







Prompt Engineering领域迭代是真的快啊,还是得看最新的文章
Synthetic Prompting: Generating Chain-of-Thought Demonstrations for Large Language Models
arxiv链接
Shao Z, Gong Y, Shen Y, et al. Synthetic prompting: Generating chain-of-thought demonstrations for large language models[J]. arXiv preprint arXiv:2302.00618, 2023.
核心思想:主要是一种demo生成方法,用少量的手写reasoning examples作为种子,借助LLM生成更多且有质量的reasoning examples,用这些生成的examples提高LLM在reasoning任务上的表现。

整个流程分为两步,forward和backward。
backward如上图左侧所示,输入首先包含一系列demo(图中为了节省空间只给了一个,实际上是多个),每个demo主要包括一个instruction(表明该任务是根据某个top来生成一个Python代码形式的推理过程)、target complexity(整个推理有几步)、topic、代码形式的reasoning chainsolution()以及和solution配套的一个自然语言描述的question。而LLM的任务是根据同样的instruction生成另一个topic,相应target complexity的reasoning chain和question。注意在backward过程中生成的reasoning chain并不会作为“答案”,作者表示这里的reasoning chain只是为了让LLM生成可以回答、定义良好的问题(We find that this approach leads to more answerable and well-defined questions, compared to directly generating questions without a reasoning chain. )。注意topic也是LLM生成的,指令是List 50 noun words. Each word should contain one token only. Do not repeat words already listed.
第二步,forward过程同样需要一些demo,该demo的结构就是question+solution,其中solution也是用Python代码的形式描述的,这是一种叫做PaL(Promgram-aimed Language models)style的reasoning风格,更有利于LLM做reasoing,整个推理过程由代码表示,而推理结果通过运行代码得到。将demo和backward生成的question一起输入LLM,就可以得到一个reasoning solution。对于一个question,先得到n个answers,运行所有answers得到答案,如果超过一半的答案是一样的,则说明LLM是confident,从这些答案里面采纳一个最短的。否则说明LLM不confident,说明这个问题出的不好,LLM没有办法得到confident reasoning。
生成阶段讲完就是推理阶段了。推理阶段有一些神奇的结论
- selecting demonstrations based on complexity can improve the performance of the model on reasoning tasks, compared to selecting them based on similarity. 基于复杂度选demo比基于相似度选demo更有利于提升reasoning性能。
- Moreover, selecting demonstrations based on similarity may introduce biases (Zhang et al., 2022b; Lyu et al., 2022) from the demonstrations, especially if they are incorrect. 基于相似度选demo有可能会导致bias,特别是demo有错误的时候。
- Furthermore, selecting demonstrations that are complementary to each other may help the model fuse knowledge from different types of reasoning. 选择互补的demo能让LLM更好地融合不同类型的知识。
所以,在选取推理阶段需要的demo时,作者使用了他们自己提出in-cluster complexity based
scheme来选取demo。首先将所有demo用Sentence-BERT encode成embedding,然后在embedding空间中进行聚类,推理时需要几个demo就聚几个类(在后续实验中是选出了8个,但few-shot任务只输入2-4个),聚类完成后在每个类里面选出最复杂的(即需要的推理步数最多的)作为demo。后面的推理过程则跟PaL prompting没区别。
在几个Reasoning测试数据集上Synthetic Prompting都展现出较好的表现,由于之前的SOTA PaL。
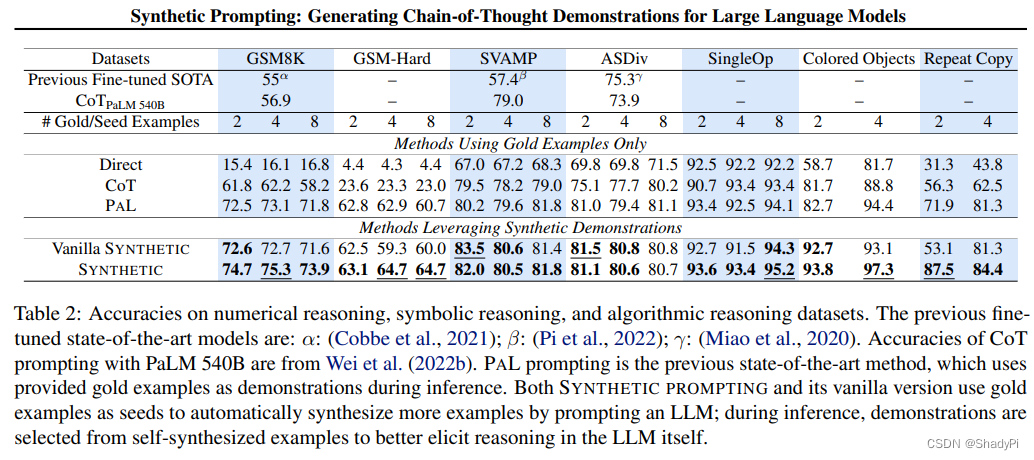
且有消融实验证明,Topic Word, Target Complexity和Reasoning Chain都是有用的。而样例选取从多样性和复杂度两个方面出发也获得了最好的效果。















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











