础
- 相对策略优化:GRPO 是一种专门用于增强 LLMs 推理能力的强化学习算法。它通过评估一组回答之间的相对表现来优化模型,而不是依赖外部评价者(如批评者模型)。
- 无批评者优化:消除了对批评者模型的需求,显著降低了计算开销。
3.2 GRPO 如何应对挑战
- 相对评估:利用组内动态来评估每个回答在同一批次中的相对表现,简化了奖励估计流程。
- 高效训练:专注于组内优势,使 GRPO 对大型模型的训练更快且更具可扩展性。
3.3 核心思想
- 相对评估:对于每个输入查询,模型生成一组潜在回答,并根据每个回答在组中的相对表现进行评分。
- 推动模型发展:通过在组内引入竞争,GRPO 推动模型不断提升其推理能力。
4. 实验验证
4.1 DeepSeek-R1 Evaluation
- 推理任务:DeepSeek-R1 在多项推理任务上表现出色,如 AIME 2024、MATH-500 等,性能接近或超过 OpenAI-o1 系列模型。
- 知识基准测试:在 MMLU、MMLU-Pro、GPQA Diamond 等知识基准测试中表现优异,明显优于 DeepSeek-V3。
4.2 Distilled Model Evaluation
- 小型密集模型:通过对提炼出的小型密集模型进行评估,证明了它们在推理任务中的优秀表现。
5. 讨论与未来工作
5.1 Distillation v.s. Reinforcement Learning
- 比较提炼和 RL:探讨了两种方法的效果,各自的优势和局限性。
5.2 Unsuccessful Attempts
- 未成功的尝试:讨论了一些未成功的尝试及其原因,为未来的研究提供了参考。
5.3 结论与未来方向
- 总结主要成果:总结了研究的主要成果,讨论了当前模型的局限性,并提出了未来可能的研究方向。
关键内容总结
- 核心贡献:
- 纯强化学习(RL)提升推理能力:通过纯强化学习显著提升了大型语言模型(LLMs)的推理能力,特别是在没有监督微调的情况下。
- 自主探索思维链:允许模型自主探索解决复杂问题的思维链,开发出 DeepSeek-R1-Zero。
- 主要方法:
- DeepSeek-R1-Zero:直接应用 RL 于基础模型,不依赖监督微调。
- DeepSeek-R1:引入冷启动数据后应用 RL,重点在于提升推理密集型任务的能力。
- 实验验证:
- 多任务表现优异:展示了在多个推理任务和基准测试中的卓越表现,特别是与 OpenAI-o1 系列模型相比。
- 知识蒸馏技术:成功地将大模型的推理能力提炼到小型模型中,使其在推理任务中表现出色。
- 提炼技术:
- 知识蒸馏:通过从 DeepSeek-R1 提炼出推理能力,应用到较小的密集模型中,展示其在多个基准测试中的出色表现。

















 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









