






目前,AI 交互辅助的智慧教育已成为提升学习效率和教学质量的关键推动力。语言的学习不仅是获取知识的手段,也满足了人们日益增长的沟通需求,更是连接世界、理解不同文化的桥梁。
在应用层面,人们可以通过众多APP进行语言学习。用户可以学习目标语言的发音、文字甚至拼音,同时语音识别功能还能够识别用户的发音并判断发音是否准确。用户根据自身的薄弱环节有针对性的设定学习任务,极大的提升了学习乐趣和效率。

图片来自duolinguo公众号
在技术层面,目前的文本交互模型如ChatGPT,语音交互模型如whisper、wavLM、wav2vec2.0,这些模型对于英文、中文等主流语言的识别能力已经十分优秀,小编测试了一下他们在方言方面的识别能力:
Round 1 - 上海话 大挑战 :小编首先让ChatGPT翻译了一段上海话的读音,ChatGPT把“路浪厢”翻译成了地名,但在上海话里,其实就是“在路上”的意思。识别结果:识别失败

Round 2 - 武汉话 大挑战
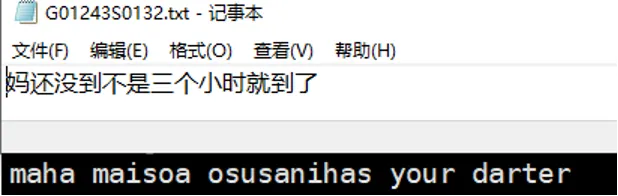
小编接着调用wavLM模型,对武汉话进行识别,上面是真实抄本,下方是识别结果,可见wavLM对武汉话不太擅长。识别结果:识别失败
虽然这些模型在标准语音和主流语言的识别与处理上表现出色,但在面对方言时的表现仍有待提升。由于训练数据集中包含的方言语料相对较少,导致模型在理解和处理非标准语音时能力受限。
01 如何利用高质量平行语料库
能够提升大模型识别能力的优质数据语料库,应包含大量方言语音数据及其准确的标准语言文字翻译。高质量的平行语料库能够有助于解决以下问题:
1. 增加数据多样性和覆盖度:扩充训练集中的方言和地方话数据,提高模型对非主流语言的理解能力和泛化能力。
2. 提高识别准确度:提供准确的方言语音与标准语言文字的对应关系,使模型能够学习特定表达和用法,更准确地识别和翻译方言。
3. 优化模型训练:使用方言语料进行监督学习和微调,进一步优化模型性能。
4. 增强模型的文化敏感性:包含地方特色和文化元素的方言语料,提高模型的文化敏感性和适应性。
5. 使用适配器技术:将现有预训练模型自适应到特定方言和领域,增强模型对方言理解和应用的能力,无需重新训练整个模型。
02 如何获得高质量语音平行语料
海天瑞声高质量语音平行语料包含了多种语言及其对应翻译的语音和文本数据,覆盖多语种和方言,满足全球化语言学习需求,为不同文化背景的学习者提供便利。
- 高准确性:每条语音记录都包含准确的文本翻译,确保学习者获得正确反馈
- 多样性和全面性:包含多种场景和不同语言,满足不同学习需求,广泛应用于各种学习环境。
在智慧教育领域,通过高质量的ASR平行语料数据研发团队能够更好的提升平台算法能力,以更加科学和精准的方式评估学习者的语言学习进展,提供个性化的反馈和指导。更进一步,能够更好的促进教育资源的均衡分配,让不同地区和背景的用户获得高质量的语言学习资源。

















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









