






本教程是一个系列,带你玩转国内的各大模型:Qwen、GLM,实践各种技术包括全参微调、Lora微调、Agent、RAG等。
目录
完整代码如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
代码详解
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
1.首先引入是的transformer库,transformers库是由huggingface所提供的一系列工具,包含了自然语言、计算机视觉、音频等领域,有transformers库的支持能大大降低我们开发的难度和复杂性。
2.我们从transformers库里面导入两个类,第一个是AutoModelForCausalLM,关于因果模型的自动类(Auto Classes),AutoModelForCausalLM是继承于Auto Classes,Auto Classes是transformers提供的一些列方便开发人员配置的类。
3.因果模型是诸如像ChatGPT一类模型,简单来说他是有上一个词预测下一个词的模型,必须有了上一次词(因)才能生成下一个词(果)然后引入的是另一个自动类AutoTokenizer,他也是继承于(Auto Classes),这是关于分词的一个类,我们输入自然语言例如“今天天气很好”,AutoTokenizer会把自然语言转化为数字,这样才能输入到模型中。
4.cuda可以简单理解为gpu(显卡)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
1.我们根据AutoModelForCausalLM的from_pretrained方法加载Qwen2,Qwen2是通义千问团队已经预先训练好的模型了,我们直接拿来用,所以叫预训练模型,我们直接from_pretrained就能加载他。 torch_dtype是选择加载的数据精度,类似于是int型还是float型,大语言模型在推理的时候我们常用的有float16,这里我们选择Auto就行。
2.device_map是选择放到那个设备上,是cpu还是gpu,gpu这里使用cuda表示,cuda是nvidia推出的并行架构,NVIDIA的cuda生态完整,发展很多年了,现在跑Ai大部分都是用NVIDIA,这也就是为什么NVIDIA股票大涨的原因。
3.同样的我们加载预训练好的分词(tokenizer) ,这样我们就有了一个模型(model) 一个分词器(tokenizer),分词器把自然语言如“今天天气很好”转化为数字 然后输入到模型,模型然后生成回答。 加载模型需要一些时间因为足足有7个G
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
定义一个字符串prompt,也是就是我们所说的提示词,读prompt不是promote!!!
messages是模板 这个在后面会对比的
apply_chat_template会把prompt和messages组合起来,我们可以打印一下text 3
model_inputs = tokenizer([text], return_tensors="pt").to(device)
使用tokenizer把text全部变成模型所能处理的数字 1 ,return_tensors参数表示要返回的数据类型,我们选择返回pytorch的tensor简称pt,关于tensor的解释可以看下图,就是就是一堆立方体的数字,
.to(device)的意思是把tokenizer返回的一堆立方体数字放到device上,device指的是cuda或者cpu,在代码开头已经定义好了device = “cuda”
在文章开头也说了cuda可以简单理解为gpu
model_inputs就是我得到的数据,这个数据是text的数字表示,这个数据格式为tensor,且放在了GPU上。
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
激动人心的时候到了,我们开始生成(generate)字了,这里讲快一点,然后在下面集中解释。
generate的一个参数是model_inputs.input_ids 也就是刚才model_inputs的一个属性。
max_new_tokens表面模型输出最大长度为512。
generated_ids是我们生成的字,这些字也是由数字表示。
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
我们把关键部分取出来。
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
然后再把数字转化为自然语言。
response就是我们得到的东西了
运行代码
没有云GPU的可以进以下网站注册,新用户白嫖70块,链接: GPU
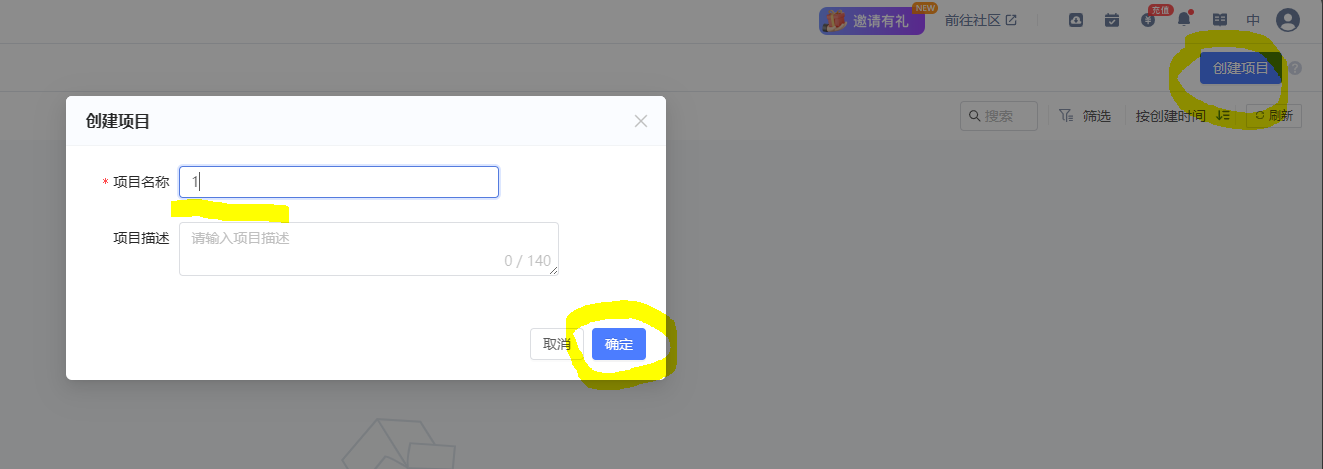
注册好了直接点击右上角创建项目,然后输入项目名字。
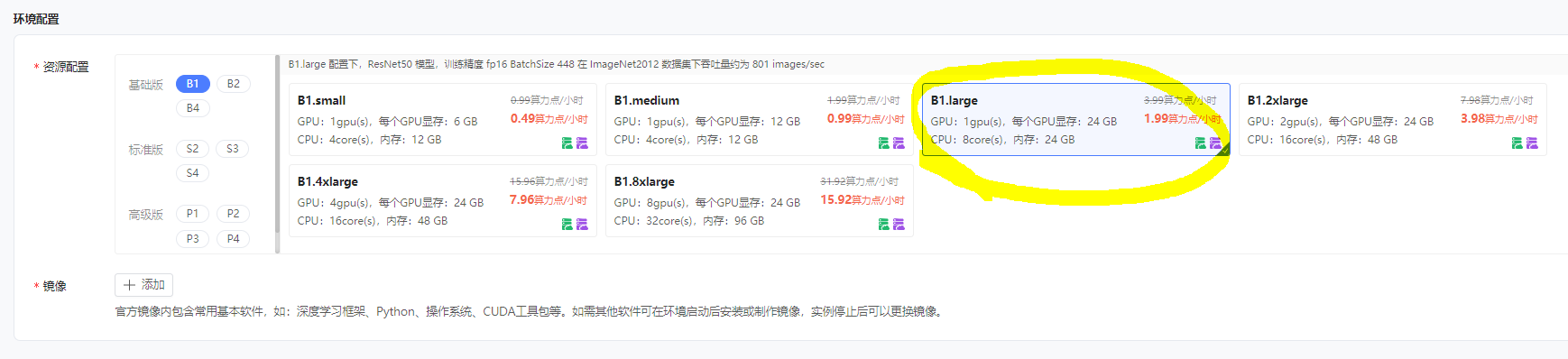
配置资源
选择配置资源为B1.large
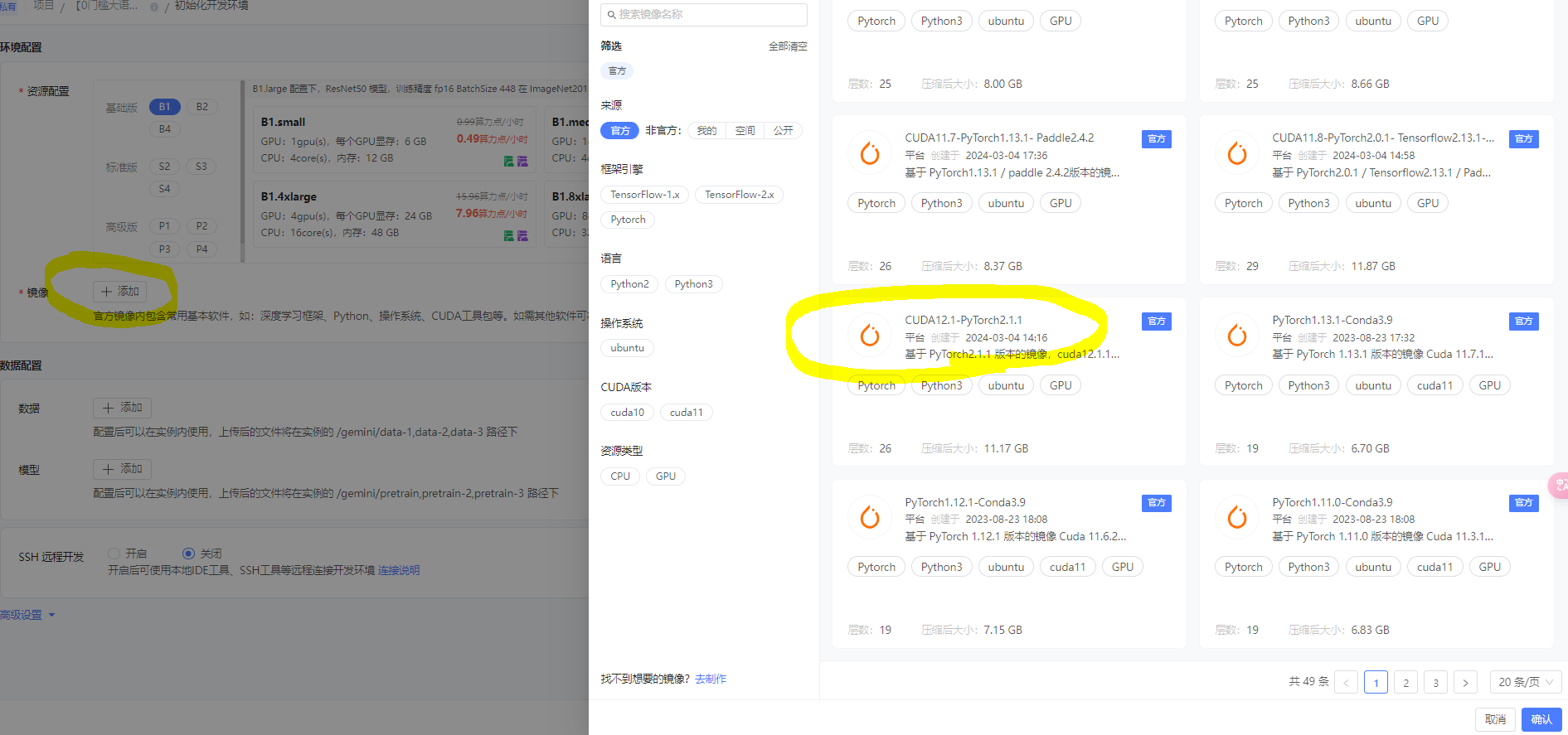
镜像
选择镜像为 CUDA12.1-PyTorch2.1.1 在第一页的倒数第二行,然后点击确认。
数据
暂时不用
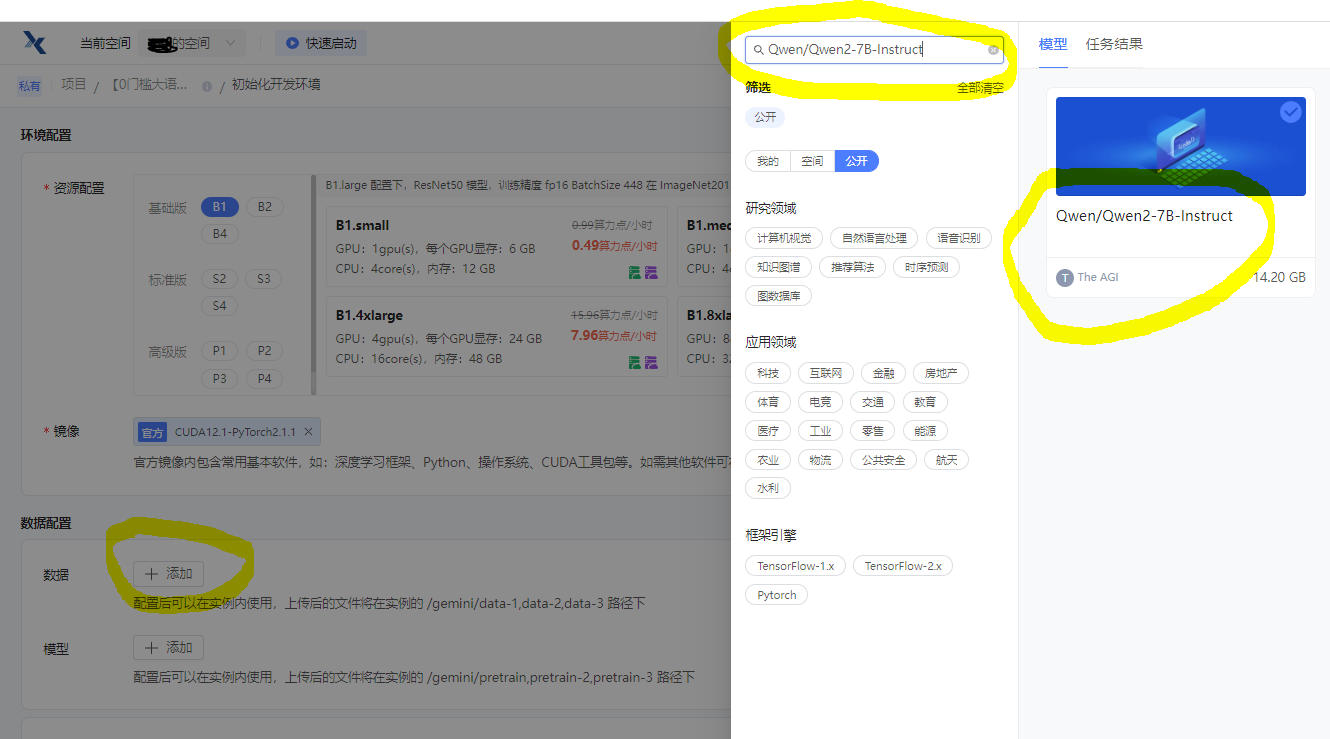
模型
选择云上已经下载好了的模型,点击公开,然后搜索Qwen/Qwen2-7B-Instruct,选择好了点右下角确认。
所有的配置好了如下图,然后点击立即启动。
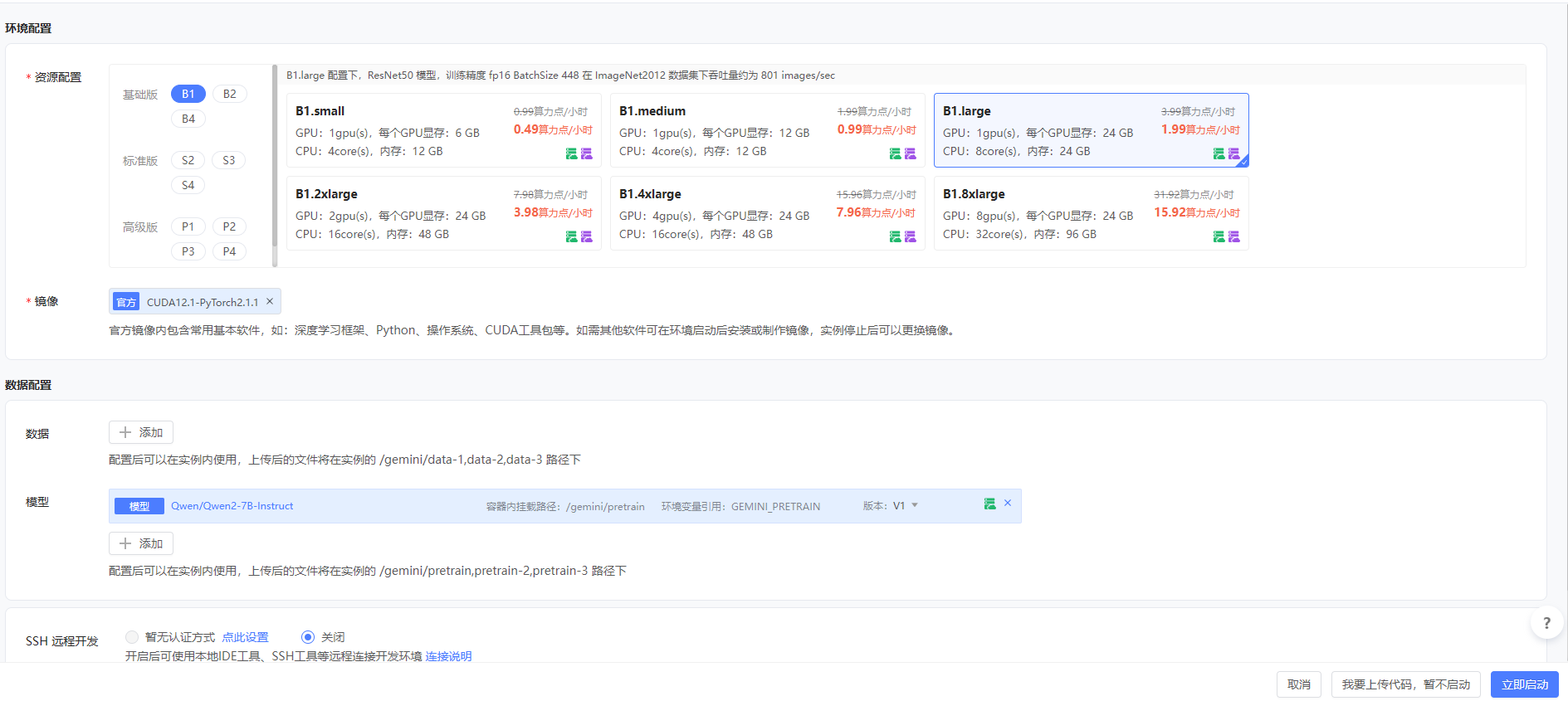
请看右边正在分配资源,我们马上就能拥有一块GPU了
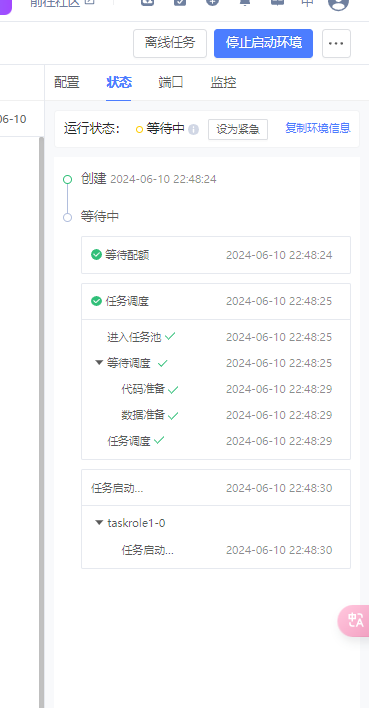
点击进入开发环境我们正式开始开发了
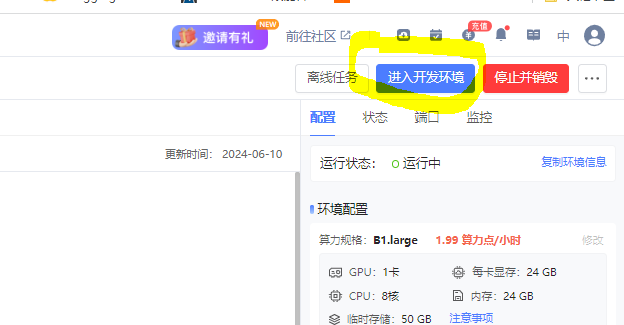
我们新建一个Notebook,点击下图所示:
首先粘贴如下代码:
# 先升级一下环境
!pip install --upgrade pip
!pip install --upgrade datasets torchx
!pip install --upgrade transformers
然后鼠标发到黄色位置,再新建一个cell

再新建一个cell,粘贴以下代码。
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"/gemini/pretrain/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("/gemini/pretrain/Qwen2-7B-Instruct")
# 上面代码运行一次就够了,如果需要修改prompt,重新生成结果的话,复制下面代码粘贴到新的cell上运行
再新建一个cell,粘贴以下代码。
prompt = "端午节有些什么习俗?"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
一共就有3个cell
点击第一个cell然后点击上面的播放按钮运行第一个cell,
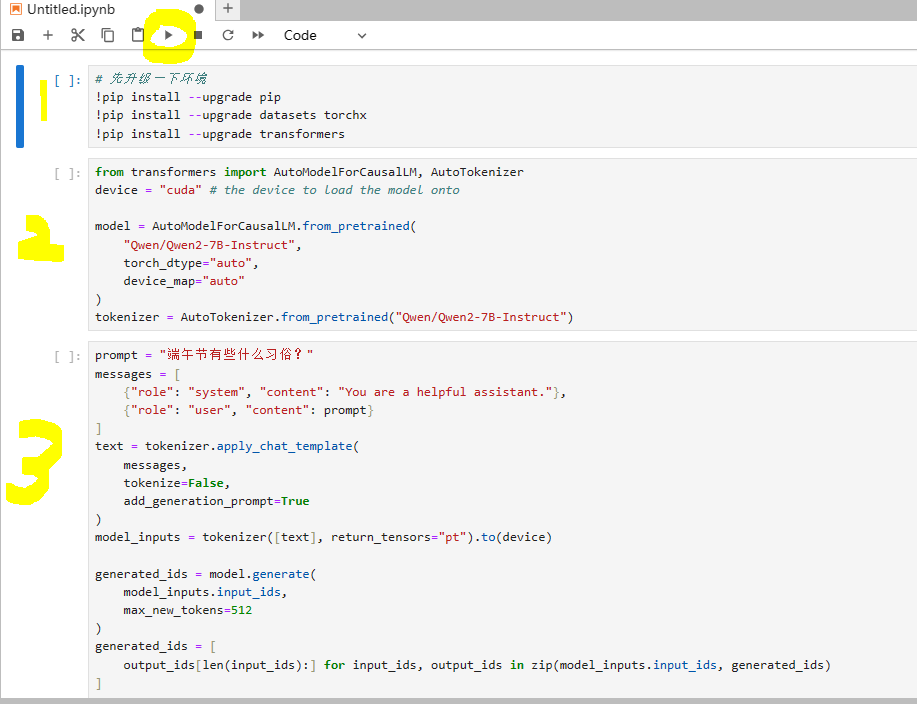
这个圆圈深色表示cell还在运行
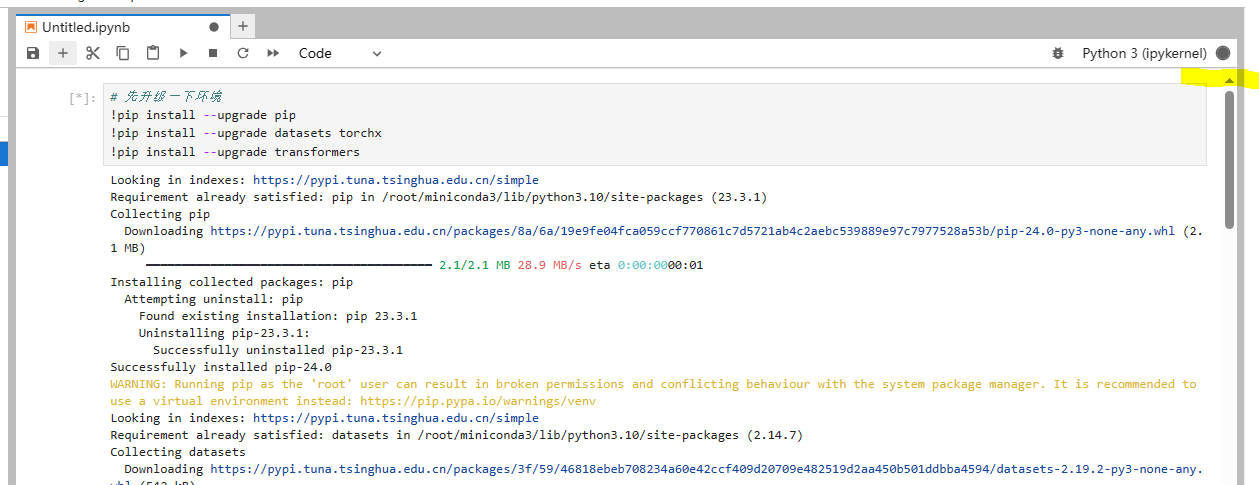
同样点击第二个cell,点击运行,这一步可能要加载1-2分钟
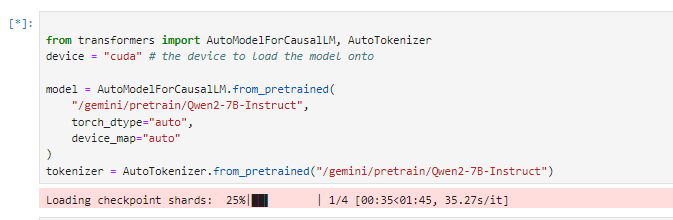
接下来运行第三个cell,就得到结果了,更改prompt后只需要运行第三个cell,因为模型都加载进去了不需要二次加载。
不用了GPU了一定要点 停止并销毁 不然GPU一直在运行。















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









