








论文代码:https://github.com/icey-zhang/SuperYOLO
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.1. Object Detection With Multimodal Data
2.3.2. Super Resolution in Object Detection
2.6.5. Comparisons With Previous Methods
2.6.6. Generalization to Single Modal Remote Sensing Images
2.7. Conclusion and Future Work
1. 心得
(1)自从上次TPAMI把脑子看爆之后又回到了轻松愉悦的频道,人还是不能太勉强自己。我真的是生理上的脑过载红温了
(2)依然很多title,我也好想要个title,Sherlily, Member, Joker
(3)每次看OD的论文实验都是从消融开始,hhh
2. 论文逐段精读
2.1. Abstract
①Challenges in smalll object detection: accuracy and timeliness
②Existing problem: heavy computing costs
2.2. Introduction
①Detection task under different modalities:
2.3. Related Work
2.3.1. Object Detection With Multimodal Data
①Lists possible modalities: RGB, synthetic aperture radar (SAR), Light Detection and Ranging (LiDAR), IR, panchromatic (PAN), and multispectral (MS)
②Fusion strategy: they choose pixel-level fusion methods of pixel-level fusion, feature-level fusion, and decision-level fusion methods to reduce computational cost
aperture n.光圈;(尤指摄影机等的光圈)孔径;小孔;缝隙
2.3.2. Super Resolution in Object Detection
①Lists other data augmentation methods and points out their assisted SR module
2.4. Baseline Architecture
①Backbone of YOLOv5 aims to extract low-level texture and high-level semantic features
②Overall framework of SuperYOLO:
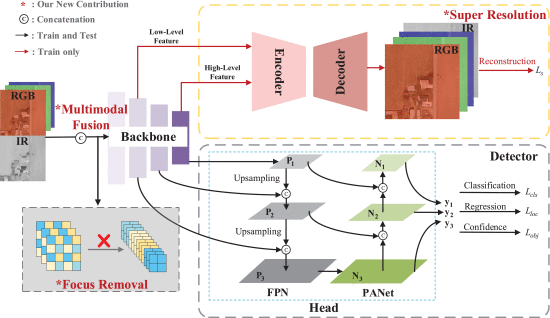
where removed Focus operation is for reducing computational cost
③Backbone of YOLOv5:
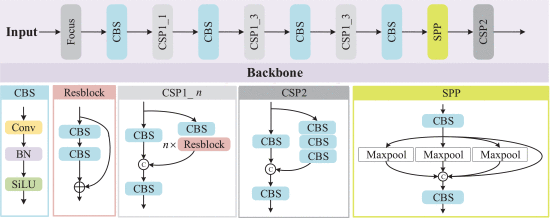
where deep convs cause a sharp reduction in feature map size and loss of small object information
2.5. SuperYOLO Architecture
2.5.1. Focus Removal
①Multimodal fusion (MF) module:
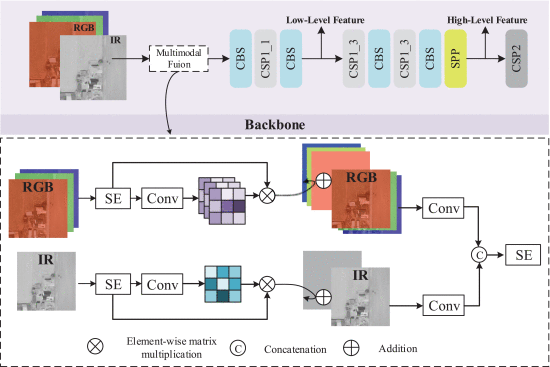
2.5.2. Multimodal Fusion
①Both are downsampled to
by SE and further combine to
by the whole MF:
②我再次忍不住思考,CNN中的公式到底有什么意义,还不如看图来得直观。因此我打算忽略MF的公式(可能是为了严谨吧,不过y=conv(x)无论怎么看都是少儿读物)
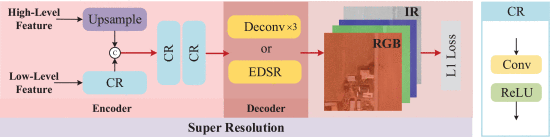
2.5.3. Super Resolution
①SR module:
②Backbone feature of YOLOv5s, YOLOv5x, and SuperYOLO:
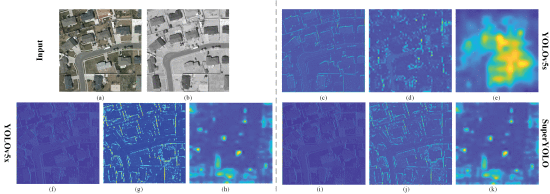
where the 3 feature maps are, features in the first layer, low-level feature and high level feature
2.5.4. Loss Function
①Total loss:
where denotes detection loss and
denotes SR construction loss,
and
are weights
②SR construction loss: L1 loss:
③Detection loss:
2.6. Experimental Results
2.6.1. Dataset
①Dataset: Vehicle Detection in Aerial Imagery (VEDAI)
②Pixels in each image: 1024*1024 or 512*512
③Original image from Utah Automated Geographic Reference Center (AGRC): 16000*16000 pixels with 12.5cm * 12.5cm per pixel
④Modality: RGB and IR
⑤Sample: 1246
⑥Class: 11 cars
2.6.2. Implementation Details
①Cross validation: 10 fold for comparison and the 1st one for ablation
②Data split: 1089 for train, 121 for test
③Categories: , except for classes which instance number is less than 50
④Optimizer: stochastic gradient descent (SGD)
⑤Momentum: 0.937
⑥Weight decay: 0.0005
⑦Batch size: 2
⑧Learning rate: 0.01
⑨Epoch: 300
2.6.3. Accuracy Metrics
①Lists used metrics
2.6.4. Ablation Study
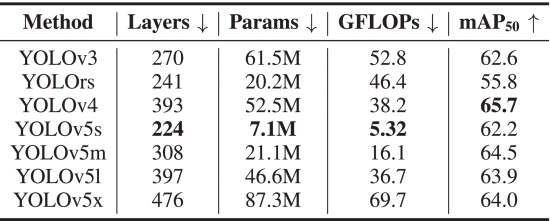
①Choose of baseline:
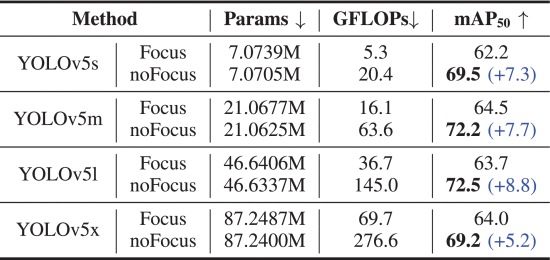
②Focus:
③Fusuin methods ablation:

where fusion1, fusion2, fusion3, and fusion4 represent the concatenation fusion operation performed in the first, second, third, and fourth blocks
④Different fusion methods:
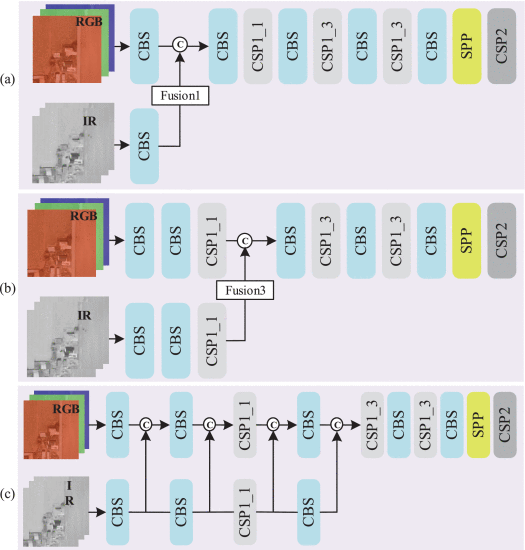
where (a) and (b) Feature-level fusion. (c) Multistage feature-level fusion
⑤Resolution ablation:
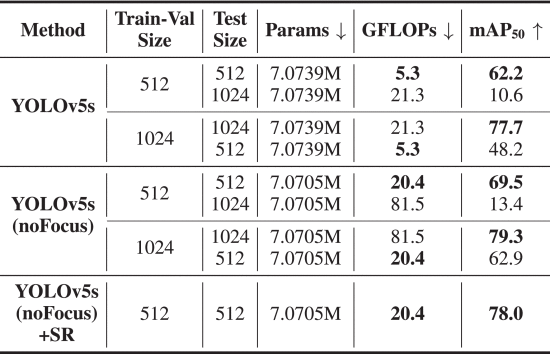
⑥Module ablation:

⑦SR ablation:
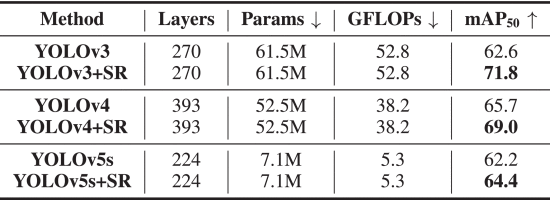
2.6.5. Comparisons With Previous Methods
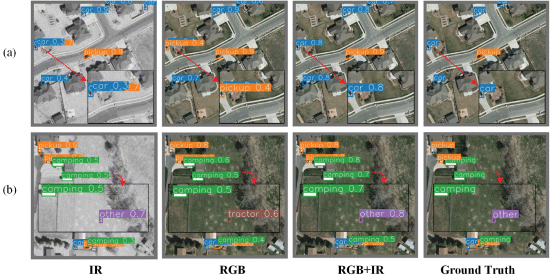
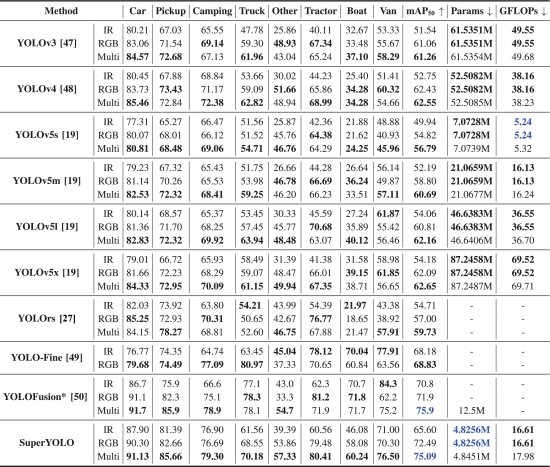
①Vis of results:

where red cycles represent the false alarms, the yellow ones denote the FP detection results, and the blue ones are FN detection results
②Comparison table:
2.6.6. Generalization to Single Modal Remote Sensing Images
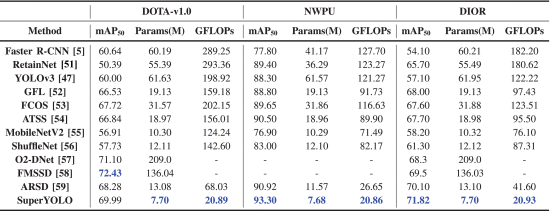
①Generalize to DOTA, NWPU VHR-10 and DIOR:
2.7. Conclusion and Future Work
~
3. Reference
Zhang, J. et al. (2023) SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery, IEEE Transactions on Geoscience and Remote Sensing, 61. doi: 10.1109/TGRS.2023.3258666

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









