






答案
CLIP(Contrastive Language-Image Pre-training)和BLIP(Bootstrapping Language-Image Pre-training)是两种重要的多模态视觉-语言预训练模型,它们在架构、训练方式和应用场景上存在显著区别。
模型架构
- CLIP:采用双编码器结构,分别对图像和文本进行编码。通过计算图像和文本编码之间的相似度来实现视觉与语言的对齐。其核心思想是通过对比学习来最大化正确图文对的相似度,同时最小化错误图文对的相似度 。
- BLIP:采用编码器-解码器架构,能够生成图像描述。BLIP不仅包括图像和文本编码器,还引入了解码器,使其能够生成文本描述。这种结构使得BLIP在处理视觉问答(VQA)和图像描述生成等任务时表现更好 。
预训练方式
- CLIP:使用大量从互联网爬取的图文对数据进行预训练,主要依赖于对比学习。这种方法虽然数据量大,但由于数据的多样性和噪声,可能影响模型的泛化能力 。
- BLIP:在CLIP的基础上,引入了字幕生成和过滤模块(CapFilt),用于生成和过滤高质量的图文对数据,从而降低噪声。BLIP通过这种方式获得的数据量较小但质量更高,使得其在特定任务中的表现更佳 。
应用场景
- CLIP:适用于图像分类、图像检索等任务,具有强大的零样本学习能力,可以在未见过的类别上进行分类。然而,CLIP在生成新颖输出(如图像描述)方面能力有限,主要依赖于给定的标签 .
- BLIP:除了图像-文本对齐外,BLIP还能够生成描述,并在视觉问答等任务中表现出色。它特别适合需要生成具体文本输出的应用,如自动生成图片描述或回答与图片相关的问题 。
优劣比较
| 特性 | CLIP | BLIP |
|---|---|---|
| 架构 | 双编码器结构 | 编码器-解码器结构 |
| 预训练方式 | 对比学习,数据量大但噪声多 | 引入高质量数据生成与过滤机制 |
| 主要应用 | 图像分类、检索、零样本学习 | 图像描述生成、视觉问答 |
| 优势 | 强大的跨模态匹配能力 | 更好的文本生成能力 |
| 劣势 | 无法生成复杂文本输出 | 训练过程可能较慢 |
总结而言,CLIP擅长于处理大规模数据并进行快速匹配,而BLIP则在理解和生成方面更为出色。选择使用哪种模型应根据具体应用需求而定。
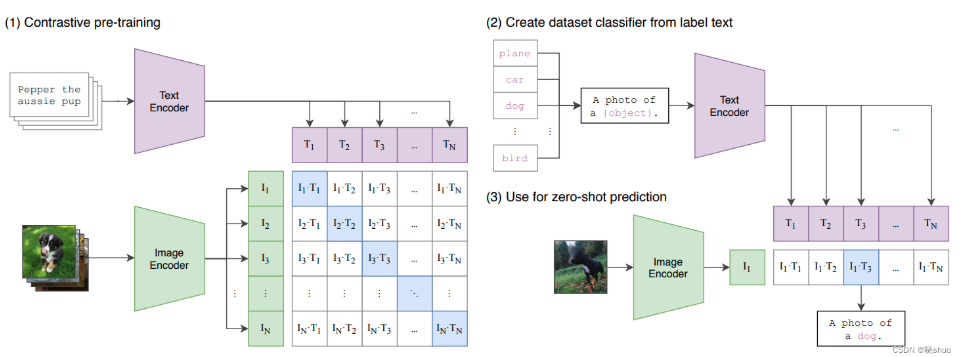
在 CLIP 中,提到的“对角矩阵”通常是指在一批图像和文本对中,图像和文本的相似度矩阵的对角线部分。这对应于图像和其正确文本对的相似度值。
以下是如何构造和求解这个相似度对角矩阵的详细过程:
1. 相似度矩阵的构造
假设我们有一个批次(batch)大小为 N 的图像和文本对,分别记为:
- 图像集合:{I₁, I₂, ..., Iₙ}
- 文本集合:{T₁, T₂, ..., Tₙ}
CLIP 会计算所有图像和所有文本之间的相似度,构成一个 N × N 的相似度矩阵 S。
相似度矩阵 S 的元素定义为:
![]()
Sij=f(Ii)′⋅g(Tj)′S_{ij} = f(I_i)' \cdot g(T_j)'Sij=f(Ii)′⋅g(Tj)′
其中:

- f(Ii)′f(I_i)':图像 I₁ 的归一化嵌入向量。
- g(Tj)′g(T_j)':文本 T₁ 的归一化嵌入向量。
- ⋅\cdot⋅:向量的点积操作。
因此,矩阵 SSS 的每一行表示一个图像与所有文本的相似度,每一列表示一个文本与所有图像的相似度。
2. 对角线元素
相似度矩阵的对角线元素 SiiS_{ii}Sii 表示第 i 个图像与第 i 个文本的相似度(即正确的图文对的相似度)。对角线矩阵可以表示为:
diag(S)={S11,S22,…,SNN}\text{diag}(S) = \{S_{11}, S_{22}, \dots, S_{NN}\}diag(S)={S11,S22,…,SNN}
这些对角线元素是对比学习中被最大化的目标,因为它们对应于正确的图文对。
3. 如何使用对角矩阵
在对比学习中,CLIP 的损失函数会对对角线元素进行操作。以下是关键步骤:
(1) Softmax 归一化
对于每一行(或列),CLIP 使用 softmax 归一化来将相似度转换为概率分布。例如:
对于第 iii 行(图像为查询):
Pimage(Ti∣Ii)=exp(Sii/τ)∑j=1Nexp(Sij/τ)P_{\text{image}}(T_i | I_i) = \frac{\exp(S_{ii} / \tau)}{\sum_{j=1}^N \exp(S_{ij} / \tau)}Pimage(Ti∣Ii)=∑j=1Nexp(Sij/τ)exp(Sii/τ)
这里:
- SiiS_{ii}Sii 是对角线上的元素。
- SijS_{ij}Sij 是第 iii 个图像和所有文本的相似度。
- τ\tauτ 是温度参数。
对于第 iii 列(文本为查询):
Ptext(Ii∣Ti)=exp(Sii/τ)∑j=1Nexp(Sji/τ)P_{\text{text}}(I_i | T_i) = \frac{\exp(S_{ii} / \tau)}{\sum_{j=1}^N \exp(S_{ji} / \tau)}Ptext(Ii∣Ti)=∑j=1Nexp(Sji/τ)exp(Sii/τ)
(2) 对比损失(InfoNCE)
对角线元素被用来定义对比学习损失,如下:
对于图像为查询的损失:
Liimage=−logexp(Sii/τ)∑j=1Nexp(Sij/τ)\mathcal{L}_i^{\text{image}} = -\log \frac{\exp(S_{ii} / \tau)}{\sum_{j=1}^N \exp(S_{ij} / \tau)}Liimage=−log∑j=1Nexp(Sij/τ)exp(Sii/τ)
对于文本为查询的损失:
Litext=−logexp(Sii/τ)∑j=1Nexp(Sji/τ)\mathcal{L}_i^{\text{text}} = -\log \frac{\exp(S_{ii} / \tau)}{\sum_{j=1}^N \exp(S_{ji} / \tau)}Litext=−log∑j=1Nexp(Sji/τ)exp(Sii/τ)
最终的损失是两者的平均值:
L=12N∑i=1N(Liimage+Litext)\mathcal{L} = \frac{1}{2N} \sum_{i=1}^N \left( \mathcal{L}_i^{\text{image}} + \mathcal{L}_i^{\text{text}} \right)L=2N1i=1∑N(Liimage+Litext)
4. 对角矩阵的实现
在代码中,计算相似度对角线可以非常简单地实现。以下是伪代码的示例:
python
运行复制
import torch
# 假设 image_features 和 text_features 是图像和文本的归一化嵌入向量
# 它们的形状均为 [N, D],其中 N 是批大小,D 是嵌入向量的维度
image_features = ...
text_features = ...
# 计算相似度矩阵 S
similarity_matrix = torch.matmul(image_features, text_features.T) # [N, N]
# 提取对角线元素(正确的图文对相似度)
diag_elements = similarity_matrix.diag() # [N]
# 计算对比学习的损失
tau = 0.07 # 温度参数
logits_per_image = similarity_matrix / tau
logits_per_text = similarity_matrix.T / tau
labels = torch.arange(len(image_features)).to(image_features.device) # 正确对的索引
# CrossEntropyLoss 自动对 logits 进行 softmax
loss_image = torch.nn.CrossEntropyLoss()(logits_per_image, labels)
loss_text = torch.nn.CrossEntropyLoss()(logits_per_text, labels)
# 总损失
loss = (loss_image + loss_text) / 2
5. 总结
- 相似度矩阵的对角线元素 SiiS_{ii}Sii 表示正确图文对的相似度。
- CLIP 的目标是通过对比学习最大化这些对角线上的相似度,同时最小化其他位置(错误图文对)的相似度。
- 通过 softmax 和交叉熵损失,CLIP 将对角线上的相似度转化为概率,并优化模型以提升这些概率。
这种方法使得 CLIP 能够高效地学习图像和文本之间的语义对齐关系。
CLIP(Contrastive Language-Image Pre-training)和BLIP(Bootstrapping Language-Image Pre-training)是两种先进的多模态模型,旨在连接计算机视觉与自然语言处理领域。它们在架构、训练方式以及应用场景上存在显著差异。
架构与核心思想
CLIP采用双编码器结构,分别对图像和文本进行编码,通过对比学习最大化正确图文对的相似度,最小化错误图文对的相似度,以学习视觉-语言对齐。其核心思想是通过对比学习将图像和文本映射到一个共享的嵌入空间中,进行匹配与分类。
BLIP则结合了对比学习、生成任务和图文匹配,通过自引导学习提高生成能力。它包含图像编码器、文本编码器、视觉文本编码器和视觉文本解码器,支持生成任务。BLIP的核心思想在于通过多任务预训练和自引导机制,能够更高效地学习图像与文本之间的关系。
训练方式与数据处理
CLIP依赖于大规模图像-文本配对数据进行训练,这些数据通常来源于互联网上的爬取数据,尽管数据量大但噪声较多。CLIP的训练主要基于对比学习,通过计算两个嵌入向量的余弦相似度来判断匹配程度。
BLIP则引入了多任务学习框架,包括对比学习、图文匹配、图像到文本生成等任务,并采用CapFilt技术去除噪声数据,提高模型性能。BLIP的训练方式更加灵活,能够处理更复杂的视觉和语言结合任务,如图像描述生成和视觉问答。
应用场景与优势
CLIP擅长于图像分类、搜索和检索任务,尤其适用于开放领域图像分类和跨模态检索任务,在大规模数据集下表现出色。此外,CLIP在零样本学习任务中也取得了显著成果,能够有效地将图像和文本相互转换和匹配。
BLIP则在图像描述生成、视觉问答和图文检索等任务中表现优异。它通过多任务学习框架,增强了模型在多模态任务中的表现能力,特别是在需要自然语言生成的任务中。BLIP还展示了在低数据或无监督情况下仍能有效训练的能力。
局限性
CLIP在复杂的多模态任务(如图像描述生成)中存在局限性,尤其是在生成类任务中表现不佳。此外,CLIP的架构虽然简洁高效,但在某些复杂的场景生成文本质量上可能不够精确。
BLIP虽然在生成类任务和低数据场景中表现优异,但在复杂的场景生成文本质量上可能不精确,且存在过拟合、数据偏见和计算资源需求等风险。
总结
CLIP和BLIP各有优势和局限性。用户可以根据具体需求选择合适的模型:如果需要处理大规模零样本图像分类和检索任务,CLIP是一个合适的选择;而如果需要进行复杂的图像描述生成或视觉问答任务,则BLIP可能更适合。两者在不同应用场景中各有优势,用户应根据具体需求进行选择。
整理表格:
模型名称、核心思想、模型架构、训练方式、应用场景、优势、局限性
分享研究追问
相关事件
| 事件名称 | 事件时间 | 事件概述 |
|---|---|---|
| CLIP与BLIP在多模态模型中的应用 | 2024-10-09 | 技术发展CLIP和BLIP是两种强大的多模态模型,分别侧重于图像和文本的对齐以及视觉与语言的深度集成。 |
| 文本到图像模型中的隐性刻板印象检测 | 未明确 | 研究发现通过比较CLIP和BLIP在不同子集分类任务中的表现,发现BLIP在大多数任务中表现更优,但存在对特定群体的误分类问题。 |
| Midjourney的刻板印象问题 | 未明确 | 研究发现Midjourney在生成图像时存在严重的刻板印象问题,尽管其生成质量高,但仍未能避免这些偏见。 |
| 多模态大模型的架构与训练挑战 | 2024-03-24 | 技术挑战在生成动画方面,现有的个性化T2I模型面临挑战,需要进一步优化以提高图像质量。 |
| CLIP的社会影响分析 | 未明确 | 社会影响CLIP在视觉语义嵌入空间中的应用揭示了AI领域的偏见问题,包括对特定群体的歧视。 |
相关组织
| 组织名称 | 概述 |
|---|---|
| OpenAI | 科技/人工智能OpenAI是一家专注于人工智能研究和开发的公司,开发了CLIP和BLIP等多模态模型。 |
| Salesforce团队 | 科技/软件Salesforce团队在多模态模型方面有贡献,特别是在BLIP2的架构设计上。 |
| PaddleMIX | 科技/人工智能PaddleMIX是一个基于飞桨的多模态大模型开发套件,支持多种跨模态任务。 |
来源
1. PDF
2. PDF
3. PDF
4.
[2024-11-28]5. PDF
6.
[2024-10-09]7.
[2024-11-12]8.
[2024-09-24]9.
[2021]10.
[2024-04-03]11.
[2024-09-11]12.
LLM大模型: blip2/blip3多模态大模型原理. Salesforce团队.
[2024-10-21]13.
多模态过渡态模型的探索与应用. 图科学实验室Graph Science Lab.
[2024-08-25]14.
[2024-03-12]15.
深度学习中的教师-学生模型与多模态模型应用. YungJZ.
[2024-10-24]16. PDF
LANGUAGE AGENTS FOR DETECTING IMPLICIT STEREOTYPES IN TEXT-TO-IMAGE MODELS AT SCALE
17. PDF
Digital Scholarship in the Humanities
[2022-12-31]18.
[2024-04-09]19.
[2024-08-28]20.
[2024-08-28]21.
[2024-03-24]22.
23.
[2024-02-04]24. PDF
Markedness in Visual Semantic AI. Robert Wolfe et al.
25.
[2024-09-29]26. PDF
27.
[2024-10-04]28. PDF
TYPEOriginal Research
[2023-10-29]29.
刘杰,乔文昇,朱佩佩等.基于图像-文本大模型CLIP微调的零样本参考图像分割 附视频[J].计算机应用研究,2024.
30. PDF
Tracking the Temporal-Evolution of Supernova Bubbles in Numerical Simulation. University of Groningen.

















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









