






这篇文章介绍了一种名为 YOLOE(YOLO for Efficient Open-Set Detection and Segmentation)的新型实时目标检测与分割模型,旨在通过高效的架构和创新的提示机制,实现对任意目标的实时检测与分割,同时支持多种开放场景下的提示方式(如文本提示、视觉提示和无提示)。YOLOE的核心贡献和研究内容可以凝练为以下几点:
1. 研究背景与动机
-
传统模型的局限性:现有的目标检测和分割模型(如YOLO系列)虽然高效,但受限于预定义的类别,难以适应开放场景下的任意目标检测需求。
-
开放场景的需求:实际应用中,模型需要能够处理未见过的新类别(开放词汇目标检测)或在无提示的情况下识别所有对象。
-
现有方法的不足:现有的开放集方法(如GLIP、DINO-X等)虽然在性能上有一定提升,但往往面临计算开销大、部署复杂或依赖昂贵的语言模型等问题。
2. YOLOE的核心贡献
YOLOE通过以下三个关键策略,在一个高效模型中实现了对多种开放提示机制的支持:
(1) 可重参数化的区域-文本对齐(RepRTA)
-
目标:优化文本提示与视觉特征的对齐,提升开放词汇目标检测的性能。
-
方法:通过轻量级辅助网络对预训练的文本嵌入进行改进,并在训练时增强视觉-文本对齐。
-
优势:在推理和迁移时,辅助网络可以无缝重参数化到分类头中,实现零开销部署。
(2) 语义激活的视觉提示编码器(SAVPE)
-
目标:高效处理视觉提示(如边界框、掩码等),提升对特定目标的检测和分割能力。
-
方法:通过解耦的语义分支和激活分支,以低复杂度生成提示嵌入。
-
优势:在保持高精度的同时,显著降低了计算开销,适合边缘设备部署。
(3) 懒惰区域提示对比(LRPC)
-
目标:在无提示场景下,高效识别图像中的所有对象。
-
方法:通过内置的大词汇表和专用嵌入,仅对检测到的对象进行类别检索,避免了对语言模型的依赖。
-
优势:显著降低了推理开销,同时保持了高性能。
3. 实验结果与性能分析
-
零样本性能:YOLOE在LVIS数据集上表现出色,YOLOE-v8-S在训练成本减少3倍、推理速度提升1.4倍的情况下,比YOLO-Worldv2-S高出3.5 AP。
-
视觉提示性能:YOLOE-v8-L在视觉提示场景下比T-Rex2高出3.3 APr,且训练数据和参数量更少。
-
无提示性能:YOLOE-v8-L在无提示场景下达到27.2 AP,显著优于GenerateU(26.8 AP),同时推理速度提升了53倍。
-
迁移能力:在迁移到COCO数据集时,YOLOE在有限的训练时间下,比YOLOv8系列高出0.4~0.6 AP,展现了强大的迁移能力。
4. 消融研究与分析
-
RepRTA的有效性:通过改进文本嵌入对齐,YOLOE在零样本检测任务中提升了2.3% AP,且无推理开销。
-
SAVPE的有效性:与简单的掩码池化相比,SAVPE通过激活分支显著提升了1.5 AP。
-
LRPC的有效性:通过懒惰检索机制,YOLOE在无提示场景下实现了1.7倍的推理速度提升,且性能无下降。
5. 结论
YOLOE通过高效的架构和创新的提示机制,成功地将目标检测和分割能力扩展到了开放场景,支持文本提示、视觉提示和无提示等多种模式。它在性能、效率和泛化能力上均表现出色,为实时开放集目标检测和分割任务提供了一个强大的基线模型。
6. 研究意义
YOLOE的提出不仅解决了现有开放集方法在效率和部署上的瓶颈,还为实时视觉任务(如自动驾驶、机器人视觉等)提供了一种灵活、高效且适应性强的解决方案,具有重要的理论和实际应用价值。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:
官方项目地址在这里,如下所示:
摘要
目标检测和分割在计算机视觉应用中被广泛使用,但传统的模型(如YOLO系列)虽然高效且准确,却受限于预定义的类别,限制了其在开放场景中的适应性。最近的开放集方法通过利用文本提示、视觉线索或无提示范式来克服这一限制,但这些方法通常会在性能和效率之间做出妥协,因为它们计算需求高或部署复杂。在本工作中,我们引入了YOLOE,它在一个高效的模型中集成了检测和分割,并支持多种开放提示机制,实现了“实时识别万物”。对于文本提示,我们提出了可重参数化的区域-文本对齐(RepRTA)策略。它通过一个可重参数化的轻量级辅助网络优化预训练的文本嵌入,并在零推理开销和转移开销的情况下增强视觉-文本对齐。对于视觉提示,我们提出了语义激活的视觉提示编码器(SAVPE)。它通过解耦的语义分支和激活分支,以最小的复杂度带来改进的视觉嵌入和准确性。对于无提示场景,我们引入了懒惰区域提示对比(LRPC)策略。它利用内置的大词汇表和专用嵌入来识别所有对象,避免了依赖昂贵的语言模型。广泛的实验表明,YOLOE在零样本性能和转移能力方面表现出色,同时具有高推理效率和低训练成本。值得注意的是,在LVIS数据集上,YOLOE-v8-S在训练成本减少3倍、推理速度提升1.4倍的情况下,比YOLO-Worldv2-S高出3.5 AP。在迁移到COCO数据集时,YOLOE-v8-L在几乎少4倍训练时间的情况下,比封闭集YOLOv8-L高出0.6 APb和0.4 APm。
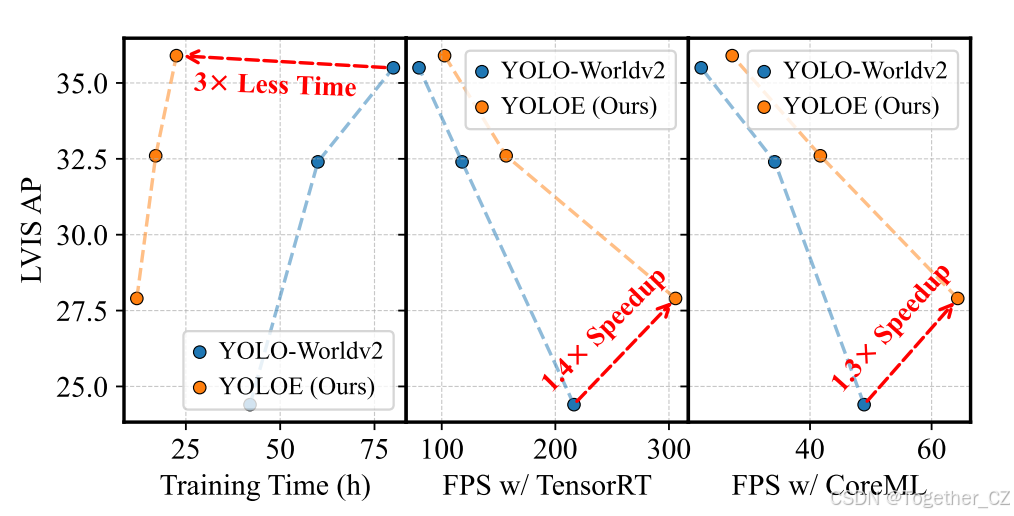
图1. 在开放文本提示条件下,YOLOE(我们的方法)与先进的YOLO-Worldv2在性能、训练成本和推理效率方面的比较。LVIS AP在minival数据集上进行评估,FPS(每秒帧数)分别在T4 GPU上使用TensorRT以及在iPhone 12上使用CoreML进行测量。结果突出了我们的优势。
1. 引言
目标检测和分割是计算机视觉中的基础任务,广泛应用于自动驾驶、医学分析和机器人等领域。传统的YOLO系列等方法利用卷积神经网络实现了实时卓越性能,但它们依赖于预定义的目标类别,限制了其在实际开放场景中的灵活性。这些场景越来越需要模型能够在文本、视觉线索或无提示等多种提示机制的引导下检测和分割任意对象。鉴于此,最近的研究转向使模型能够泛化到开放提示,例如GLIP或DINO-X。具体来说,通过区域级视觉-语言预训练,文本提示通常通过文本编码器处理,作为区域特征的对比目标,实现对任意类别的识别。对于视觉提示,它们通常被编码为与指定区域相关的类别嵌入,通过与图像特征或语言对齐的视觉编码器的交互来识别相似对象。在无提示场景中,现有方法通常整合语言模型,根据区域特征顺序找到所有对象并生成相应的类别名称。尽管取得了显著进展,但目前仍然缺乏一个能够支持多种开放提示、高效且准确识别任意对象的单一模型。例如,DINO-X虽然具有统一架构,但训练和推理开销巨大。此外,针对不同提示的单独设计在性能和效率之间存在次优权衡,难以直接整合到一个模型中。例如,文本提示方法在引入大词汇表时通常会因跨模态融合的复杂性而带来显著的计算开销。视觉提示方法通常因依赖于Transformer或额外的视觉编码器而在边缘设备上部署困难。无提示方法则依赖于大型语言模型,引入了显著的内存和延迟成本。鉴于此,本文提出了YOLOE,这是一个高效、统一且开放的对象检测和分割模型,能够在不同的提示机制(如文本、视觉输入和无提示范式)下像人眼一样工作。我们从广泛验证有效的YOLO模型开始。对于文本提示,我们提出了可重参数化的区域-文本对齐(RepRTA)策略,通过轻量级辅助网络优化预训练的文本嵌入,以实现更好的视觉-语义对齐。在训练期间,预缓存的文本嵌入只需要辅助网络处理文本提示,与封闭集训练相比,额外成本较低。在推理和转移时,辅助网络可以无缝重参数化到分类头中,产生与YOLO相同的架构,零开销。对于视觉提示,我们设计了语义激活的视觉提示编码器(SAVPE)。通过将感兴趣区域形式化为掩码,SAVPE在激活分支中将其与PAN的多尺度特征融合,以低维度产生分组的提示感知权重,并在语义分支中提取提示无关的语义特征。通过聚合它们得到提示嵌入,从而在最小复杂度下实现良好性能。对于无提示场景,我们引入了懒惰区域提示对比(LRPC)策略。LRPC不依赖于昂贵的语言模型,而是利用专用提示嵌入来找到所有对象,并利用内置的大词汇表进行类别检索。通过仅匹配锚点与识别到的对象与词汇表,LRPC确保了高性能与低开销。
2. 相关工作
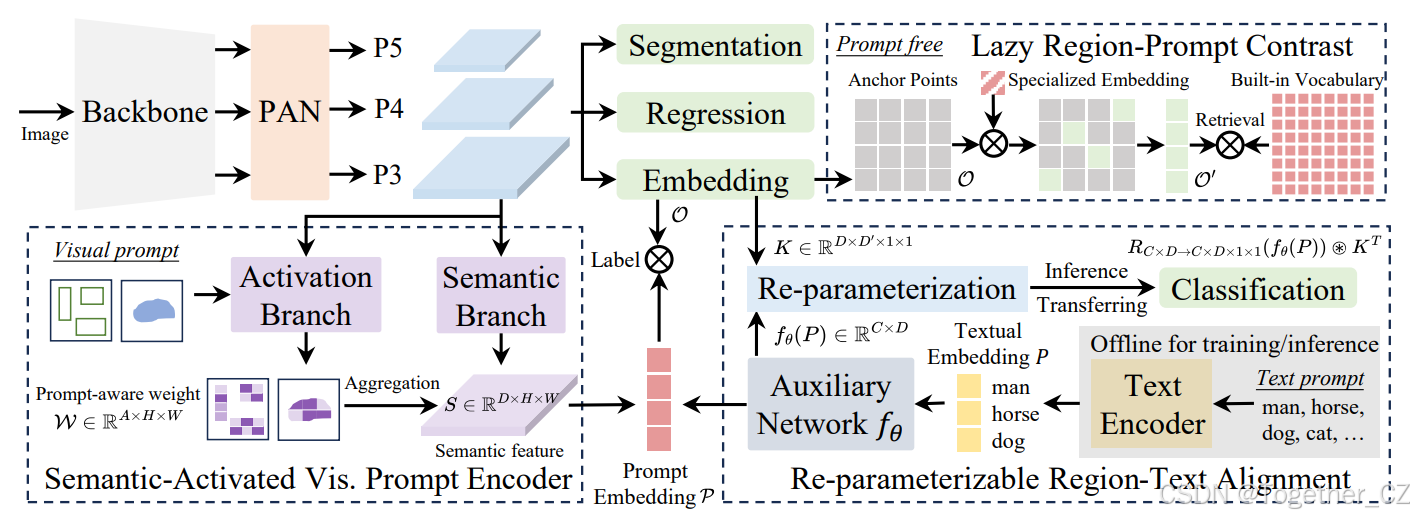
图2. YOLOE的总体架构,支持多种开放提示机制下的检测和分割。对于文本提示,我们设计了一种可重参数化的区域-文本对齐策略,以零推理和转移开销提升性能。对于视觉提示,采用SAVPE(语义激活的视觉提示编码器)以极小的代价对视觉线索进行编码,并生成增强的提示嵌入。对于无提示场景,我们引入了懒惰区域提示对比策略,通过检索高效地为所有识别到的对象提供类别名称。
传统的目标检测和分割
传统的目标检测和分割方法主要在封闭集范式下运行。早期的两阶段框架,例如Faster R-CNN,引入了区域提议网络(RPN),随后进行区域分类和回归。与此同时,单阶段检测器通过在单一网络中进行基于网格的预测来优先考虑速度。YOLO系列在这一范式中发挥了重要作用,并被广泛应用于现实世界中。此外,DETR及其变体通过使用基于Transformer的架构,消除了启发式驱动的组件,标志着一个重大转变。为了实现更细粒度的结果,现有的实例分割方法预测像素级掩码,而不是边界框坐标。例如,YOLACT通过整合原型掩码和掩码系数,实现了实时实例分割。基于DINO,MaskDINO利用查询嵌入和高分辨率像素嵌入图来生成二值掩码。
文本提示的目标检测和分割
最近的开放词汇目标检测进展集中在通过对齐视觉特征和文本嵌入来检测新类别。具体来说,GLIP通过在大规模图像-文本对上进行基于区域的预训练,统一了目标检测和短语定位,展示了强大的零样本性能。DetCLIP通过丰富概念描述,促进了开放词汇学习。此外,Grounding DINO通过将跨模态融合整合到DINO中,增强了文本提示和视觉表示之间的对齐。YOLO-World进一步展示了基于YOLO架构的小型检测器的开放识别能力。YOLO-UniOW在此基础上利用自适应决策学习策略。同样,一些开放词汇实例分割模型从先进的基础模型中学习丰富的视觉-语义知识,以对新目标类别进行分割。例如,X-Decoder和OpenSeeD探索了开放词汇检测和分割任务。APE引入了一个通用视觉感知模型,通过各种文本提示对图像中的所有对象进行对齐和提示。
视觉提示的目标检测和分割
虽然文本提示提供了通用描述,但某些对象仅靠语言描述可能具有挑战性,例如那些需要专业知识的对象。在这种情况下,视觉提示可以通过更灵活、更具体地引导检测和分割来补充文本提示。例如,OV-DETR和OWL-ViT利用CLIP编码器处理文本和图像提示。MQDet通过查询图像中的类别特定视觉信息增强文本查询。DINOv探索了视觉提示作为通用和指代视觉任务中的上下文示例。T-Rex2通过区域级对比对齐整合了视觉和文本提示。对于分割任务,基于大规模数据,SAM提出了一个灵活且强大的模型,可以交互式和迭代地进行提示。SEEM进一步探索了使用更多样化提示类型分割对象。Semantic-SAM在语义理解和粒度检测方面表现出色,能够处理全景分割和部件分割任务。
无提示的目标检测和分割
现有的方法仍然依赖于在推理过程中使用显式提示进行开放集检测和分割。为了克服这一限制,一些工作探索了整合生成性语言模型,以生成所有找到的对象的描述。例如,GRiT使用文本解码器同时完成密集字幕和目标检测任务。DetCLIPv3在大规模数据上训练对象字幕器,使模型能够生成丰富的标签信息。GenerateU利用语言模型以自由形式生成对象名称。
总结
据我们所知,除了DINO-X之外,很少有工作能够在单一架构中实现多种开放提示机制下的目标检测和分割。然而,DINO-X需要大量的训练成本和显著的推理开销,严重限制了其在现实世界边缘部署中的实用性。相比之下,我们的YOLOE旨在提供一个高效且统一的模型,能够实现实时性能和易于部署的效率。
3. 方法论
在本节中,我们将详细介绍YOLOE的设计。YOLOE基于YOLO架构(第3.1节),通过RepRTA支持文本提示(第3.2节),通过SAVPE支持视觉提示(第3.3节),并通过LRPC支持无提示场景(第3.4节)。
3.1 模型架构
如图2所示,YOLOE采用了典型的YOLO架构,包括主干网络、PAN、回归头、分割头和对象嵌入头。主干网络和PAN提取图像的多尺度特征。对于每个锚点,回归头预测检测的边界框,分割头生成原型和掩码系数以进行分割。对象嵌入头遵循YOLO中的分类头结构,只是最后一层1×1卷积层的输出通道数从封闭集场景中的类别数量改为嵌入维度。同时,给定文本和视觉提示时,我们分别使用RepRTA和SAVPE将它们编码为归一化的提示嵌入P。它们作为分类权重,与锚点的对象嵌入O进行对比以获得类别标签。该过程可以形式化为:
Label = O · PT : RN×D × RD×C → RN×C, (1)
其中N表示锚点的数量,C表示提示的数量,D表示嵌入的特征维度。
3.2 可重参数化的区域-文本对齐
在开放集场景中,文本和对象嵌入之间的对齐决定了识别类别的准确性。以往的工作通常通过复杂的跨模态融合来改进视觉-文本表示,以实现更好的对齐。然而,这些方法会带来显著的计算开销,尤其是在文本数量较多时。鉴于此,我们提出了可重参数化的区域-文本对齐(RepRTA)策略,通过可重参数化的轻量级辅助网络在训练期间改进预训练的文本嵌入。在零推理和转移开销的情况下增强文本和锚点对象嵌入之间的对齐。具体来说,对于长度为C的文本提示T,我们首先使用CLIP文本编码器获得预训练的文本嵌入P = TextEncoder(T)。在训练之前,我们提前缓存数据集中所有文本的嵌入,并且可以移除文本编码器,而无需额外的训练成本。同时,如图3(a)所示,我们引入了一个轻量级辅助网络fθ,它仅包含一个前馈块,其中θ表示可训练参数,并且与封闭集训练相比引入了较低的开销。它推导出增强的文本嵌入P = fθ(P) ∈ RC×D,用于在训练期间与锚点的对象嵌入进行对比,从而实现改进的视觉-语义对齐。设K ∈ RD×D′×1×1为对象嵌入头中最后一层卷积的核参数,I ∈ RD′×H×W为输入特征,⊛为卷积运算符,R为重塑函数,则有:
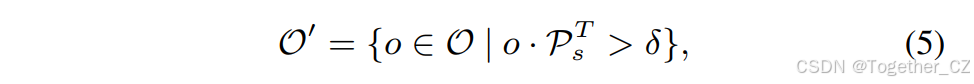
此外,在训练完成后,辅助网络可以与对象嵌入头重参数化为YOLO相同的分类头。经过重参数化后最后一层卷积的新核参数K′ ∈ RC×D′×1×1可以通过以下方式得出:
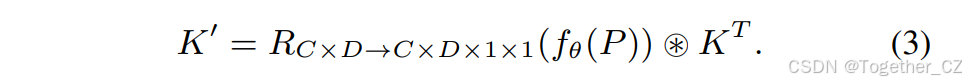
最终预测可以通过Label = I ⊛ K′获得,这与原始YOLO架构相同,从而在部署和转移到下游封闭集任务时实现零开销。
3.3 语义激活的视觉提示编码器
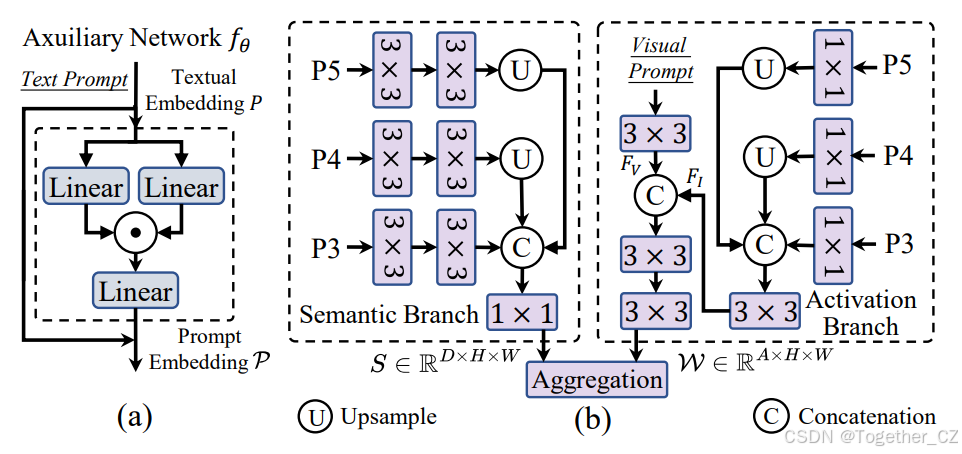
图3. (a) RepRTA中轻量级辅助网络的结构,由一个SwiGLU FFN模块组成。
(b) SAVPE的结构,包含语义分支用于生成与提示无关的语义特征,以及激活分支用于提供分组的提示感知权重。通过聚合这两个分支的输出,可以高效地生成视觉提示嵌入。
视觉提示旨在通过视觉线索(例如框和掩码)指示感兴趣的目标类别。为了生成视觉提示嵌入,以往的方法通常采用Transformer密集设计,例如可变形注意力,或者额外的CLIP视觉编码器。然而,这些方法由于复杂的运算符或高计算需求,给部署和效率带来了挑战。鉴于此,我们引入了语义激活的视觉提示编码器(SAVPE),以高效地处理视觉线索。它包含两个解耦的轻量级分支:(1)语义分支输出与提示无关的语义特征,通道数为D,无需融合视觉线索的开销;(2)激活分支通过与图像特征的交互,以较低的成本产生分组的提示感知权重。通过聚合这两个分支,可以在最小复杂度下得到信息丰富的提示嵌入。如图3(b)所示,在语义分支中,我们采用了与对象嵌入头类似的结构。对于PAN的多尺度特征{P3, P4, P5},我们分别为每个尺度使用两个3×3卷积。在上采样后,特征被连接并投影以得到语义特征S ∈ RD×H×W。在激活分支中,我们将视觉提示形式化为掩码,感兴趣区域为1,其他区域为0。我们对掩码进行下采样,并通过3×3卷积得到提示特征FV ∈ RA×H×W。此外,我们从{P3, P4, P5}中通过卷积得到图像特征FI ∈ RA×H×W,用于与FV融合。FV和FI被连接起来,用于输出提示感知权重W ∈ RA×H×W,该权重在提示指示区域内通过softmax进行归一化。此外,我们将S的通道数分为A组,每组有D/A个通道。第i组中的通道共享来自W的第i个通道的权重Wi:i+1。通过A ≪ D,我们可以在低维度下处理视觉线索与图像特征,带来最小的开销。此外,提示嵌入可以通过以下方式从两个分支的聚合中得到:
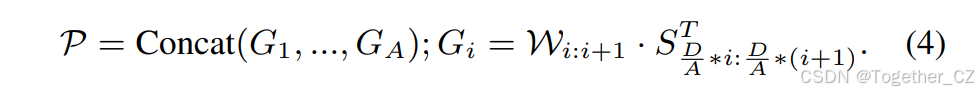
然后,它可以通过与锚点的对象嵌入进行对比来识别感兴趣类别的对象。
3.4 懒惰区域提示对比
在无提示场景中,没有明确的引导,模型被期望识别图像中所有对象的名称。以往的方法通常将这种设置表述为一个生成问题,其中使用语言模型为密集找到的对象生成类别。然而,这引入了显著的开销,例如GenerateU中使用的FlanT5-base(2.5亿参数)和DINO-X中的OPT-125M,这些模型远远不符合高效率的要求。鉴于此,我们将这种设置重新表述为一个检索问题,并提出了懒惰区域提示对比(LRPC)策略。它以一种成本效益高的方式,从内置的大词汇表中为包含对象的锚点懒惰地检索类别名称。这种范式完全不依赖于语言模型,同时具有良好的效率和性能。具体来说,对于预训练的YOLOE,我们引入了一个专用提示嵌入,并专门训练它以找到所有对象,其中对象被视为一个类别。同时,我们按照[16]收集了一个涵盖各种类别的大词汇表,并将其作为检索的内置数据源。人们可以直接使用大词汇表作为YOLOE的文本提示来识别所有对象,然而,这将通过对比大量锚点的对象嵌入与众多文本嵌入来产生显著的计算成本。相反,我们使用专用提示嵌入Ps来找到包含对象的锚点集合O′:
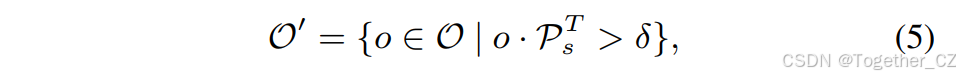
其中O表示所有锚点,δ是用于过滤的阈值超参数。然后,只有O′中的锚点才会懒惰地与内置词汇表进行匹配以检索类别名称,跳过了与无关锚点的成本。这进一步提高了效率,而不会降低性能,促进了其在现实世界中的应用。
3.5 训练目标
在训练期间,我们按照[5]为每个mosaic样本在线获取词汇表,将图像中涉及的文本作为正标签。按照[21],我们利用任务对齐的标签分配来匹配预测与真实值。分类采用二元交叉熵损失,回归采用IoU损失和分布式焦点损失。对于分割,我们按照[3]使用二元交叉熵损失来优化掩码。
4. 实验
4.1 实现细节
模型
为了与[5]进行公平比较,我们采用与YOLOv8相同的架构用于YOLOE。此外,为了验证YOLOE在其他YOLO架构上的良好泛化能力,我们还使用了YOLOv11架构进行实验。对于这两种架构,我们分别提供了三种模型规模,即小(S)、中(M)和大(L),以满足不同的应用需求。文本提示使用预训练的MobileCLIP-B(LT)文本编码器进行编码。我们默认使用A = 16作为SAVPE中的分组数。
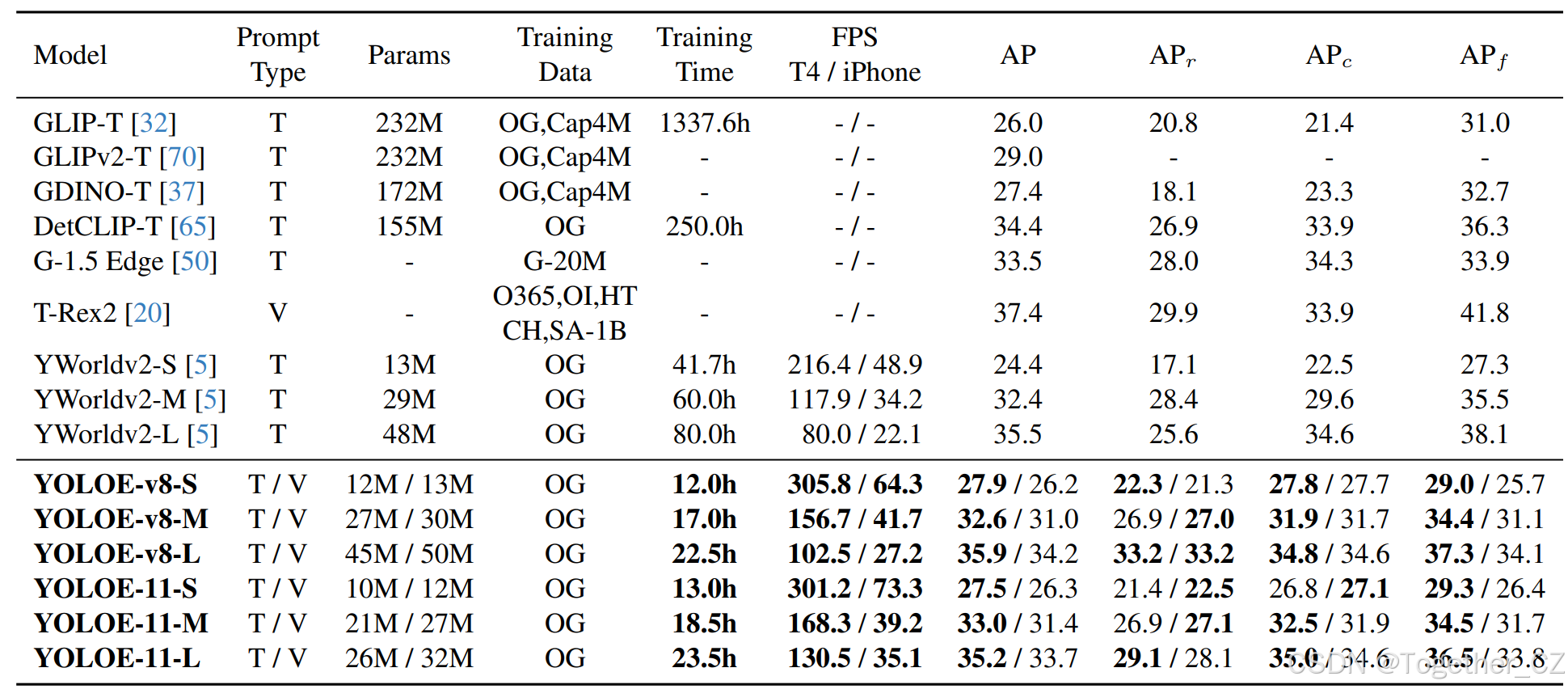
表1. 在LVIS上的零样本检测评估。为了公平比较,报告了在LVIS minival数据集上以零样本方式评估的固定AP。训练时间是针对文本提示的,基于8个Nvidia V100 GPU用于[32, 65],以及8个RTX4090 GPU用于YOLO-World和YOLOE。FPS分别在Nvidia T4 GPU上使用TensorRT和在iPhone 12上使用CoreML进行测量。结果提供了文本提示(T)和视觉提示(V)类型。对于训练数据,OI、HT和CH分别表示OpenImages [24]、HierText [39]和CrowdHuman [51]。OG表示Objects365 [52]和GoldG [22],G-20M表示Grounding-20M [50]。
数据
我们按照[5]使用检测和定位数据集,包括Objects365(V1)[52]和GoldG [22](包含GQA [17]和Flickr30k [43]),其中排除了COCO [34]中的图像。此外,我们利用SAM-2.1 [46]模型,使用检测和定位数据集中的真实边界框生成伪实例掩码作为分割数据。这些掩码经过滤波和简化以去除噪声[9]。对于视觉提示数据,我们按照[20]使用真实边界框作为视觉线索。在无提示任务中,我们重用相同的数据集,但将所有对象标注为一个类别,以学习专用提示嵌入。
训练
由于计算资源有限,与YOLO-World训练100个epoch不同,我们首先训练YOLOE的文本提示30个epoch。然后,我们仅用2个epoch训练SAVPE以支持视觉提示,避免了因支持视觉提示而带来的额外显著训练成本。最后,我们仅用1个epoch训练专用提示嵌入以支持无提示场景。在文本提示训练阶段,我们采用了与[5]相同的设置。值得注意的是,YOLOE-v8-S/M/L可以在8个Nvidia RTX4090 GPU上分别训练12.0/17.0/22.5小时,与YOLO-World相比,训练成本降低了3倍。对于视觉提示训练,我们冻结了其他部分,并采用了与文本提示训练相同的设置。为了启用无提示能力,我们使用相同的数据训练专用嵌入。我们可以看到,YOLOE不仅训练成本低,而且在零样本性能方面表现出色。此外,为了验证YOLOE在下游任务上的良好迁移能力,我们在COCO [34]上对YOLOE进行了微调,用于封闭集检测和分割。我们尝试了两种不同的实际微调策略:(1)线性探测:只有分类头是可训练的;(2)全调优:所有参数都是可训练的。对于线性探测,我们只训练所有模型10个epoch。对于全调优,我们训练小规模模型(包括YOLOE-v8-S/11-S)160个epoch,中规模和大规模模型(包括YOLOE-v8-M/L和YOLOE-11-M/L)80个epoch。
评估指标
对于文本提示评估,我们使用基准测试中的所有类别名称作为输入,遵循开放词汇目标检测任务的标准协议。对于视觉提示评估,按照[20],对于每个类别,我们随机抽取N个训练图像(默认N=16),使用它们的真实边界框提取视觉嵌入,并计算平均提示嵌入。对于无提示评估,我们采用与[33]相同的协议。使用预训练的文本编码器[57]将开放式的预测映射到基准测试中语义相似的类别名称。与[33]不同的是,我们通过选择最自信的预测来简化映射过程,消除了对top-k选择和束搜索的需求。我们使用[16]中的标签列表作为内置的大词汇表,总共有4585个类别名称,并默认使用δ = 0.001作为LRPC的阈值。对于所有三种提示类型,按照[5, 20, 33],我们在LVIS [14]上以零样本的方式进行评估,该数据集包含1203个类别。默认情况下,报告的是在LVIS minival子集上的固定AP [7]。对于迁移到COCO,我们按照[1, 21]评估标准AP。此外,我们在Nvidia T4 GPU上使用TensorRT和iPhone 12上使用CoreML测量所有模型的FPS。
4.2 文本和视觉提示评估
如表1所示,在LVIS上的检测任务中,YOLOE在不同模型规模下均表现出良好的效率与零样本性能之间的权衡。我们还注意到,这些结果是在比YOLO-Worldv2少3倍的训练时间下实现的。具体来说,YOLOE-v8-S/M/L的性能分别比YOLO-Worldv2-S/M/L高出3.5/0.2/0.4 AP,同时在T4和iPhone 12上的推理速度分别提升了1.4倍/1.3倍和1.3倍/1.2倍。此外,对于稀有类别(这是一个挑战性问题),我们的YOLOE-v8-S和YOLOE-v8-L分别获得了5.2%和7.6%的APr提升。此外,与YOLO-Worldv2相比,尽管YOLOE-v8-M/L在APf上表现略低,但这种性能差距主要源于YOLOE将检测和分割集成到一个模型中。这种多任务学习引入了权衡,对频繁类别的检测性能产生了不利影响,如表5所示。此外,使用YOLOv11架构的YOLOE也表现出良好的性能和效率。例如,YOLOE-11-L在T4和iPhone 12上的推理速度分别比YOLO-Worldv2-L快1.6倍,突出了YOLOE的强大泛化能力。此外,视觉提示的加入进一步增强了YOLOE的多功能性。与T-Rex2相比,YOLOE-v8-L在APr上提高了3.3,APc上提高了0.9,同时训练数据减少了2倍(3.1M vs. 我们的1.4M),并且训练资源显著降低(16个Nvidia A100 GPU vs. 我们的8个Nvidia RTX4090 GPU)。此外,对于视觉提示,尽管我们仅在其他部分冻结的情况下训练了2个epoch的SAVPE,但我们注意到它在各种模型规模上都能实现与文本提示相当的APr和APc。这表明视觉提示在文本提示通常难以准确描述的不频繁对象中具有有效性,这与[20]中的观察结果相似。此外,对于分割任务,我们在表2中报告了在LVIS val集上的评估结果,并报告了标准的APm。结果表明,YOLOE在使用文本提示和视觉提示时表现出强大的性能。具体来说,YOLOE-v8-M/L在零样本方式下分别实现了20.8和23.5的APm,显著优于在LVIS-Base数据集上微调的YOLO-Worldv2-M/L,分别高出3.0和3.7 APm。这些结果很好地证明了YOLOE的优越性。
4.3 无提示评估
如表3所示,在无提示场景中,YOLOE也表现出优越的性能和效率。具体来说,YOLOE-v8-L在AP上达到了27.2,APr上达到了23.5,显著优于使用Swin-T骨干网络的GenerateU [33](26.8 AP和20.0 APr),同时参数减少了6.3倍,推理速度提升了53倍。这表明YOLOE通过将开放式问题重新表述为内置大词汇表的检索任务,有效地避免了对显式提示的依赖,并展示了其在广泛类别泛化方面的潜力。这种功能还增强了YOLOE的实用性,使其能够在更广泛的现实世界场景中应用。
表2. 在LVIS上的分割评估。我们在LVIS验证集上对所有模型进行评估,并报告标准的APm(平均精度均值)。YOLOE支持文本(T)和视觉线索(V)作为输入。†表示预训练模型在LVIS-Base数据上对分割头进行了微调。相比之下,我们在训练过程中未使用任何LVIS图像,以零样本的方式评估YOLOE。
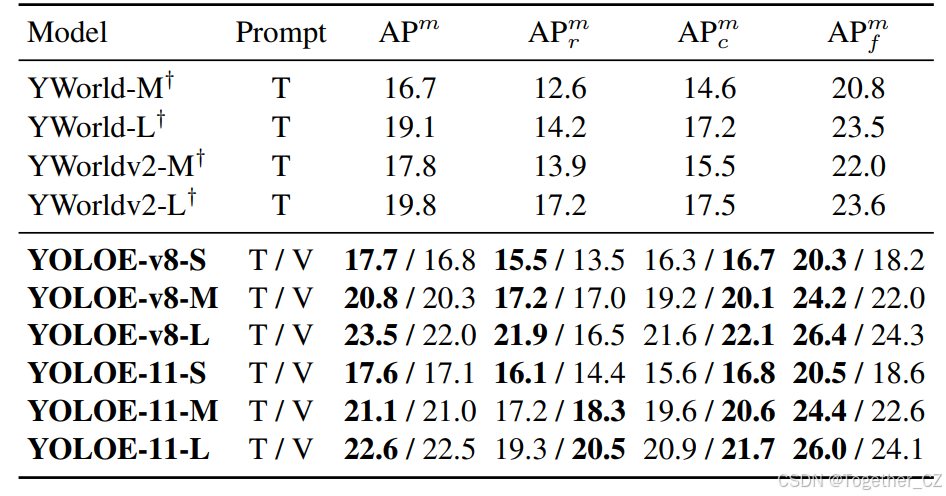
表3. 在LVIS上的无提示评估。按照[33]中的协议,在LVIS minival数据集上报告固定AP。FPS使用Pytorch [42]在Nvidia T4 GPU上进行测量。
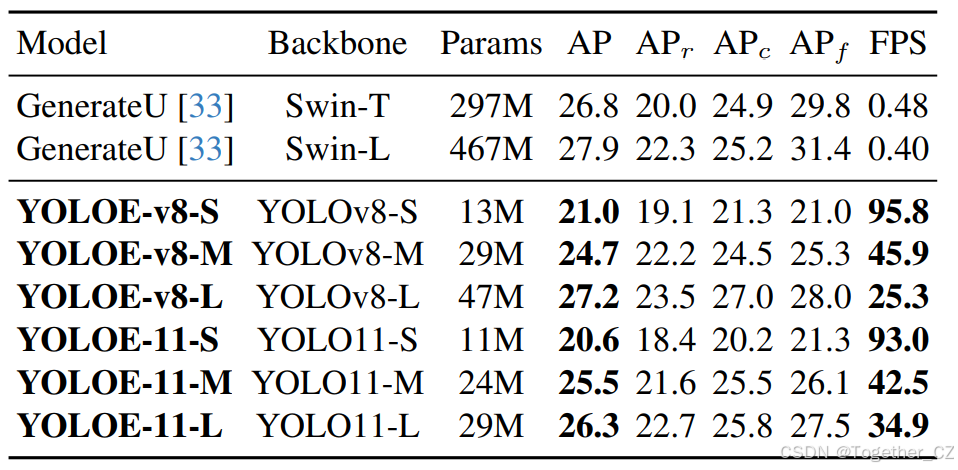
表4. 在COCO上的下游迁移评估。我们在COCO数据集上对YOLOE进行微调,并报告目标检测和实例分割的标准平均精度(AP)。我们尝试了两种实际的微调策略,即线性探测(Linear probing)和全调优(Full tuning)。
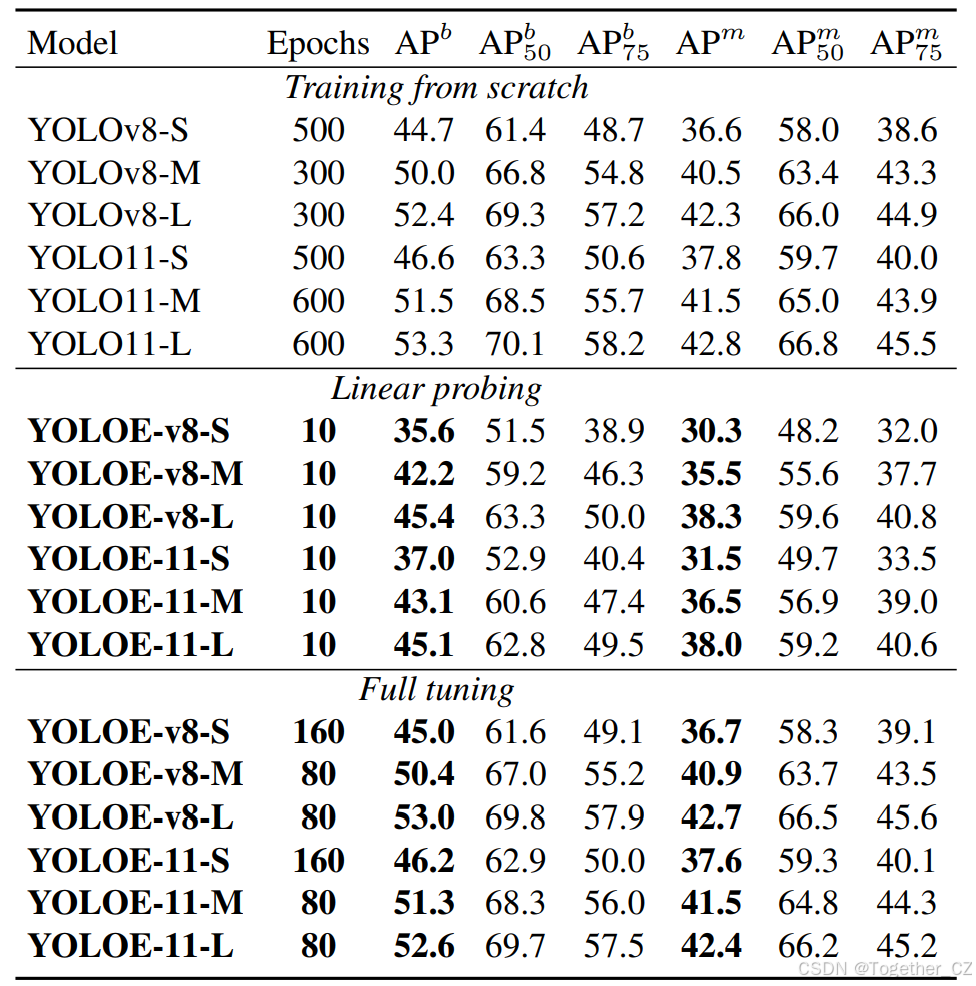
表5. 基于文本提示的YOLOE发展路线图。在LVIS minival数据集上以零样本方式报告标准平均精度(AP)。FPS分别在Nvidia T4 GPU上使用TensorRT(T)和在iPhone 12上使用CoreML(C)进行测量。
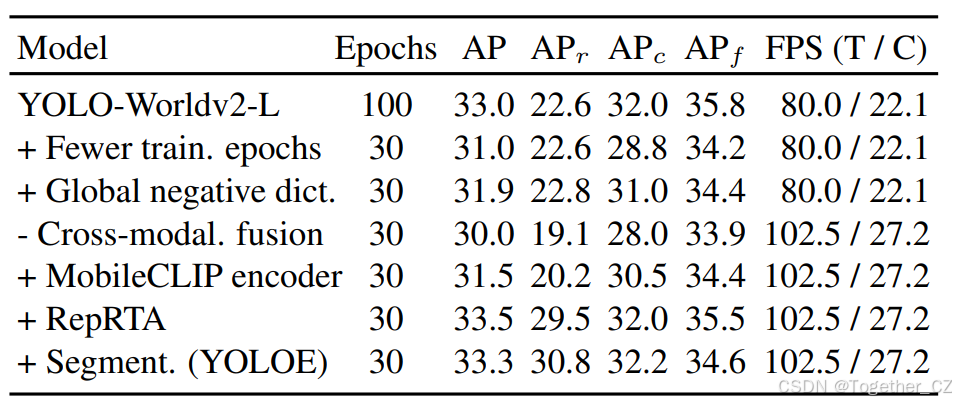
4.4 下游迁移
如表4所示,当迁移到COCO进行下游封闭集检测和分割时,YOLOE在有限的训练周期内表现出良好的性能,无论是在线性探测还是全调优策略下。具体来说,在线性探测中,YOLOE-11-M/L仅用不到2%的训练时间就能达到YOLO-11-M/L性能的80%以上。这突出了YOLOE的强大迁移能力。对于全调优,YOLOE可以在有限的训练成本下进一步提升性能。例如,在比YOLOv8-M/L少近4倍的训练周期下,YOLOE-v8-M/L分别比YOLOv8-M/L高出0.4 APm和0.6 APb。在3倍少的训练时间下,YOLOE-v8-S也比YOLOv8-S在检测和分割方面表现更好。这些结果很好地证明了YOLOE可以作为迁移到下游任务的强大起点。
4.5 消融研究
我们进一步对YOLOE的设计进行了广泛的分析。实验在YOLOE-v8-L上进行,默认情况下在LVIS minival集上以零样本方式进行标准AP评估。从YOLOv8-Worldv2-L到我们的YOLOE的路线图。我们在表5中概述了从基线模型YOLOv8-Worldv2-L到我们的YOLOE的逐步进展。由于计算资源有限,我们首先将训练周期减少到30个,导致AP从33.0%下降到31.0%。此外,我们没有使用空字符串作为定位数据的负文本,而是按照[65]维护一个全局字典以采样更多样化的负提示。全局字典是通过选择在训练数据中出现超过100次的类别名称构建的。这带来了0.9%的AP提升。接下来,我们移除了跨模态融合以避免昂贵的视觉-文本特征交互,这导致了1.9%的AP下降,但在T4和iPhone 12上的推理速度分别提升了1.28倍和1.23倍。为了弥补这一下降,我们使用了更强大的MobileCLIP-B(LT)文本编码器[57]来获得更好的预训练文本嵌入,这将AP恢复到了31.5%。此外,我们引入了RepRTA以增强锚点对象和文本嵌入之间的对齐,这带来了显著的2.3%的AP提升,且零推理开销,这证明了其有效性。最后,我们引入了分割头,并同时训练YOLOE进行检测和分割。尽管这导致了0.2%的AP和0.9 APf下降(由于多任务学习),YOLOE获得了分割任意对象的能力。

图4. (a) 在LVIS上的零样本推理。
(b) 使用自定义文本提示的结果,其中“白色帽子、红色帽子、白色汽车、太阳镜、胡子、领带”作为文本提示。
(c) 使用视觉提示的结果,其中红色虚线边界框作为视觉线索。
(d) 无提示场景下的结果,未提供任何明确的提示。
更多示例请参考补充材料。
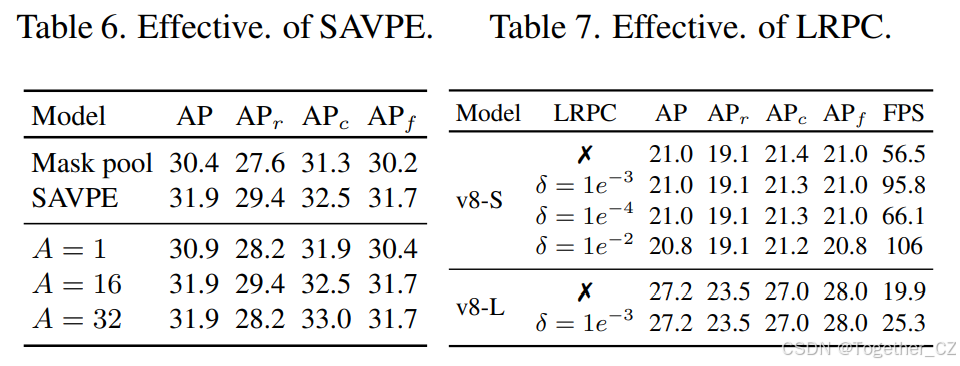
SAVPE的有效性
为了验证SAVPE对视觉输入的有效性,我们移除了激活分支,并简单地使用掩码池化来聚合语义特征与制定的视觉提示掩码。如表6所示,SAVPE显著优于“掩码池化”,提升了1.5 AP。这是因为“掩码池化”忽略了提示指示区域内不同位置的语义重要性差异,而我们的激活分支有效地模拟了这种差异,从而改进了语义特征的聚合,并为对比提供了更好的提示嵌入。我们还检查了激活分支中不同分组数A的影响。如表6所示,在A = 1时性能也可以得到提升。此外,我们在A = 16时实现了31.9 AP的强劲性能,获得了有利的平衡,更多分组只会带来边际性能差异。
LRPC的有效性
为了验证LRPC在无提示场景中的有效性,我们引入了一个基线,该基线直接使用内置的大词汇表作为文本提示,让YOLOE识别所有对象。表7展示了比较结果。我们观察到,在相同性能的情况下,我们的LRPC为YOLOE-v8-S/L分别获得了显著的1.7倍/1.3倍推理速度提升,通过懒惰地检索找到对象的锚点的类别,并跳过大量无关的锚点。这些结果很好地突出了其有效性和实用性。此外,随着不同阈值δ用于过滤,LRPC可以实现不同的性能和效率权衡,例如,对于YOLOE-v8-S,启用1.9倍速度提升仅导致0.2 AP下降。
4.6 可视化分析
我们对YOLOE在四种场景下进行了可视化分析:(1)图4(a)中的LVIS零样本推理,其中其类别名称作为文本提示;(2)图4(b)中的文本提示,其中任意文本可以作为提示输入;(3)图4(c)中的视觉提示,其中视觉线索可以作为提示绘制;(4)图4(d)中没有明确提示,模型识别所有对象。我们可以看到,YOLOE在这些多样化场景中均能准确检测和分割各种对象,进一步证明了其在各种应用中的有效性和实用性。
5. 结论
在本文中,我们提出了YOLOE,这是一个单一的高效模型,能够无缝集成多种开放提示机制下的目标检测和分割。具体来说,我们引入了RepRTA、SAVPE和LRPC,使YOLO能够处理文本提示、视觉线索和无提示范式,并以较低的成本实现良好的性能。凭借这些优势,YOLOE在各种提示方式下均具有强大的能力,并且推理效率高,能够实现实时“识别万物”。我们希望它能够作为一个强大的基线,激励进一步的发展。



















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











