









Google DeepMind
Google Research
发表于 2024-04-29

相关链接:
数据集:https://huggingface.co/datasets/katielink/med-gemini-medqa-relabeled
注:长EHR是长的电子健康记录(Electronic Health Record)
未开源!
摘要
在众多医疗应用中实现卓越表现对人工智能来说是巨大挑战,这需要先进的推理能力、获取最新医学知识的途径,以及对复杂多模态数据的理解。Gemini模型在多模态和长上下文推理方面具备强大的通用能力,为医学领域带来了令人期待的可能性。基于Gemini 1.0和Gemini 1.5的这些核心优势,我们推出了Med - Gemini,这是一系列功能强大的多模态模型,专门针对医学领域进行了优化,能够无缝整合网络搜索功能,并且可以通过定制编码器高效地适配新的模态。
我们在涵盖文本、多模态和长上下文应用的14个医学基准测试中对Med - Gemini进行评估,在其中10个测试中创造了新的最先进(SoTA)性能,并且在所有能够直接比较的基准测试中都超越了GPT - 4模型系列,且往往优势明显。在广受欢迎的MedQA(美国医学执照考试,USMLE)基准测试中,我们表现最佳的Med - Gemini模型采用了一种新的不确定性引导搜索策略,达到了91.1%的准确率,创造了新的SoTA性能,比我们之前表现最佳的Med - PaLM 2高出4.6%。
我们基于搜索的策略在《新英格兰医学杂志》(NEJM)的复杂诊断挑战和GeneTuring基准测试中也展现出了SoTA性能。在包括NEJM图像挑战和MMMU(健康与医学)在内的7个多模态基准测试中,Med - Gemini比GPT - 4V的平均相对优势提高了44.5%。我们通过在从长去标识化健康记录的“大海捞针”式检索任务和医学视频问答中达到SoTA性能,展示了Med - Gemini的长上下文能力,超越了仅使用上下文学习的先前定制方法。
最后,Med - Gemini的性能表明了其在现实世界中的实用性,在医学文本摘要和转诊信生成等任务中超越了人类专家,同时在多模态医学对话、医学研究和教育方面也显示出了巨大的潜力。总体而言,我们的结果为Med - Gemini在医学众多领域的应用前景提供了有力证据,尽管在这个对安全性要求极高的领域进行实际部署之前,进一步严格的评估至关重要。
1 引言
医学是一项复杂的工作。临床医生的日常工作包括与患者会诊,在这个过程中,清晰地沟通诊断结果、治疗方案以及表达同理心对于建立信任至关重要。复杂病例需要深入了解患者电子病历中的病史,同时还需要从医学图像和其他诊断中进行多模态推理。为了在不确定的情况下做出决策,临床医生必须及时了解从研究出版物到手术视频等各种权威来源的最新医学信息。医疗服务的艺术在于临床医生能够进行先进的临床推理,从多样的多模态来源综合复杂信息,并与其他临床医生有效协作,以帮助患者进行治疗。虽然人工智能(AI)系统可以辅助完成个别医疗任务 ,并且在多模态多任务“通用”医疗应用方面也展现出了初步的前景,但开发更复杂的推理、多模态和长上下文理解能力,将为临床医生和患者带来更加直观且实用的辅助工具。
大语言模型(LLMs)和大多模态模型(LMMs),如GPT4、PaLM和Gemini的出现,表明这些模型能够有效地编码临床知识,甚至在需要专业知识的复杂病例和场景的医学问答基准测试中也能有出色表现。然而,在这些任务上的表现并不能直接反映其在现实世界中的实用性。医学数据的独特性质以及对安全性的严格要求,需要专门的提示、微调,或者可能两者都需要,同时还需要仔细校准这些模型。
经过医学微调的大语言模型可以为数百万互联网用户提出的细致且开放式的医学问题提供高质量的长篇答案,Med - PaLM 2在事实性、推理、危害和偏差等方面超越了医生。其潜力不仅限于问答领域。诸如Flamingo - CXR和Med - PaLM M等大多模态模型在受控环境下生成放射学报告的能力与放射科医生相当。在与患者进行基于文本的诊断咨询这一更具挑战性的场景中,Articulate Medical Intelligence Explorer(AMIE)模型在诊断对话的多个评估维度上优于初级保健医生。
尽管取得了这些有前景的成果,但性能仍有很大的提升空间。大语言模型在不确定性下的临床推理表现欠佳,虚构信息和偏差仍然是主要挑战。对于大语言模型来说,使用工具和获取最新医学信息以完成医疗任务仍然是一个难题,与临床医生的有效协作也是如此。此外,它们处理复杂多模态医学数据(例如,整合图像、视频和随时间变化的去标识化健康记录)的能力目前也较为有限。尽管这些能力在医学应用中尤为重要,但性能的提升可能不仅限于医学领域。为衡量和加速医学大语言模型的进展而开发的任务和基准测试将产生广泛的影响。
Gemini模型,如Gemini 1.0和1.5技术报告中所述,是新一代功能强大的多模态模型,具有新的基础能力,有可能解决医学人工智能的一些关键挑战。这些模型是基于Transformer解码器架构的模型,通过在架构、优化和训练数据方面的创新得到增强,使其能够在包括图像、音频、视频和文本在内的各种模态中展现出强大的能力。最近引入的专家混合架构,使Gemini模型能够在推理时高效地扩展并处理更长、更复杂的数据。
基于Gemini模型的优势,我们推出了Med - Gemini,这是一系列针对医学领域进行微调并专门化的模型。通用医学人工智能模型的概念受到了广泛关注,这类系统的潜力也得到了令人瞩目的展示。然而,尽管通用方法在医学研究中是一个有意义的方向,但现实世界的考虑因素带来了权衡和特定任务优化的要求,这些要求之间可能相互冲突。在这项工作中,我们并不试图构建一个通用的医学人工智能系统。相反,我们引入了一系列模型,每个模型都针对不同的能力和特定应用场景进行了优化,同时考虑了训练数据、计算资源可用性和推理延迟等因素。
Med - Gemini继承了Gemini在语言和对话、多模态理解以及长上下文推理方面的基础能力。对于基于语言的任务,我们通过自训练增强了模型使用网络搜索的能力,并在代理框架内引入了推理时的不确定性引导搜索策略。这种结合使模型能够为复杂的临床推理任务提供更符合事实、可靠且细致入微的结果。这使得Med - Gemini在MedQA(USMLE)测试中达到了91.1%的准确率,创造了新的最先进性能,比之前的Med - PaLM 2模型高出4.6%。我们还通过与多位独立的专家临床医生重新标注MedQA(USMLE)数据,仔细检查了数据质量,识别出由于信息缺失和错误而无法回答的问题,从而能够对我们的最先进性能进行可靠的分析和描述。不确定性引导搜索策略具有通用性,在《新英格兰医学杂志》(NEJM)临床病理会议(CPC)病例和GeneTuring基准测试中也带来了最先进的性能。除了在这些基准测试中的出色表现,我们的模型在与人类医生进行医学笔记总结和临床转诊信生成等任务的比较中也表现出色,这表明了其在现实世界中的实用性。
由于Gemini模型经过训练能够处理与多种其他数据模态交织的文本输入,因此它们在多模态任务中表现出色。这使得它们在一些多模态医学基准测试中,如NEJM图像挑战,具有令人印象深刻的开箱即用的最先进性能。然而,当处理在预训练数据中代表性不足的专业医学模态时,它们的性能仍有提升空间。我们通过多模态微调解决了这个问题,并展示了模型使用定制编码器适应新医学模态的能力,在Path - VQA和ECG - QA等基准测试中达到了最先进的性能。我们定性地展示了我们的模型在各种分布内和分布外数据模态上进行具有临床意义的多模态对话的能力。
最后,Gemini模型的长上下文能力为医学应用开辟了许多令人兴奋的可能性,因为在临床决策中,经常需要解析大量数据,而这存在“信息过载”的风险。我们配置用于长上下文处理的Med - Gemini模型能够无缝分析复杂的长格式模态,如去标识化的电子健康记录(EHRs)和视频。我们在“大海捞针”式的长EHR理解、医学教学视频问答、视频中的手术动作识别以及手术视频的安全关键视图(CVS)评估等任务中取得了令人瞩目的成绩,展示了这些能力的有效性。
Med - Gemini的进展前景广阔,但在大规模实际部署之前,仔细考虑医学领域的细微差别、明确AI系统作为专家临床医生辅助工具的作用,并进行严格的验证仍然至关重要。
我们的主要贡献总结如下:
Med - Gemini,我们新的多模态医学模型系列:我们推出了一个新的功能强大的多模态医学模型系列,基于Gemini构建。Med - Gemini在临床推理、多模态和长上下文能力方面取得了重要进展。它们经过进一步微调,能够利用网络搜索获取当前信息,并可以通过使用特定模态的编码器定制以适应新的医学模态。
全面的基准测试:我们在14个医学基准测试中的25个任务上评估了Med - Gemini的能力,涵盖了文本、多模态和长上下文应用。据我们所知,这是迄今为止对多模态医学模型最全面的基准测试。
临床语言任务的最先进结果:针对临床推理进行优化的Med - Gemini在MedQA(USMLE)测试中使用一种新的不确定性引导搜索策略,达到了91.1%的最先进性能。我们通过与临床专家对MedQA数据集进行仔细的重新标注,量化并描述了我们的性能提升,发现这些改进是有意义的。我们还通过在NEJM CPC和GeneTuring基准测试中的最先进性能,展示了搜索策略的有效性。
多模态和长上下文能力:Med - Gemini在本研究评估的7个多模态医学基准测试中的5个中达到了最先进性能。我们展示了多模态医学微调的有效性,以及使用专门的编码器层定制以适应新医学模态(如心电图,ECGs)的能力。Med - Gemini还展现出强大的长上下文推理能力,在诸如长电子健康记录中的“大海捞针”任务或医学视频理解基准测试等具有挑战性的基准测试中达到了最先进水平。此外,在未来的工作中,我们还将严格探索Gemini在放射学报告生成方面的能力。
Med - Gemini在现实世界中的实用性:除了在流行的医学基准测试中的表现,我们还通过对医学笔记总结、临床转诊信生成和EHR问答等任务的定量评估,预展示了Med - Gemini在现实世界中的潜在实用性。我们进一步展示了多模态诊断对话的定性示例,以及模型的长上下文能力在医学教育、面向临床医生的工具和生物医学研究中的应用。我们注意到,这些应用(特别是在像诊断这样对安全性要求极高的领域)将需要大量的进一步研究和开发。
2 方法
如Gemini技术报告中所介绍的,Gemini生态系统包含一系列在大小、模态编码器和架构上有所不同的模型,这些模型在多种模态的大量高质量数据上进行训练。Gemini模型在各种语言、推理、编码、多语言、图像和视频基准测试中都取得了最先进的结果。
值得注意的是,Gemini 1.0 Ultra模型在需要复杂推理的基于语言的任务中表现出色,而Gemini 1.5 Pro模型则增加了有效处理和利用跨越数百万个标记的长上下文输入和 / 或多模态输入(如数小时的视频或数十小时的音频)的能力。Gemini 1.0 Nano是Gemini模型系列中最小的模型变体,可以在设备上高效运行。
我们基于Gemini系列开发Med - Gemini模型,重点关注以下能力和方法:
1. 通过自训练和网络搜索集成实现先进推理:对于需要较少复杂推理的语言任务,如总结医学笔记和生成转诊信,我们通过微调Gemini 1.0 Pro模型引入了Med - Gemini - M 1.0。对于其他需要更先进推理的任务,我们通过使用自训练方法微调Gemini 1.0 Ultra模型引入了Med - Gemini - L 1.0,使模型能够有效地使用网络搜索。我们在推理时开发了一种新的不确定性引导搜索策略,以提高在复杂临床推理任务中的性能。
2. 通过微调定制编码器实现多模态理解:Gemini模型本质上是多模态的,并且在许多多模态基准测试中展示了令人印象深刻的零样本性能。然而,一些医学模态的独特性质和异质性需要进行微调才能实现最佳性能。我们通过在一系列多模态医学数据集上对Gemini 1.5 Pro进行微调,引入了Med - Gemini - M 1.5。我们还引入了Med - Gemini - S 1.0,并展示了Gemini模型使用专门的编码器适应新医学模态的能力,该模型基于Gemini 1.0 Nano构建。
3. 通过推理链实现长上下文处理:对于长上下文处理任务,我们使用具有长上下文配置的Med - Gemini - M 1.5。此外,我们还开发了一种受Tu等人启发的新的推理时推理链技术,以更好地理解长EHRs。
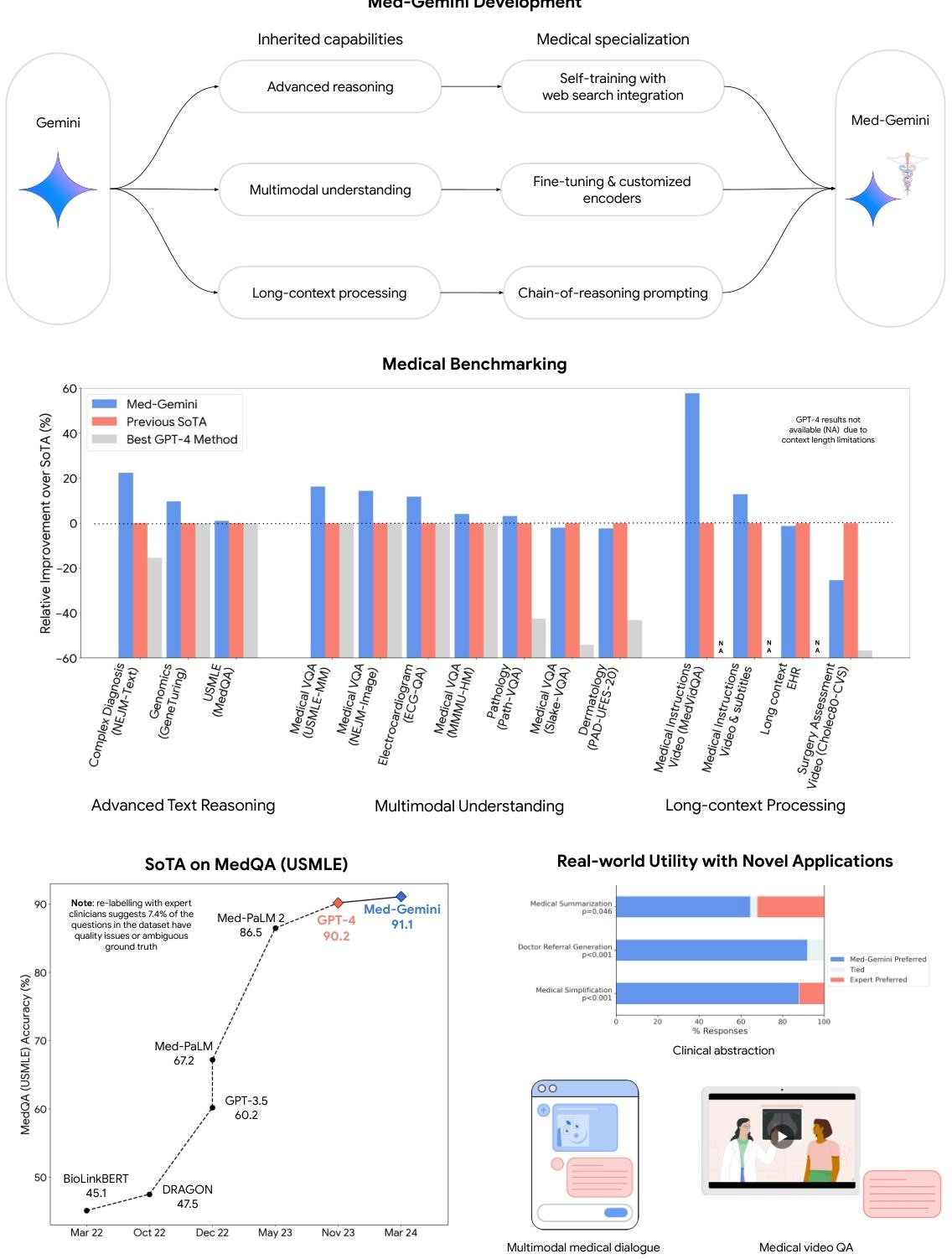
图1 | 我们的研究贡献概述。我们推出了Med - Gemini,这是一系列基于Gemini构建的高性能多模态医学模型。我们通过自训练和网络搜索集成来增强模型的临床推理能力,同时通过微调与定制编码器提升多模态性能。Med - Gemini模型在涵盖文本、多模态和长上下文应用的14个医学基准测试中,有10个达到了最先进(SoTA)水平,并且在所有可直接比较的基准测试中均超越了GPT - 4模型系列。柱状图展示了我们的模型相对于先前最先进方法在各个基准测试中的相对百分比提升。特别是在MedQA(美国医学执照考试,USMLE)基准测试中,我们达到了新的最先进水平,比我们之前最好的Med - PaLM 2模型大幅高出4.6%。此外,由专家临床医生对数据集进行重新标注后发现,7.4%的问题被认为不适合用于评估,因为这些问题要么缺少关键信息、答案错误,要么存在多种合理的解释。我们考虑到这些数据质量问题,以便更精确地描述我们模型的性能。Med - Gemini模型在多模态和长上下文能力方面表现卓越,在多个基准测试中达到最先进水平就是证明,这些测试包括从长时间去标识化健康记录中进行“大海捞针”式的检索任务,以及医学视频问答基准测试。除了基准测试,我们还通过对医学总结、转诊信生成和医学简化任务的定量评估,展示了Med - Gemini在现实世界中的潜力,在这些任务中我们的模型表现优于人类专家,此外还提供了多模态医学对话的定性示例。
2.1 通过自训练和网络搜索集成实现先进推理
临床推理是成功医疗的一项基本技能。虽然它是一个广泛的领域,有许多定义,但临床推理可以被概念化为一个迭代过程,在这个过程中,医生将自己的临床知识与初始患者信息相结合,形成病例表征。
然后,这个表征被用于指导进一步信息的迭代获取,直到达到置信阈值,以支持最终的诊断以及治疗和管理计划。在这个过程中,医生可能会对许多不同的输入进行推理,如患者症状、医学和社会经济病史、检查和实验室测试、先前对治疗的反应以及其他更广泛的因素,如流行病学数据。
此外,许多这些输入都具有时间成分,例如一系列不断变化的症状、随时间变化的实验室测量值,或者为监测健康而收集的各种时间数据,如心电图(ECGs)。医学知识是高度动态的,由于研究的快速发展,医学信息量的“翻倍时间”不断缩短。
为了确保其输出反映该领域的最新信息,大语言模型不仅需要具备强大的推理能力,还需要能够整合最新信息,例如从权威的网络来源获取信息。这种对外部知识的依赖有可能减少模型响应中的不确定性,但需要一种明智的信息检索方法。
我们对Gemini 1.0 Ultra进行医学微调的主要目标是提高模型进行最有帮助的网络搜索查询的能力,并在推理过程中整合搜索结果以生成准确答案。最终得到的模型是Med - Gemini - L 1.0。
指令微调已被证明可以提高大语言模型的临床推理能力。一个常用的指令调优数据集是MedQA,它由代表美国医学执照考试(USMLE)问题的多项选择题组成,旨在评估在各种场景下的医学知识和推理能力,涉及大量感兴趣的变量。
然而,MedQA只提供了多项选择题的正确答案,缺乏训练大语言模型在不同环境下进行临床推理所需的专家推理过程示范。因此,在MedQA上进行微调的大语言模型,如Med - PaLM 2,仍然存在显著的推理缺陷。再加上此类系统无法访问网络搜索,这导致了事实性错误,这些错误会在下游推理步骤中累积,或者导致模型在未考虑所有可能推理路径的情况下过早得出结论。
为基于语言的任务微调数据集,收集专家临床推理示范,包括专家如何明智地使用网络搜索等知识检索工具,既耗时又难以扩展。为了克服这个问题,我们通过如下所述的自训练生成了两个新的数据集:MedQA - R(推理),它通过合成生成的推理解释(即“思维链”,CoTs)扩展了MedQA;以及MedQA - RS(推理和搜索),它在MedQA - R的基础上增加了使用网络搜索结果作为额外上下文以提高答案准确性的指令。
为了给Med - Gemini - L 1.0的微调数据增加更多样性,我们还添加了一个长篇问答数据集,该数据集包含对MultiMedQA基准测试中HealthSearchQA、LiveQA和MedicationQA问题的260个由专家精心编写的长篇答案,以及一个医学摘要数据集,其中包含65个由临床医生撰写的来自MIMIC - III的医学笔记摘要。我们在表C1中概述了用于基于语言的指令微调数据集。
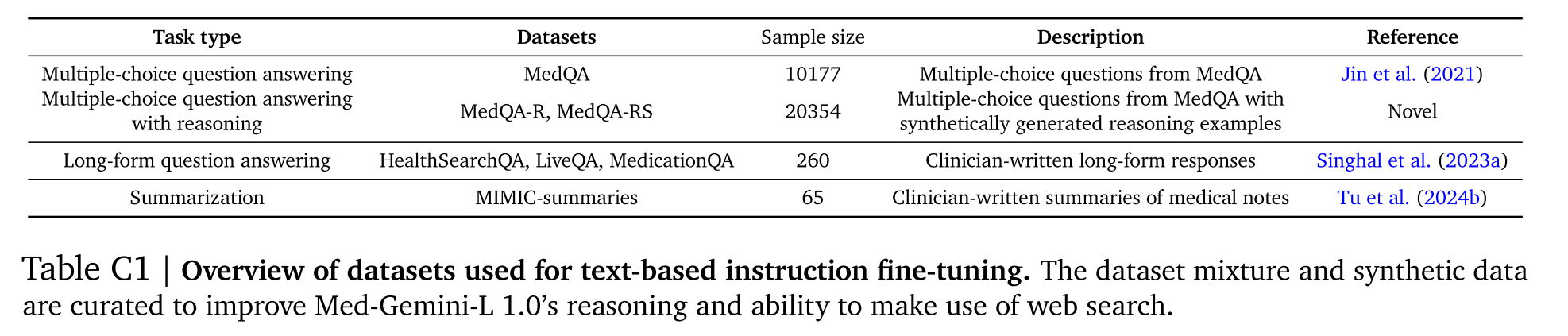
表C1|用于基于文本的指令微调的数据集概述。对数据集混合和合成数据进行管理,以提高Med-Gemini-L 1.0的推理能力和利用网络搜索的能力。
受最近自训练在合成数据生成方面取得成功的启发,我们实施了一个迭代数据生成框架,旨在精心策划使用网络搜索的高质量临床推理合成示例。
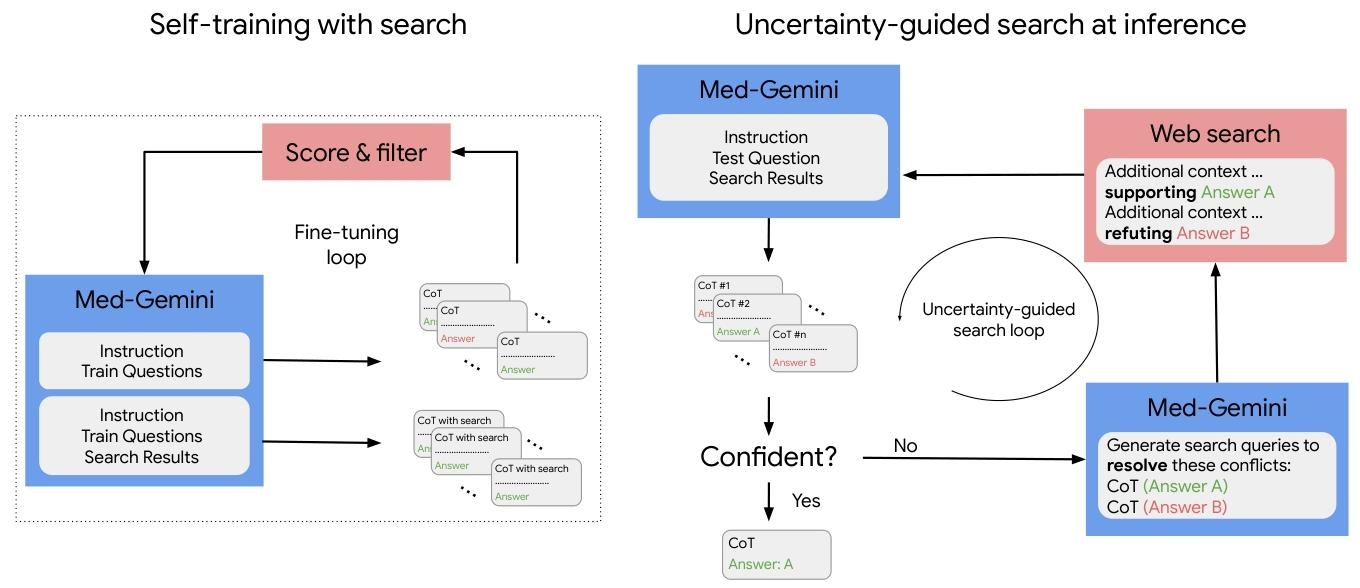
图2 | 自训练与搜索工具的使用。左图展示了用于对Med - Gemini - L 1.0进行微调的搜索自训练框架,以实现先进的医学推理和网络搜索的运用。该框架通过迭代生成有网络搜索和无网络搜索的推理响应(思维链,CoTs),提升模型利用外部信息得出准确答案的能力。右图展示了Med - Gemini - L 1.0在推理时的不确定性引导搜索过程。这个迭代过程包括生成多个推理路径、基于不确定性进行筛选、生成搜索查询以消除歧义,以及整合检索到的搜索结果以获得更准确的响应。
左侧:自训练与搜索
- Med - Gemini 模块:接收指令(Instruction)、训练问题(Train Questions) ,以及训练问题对应的搜索结果(Search Results)。
- 生成推理响应:模型生成两类推理响应(Chain of Thought, CoT),一类是无搜索的 CoT,另一类是有搜索的 CoT(CoT with search),每个 CoT 都对应一个答案(Answer)。
- 评分与筛选(Score & filter):对生成的推理响应进行评分和筛选,筛选后的结果进入微调循环(Fine - tuning loop),反馈给 Med - Gemini 模块,用于进一步训练模型,提升其利用外部信息得出准确答案的能力。
右侧:推理时的不确定性引导搜索
- 初始输入:Med - Gemini 模型接收指令(Instruction)、测试问题(Test Question)以及搜索结果(Search Results),生成多个推理路径(CoT #1, CoT #2 等 ),每个推理路径对应不同答案(如 Answer A、Answer B )。
- 置信度判断:判断模型对生成答案是否有足够的置信度(Confident? )。
- 是(Yes):直接输出推理路径和对应的答案(如 CoT 和 Answer: A )。
- 否(No):进入不确定性引导搜索循环(Uncertainty - guided search loop) 。模型根据相互冲突的推理路径生成搜索查询(Generate search queries to resolve these conflicts),发送到网络搜索(Web search)。网络搜索返回补充上下文信息,如支持答案 A 的信息和反驳答案 B 的信息等,这些信息再反馈给 Med - Gemini 模型,继续下一轮循环,直至模型对答案有足够置信度 。
如图2左面板所示,对于每个训练问题,我们生成两条推理路径,即思维链:一条不访问搜索中的外部信息,另一条在思维链生成过程中将搜索结果作为额外上下文进行整合。我们的搜索自训练框架包含以下关键要素:
网络搜索:对于每个问题,我们促使Med - Gemini - L 1.0生成有助于回答医学问题的搜索查询。然后,我们将搜索查询传递给网络搜索API并检索搜索结果。
上下文示范:对于每种推理响应路径类型,我们手动策划五个具有准确临床推理的专家示范作为种子,解释为什么正确答案是最合适的,而不是其他可能有效的答案。对于有搜索结果的问题示例,示范明确引用并引用搜索结果中的有用信息,以最好地回答问题。
生成思维链:我们促使Med - Gemini - L 1.0使用训练集上的上下文种子示范生成思维链。在对生成的思维链进行模型微调之前,我们过滤掉那些导致错误预测的思维链。
微调循环:在对生成的思维链进行Med - Gemini - L 1.0微调后,模型遵循专家示范的推理风格和搜索整合能力得到提高。然后,我们使用改进后的模型重新生成思维链,并迭代重复这个自训练过程,直到模型性能达到饱和。
下面我们提供一个MedQA - RS的输入提示示例,以及检索到的搜索结果和一个生成的思维链示例,该思维链随后用于进一步微调Med - Gemini - L 1.0。为简洁起见,我们在下面的示例中仅显示一个代表性的搜索结果我们设计了一种新颖的、基于不确定性引导的迭代搜索过程,以提高Med - Gemini - L 1.0在推理时的生成结果质量。
如图2右面板所示,每次迭代包含四个步骤:多推理路径生成、基于不确定性的搜索调用、不确定性引导的搜索查询生成,以及最后的搜索检索以扩充提示信息。需要注意的是,虽然推理时的不确定性引导搜索可能在多模态场景中也有益处,但我们目前仅将这种方法应用于纯文本基准测试,多模态方面的探索留待未来研究。
1. 多推理路径生成:给定一个包含医学问题的输入上下文提示,我们让Med - Gemini - L 1.0生成多个推理路径。在第一次迭代时,提示仅包含指令和问题。在后续迭代中,提示还包括下面步骤(4)中的搜索结果。
2. 基于不确定性的搜索调用:根据步骤(1)中生成的多个推理路径,我们基于答案选择分布的香农熵定义一个不确定性度量。具体来说,我们通过将每个答案选择的出现次数除以总响应次数来计算其概率,并基于这些概率应用熵公式(Horvitz等人,1984)。高熵(模型响应在不同答案选择中分布更均匀)表示较高的认知不确定性。如果一个问题的不确定性高于定义的阈值,我们就执行步骤(3)和(4)中的不确定性引导搜索过程;否则,将多数投票的答案作为最终答案返回。
3. 不确定性引导的搜索查询生成:根据步骤(1)中相互冲突的响应,我们促使Med - Gemini - L 1.0生成三个有助于解决冲突的搜索查询。我们基于先前生成但相互冲突的响应来生成查询,目的是检索能够直接解决模型对该问题不确定性的搜索结果。
4. 搜索检索:生成的查询随后被提交到网络搜索引擎,检索到的结果被整合到Med - Gemini - L 1.0的输入提示中,用于下一次迭代,然后再回到步骤(1)。用搜索结果扩充提示信息,能使模型通过考虑从网络搜索中获得的外部相关见解来优化其响应。
2.2 通过微调与定制编码器实现多模态理解
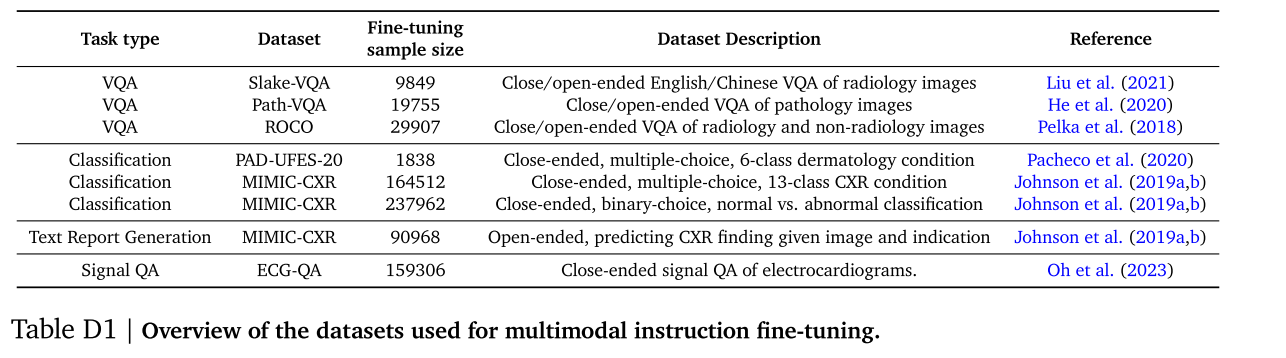
为了将Gemini的多模态推理和对话能力专门应用于医学领域,我们按照Tu等人、Yu等人和Alayrac等人先前工作中的类似流程,在一系列特定领域的多模态任务上对Gemini进行指令微调。我们使用了六个数据集中的八个多模态任务,具体内容见表D1。附录D.1中提供了数据集的详细描述。
我们使用来自MultiMedBench的四个图像到文本数据集,包括Slake - VQA、Path - VQA、MIMIC - CXR、PAD - UFES - 20,以及Radiology Objects in COntext(ROCO)数据集。Slake - VQA和Path - VQA分别包括放射学和病理学领域的开放式和封闭式视觉问答任务。ROCO包含跨越多种成像模态(包括计算机断层扫描(CT)、超声、X射线[胸部X射线(CXR)、荧光透视、乳腺摄影、血管造影]、正电子发射断层扫描(PET)和磁共振成像(MRI))的放射学图像字幕任务。PAD - UFES - 20是一个特定领域的数据集,具有诊断标签和患者临床信息,用于皮肤病图像分类。MIMIC - CXR是一个放射学数据集,由胸部X射线、相应的文本报告以及一组使用CheXpert标注器得出的表示13种异常放射学状况(如肺炎)的离散标签组成。我们使用这个数据集来制定胸部X射线报告生成和图像分类任务,用于微调。对于每个任务,我们通过提供特定任务的指令来微调Gemini 1.5 Pro,如图D1所示。每个任务的混合比例大致与每个数据集中的训练样本数量成比例。最终得到的模型是Med - Gemini - M 1.5。
我们预计整合各种与健康相关的信号将显著增强医学模型和治疗决策。这些信号包括来自消费级可穿戴设备的数据(例如长期心率测量、活动水平)、基因组信息、营养数据(例如餐食图像)以及环境因素(例如空气质量测量)。作为概念验证,我们扩展了Med - Gemini处理原始生物医学信号的能力。具体而言,我们通过使用基于Flamingo的交叉注意力机制为Gemini 1.0 Nano添加一个专门的编码器,开发了Med - Gemini - S 1.0,使其能够直接以原始12通道心电图(ECG)波形作为输入来回答问题。我们使用来自ECG - QA数据集的一部分带标签的ECG示例,并按照图D1中的指令将任务制定为封闭式问答。
2.3 通过指令提示与推理链实现长上下文处理
医学领域的许多应用需要分析大量信息,并具备识别该领域细微细节的专业知识。如前所述,Gemini模型具有突破性的长上下文能力。我们通过为两种不同的医学应用有意义地处理大量细粒度信息,来评估Med - Gemini - M 1.5在医学相关长上下文方面的性能:一个是从冗长的电子健康记录(EHR)笔记和记录中进行“大海捞针”式的检索任务;另一个是需要理解医学视频的任务。我们描述了各种提示策略和推理链,以实现对信息的准确回忆和推理。
从长EHR笔记和记录中搜索和检索临床相关信息是患者护理中一项常见且重要的任务,但必须以高精度和高召回率进行,以提高临床医生的工作效率并减少工作量。临床医生经常整理患者历史病情、症状或手术的摘要(即“问题列表”),对于病历冗长的患者来说,这既耗时又具有挑战性。电子健康记录中存在多个因素阻碍了有效信息检索。
首先,经典的查询扩展和匹配机制由于相似分类法的病症之间的文本相似性以及电子健康记录中使用的多样化信息模型(例如“Miller”与“Miller Fisher综合征”、“糖尿病肾病”与“糖尿病”)而受到限制。电子健康记录系统内部和之间的词汇不一致会带来问题,包括医学术语编码方式的差异,如首字母缩写(“rx”与“prescription”)、拼写错误或同一病症的同义词。
其次,电子健康记录通常包含异构数据结构,例如清单式数据模板:“[ ]咳嗽 [x]头痛”,其中提及并不总是表示存在某种医学病症。第三,提及的上下文会影响其解释。例如,在患者的“家族病史”和“既往病史”中提及相同病症,可能对患者的护理有不同的解释和影响。最后,医学笔记中的多义首字母缩写可能导致误解。
这些挑战促使需要人工智能系统来解决从长电子健康记录中进行上下文感知检索细微或罕见病症、药物或手术提及的任务,这是评估Med - Gemini在医学领域实用性的一个实际基准。我们基于先前的工作设置了长上下文电子健康记录理解任务,在该任务中,我们从MIMIC - III中精心挑选了一组长且具有挑战性的电子健康记录案例,并针对一系列电子健康记录笔记和记录,制定了一个关于细微医学问题(病症/症状/手术)的搜索检索任务,模拟临床上相关的“大海捞针”问题。附录E.1和第3.3节中描述了数据集和任务策划过程的详细信息。
为了评估Med - Gemini - M 1.5的长上下文检索和推理能力,我们在每个示例中聚合单个患者多次就诊的电子健康记录笔记,并利用模型的长上下文窗口,采用两步推理链方法(仅使用上下文学习)。在第一步中,我们促使Med - Gemini - M 1.5通过一次示范检索与给定问题(病症/症状/手术)相关的所有提及(证据片段)。在第二步中,我们进一步促使Med - Gemini - M 1.5根据检索到的提及来确定给定问题实体的存在与否。指令提示的详细信息见图8和第3.3节。

图8| Med-Gemini-M 1.5在长EHR理解上的长上下文能力示例(MIMIC-III大海捞针)。Med-Gemini-M 1.5执行两步流程,根据患者的大量EHR记录确定患者是否有特定疾病史。(a)第1步(检索):Med-Gemini-M 1.5识别EHR注释中所有提及的“体温过低”,提供直接引用[例如,“+汗。口腔温度93.7.转至重症监护病房(MICU)"]并记录每次提及的ID。(b)第2步(确定是否存在):Med-Gemini-M 1.5然后评估每个检索到的提及的相关性,将其分类为明确确认、强烈指示或体温过低的相关提及。基于此分析,模型得出结论,患者确实有体温过低的历史,为决策提供了清晰的推理。
我们使用先前基于启发式的注释聚合方法作为与Med - Gemini - M 1.5进行比较的基线方法。这种基于启发式的方法需要大量的手动特征工程,以从一组医疗记录中确定问题(病症/症状/手术)的存在。这是一个依赖本体的多步骤过程,包括一个注释步骤,用于标记每个电子健康记录笔记中的问题;一个基于规则的选择步骤,用于选择置信度高的问题实体提及;以及另一个基于规则的聚合步骤,用于汇总所有选定的问题提及以得出最终结论。需要注意的是,手动制定的聚合规则只能有限地覆盖所有可能的病症,因此需要额外的工程工作来将覆盖范围扩展到新的病症。
为了策划一个“大海捞针”式的评估基准,我们从电子健康记录集合中选择在聚合步骤中仅找到一个证据片段的医学病症。需要注意的是,电子健康记录中提及某病症并不总是意味着患者患有该病症。这个任务使我们能够评估Med - Gemini - M 1.5识别罕见记录和细微病症、症状和手术的能力,以及准确全面地推断它们是否存在的能力。
对手术和操作视频的理解是医学人工智能领域一个非常活跃的研究课题。计算机视觉在语义分割、目标检测与跟踪以及动作分类方面的前沿进展,催生了新的临床应用,如手术阶段识别、工具检测与跟踪,甚至手术技能评估。
有限的模型上下文窗口阻碍了视觉语言模型捕捉视频中的长程依赖关系和复杂关系。Gemini的长上下文能力为医学视频理解提供了潜在的突破。通过处理整个视频输入,Med - Gemini - M 1.5能够识别视觉模式,并理解跨越较长时间框架的事件之间的动作和关系。
为了使Med - Gemini - M 1.5能够理解医学视频,我们采用零样本提示,并结合特定任务的指令,如图10、图9和图11所示。目标是使模型能够分析语言查询和视频内容,并执行与输入医学视频相关的给定任务,即在医学视觉答案定位(MVAL)任务中定位与查询匹配的相关视觉片段,或在安全关键视图(CVS)评估任务中识别视频帧中的手术视图。附录E.1和第3.3节中描述了医学视频数据集和评估指标的更多详细信息。

图10| Med-Gemini-M 1.5在医学教学视频中的长上下文功能示例。Med-Gemini-M 1.5分析来自医学视频问答(MedVidQA)数据集的视频,以回答有关缓解小腿劳损的特定问题。该模型识别相关的视频片段(02:22-02:58),其中理疗师解释并演示针对该状况的锻炼。MedVidQA地面真实时间跨度注释为02:22-03:00。
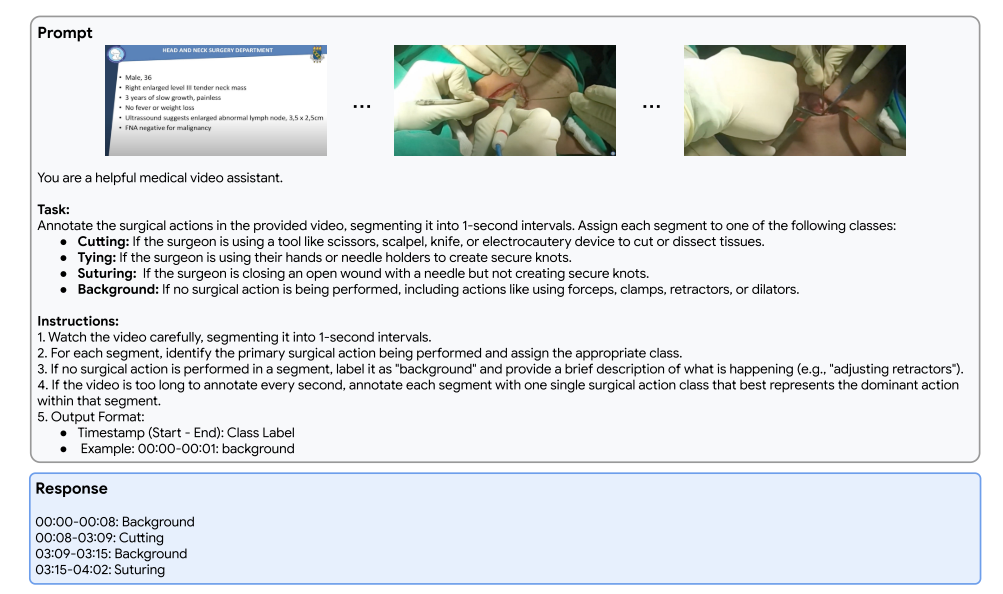
图11| Med-Gemini-M 1.5在手术动作视频跨度预测方面的长上下文能力示例。Med-Gemini-M 1.5分析来自手术动作识别(AVOS)数据集的视频,以注释视频中的手术动作。它将视频分段并基于正在执行的手术动作(例如,切割、打结、缝合),或者如果没有动作发生,则将其分类为背景。本例的地面真实AVOS注释为:00:00 - 00:11:背景,00:12 - 03:05:切割,03:05 - 03:15:背景,03:15 - 04:02:缝合。
3 评估
我们展示了涵盖(1)基于文本的推理、(2)多模态以及(3)长上下文处理任务的评估基准,展示了Med - Gemini在医学领域广泛能力的性能表现。
3.1 基于文本任务的先进推理评估
我们在三个评估临床推理和使用网络搜索检索信息以减少不确定性能力的文本基准上,评估Med - Gemini - L 1.0的医学推理能力:
- MedQA(USMLE):这是一个封闭式多项选择(4个选项)数据集,包含1273个由Jin等人整理的USMLE风格测试题。
- NEJM临床病理会议(NEJM CPC):该数据集包含《新英格兰医学杂志》(NEJM)中的复杂诊断案例挑战,由McDuff等人整理。
- GeneTuring:一个包含600个开放式/封闭式问答对的数据集,用于评估大语言模型的基因组知识(Hou和Ji,2023)。
对于MedQA,我们遵循Singhal等人描述的输入 - 输出格式和评估方法,使用预测准确率作为指标。在推理时,我们进行四轮不确定性引导搜索。此外,我们邀请美国的董事会认证初级保健医生(PCPs)对MedQA测试集进行重新标注。这使我们能够识别出缺少信息(如图表或图形)的问题、标注错误的问题,以及其他可能存在多个正确答案的模糊问题。总体而言,这有助于我们更好地描述我们在MedQA(USMLE)上的性能。关于这个评级任务的更多详细信息,可以在附录C.2中找到。
NEJM CPC评估是一个开放式诊断任务。输入是一个基于文本的、具有挑战性的临床病理案例(CPC)报告,输出是一个鉴别诊断列表,包含10个潜在诊断。我们使用识别给定具有挑战性案例正确诊断的前1名和前10名准确率,并遵循McDuff等人的相同提示程序。在推理时,我们进行一轮不确定性引导搜索。
GeneTuring由12个模块组成,每个模块包含50个开放式或封闭式问答对。我们使用预测准确率作为评估指标,每个模块的评估方法和评分技术遵循Hou和Ji中描述的方法。具体来说,我们在数值评估中排除模型输出未直接回答或未承认局限性(即弃权)的情况。在推理时,我们同样进行一轮不确定性引导搜索,与NEJM CPC评估类似。
除了这些基准测试,我们还在三个需要长篇文本生成的具有挑战性的实际用例上进一步评估Med - Gemini - M 1.0。为此,我们进行了一项专家评估,由一组临床医生通过并排盲法偏好比较,将我们模型的响应与其他人类专家的响应进行比较(附录C.4中提供了更多详细信息):
- 医学总结:根据去标识化的病史和体格检查(H&P)笔记生成就诊后总结(AVS)。AVS是患者在医疗预约结束时收到的结构化报告,用于总结和指导他们的治疗过程。
- 转诊信生成:根据包含转诊建议的去标识化门诊医疗笔记,生成转诊信给另一位医疗服务提供者。
- 医学简化:根据医学系统评价的技术摘要生成通俗易懂的语言摘要(PLS)。PLS应该用通俗易懂的英语撰写,大多数没有大学教育背景的读者都能理解。
3.2 多模态能力评估
我们在七个多模态视觉问答(VQA)基准上评估Med - Gemini。对于分布内评估,我们选择了在Med - Gemini指令微调中使用的四个医学专科数据集:用于Med - Gemini M 1.5的PAD - UFES - 20(皮肤病学)、Slake - VQA(英语和中文放射学)和Path - VQA(病理学),以及用于Med - Gemini S 1.0的ECG - QA(心脏病学)。
我们还纳入了三个跨专科基准,用于衡量Med - Gemini的开箱即用性能:NEJM图像挑战、USMLE - MM(多模态)和MMMU - HM(健康与医学)数据集。这些数据集在任何训练或微调过程中均未使用。在此,我们主要评估未进行任何多模态微调的Med - Gemini - L 1.0模型。
值得注意的是,PAD - UFES - 20、NEJM图像挑战、USMLE - MM数据集以及MMMU - HM中的大多数问题都是封闭式VQA,即在VQA设置中的多项选择题。选定数据集的概述见表D2,附录D.1和D.2中提供了更多详细信息。
我们报告所有封闭式多项选择VQA任务的预测准确率,包括NEJM图像挑战、USMLE - MM和PAD - UFES - 20的6类皮肤状况分类。我们还遵循Yue等人的评估设置,报告MMMU - HM的准确率。对于ECG - QA,我们按照Oh等人的方法使用精确匹配准确率。对于开放式VQA任务(Slake - VQA和Path - VQA),我们按照Tu等人的方法使用标记级F1分数。
我们进一步在皮肤病学和放射学两个专科的多模态医学诊断对话中,通过专家临床医生对示例对话的定性评估,展示了Med - Gemini - M 1.5的多模态能力。我们注意到,这些展示表明了“可能实现的成果”,但在考虑将其部署用于像辅助临床医生诊断这样对安全性要求极高的用例之前,还需要进行大量的进一步研究和验证。
3.3 视频和EHR任务的长上下文能力评估
我们考虑三个任务来展示Med - Gemini - M 1.5无缝理解和推理长上下文医学信息的能力(表E1,附录E.1中有详细信息):
- 长非结构化EHR笔记理解
- 医学教学视频问答
- 手术视频的安全关键视图(CVS)评估
对于长上下文电子健康记录理解任务,我们策划了一个MIMIC - III“大海捞针”任务,目标是在大量电子健康记录临床笔记中检索任何提及给定医学问题(病症/症状/手术)的相关文本片段,并通过对检索到的证据进行推理来确定该病症的存在与否。具体而言,我们策划了200个示例,每个示例由从44名具有长期病史的独特ICU患者中选择的一组去标识化电子健康记录笔记组成,遵循以下标准:
记录长的患者:超过100份医疗笔记(不包括结构化电子健康记录数据)。每个示例的长度在200,000到700,000字之间。
在每个示例中,病症在所有电子健康记录笔记集合中仅被提及一次。
每个样本有一个感兴趣的单一病症。
每个样本的真实标签是一个二进制变量,表示给定的感兴趣问题实体是否存在,由三名医生评分者的多数投票得出。在200个测试示例中,阳性案例和阴性案例的数量分别为121和79。
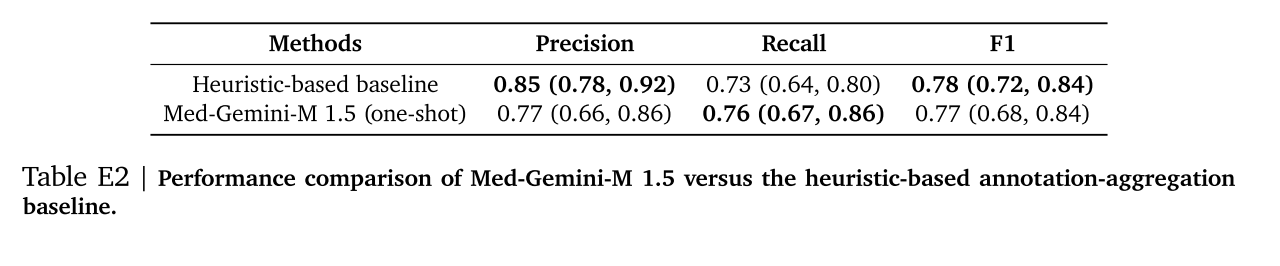
我们将Med - Gemini - M 1.5的一次性上下文学习性能与基于启发式的注释聚合基线方法在精度和召回率方面进行比较。
我们使用三个医学视频任务,在视频问答设置中定量评估Med - Gemini - M 1.5的长上下文性能:两个使用医学教学视频问答(MedVidQA)数据集的医学视觉答案定位(MVAL)任务,以及在Cholec80 - CVS数据集上的安全关键视图(CVS)评估任务。
MVAL的目标是根据自然语言描述(查询)在给定视频输入中识别特定的视频片段。对于MVAL,我们在MedVidQA测试集上对两个视频跨度预测任务进行基准测试,一个使用视频输入和字幕文本,另一个仅使用视频输入。我们遵循Gupta等人和Li等人的方法,使用阈值为0.3、0.5、0.7的交并比(IoU)和平均交并比(mIoU)作为视频跨度预测任务的评估指标。IoU和mIoU用于衡量真实跨度与预测跨度的重叠程度。
我们评估Med - Gemini - M 1.5在评估腹腔镜胆囊切除术(一种切除胆囊的微创手术)视频中安全关键视图(CVS)方法实现情况的长上下文能力。CVS是一种推荐的协议,用于安全识别胆囊管和胆囊动脉,以尽量减少胆管损伤(BDI)的风险,胆管损伤是一种严重的损伤,会导致术后发病率和死亡率上升、长期生存率降低以及对生活质量的影响。
我们在公开的Cholec80数据集和Cholec80 - CVS视频剪辑注释上评估CVS评估任务。具体来说,对于Cholec80数据集中的每个手术视频,Cholec80 - CVS数据集提供了完整视频内符合至少一个CVS标准的视频剪辑注释。
每个这样的视频剪辑针对三个CVS标准中的每一个都被标注为0、1或2分。给定视频剪辑中的所有帧都被认为具有相同的注释。我们评估模型根据整个视频剪辑预测哪些CVS标准得到满足的能力。
然后,我们计算模型答案相对于Cholec80 - CVS注释在572个带注释视频剪辑上的平均准确率。关于CVS任务的更多详细信息可以在附录E.1中找到。
此外,为了展示Med - Gemini - M 1.5在捕捉手术视频中手术动作的实际能力,我们使用来自Annotated Videos of Open Surgery(AVOS)数据集的示例对手术动作识别任务进行定性评估,该数据集是一个上传到YouTube平台的开放手术视频集合。
4 结果
如前所述,我们在广泛的医学基准测试中对Med - Gemini的先进推理、多模态和长上下文能力进行了定量和定性评估。据我们所知,这项工作中考虑的任务范围和多样性是医学大语言模型中最全面的。此外,我们对Med - Gemini的评估不仅限于模型能力的基准测试,还扩展到了反映现实世界实用性的任务,如医学总结、多模态对话和手术视频理解。
4.1 Med - Gemini在基于文本的任务中展示了先进的推理能力
如表1所示,Med - Gemini - L 1.0在MedQA(USMLE)上的准确率达到91.1%,创造了新的最先进水平,比我们之前的Med - PaLM 2高出4.5%,比最近使用复杂、专门提示增强的GPT - 4(MedPrompt)高出0.9%。与MedPrompt不同,我们的原则性方法在不确定性引导的框架中利用通用网络搜索,并且可以轻松扩展到MedQA之外的更复杂场景。
作为我们搜索集成泛化的证明,在NEJM CPC复杂诊断挑战基准测试中,Med - Gemini - L 1.0在Top - 10准确率上比我们之前的最先进模型AMIE(其本身优于GPT - 4)高出13.2%,如图3a所示。
同样的搜索策略在基因组学知识任务中也很有效,如表1所示。Med - Gemini - L 1.0在包括基因名称提取、基因别名、基因名称转换、基因位置、蛋白质编码基因、基因本体和转录因子调控在内的七个GeneTuring模块上优于Hou和Ji中报告的最先进模型。我们还在图3b中比较了模型在12个模块上的弃权情况。值得注意的是,GeneGPT通过专门的网络API取得了更高的分数,而我们的比较主要集中在Hou和Ji中与我们模型类似使用通用网络搜索的先前模型。
为了了解自训练和不确定性引导搜索对性能的影响,我们比较了Med - Gemini - L 1.0在有和没有自训练情况下的性能,以及在MedQA(USMLE)中不同轮次不确定性引导搜索的性能。如图4a所示,Med - Gemini - L 1.0的性能在自训练后有显著提升(准确率提高了3.2%),并且随着搜索轮次的增加,从87.2%提高到了91.1%。同样,对于NEJM CPC基准测试,图3a显示在推理时添加搜索后,Top - 10准确率提高了4.0%。在附录C.3中,我们还按四个专科展示了NEJM CPC上的性能。
MedQA(USMLE)是评估大语言模型在医学领域能力的一个流行基准。然而,一些MedQA测试问题存在信息缺失,如图表或实验室结果,以及可能过时的正确答案。为了解决这些问题,我们对MedQA(USMLE)测试集进行了全面重新标注。具体来说,我们招募了至少三名美国医生对每个问题进行重新注释,要求他们回答问题并评估提供的正确答案。我们还要求他们识别问题中是否有任何缺失信息。根据Stutz等人的方法,我们通过对每个问题由三名评分者组成的委员会进行投票引导,来确定由于信息缺失或标注错误而应排除的问题。我们还将允许多个正确答案的问题识别为模糊问题(更多细节可以在附录C.2中找到)。
图4b显示,在投票引导的委员会中,平均有3.8%的问题存在信息缺失,这是根据委员会的一致投票得出的。此外,2.9%的问题可能存在标注错误。另有0.7%的问题是模糊的。排除这些问题得到了较高的评分者间一致性支持,分别为94%、87.6%和94.6%。重要的是,Med - Gemini - L 1.0的错误在很大程度上可以归因于这些问题;我们基于熵的不确定性分数在这些问题上也往往更高(t检验,\(p值 = 0.033\))。过滤这两种类型的问题后,准确率从91.1%提高到91.8%±0.2%。使用多数投票而不是一致投票,通过丢弃高达20.9%的不确定问题,进一步将准确率提高到92.9%±0.38%。
4.1.1 长篇医学文本生成的性能
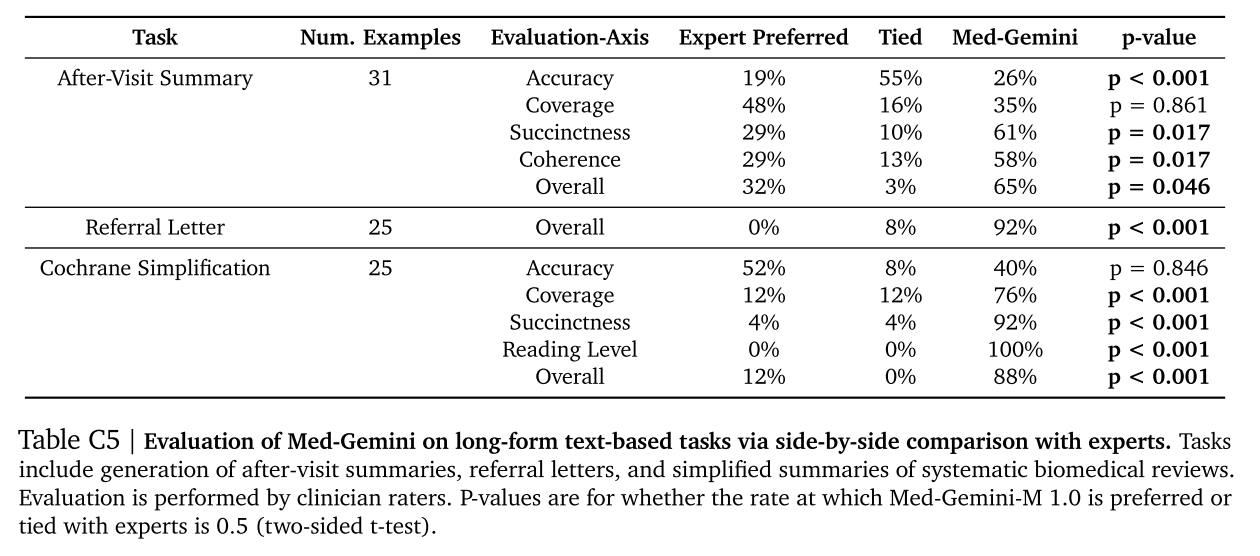
Med - Gemini - M 1.0展示了为三个具有挑战性的现实世界用例生成长篇文本的能力,即就诊后临床总结、医生转诊信生成和医学简化。在并排比较中,临床医生评分者在超过一半的时间里认为Med - Gemini - M 1.0的回答与专家回答一样好或更好,涵盖这三个任务(图5)。有关更多任务细节,请参见附录C.4。值得注意的是,在转诊信生成任务中,模型生成的信件在所有评估样本中都与专家的信件相当或更受青睐。
4.2 Med - Gemini在各种任务中展示了多模态理解能力
我们的Med - Gemini模型在七个医学多模态基准测试中优于或与最先进方法表现相当(见表2)。我们在图D1中提供了多模态任务的代表性输入和输出示例以作说明。
具体来说,Med - Gemini - L 1.0在三个分布外封闭式VQA任务(NEJM图像挑战、多模态USMLE样本问题(USMLE - MM)和MMMU(健康与医学)子集(MMMU - HM))上达到了最先进水平,分别比GPT - 4V高出8.7%、13.1%和2.6%。同时,Med - Gemini - M 1.5在Path - VQA上的标记F1分数比我们之前的多模态模型Med - PaLM M高出2.0%,Med - Gemini - S 1.0在ECG - QA(Oh等人,2023)的心电图问题类型上的宏观平均准确率比之前的最先进模型(GPT - 4与SE - WR)高出6.1%。与之前的最先进方法(Med - PaLM M)相比,Med - Gemini - M 1.5在Slake - VQA和PAD - UFES - 20上也表现出色,但未达到最先进水平。
值得注意的是,我们在两种不同的数据分割设置下评估了PAD - UFES - 20。我们首先在Med - PaLM M分割(图像级分割)上进行评估,以便与之前的最先进方法进行直接、公平的比较。此外,我们还报告了模型在新的分割(患者级分割)上的性能(表2)。
对于USMLE - MM,我们的模型在USMLE第1步问题(\(n = 19\))、第2步问题(\(n = 14\))和第3步问题(\(n = 13\))上的准确率分别达到89.5%、92.9%和100.0%。
总体而言,在这七个基准测试中,Med - Gemini比GPT - 4V的平均相对优势提高了44.5%。需要注意的是,对于USMLE - MM、PADS - UFES - 20和Slake - VQA数据集,我们使用公共API和用于相应Med - Gemini模型的相同提示来报告重现的GPT - 4V结果。
4.2.1 多模态对话能力的预展示
为了超越多模态基准测试,我们通过两个专科的假设性多模态医学对话展示了Med - Gemini在未来现实世界中的潜在实用性。
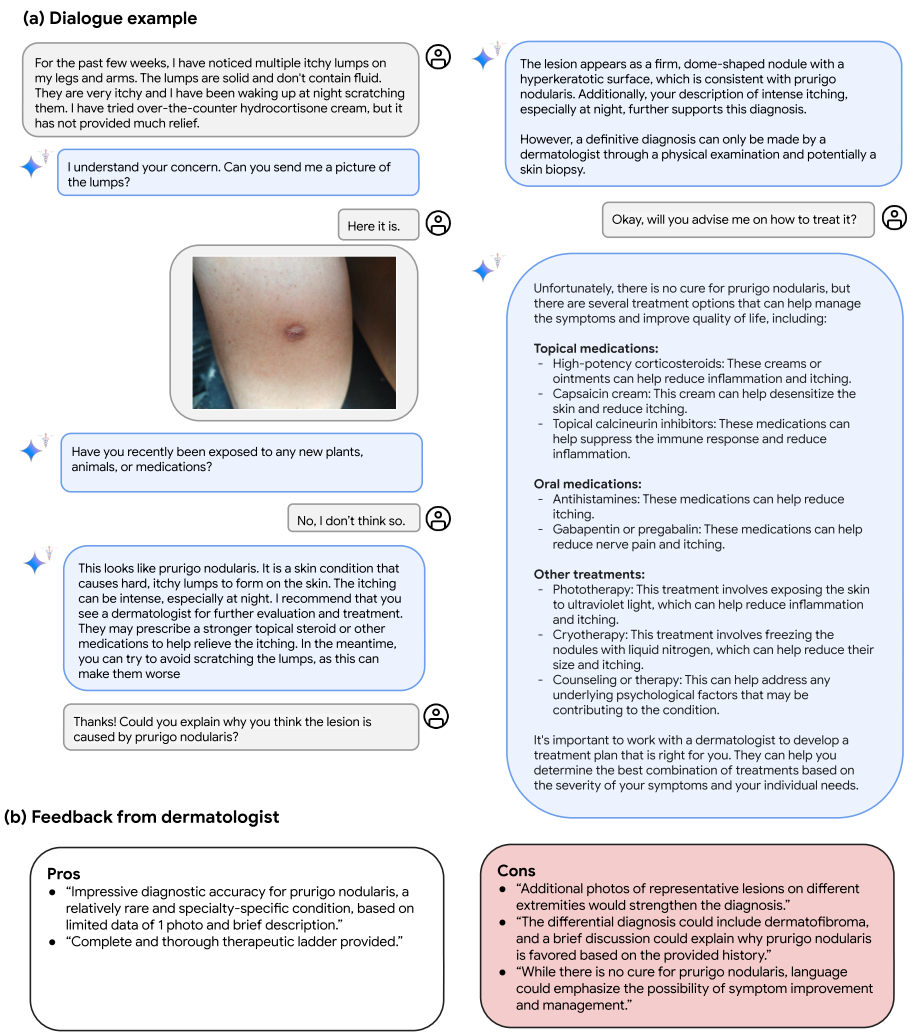
图6|在皮肤科环境中使用Med-Gemini-M 1.5进行假设多模式诊断对话的示例。(a)用户与我们的多模式模型Med-Gemini-M 1.5交互,基于来自SCIN的病例充当患者(Ward等人,2024),不包括在微调混合物中的外部数据集。如果没有大量的进一步研究和开发,该系统将不适合用于现实世界的诊断任务。尽管如此,这个例子表明了未来的初步承诺,如何从原始的双子座模型继承的会话能力和新获得的多模态医学知识的微调可以潜在地使丰富的多轮诊断对话的属性。在这种互动中,Med-Gemini-M 1.5在没有提供图片时要求提供图片(多模式信息采集),有效地得出正确的诊断(开放式诊断),通过整合相关视觉特征和其他收集的患者症状(可解释性)来解释推理,回答有关治疗方案的问题,同时适当地推迟专家的最终决定。(b)显示从皮肤科医生收集的反馈,以评估定性的诊断对话的内容,特别是要求他们对积极和消极方面的评论。
图6展示了一个分布外的场景,其中皮肤病学图像来自一个未在多模态微调混合数据集中使用的数据集。用户首先向Med - Gemini - M 1.5询问腿部和手臂上的瘙痒肿块;我们的模型随后要求用户分享肿块的图像;在用户提供可疑病变的图像后,模型提出后续问题,并继续正确诊断为结节性痒疹,并推荐下一步措施和潜在的治疗方案。
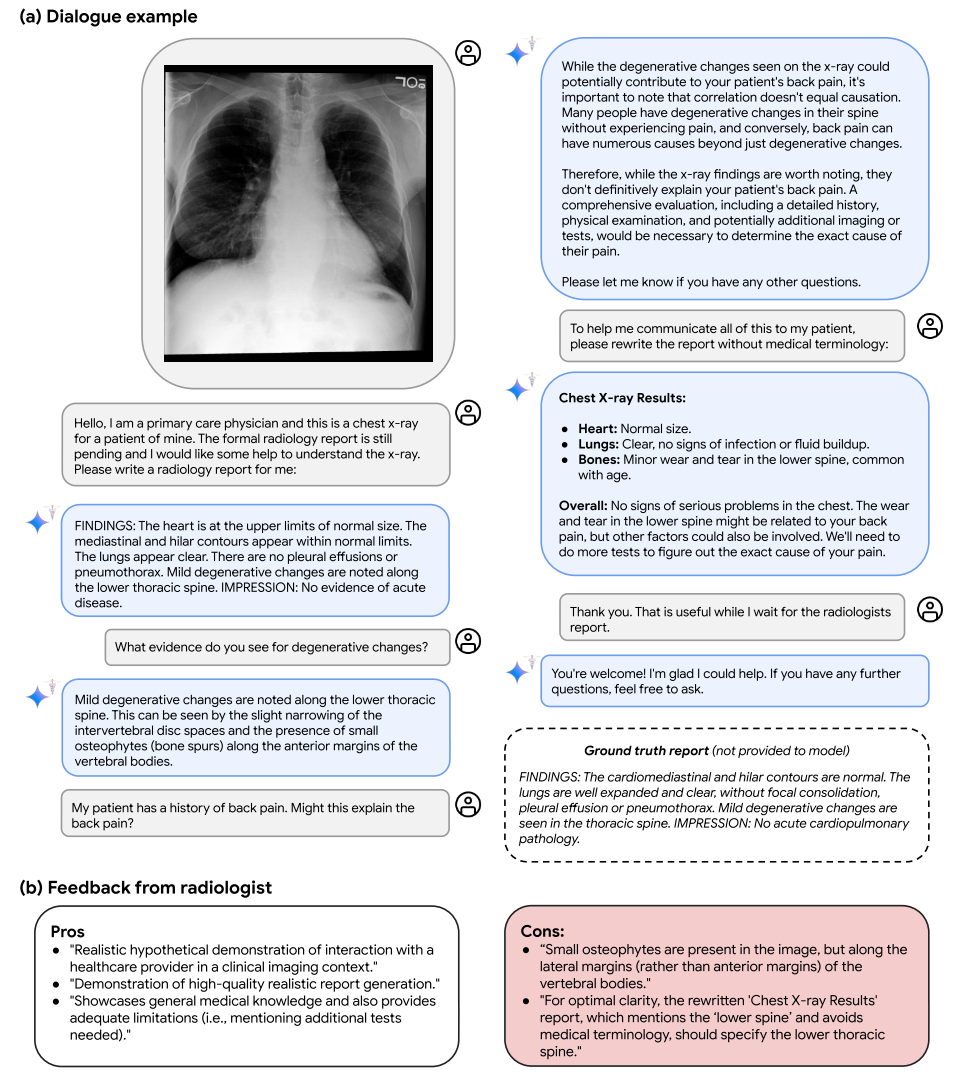
图7|在放射学设置中与Med-Gemini-M 1.5进行假设的多模式诊断辅助对话的示例。(a)在这种互动中,Med-Gemini-M 1.5展示了其分析胸部X射线(CXR)并与初级保健医生进行假设现实对话的能力。如上所述,Med-Gemini-M 1.5不适合在未经进一步研究的情况下实际使用。然而,该实施例证明了最初的希望,其中Med-Gemini-M 1.5识别沿着脊柱的轻度退行性变化沿着,并且可以回答关于导致该发现的推理的问题,证明关于退行性椎间盘疾病的一般医学知识,并且区分与患者背痛史相关的相关性和因果关系。最后,在本例中,Med-Gemini-M 1.5能够以外行的语言解释其发现,证明其在临床环境中促进患者理解和沟通的潜力。提供了本CXR的基础事实报告。(b)来自放射科医师的关于该放射学对话质量的反馈。
在图7中,我们展示了一个放射学对话示例,示例图像来自MIMIC - CXR数据集的测试集。Med - Gemini - M 1.5展示了与初级保健提供者互动以分析胸部X射线、识别退行性椎间盘疾病、讨论与患者背痛病史之间的因果关系和相关性、建议进一步检查以确定背痛原因,并使用通俗易懂的语言生成报告以促进患者理解和沟通的能力。我们观察到Med - Gemini - M 1.5的回答会因提示而异(例如,对于某些提示,报告可能不会列出轻微的退行性变化,特别是如果提示关注其他解剖特征)。对Med - Gemini - M 1.5多模态对话能力和可变性的全面量化超出了本工作的范围,但这些定性示例仍然说明了Med - Gemini - M 1.5支持基于多模态来源的医学知识对话的能力,这对于考虑用户 - AI和临床医生 - AI交互的应用来说是一个潜在有用的属性。对这些用例的现实世界探索需要大量的进一步开发和验证,以基于这些早期有前景的迹象进行拓展。
4.3 Med - Gemini在长EHR和视频任务中展示了长上下文处理能力
最后,我们通过从长EHR中进行“大海捞针”式的医学病症检索任务以及三个医学视频任务(两个MAVL和一个手术视频的CVS评估)评估Med - Gemini - M 1.5的长上下文能力。
我们展示了Med - Gemini - M 1.5在长EHR笔记中正确识别罕见和细微问题实体(病症/症状/手术)的实用性。Med - Gemini - M 1.5与基线方法之间的平均精度和召回率如表3所示(置信区间见表E2)。令人鼓舞的是,我们观察到Med - Gemini - M 1.5的一次性能力与经过精心调整的、高度依赖任务的基于启发式的注释聚合基线方法相当。Med - Gemini - M 1.5处理长文档或记录的上下文学习能力可以轻松推广到新的问题场景,而无需大量的手动工程。我们在图8中提供了使用的提示示例以及我们模型的响应。我们尝试在这个任务上对GPT - 4进行基准测试,但该数据集中的平均上下文令牌长度远远超过了公共API支持的最大上下文窗口。
Med - Gemini - M 1.5在两个MedVidQA MAVL任务(一个同时使用视频和字幕,另一个仅使用视频)上也达到了最先进的性能,优于需要大量定制调整的非大语言模型的最先进模型。我们注意到MedVidQA中有7个问题由于YouTube视频访问问题(私人视频、已删除视频)无法回答。因此,我们的结果是基于其余148个问题报告的。详细信息见表3。我们在图10中提供了使用的提示示例以及我们模型的响应。在评估MedVidQA时,我们还观察到嵌入的字幕可以显著帮助模型理解。未来的研究可以探索如何优化使用多模态视频数据,包括图像、文本和音频,以进一步提高视频理解能力。我们尝试在这些任务上对GPT - 4V进行基准测试,但再次遇到了大多数视频使用公共API时的上下文长度限制。
对于腹腔镜胆囊切除术视频的CVS评估任务,Med - Gemini - M 1.5比GPT - 4V高出21%。然而,我们观察到使用ResNet3D架构的监督基线表现更好。可能需要进一步研究提示策略或指令微调,以提高我们模型在该任务上的性能。我们在图9中提供了使用的提示示例以及我们模型的响应。
4.3.1 长上下文能力在生物医学中的应用
除了定量结果,我们还进一步预展示了长上下文能力在医学教育、促进临床医生与EHR系统交互以及生物医学文献回顾和总结方面的潜力。
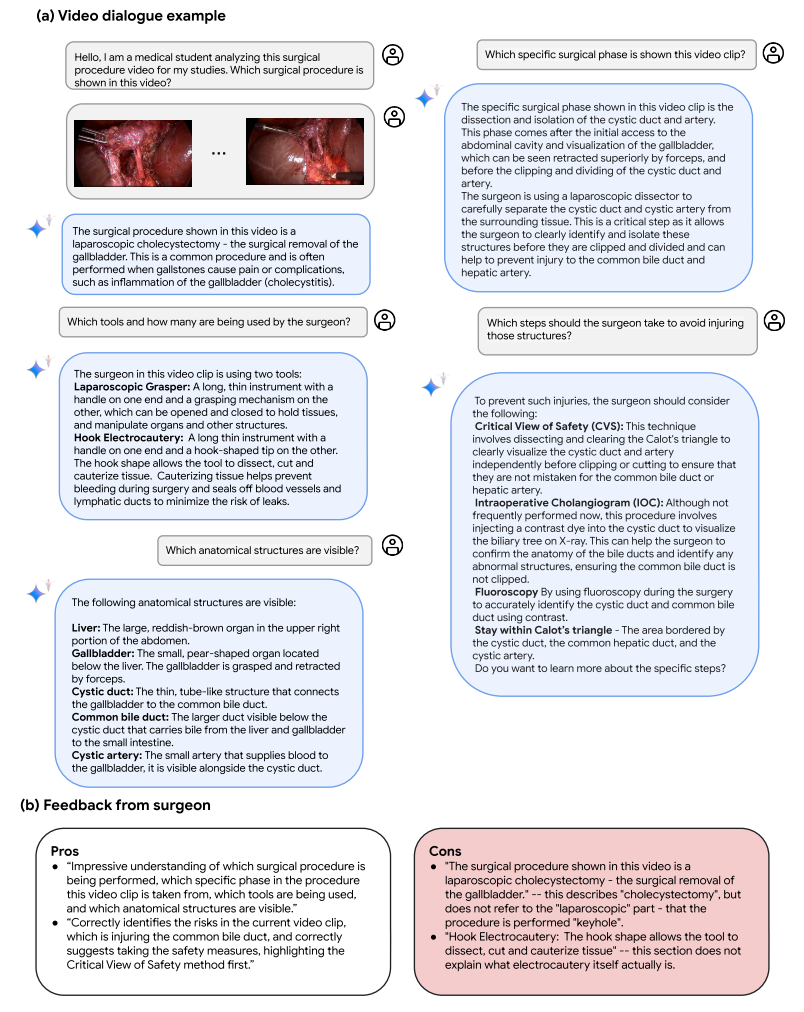
图12| Med-Gemini-M 1.5在手术视频对话方面的长上下文功能示例。Med-Gemini-M 1.5分析了来自Cholec 80数据集的视频剪辑,包括腹腔镜胆囊切除术(切除胆囊的锁孔手术)的镜头。该模型展示了其分析视频的能力,并与学习该过程的学生进行逼真的对话。
在图11中,我们定性地预展示了Med - Gemini - M 1.5从AVOS数据集中的视频识别手术动作的能力。这种能力在手术护理方面具有潜力,有望通过自动评估来增强手术培训,通过分析工作流程来优化手术室效率,并可能在复杂手术过程中实时指导外科医生,以提高准确性和患者预后。在图12中,我们还展示了Med - Gemini -M 1.5在手术视频对话中的长上下文能力示例,模型分析了一段来自腹腔镜胆囊切除术的视频片段。Med - Gemini - M 1.5展示了分析视频并与可能正在学习该手术的学生进行对话的能力。这些有前景的能力有可能为临床医生提供有用的辅助工具,也许可以通过教育辅助或手术过程中的自动辅助和指导来提高患者安全性或增强医学培训过程。模型正确告知用户他们正在观察的是腹腔镜胆囊切除术,并正确提及了“安全关键视图”背后的关键结构。这些分类任务如果能够大规模高精度地执行,可能能够实现更好的手术审计(例如用于质量保证),甚至通过预测手术阶段来提高前瞻性效率。对于更宏伟的目标,如对教育、手术指导或患者安全的益处,需要进行大量进一步的工作来评估更细微和复杂的能力。例如,我们没有测试Med - Gemini准确分割或突出视频中的物理结构并将对话与相关解剖结构联系起来的能力;或者检索和展示有用的教育资源,如图解显示的解剖结构或关键手术阶段指南。对于像教育这样的用途,教学对话目标可能也非常重要。进一步的工作应该在更广泛的手术视频场景中探索这些和其他令人兴奋的新能力,手术视频在医学中越来越普遍。
在图13中,我们展示了Med - Gemini - M 1.5有效地解析大量医疗记录,将其综合为清晰、简洁的当前和历史病症总结的能力。此外,用户可以基于这个总结数据发起对话,请求从记录中获取更详细的信息。我们的示例展示了用户如何进行自然语言查询,询问特定病症(如肺炎)或相关诊断结果(如胸部X射线结果)。通过简化对长篇医学数据的访问并以对话界面呈现交互,这种能力有可能显著减轻临床医生和患者的认知负担,在不影响工作人员福祉的情况下,潜在地提高对复杂医学信息的理解和效率。要在现实世界中实现这种潜力,需要进行大量额外的评估和研究。仅举一个例子,有必要仔细检查从实际内容中检索或生成的临床显著错误的发生率;并积极测量和减轻数据集和模型偏差问题(如我们在下面进一步讨论的)。
在图14中,我们展示了Med - Gemini - M 1.5处理多篇关于特定基因座(FTO)及其与肥胖关联的研究文章的能力。在这个现实世界的应用中,Med - Gemini - M 1.5成功理解了当前研究中呈现的信息(12篇预先整理的便携式文档格式研究论文的完整内容),并为用户编制了一个简洁的总结。我们在这个示例中展示的FTO基因座(FTO基因内与BMI和肥胖相关的变异区域)是一个经典的全基因组关联研究(GWAS)发现的机制理解案例。在这个例子中,其机制是一个相对复杂的多步骤过程,经过大量研究才确定——它涉及变异改变FTO基因内含子超增强子区域内转录抑制因子的结合,从而导致另外两个基因的过表达,最终促进脂质积累。
我们评估Med - Gemini - M 1.5解析大量关于FTO基因座的学术论文,并提供FTO与肥胖之间机制联系的简洁易懂描述以及具体支持实验结果列表的能力。如图14所示,模型提供了关于FTO基因座如何促进肥胖生物学的简洁、信息丰富且准确的描述,并以清晰易懂的方式呈现。模型可以通过列出与rs1421085处于高连锁不平衡状态的其他研究充分的变异,以及提供每条信息的来源参考来进一步改进。这个例子展示了Med - Gemini - M 1.5的长上下文能力如何有明显的潜力减轻基因组研究人员和临床医生的认知负担,增强他们对基因 - 疾病关联最新发现的获取;并且这种潜力在生物医学和科学研究的其他领域也具有广泛的相关性。
讨论
基于Gemini模型构建的Med - Gemini在医学领域的临床推理、多模态理解和长上下文处理方面展示了显著的进展。这体现在它在涵盖医学知识、临床推理、基因组学、波形、医学成像、健康记录和视频的14个医学基准测试的25个任务中的强劲表现。
值得注意的是,Med - Gemini - L 1.0在MedQA(USMLE)上使用基于自训练的微调与搜索集成,达到了新的最先进水平。我们由主治临床医生对MedQA测试集进行的全面重新标注揭示了重要的见解。虽然MedQA(USMLE)是评估医学知识和推理的有用基准,但必须认识到它的局限性。我们发现大约4%的问题包含缺失信息,另外3%可能存在标注错误。在医学领域,建立明确的正确答案通常具有挑战性,因为读者间的差异和模糊性很常见,而且医学知识也在不断发展。我们的观察表明,仅在MedQA(USMLE)基准上进一步提高最先进性能,可能并不直接等同于医学大语言模型在有意义的现实世界任务中的能力进步。因此,进行更全面的、能代表现实世界临床工作流程的基准测试和评估非常重要。一般来说,大多数基准测试在数据集大小和质量方面都存在局限性。虽然我们在此处主要分析MedQA(USMLE),但先前的研究表明其他流行的基准测试数据集也存在类似问题。用PAD - UFES - 20皮肤病数据集的新分割重新训练Med - Gemini - M 1.5,与我们在表2中的结果相比,性能下降了7.1%。因此,在解释和关联模型性能时,需要仔细关注数据集的大小和质量。
Med - Gemini与网络搜索的集成,为大语言模型在医学查询中提供更符合事实、可靠的答案带来了令人期待的可能性。在这项工作中,我们专注于训练Med - Gemini - L 1.0,使其在不确定时发出网络搜索查询,并在生成响应时整合结果。虽然在MedQA、NEJM CPC和GeneTuring基准测试中的结果很有前景,但仍需要进行大量进一步的研究。例如,我们尚未考虑将搜索结果限制在更权威的医学来源,也未使用多模态搜索检索,或对搜索结果的准确性、相关性以及引用质量进行分析。此外,较小的大语言模型是否也能学会利用网络搜索,还有待观察。我们将这些探索留待未来的工作。
Med - Gemini - M 1.5的多模态对话能力很有前景,因为它是在没有任何特定医学对话微调的情况下获得的。这种能力使得人们、临床医生和人工智能系统之间能够进行无缝、自然的交互。正如我们的定性示例所示,Med - Gemini - M 1.5有能力参与多轮临床对话,在需要时请求额外信息(如图像),以易懂的方式解释其推理过程,甚至在适当将最终决策交给人类专家的同时,帮助提供对临床决策有用的信息。这种能力在现实世界的应用中具有巨大潜力,包括辅助临床医生和患者,但当然也伴随着非常重大的相关风险。虽然我们强调了该领域未来研究的潜力,但在这项工作中,我们并未像其他人在专门针对对话式诊断人工智能的研究中那样,对临床对话能力进行严格的基准测试。此外,在未来的工作中,我们还将严格探索Gemini在临床特定多模态任务(如放射学报告生成)中的能力。
也许Med - Gemini最值得注意的方面是其长上下文处理能力,因为它为医学人工智能系统开辟了新的性能前沿,以及以前无法实现的新颖应用可能性。在这项工作中,我们引入了一个新的电子健康记录任务,专注于在非常长的电子患者记录中识别和验证病症、症状和手术。这个“大海捞针”式的检索任务反映了临床医生在现实世界中面临的挑战,Med - Gemini - M 1.5的性能表明,它有潜力通过从大量患者数据中高效提取和分析关键信息,显著减轻认知负担并增强临床医生的能力。医学视频问答和注释的性能表明,这些能力可以推广到复杂的多模态数据。值得强调的是,长上下文能力的展示是在少样本的方式下进行的,没有任何特定任务的微调。这种能力为基因组和多组学序列数据的精细分析和注释、病理或体积图像等复杂成像模态的分析,以及与健康记录的综合处理以揭示新见解和辅助临床工作流程开辟了可能性。
Gemini模型本质上是多模态的,并且由于大规模多模态预训练而拥有强大的医学知识。这体现在它在多模态基准测试(如NEJM图像挑战)中令人印象深刻的开箱即用性能上,比类似的通用视觉语言模型(如GPT - 4V)有很大优势。同时,医学知识和数据(特别是多模态数据)是独特而复杂的,不太可能在用于训练大语言模型的公共互联网上常见。Gemini是一个强大的智能基础,但在医学领域使用之前,即使是这样强大的模型也需要进一步的微调、专门化和校准。同时,鉴于Gemini的通用能力,进行这种专门化和校准所需的数据量比前一代医学人工智能系统要少得多,并且正如本文所示,确实有可能相对高效地使这些模型适应以前未见过但很重要的医学模态(如心电图)。
据我们所知,这项工作是对医学大语言模型和大多模态模型最全面的评估。该工作包括医学人工智能新能力的证据,以及表明现实世界实用性的任务。我们的模型在医学总结和转诊信生成评估中的强劲表现尤其强化了这一点。诊断任务在研究中备受关注,但在安全可行地实际应用之前,需要解决重大的监管、临床和公平相关风险。
因此,医疗保健领域中生成式人工智能更常见的现实世界用例是非诊断任务,在这些任务中错误的风险较低,但模型输出可以通过减轻行政负担和辅助日常工作中所需的复杂信息检索或合成,显著提高医疗服务提供者的效率。同时,即使对于这些非诊断任务,要确保现实世界的影响,也需要基于特定用例和环境进行评估。这些评估超出了初始基准测试的范围,我们的结果应谨慎解读。
为了评估我们在此展示的前景在现实世界临床工作流程中的下游影响和泛化性,从业者应遵循负责任人工智能的最佳实践,在预期环境中严格测量包括公平性、公正性和安全性在内的多个指标,同时考虑特定用例的多种社会技术因素,这些因素是影响的决定因素。最后,值得注意的是,虽然我们在本研究中考虑了14个多样且具有挑战性的基准测试,但社区中现有超过350个医学基准测试。
我们的工作主要集中在Gemini模型的能力、改进以及其在可能实现的方面。未来探索的一个重要焦点是在整个模型开发过程中整合负责任人工智能的原则,包括但不限于公平、隐私、平等、透明和问责原则。隐私考虑尤其需要植根于现有的管理和保护患者信息的医疗政策和法规中。公平性是另一个需要关注的领域,因为医疗保健领域的人工智能系统存在无意反映或放大历史偏见和不平等的风险,这可能导致模型性能的差异,并对边缘化群体产生有害结果。这种健康不平等现象在性别、种族、民族、社会经济地位、性取向、年龄以及其他敏感和/或受保护的个人特征方面都有体现。越来越需要对影响进行深入的交叉分析,尽管这仍然是一个棘手的技术问题,也是一个活跃的研究领域。
当我们展示大语言模型和大多模态模型的新能力时,在数据集偏差、模型偏差以及特定用例的社会技术考虑的交汇处,也出现了潜在问题的新机会。在我们讨论的能力背景下,这些问题可能潜在地出现在长上下文利用中可能存在偏差的示例和指令的上下文学习、搜索集成、自训练的动态过程,或多模态理解中的微调与定制数据编码器中。在这些能力的每一个方面,都可能有多个需要考虑偏差的点。在网络搜索集成方面,偏差可能在查询构建时出现,反映在返回的结果集中,或嵌入在每个链接的外部来源中,并以各种其他微妙的方式表现出来,例如在生成最终答案时,结果如何整合到生成推理过程中。对于多模态模型,偏差可能分别出现在每个单独的模态中,或者仅在数据的相互依赖模态中共同显现。对潜在问题的全面分析可能需要分别考虑每个点,但也需要从整体上考虑,因为它们都是复杂系统的一部分。这些系统不仅需要单独进行彻底评估,还需要在有人工专家参与的情况下进行评估。
然而,这些新能力也为减轻先前的问题并显著提高不同用例的可及性提供了机会。例如,医学领域新的长上下文能力可能使模型的用户在推理时无需进行模型微调即可解决复杂问题,因为数据可以直接在查询上下文中使用,然后跟随一组自然语言指令。以前,此类系统的用户需要具备工程专业知识,并投入额外的时间和资源来微调定制模型以处理这些复杂任务。另一方面,网络搜索集成在快速整合新开发的医学知识以及关于高度动态和非静态医学领域的外部共识方面可能被证明是非常宝贵的。COVID - 19大流行表明,公共卫生理解和建议可能需要多么迅速地更新,它也凸显了医学错误信息带来的总体危险。能够可靠地获取最新权威外部来源信息的模型,不太可能导致此类错误信息。其他模型能力也带来了类似的新机会,不过需要进一步研究来开发一个强大的评估框架,以评估偏差和不公平输出的相关风险,这种评估需要在特定临床用例的实际环境中从社会技术角度进行。
结论
大多模态语言模型正在为健康和医学领域开创一个充满可能性的新时代。Gemini和Med - Gemini展示的能力表明,在加速生物医学发现、辅助医疗服务提供和改善医疗体验方面,机会的深度和广度都有了显著的提升。然而,至关重要的是,在模型能力取得进展的同时,要密切关注这些系统的可靠性和安全性。通过同时重视这两个方面,我们可以负责任地展望未来,让人工智能系统的能力成为医学科学进步和医疗服务的有意义且安全的加速器。
数据可用性
除了三个临床抽象任务外,用于人工智能系统开发、基准测试和评估的其余数据集均为开源数据,或在获得许可后可公开访问。我们将公开我们对MedQA(USMLE)数据集的重新注释。
代码可用性
由于在医疗环境中不受监控地使用此类系统存在安全隐患,我们不会开源模型代码和权重。出于负责任创新的考虑,我们将与研究合作伙伴、监管机构和供应商合作,验证并探索我们医学模型的安全后续用途,并期望在适当的时候通过谷歌云API提供这些模型。
利益冲突
本研究由Alphabet Inc和 / 或其附属公司(“Alphabet”)资助。所有作者均为(或曾经是)Alphabet的员工,可能持有作为标准薪酬一部分的股票。
附录
A 图1 的补充
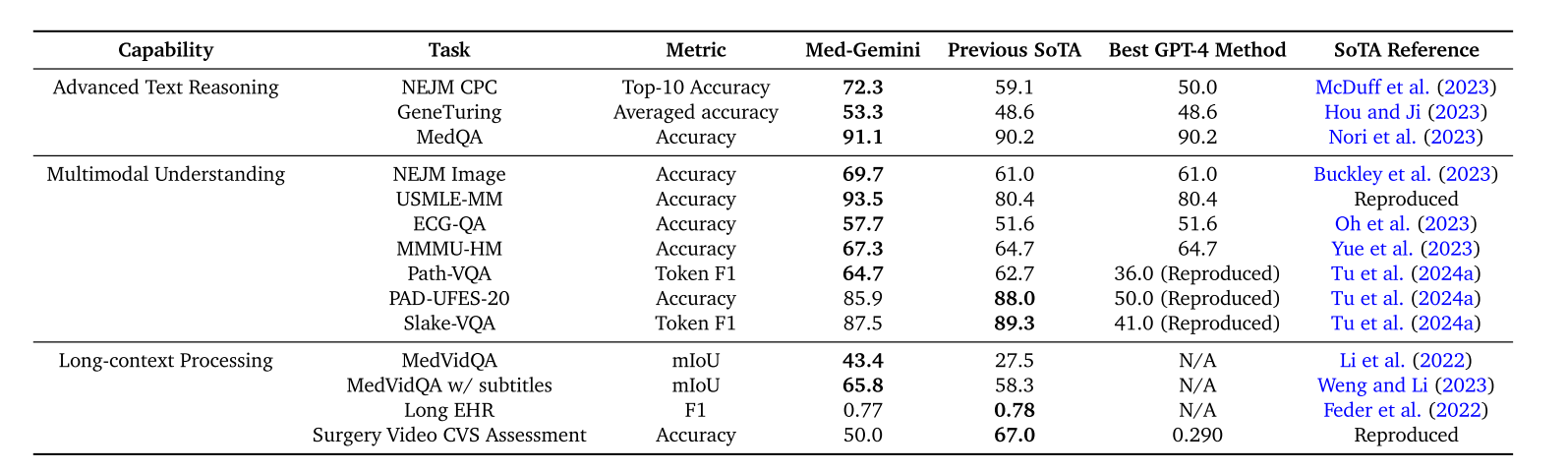
表 A1 | 图 1 条形图的性能结果。我们展示了综合结果,对比了 Med - Gemini 与先前的最先进(SoTA)方法以及 GPT - 4 系列最佳方法在基于文本的任务、多模态任务和长上下文任务中的表现。对于在文献中找不到 GPT - 4(或 GPT - 4V)报告数据的基准测试,我们使用公共 API 在相同的测试集上进行评估,以进行直接对比,采用与相应 Med - Gemini 模型相同的少样本提示,包括确保输出格式正确的指令。请注意,由于公共 GPT - 4 / GPT - 4V API 上下文窗口的限制,三个长上下文任务的 GPT - 4 结果不可用(N/A)。
B.相关工作
医学领域大语言模型综述
大语言模型(LLMs)彻底改变了机器学习和人工智能领域。研究人员采用了新颖的网络架构,如 Transformer(Vaswani 等人,2017)和 Pathways(Barham 等人,2022),在大规模数据集上训练这些模型。这种跨不同领域的自监督训练涵盖了多种模型,像 BERT(Devlin 等人,2018)、GPT(Radford 等人,2018)、T5(Raffel 等人,2020)、FLAN(Wei 等人,2021)、BLOOM(Le Scao 等人,2022)、Flamingo(Alayrac 等人,2022)、PaLM 和 PaLM2(Anil 等人,2023;Chowdhery 等人,2023)、LLaMA(Touvron 等人,2023)、PaLI(Chen 等人,2022)、PaLM-E(Driess 等人,2023),以及最近的 Gemini 模型(Gemini 团队,谷歌,2023 年、2024 年)。通过处理文本或多模态信息,这些预训练模型对语言、模式和关系有了强大的理解能力,并且具有出色的适应性。
只需进行少量微调,这些模型就能适应各种下游任务。在医学领域,Med - PaLM(Singhal 等人,2023a)和 Med - PaLM 2(Singhal 等人,2023b)是具有开创性的医学大语言模型,它们在电子健康记录、考试问题和研究文献上进行了微调。为了实现通用医学人工智能(GMAI)的目标(Moor 等人,2023a),研究人员使用通用大语言模型并结合提示策略(例如,GPT - 4 搭配 Medprompt,Nori 等人,2023),或者用多模态数据对其进行优化,以增强医学理解能力(例如,Med - PaLM - M,Tu 等人,2024a)。这些模型在诊断辅助(McDuff 等人,2023)、风险预测、药物发现、诊断对话(Tu 等人,2024b)和评估精神功能(Galatzer - Levy 等人,2023)等方面展现出了潜力。我们的工作利用了最新的 Gemini 模型,通过直接指令提示或进一步微调,使其适用于专门的医学任务。下面,我们将讨论语言、多模态学习和长上下文建模等领域的相关工作。
基于语言任务的模型推理与工具使用
推理是一个逻辑思维过程,最终得出结论。最近大语言模型和大多模态模型(LMMs)的进展显著提升了推理能力。这些改进源于更好的模型和直接模仿人类推理的方法的结合。之前的研究已经对基于语言模型的推理技术进行了综述(Huang 和 Chang,2023;Qiao 等人,2023),并且这种综述已经扩展到多模态推理领域(Wang 等人,2024)。增强语言推理的策略包括提示工程、改进流程,以及通过获取外部元素(如工具或知识)来提升推理能力。提示工程的例子有思维链(CoT)提示(Wei 等人,2022),它涉及生成一系列中间推理步骤;还有从最少到最多提示法,即把一个问题分解成较小的子问题,然后依次解决(Zhou 等人,2023);以及其他探索不同推理路径以得出结论的方法(Besta 等人,2024;Yao 等人,2023)。改进流程的方法包括通过自我改进进行模型更新(Zelikman 等人,2022)或基于集成的方法(Wang 等人,2022b)。
通过使用检索增强生成(RAG)(Gao 等人,2024;Zhang 等人,2024)来获取外部元素(如工具(Hao 等人,2024;Schick 等人,2024)或外部知识库),也证明了可以提升语言模型的推理能力。最近,大语言模型还发展出了与信息和网络工具交互的能力。在工具使用方面,大语言模型可以学习执行外部工具或应用程序编程接口(APIs),使其能够在现实世界中执行诸如搜索、使用日历或通过 API 使用翻译服务等操作(Qin 等人,2023;Schick 等人,2024)。具体到网络搜索,大语言模型通过理解复杂查询并提供综合多个来源信息的摘要,整合了传统搜索引擎(Nakano 等人,2021;Varshney 等人,2023)。此外,大语言模型不仅能够检索信息,还能利用工具并根据用户定义的需求创建工具(Cai 等人,2023)。Zakka 等人(2024)已经证明,在医学指南和治疗建议中,搜索工具的使用特别有用。在这项工作中,我们整合了搜索自训练策略,以提高 Med - Gemini 的模型推理能力。
医学领域的大多模态模型
医疗实践通常需要整合多种模态的数据来提供有效的医疗服务,例如,整合来自患者病史、医学成像、基因检测和实验室结果的数据。能够整合这些模态的模型可以更全面地描绘患者的病情。现有的方法大致分为两类:专科模型和通用模型。专科模型擅长医学学科内的特定任务。例如,针对放射学报告生成进行优化的模型(Tanno 等人,2024;Zambrano Chaves 等人,2024)、病理学问答或组织病理学图像字幕生成模型(Lu 等人,2023)、放射学相关任务模型(Xu 等人,2023),以及心脏病学心电图图像字幕生成模型(Wan 等人,2024)。
相反,“通用医学人工智能”(GMAI)系统(Moor 等人,2023a),如 Med - PaLM M(Tu 等人,2024a)和 LLaVA - Med(Li 等人,2024),能够处理多个专科的更广泛任务,旨在在临床环境中具有更广泛的适用性。像 Med - PaLM M 这样的系统所执行任务的多样性仍然值得关注,它是医学领域最早的通用多模态模型之一,能够通过强大的预训练大语言模型和适当的微调策略,在放射学、病理学、皮肤病学和基因组学任务中表现出色,甚至在不同专科中超越最先进水平。在本报告中,我们进一步证明了人工智能系统可以通过 Med - Gemini 在医学领域提供强大的通用多模态能力,但主要重点是开发一个考虑特定应用权衡的模型系列。
大语言模型的长上下文能力
先前处理长上下文窗口任务的工作受到大语言模型有效利用大段文本能力的限制,这是由于基于 Transformer 的模型存在内存和计算限制(Liu 等人,2024;Vaswani 等人,2017)。最初的尝试使用分层方法来推导无法放入模型有限上下文窗口的临床文本表示(Dai 等人,2022)。随后的工作,如 Clinical - Longformer 和 Clinical - BigBird(Li 等人,2023),致力于将上下文长度从 512 个标记扩展到 4096 个标记,从而在问答、文档分类和信息检索任务中提升了性能。后续的方法探索了将这些模型与成像编码器结合使用,以处理多模态任务,如医学视觉问答(Gupta 和 Demner - Fushman,2022)。随着硬件和高效算法的进步,研究人员开发出了上下文窗口更大的大语言模型,可达 100K 个标记(Dai 等人,2019;Poli 等人,2023)。最近,Gemini 进一步将长上下文能力的边界扩展到了 100 万个标记(Gemini 团队,谷歌,2024)。
然而,在医学领域,大多数大语言模型仍然在相对较短的文本(Parmar 等人,2023)和单张图像上进行评估。尽管长上下文能力在医学和临床实践中非常重要,但在医学领域,尤其是在多模态环境下,长上下文能力的研究还不够深入。我们致力于满足这一未被满足的需求,研究 Med - Gemini 在不同长上下文应用场景中的潜力,包括视频和与长电子健康记录相关的任务。
C. 基于文本的先进推理任务的更多细节
C.1 基于文本的微调与评估数据集
表 C1 | 用于基于文本的指令微调的数据集概述。数据集的混合和合成数据经过精心策划,以提高 Med - Gemini - L 1.0 的推理能力和利用网络搜索的能力。

表 C2 | 用于基于文本的推理任务的评估基准概述。

C.2 MedQA(USMLE)重新标注
这项评分者研究的主要目的是识别:(a)由于信息缺失而无法回答的问题;(b)潜在的标注错误;(c)可能存在歧义的问题(Stutz 等人,2023)。为此,我们精心设计了一个两步研究,具体如下:
- 步骤 1:给出 MedQA(USMLE)问题和所有四个答案选项:
- (Q1)我们询问 “这些选项中有没有适合回答这个问题的?”
- (Q2)如果有,“选择一个或多个选项来回答这个问题。”(多选)
- (Q3)我们询问 “问题中是否引用了任何缺失的额外信息(如图表、绘图、实验室结果或类似内容)?”
- (Q4)如果有,我们询问 “你认为获取到缺失的信息会改变你的答案吗?”
- 步骤 2:在评分者完成步骤 1 后,向他们展示 MedQA 的正确答案:
- (Q1)我们询问 “在揭示了题库的答案后,你之前的答案有改变吗?”
- (Q2)如果有,我们重复上述前两个问题。
采用这种两步法的一个关键考虑因素是在合适的时间揭示 MedQA(USMLE)的正确答案,以避免在回答关于问题中潜在缺失信息的问题(Q3 和 Q4)时,正确答案对评分者产生偏见。然而,为了准确识别标注错误,我们向评分者展示正确答案,以便他们可以决定是否不同意(步骤 2 中的 Q1 和 Q2)。为了识别可能存在歧义的问题(允许多个 “正确” 或 “真实” 答案),我们进一步允许评分者选择多个选项作为答案 。在询问潜在缺失信息时,我们旨在确定这些缺失信息对回答问题是否至关重要。 表 C3 | 注释一致性。顶部:各个评级与多数或一致投票在各种感兴趣的评级任务上的一致性。底部:在揭示 MedQA 正确答案前后,评分者答案在平均重叠方面的一致性。
我们总共招募了 18 名来自美国的初级保健医生(PCPs)参与这项研究。我们选择美国的初级保健医生是因为 MedQA 包含涵盖多个专业的 USMLE 风格的问题。对于每个 MedQA(USMLE)问题,我们从独立的评分者那里收集至少三个评级。虽然 Jin 等人(2021)的原始 MedQA 研究在评估专家表现时可以使用额外的文本材料,但我们的评分者并未被指示使用任何材料。不过,我们也没有明确对此进行控制。初级保健医生完成一个问题平均需要 255 秒;98% 的人在 10 分钟内完成。
对于每个问题,我们汇总评级,以便高可信度地识别例如标注错误。首先,我们在表 C3 中评估每个评分者与多数或一致投票的一致性。具体来说,我们考虑四个感兴趣的评级任务的评分者一致性:信息是否缺失、是否存在标注错误(即揭示 MedQA(USMLE)正确答案后,评分者的答案不包含 MedQA(USMLE)的正确答案)、问题是否存在歧义(即揭示 MedQA(USMLE)正确答案后,评分者的答案包含多个选项),以及原始答案选项在平均重叠方面的一致性(每个评分者可以选择无选项或多个选项)。对于前三个任务,一致性通常较高(\(>87\%\)),尽管在 Med - Gemini - L 1.0 出错的问题上通常较低。相比之下,对于第三个任务,所有答案对之间的平均重叠一致性要低得多:当评分者看到 MedQA(USMLE)正确答案时,通常约为 75%,但如果不向评分者揭示正确答案,一致性会降至约 50%。 图 C1 | MedQA(USMLE)重新标注后的结果。该结果是图 3b 的补充,展示了在使用多数投票(左图)或一致投票(右图)汇总评级时,过滤掉包含缺失信息、标注错误或被认为存在歧义的问题后,MedQA(USMLE)的准确率(蓝色)和剩余问题(红色)。
为了在考虑注释不确定性的同时衡量过滤 MedQA(USMLE)中包含缺失信息或标注错误的问题对评估的影响,我们进行了一项自助抽样实验。具体来说,我们对每个问题重复抽样一个由三名评分者组成的委员会(有放回抽样)。对于每个评分者委员会,我们进行多数投票或一致投票,以识别出在评估时应过滤掉的包含缺失信息或标注错误的问题。这可以看作是 Stutz 等人(2023)提出的评估框架的一个实例。自助抽样相对于简单投票的优势在于,我们可以得到可靠的不确定性估计,确保我们能够将性能变化识别为具有统计学意义。我们重复这个实验 1000 次,并在图 C1 中报告准确率和剩余问题比例的平均值和标准差。
虽然由于一致性较高,可以高可信度地识别出包含缺失信息或标注错误的问题,但判断一个问题是否存在歧义则更困难。在这里,我们将一个允许多个答案选项正确的问题定义为存在歧义的问题。MedQA(USMLE)测试集中的大多数问题特别要求选择 “最佳”“最可能” 或 “最合适” 的选项。然而,在很多情况下,并不清楚答案是否真的只允许一个选项作为例如某个病例 “最佳下一步治疗方案”。在使用多数投票排除包含缺失信息和标注错误的问题后,评分者平均选择 1.065 个选项,这表明有些问题可能确实存在歧义。在揭示正确答案后,这个数字增加到 1.119。为了在评估时考虑到这一点,如果评分者在揭示正确答案后选择了多个选项,我们就将该评级定义为存在歧义。然后,我们按照上述相同的分析方法,并在图 C1 中展示结果。总体而言,我们发现过滤标注错误对 Med - Gemini - L 1.0 的性能影响最大,而过滤缺失信息或存在歧义的问题可以减少问题数量,但对准确率的影响并不显著。
C.3 《新英格兰医学杂志》临床病理会议数据集的更多结果
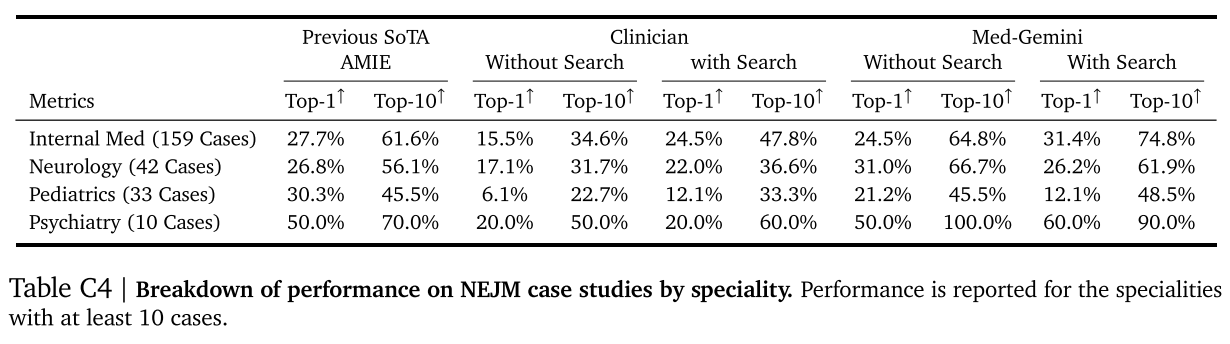
我们在表 C4 中按病例的主要专科(由《新英格兰医学杂志》确定)展示了《新英格兰医学杂志》临床病理病例研究的前 1 名和前 10 名表现,这些专科至少有 10 个病例。在大多数专科,如内科、儿科和精神科,Med - Gemini - L 1.0 在不使用搜索或使用搜索的情况下,取得了最佳的前 1 名和前 10 名表现。
表 C4 | 按专科划分的《新英格兰医学杂志》病例研究表现细分。报告了至少有 10 个病例的专科的表现。
C.4 基于文本任务的先进推理在现实世界中的应用案例
我们对 Med - Gemini - M 1.0 在三个需要长篇文本生成的具有挑战性的现实世界任务上进行指令微调并评估。总结结果见图 5。其他评估维度的详细结果见表 C5。下面将更详细地描述每个任务的数据集和评估程序。
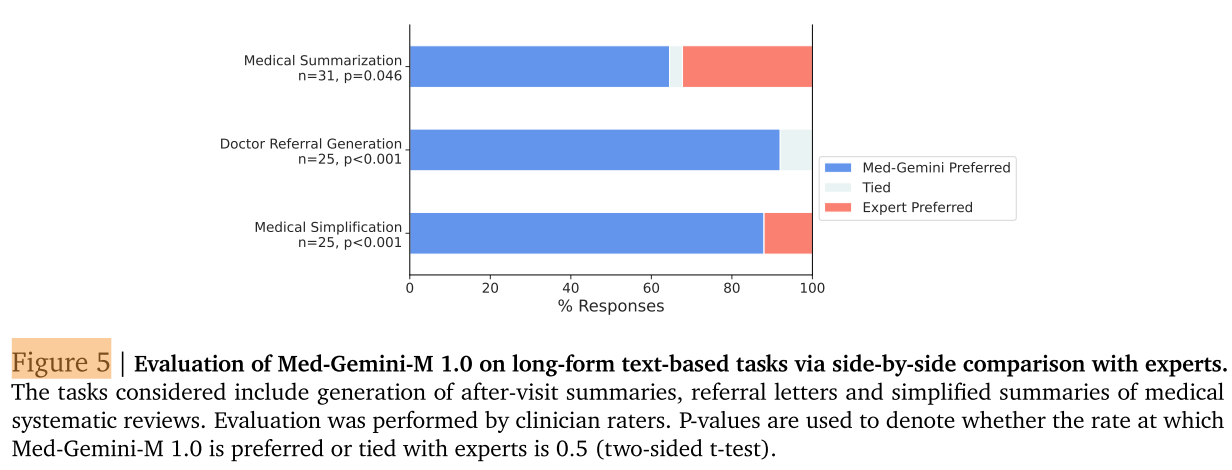
表 C5 | 通过与专家并排比较对 Med - Gemini 在基于长篇文本的任务上的评估。任务包括就诊后总结、转诊信和生物医学系统评价简化总结的生成。评估由临床医生评分者进行。p 值用于表示 Med - Gemini - M 1.0 被认为与专家相当或更受青睐的比例是否为 0.5(双侧 t 检验)。
- 医学总结评估:此任务涉及根据去标识化的病史和体格检查(H&P)笔记生成就诊后总结(AVS)。H&P 笔记是一份详细的文件,医疗保健提供者在其中记录患者就诊的发现,包括患者的健康背景、当前症状和体格检查结果。它主要是为其他医疗保健提供者编写的,以确保协调护理。另一方面,AVS 是患者在医疗就诊结束时收到的结构化报告,总结就诊的最重要方面及其健康状况。
我们从家庭医学或内科门诊就诊的去标识化医疗笔记数据集中抽取了 31 份去标识化的 H&P 笔记。专家就诊后总结由美国的临床医生根据 Sieferd 等人(2019)的指南编写,并由另一轮临床医生进一步完善以提高质量。
给 Med - Gemini - M 1.0 输入去标识化的 H&P 笔记,提示其生成就诊后总结,如下所示: 请通读提供的描述门诊就诊的医疗笔记,并为以下 12 个字段提取相关信息:
- 患者姓名 / 年龄 / 性别:应总结患者的姓名、年龄和性别。格式为:“[患者姓名],[年龄] 岁 [性别]”。如果笔记中未提及姓名,请回答 “不可用”。
- 今天为我看病的是:此字段应提供提供者的姓名。如果总结笔记中未提及为患者看病的提供者,请回答 “不可用”。
- 我今天来就诊的原因是:此字段应指出导致就诊的主要症状或问题。
- 今天新发现的健康问题是:此字段应指出因本次就诊而确定的任何新诊断或其他问题。如果该问题是过去已确定的既往病症,请回答 “无新诊断”。
- 我还有的其他健康问题是:此字段应指出笔记中确定的任何既往健康问题。
- 今天我们完成的事项:此字段应总结当前就诊期间讨论的主要话题和进行的任何程序的结果。总结可以是简短的程序列表,也可以是对患者经历的文本描述。在提供详细信息(如测试结果或药物名称)时,请尽量简洁。从患者的角度描述经历,使用 “我的就诊”“我的病情” 等短语。
- 我的重要数据:此字段应提供与就诊相关的任何测量结果,包括生命体征。提供与就诊相关的任何数值测量结果,包括生命体征、实验室检查或疼痛评分。请包括应监测的数值。不要编造笔记中未呈现的数字。
- 我的药物变化是:此字段应说明就诊后添加、剂量更新或不再需要的任何药物。如果可能,请同时说明新添加和停用的药物。如果从笔记中看不出有任何变化,请回答 “无变化”。
- 我正在服用的其他药物是:如果笔记中指出患者应继续服用且无变化的现有药物,请在此列出。如果笔记中未提及任何药物,请填写 “未指定”。
- 我的下一步是:此字段应记录患者的下一步行动,包括他们应采取的任何行动、预期的测试结果以及应安排的随访就诊,以及每个步骤的适当时间框架。
- 如果出现以下情况我应立即寻求医疗帮助:如果笔记中指定了患者应立即寻求护理的任何情况,请在此处说明。确保只包括笔记中提到的情况。如果未提及任何情况,请写 “未指定”。
- 我的医生的其他意见:这是一个可选的额外字段,用于记录医生在笔记中指出的、对患者有用的任何其他相关信息。请勿包含前面字段中已列出的信息。
对于每个字段,请以六年级的阅读水平书写,避免使用缩写或行话。 注意:{医疗笔记} 就诊后总结:
医生评分者会收到 H&P 笔记、临床医生生成的 AVS 和我们模型生成的 AVS。每个示例由三位不同的美国医生中的一位进行评估,评估维度如下:
- 准确性:哪个总结更准确?(总结中的所有陈述是否正确?)
- A - B - 平局
- 覆盖范围:哪个总结的覆盖范围更好?(它是否包含笔记的所有相关方面?)
- A - B - 平局
- 连贯性:哪个总结更容易阅读?(对于没有特定医学知识的普通消费者来说,以六年级阅读水平来看,这个总结是否易懂?)
- A - B - 平局
- 简洁性:哪个总结更简洁?(总结是否比需要的更长?)
- A - B - 平局
- 总体评价:你认为哪个总结的质量更高?(除了这些指标之外,对总结的质量有没有直观的感觉?)
- A - B - 平局
- 转诊信生成评估:此任务涉及根据包含转诊建议的去标识化门诊医疗笔记,生成转诊信给另一位医疗保健提供者。医疗转诊信是医疗保健专业人员撰写的正式文件,请求另一位医疗保健专业人员对患者进行评估或治疗。它是医疗保健提供者之间的沟通工具,确保护理的连续性并促进对患者的适当治疗。
临床医生从去标识化的电子医疗记录数据集中手动选择了一组需要跨专科评估的去标识化医疗笔记。然后他们生成转诊信,这些转诊信由一位美国董事会认证的临床医生进一步审核质量。
给 Med - Gemini - M 1.0 输入医疗笔记,提示其生成转诊信,如下所示: 你将收到一份描述患者就诊的医疗笔记。该医疗笔记将包含将患者转诊给另一位医疗保健提供者的建议。你的任务是为这位医疗保健提供者生成医疗转诊信。
医疗转诊信是医疗保健专业人员撰写的正式文件,请求另一位医疗保健专业人员对患者进行评估或治疗。它是医疗保健提供者之间的沟通工具,确保护理的连续性并促进对患者的适当治疗。 医疗笔记:{医疗笔记} 转诊信:
医生评分者会收到门诊笔记、临床医生生成的转诊信和我们模型生成的转诊信。他们不知道每封转诊信的来源,并被要求进行以下比较: 说明: 你收到一份提到转诊给另一位医疗保健提供者的医疗笔记。假设你需要根据笔记中的信息撰写一封转诊信。你会看到由两位不同助手撰写的转诊信草稿。你更倾向于选择哪一份草稿作为编辑最终版本的起点?请在 “备注” 栏中简要说明你选择的理由。 警告:请注意,不能保证草稿信准确反映转诊原因或患者病史。这需要根据提供的医疗笔记来确定,并且在你的选择中应占重要考虑因素。 选项:
- A 非常倾向 - A 有点倾向 - 平局 - B 有点倾向 - B 非常倾向
我们招募了三位不同的美国董事会认证医生,他们每个人评估所有 25 个示例。评分通过将李克特量表映射到数值范围(\([-2,2]\))并取中位数的符号来汇总。
- 医学简化评估:此任务涉及从生物医学系统评价的技术摘要生成通俗易懂的语言摘要(PLS)。PLS 是技术摘要的一个版本,用通俗易懂的英语撰写,旨在让大多数没有大学教育背景的读者能够理解(Cochrane,2014)。
我们从 Devaraj 等人(2021)引入的数据集的测试分割中抽取了 25 个来自 Cochrane 系统评价的技术摘要和通俗易懂的语言摘要。专家撰写的通俗易懂的语言摘要是由 Cochrane 系统评价的原始作者编写的。
给 Med - Gemini - M 1.0 输入技术摘要,提示其生成 PLS,如下所示: 请通读提供的医学研究技术总结,并提供一个对没有医学专业知识的普通读者易懂的简化总结。 技术总结:{技术摘要} 简化总结:
临床医生会收到技术摘要、原始 PLS 和我们模型生成的 PLS。他们不知道每个 PLS 的来源,并被要求进行以下比较:
- 依据性:简单总结中的所有信息在技术总结中是否都有事实依据?
- A 非常倾向 - A 有点倾向 - 平局 - B 有点倾向 - B 非常倾向
- 覆盖范围:简单总结是否包含了对普通读者最重要的要点?
- A 非常倾向 - A 有点倾向 - 平局 - B 有点倾向 - B 非常倾向
- 简洁性:简单总结是否只包含了对普通读者最重要的要点?
- A 非常倾向 - A 有点倾向 - 平局 - B 有点倾向 - B 非常倾向
- 阅读水平:简单总结的阅读水平是否适合普通读者?
- A 非常倾向 - A 有点倾向 - 平局 - B 有点倾向 - B 非常倾向
- 总体评价:对于普通读者来说,这个简单总结的总体质量如何?
- A 非常倾向 - A 有点倾向 - 平局 - B 有点倾向 - B 非常倾向
三位不同的美国董事会认证医生各自评估所有 25 个示例。评分的汇总方式与转诊信任务类似。
D. 多模态理解任务的更多细节
D.1 多模态微调数据集
为了对 Med - Gemini - M 1.5 进行多模态微调,我们使用了来自 MultiMedBench(Tanno 等人,2024;Tu 等人,2024a)的四个图像 - 文本数据集,包括 Slake - VQA(Liu 等人,2021)、Path - VQA(He 等人,2020)、MIMIC - CXR(Johnson 等人,2019a,b)、PAD - UFES - 20(Pacheco 等人,2020),以及 Radiology Objects in COntext(ROCO)数据集(Pelka 等人,2018)。我们还进一步使用了 ECG - QA(Oh 等人,2023)的一个子集,为 Med - Gemini - S 1.0 开发用于编码传感器输入的健康信号编码器。下面我们详细描述这些数据集: 表 D1 | 用于多模态指令微调的数据集概述。
- MIMIC - CXR 是一个带有自由文本报告的胸部 X 光(CXR)数据集(Johnson 等人,2019a,b),由 377,110 张胸部 X 光图像以及来自 65,379 名患者的相应去除受保护健康信息(PHI)的文本报告组成(227,835 次图像研究,有一个或多个图像视图位置)。每份报告使用 CheXpert 标注软件(Irvin 等人,2019)标注了 13 种常见的放射学状况。我们对所有任务使用 MIMIC - CXR 中描述的官方训练 / 测试分割。我们考虑使用 MIMIC - CXR 进行四个微调任务:(1)正常与异常的二元分类;(2)CXR 异常状况视觉问答(VQA);(3)合成 CXR 视觉问答;(4)文本报告生成。对于正常与异常的二元分类任务,我们根据 CheXpert 的 “无异常发现” 标签,使用所有正位视图图像(前后位(AP)和后前位(PA)视图)将每张图像分类为正常或异常类别,任务提示见图 D1。对于 CXR 异常状况视觉问答任务,我们排除所有正常发现的图像,并将 13 种异常状况(肺不张、心脏肥大、实变、水肿、纵隔增宽、骨折、肺部病变、肺部阴影、胸腔积液、胸膜其他病变、肺炎、气胸和支持装置)的阳性和不确定标签归为阳性类别。然后,我们将异常检测问题构建为一个封闭式多类别多项选择题设置,如图 D1 所示。为了进一步丰富这些视觉问答任务,我们通过查询 Gemini 基础模型从放射学报告中生成一组合成的问答对。我们特别促使大语言模型从每份报告中提取是或否问题及其相应答案,使其与上述 13 种状况的存在无关。我们确保每个问题的 “是” 和 “否” 答案数量相同,以避免引入虚假相关性。所有视觉问答任务都作为报告生成任务的辅助任务添加,该报告生成任务将图像与来自 “检查指征” 部分(研究原因)的上下文信息作为模型输入,以生成报告的 “检查结果” 和 “印象” 部分作为目标,与先前的工作类似(Hyland 等人,2023;Tu 等人,2024a)。此外,按照 Tanno 等人(2024)提出的程序,我们过滤掉报告中引用先前研究的训练示例,只保留报告仅提及输入图像中存在的发现的示例。这旨在减轻对不存在的先前报告的引用幻觉,这是多个研究中提出的常见问题(Ramesh 等人,2022;Hyland 等人,2023)。MIMIC - CXR 的评估将在后续论文中报告。
- PAD - UFES - 20 包含 2,298 张临床皮肤病变图像,这些图像是通过巴西圣埃斯皮里图联邦大学(UFES)的皮肤病学和外科援助计划,从各种不同分辨率、尺寸和光照条件的智能手机设备上收集的(Pacheco 等人,2020)。数据集中包含六种类型的皮肤病变:基底细胞癌、黑色素瘤、鳞状细胞癌、光化性角化病、黑素细胞痣和脂溢性角化病。每张图像最多与 21 个临床特征相关联(例如,患者人口统计信息、家族癌症病史、病变位置、病变大小)。由于没有公布官方分割,我们采用了两种 PAD - UFES - 20 分割设置。我们使用 Med - PaLM M 分割(图像级分割),以便与先前的最先进方法进行直接、公平的评估和比较。我们还在一个新的分割(患者级分割)上进行评估(表 2)。我们设置了三个分类任务进行微调:(1)使用原始标签分布和 14 个临床特征(年龄、性别、吸烟、饮酒、皮肤癌病史、癌症病史、地区、菲茨帕特里克皮肤分型、水平和垂直直径、瘙痒、生长、出血和隆起)进行 6 类分类;(2)与前一个任务一样使用图像和临床特征进行 6 类分类,但在训练集上使用 8 种 RandAugment(Cubuk 等人,2020)操作进行图像增强:自动对比度调整、均衡化、反转、旋转、色调分离、曝光、色彩调整和对比度调整;(3)与前一个任务相同的 6 类分类,但对四种较少见的皮肤状况(黑色素瘤、鳞状细胞癌、脂溢性角化病和痣)使用上采样子集,并在训练期间进行图像增强,以缓解类别不平衡问题。后两个辅助任务包含在训练组合中,以帮助模型区分不同类型的临床观察结果。我们还将皮肤状况分类问题构建为一个封闭式多项选择题设置,如图 D1 所示,并报告该任务的预测准确率。
- Path - VQA 是一个病理学问答(VQA)数据集,由 998 张病理图像和 32,799 个问答对组成(He 等人,2020)。所有图像均从医学教科书和在线数字图书馆中提取。每张图像都与一个或多个关于病理成像不同方面的问题相关,包括颜色、位置、外观、形状等。50.2% 的问答对是开放式问题(分为 7 类:什么、哪里、何时、谁的、如何以及多少)。49.8% 的问答对是简单的 “是 / 否” 封闭式问题。我们采用官方分割,其中训练 / 验证 / 测试分割分别包含 19,755、6,279 和 6,761 个问答对。
- Slake - VQA 是一个双语(英语和中文)放射学图像视觉问答数据集(Liu 等人,2021),包含 642 张标注图像和 14,028 个问答对,涵盖三种成像模态(CT、MRI 和胸部 X 光)、39 个器官系统和 12 种疾病。问题与放射学图像的各个方面相关,包括层面、质量、位置、器官、异常、大小、颜色、形状、知识图谱等,有开放式和封闭式问题。训练 / 验证 / 测试分割分别包含 9,849、2,109 和 2,070 个问答对。
- ROCO(Radiology Objects in Context)数据集是一个大规模的医学和多模态成像数据集(Pelka 等人,2018)。ROCO 图像来自 PubMed Central 开放访问 FTP 镜像上的出版物,这些图像被自动标记为放射学或非放射学图像。每张图像都有其标题、关键词、相应的 UMLS 语义类型(SemTypes)和 UMLS 概念唯一标识符(CUIs)。我们使用官方的放射学和非放射学训练集,其中包含 29,907 个图像 - 标题对,并设置了一个标题生成任务进行微调。我们仅在 ROCO 中包含具有 CC BY、CC BY ND、CC BY SA 和 CC0 许可的图像。
- ECG - QA 是一个用于评估心脏健康的传感器 - 文本多模态基准数据集(Oh 等人,2023)。它是第一个专门为基于 PTB - XL(Wagner 等人,2020)的心电图分析设计的问答数据集,包含各种问题模板,每个模板都经过心电图专家验证,以确保临床实用性。在 ECG - QA 上的出色表现表明能够掌握复杂的医学概念及其与原始波形信号的联系。ECG - QA 包含两种类型的问题:(1)单心电图问题;(2)比较两个心电图的问题;每种问题类型又包括(1)是 / 否问题、(2)多项选择题和(3)提供心电图相关属性的开放式问题。在这项工作中,我们专注于单心电图问题,其训练、验证和测试集分别包含 159,306、31,137 和 41,093 个样本。
D.2 多模态评估数据集
除了分布内数据集(上述部分有详细介绍),我们还纳入了三个分布外数据集来评估 Gemini 的多模态能力:
表 D2 | 用于多模态理解评估的数据集概述。OOD:分布外数据集。

- 《新英格兰医学杂志》(NEJM)图像挑战是一个著名的临床病例挑战系列,用于测试全球医学专业人员的诊断敏锐度和视觉观察技能(《新英格兰医学杂志》,2024)。每周,NEJM 都会展示一幅临床图像,并附带简短的病例描述。这些图像包括放射学图像、自然和皮肤镜下的皮肤图像、心电图、组织病理学图像、内窥镜图像和眼底镜图像。读者被邀请仔细分析照片,考虑患者的病史,并从五个可能的诊断候选中选择最终诊断。我们收集了 2005 年至 2023 年的 942 个 NEJM 图像挑战病例。每个病例都由一幅医学图像、一个相关问题(例如,“最可能的诊断是什么?”)、五个多项选择题选项和一个正确答案组成。有些病例在问题中还提供了带有相关临床背景或其他背景信息的文本说明。我们总共收集了 942 个病例,但最终为了公平比较,评估了 934 个病例(截至 10 月 12 日,20160519 和 20111103 这两个病例由于 GPT - 4V 过滤器阻止了被认为是露骨内容的图像而未被评估(Buckley 等人,2023))。
- USMLE - MM(多模态)是一个多模态多项选择题数据集,在www.usmle.org提供的样本考试中确定了 46 个问题,这些问题中包含图像。样本考试用于美国医学执照考试(USMLE)的备考。
- MMMU - HM(健康与医学)是公开可用基准 MMMU(大规模多学科多模态理解)验证集(Yue 等人,2023)的一个子集。MMMU - HM 包括 150 个与基础医学科学、临床医学、诊断和实验室医学、药学以及公共卫生领域相关的问题。
D.3 多模态任务的更多结果
在 ECG - QA 任务方面,为了扩展 Med - Gemini 处理原始生物医学信号以用于 ECG - QA 任务的能力,我们为 Gemini 1.0 Nano 添加了一个特定于心电图的编码器,并使用两种方法进行微调:保持 Gemini 模型不变(冻结)和微调 Gemini 模型(解冻)。我们将我们的 Med - Gemini - S 1.0 与相应的基线模型进行比较:将冻结 Gemini 模型的我们的模型与在输入提示中使用 SE - WR 心电图特征的 GPT - 4 进行比较(Oh 等人,2023),将解冻 Gemini 模型的我们的模型与基于\(M^{3}AE\)的心电图基础模型进行比较(Oh 等人,2023)。冻结和解冻 Gemini 的 Med - Gemini - S 1.0 在单心电图问题上的准确率分别为 57.7% 和 58.4%,比 GPT - 4(51.6%)高出 6.1%,比\(M^{3}AE\)(57.6%)高出 0.8%。
E. 长上下文理解任务的更多细节
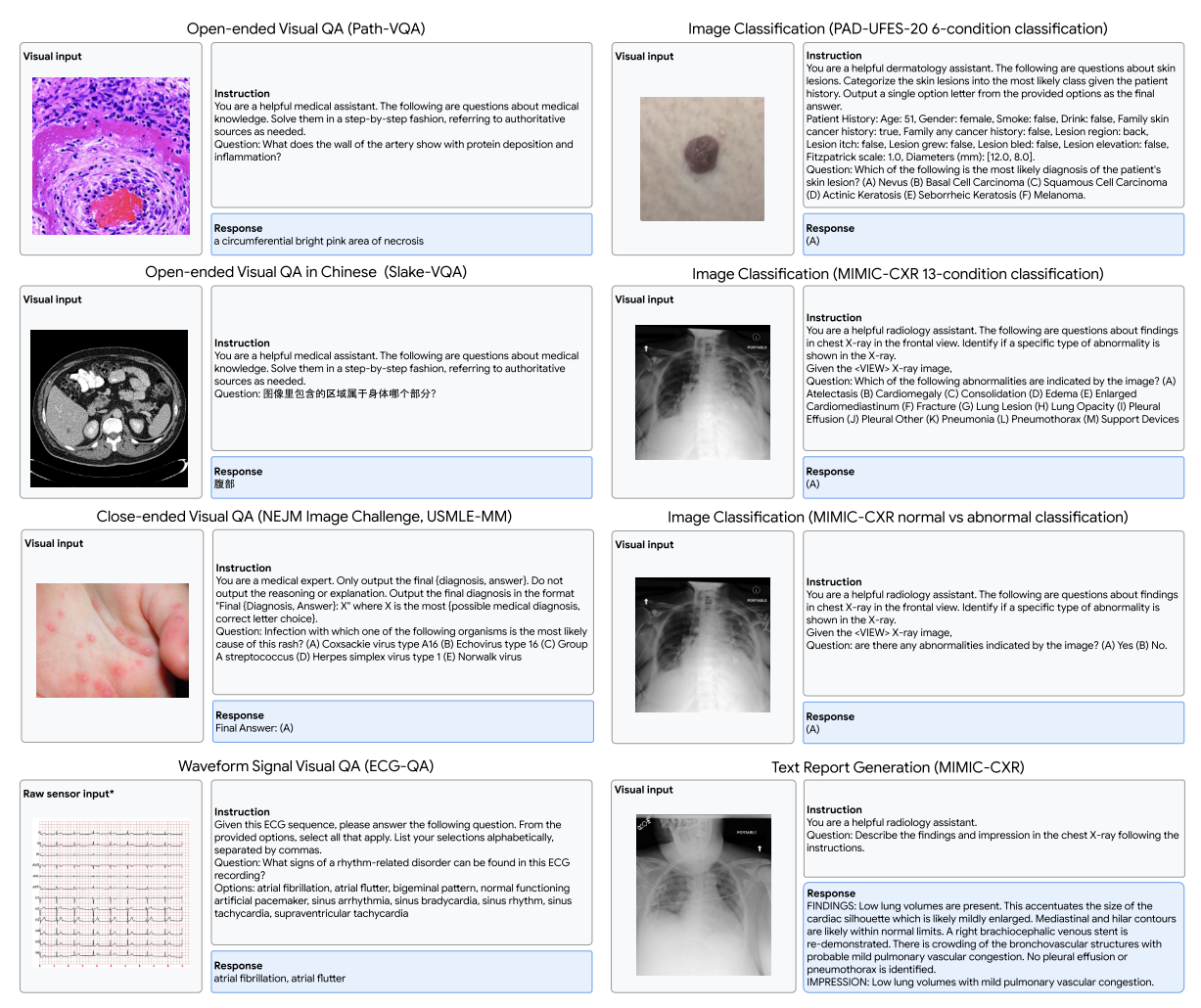
图D1|多模态理解任务的代表性示例和提示。Med-Gemini在各种任务中进行了评估,包括图像分类和视觉问答(VQA),证明了其分析和解释各种生物医学数据格式的能力。请注意,ECG-QA的输入是原始ECG传感器序列,在此可视化为来自PTB-XL的12导联ECG图像(瓦格纳等人,2020年)的报告。另请注意,三个MIMIC-CXR任务仅用于指令微调。
E.1 长上下文评估数据集
- MIMIC - III “大海捞针” 数据集是从 MIMIC - III(Johnson 等人,2016)中特别策划的一个数据集,用于在长电子健康记录(EHR)中进行细微医学状况的搜索检索任务。它旨在模拟一个与临床相关的 “大海捞针” 式挑战性问题(Gemini 团队,谷歌,2023)。MIMIC - III 是一个大型的公开可用医学数据库,包含入住重症监护病房患者的医疗记录。我们从 44 名具有 100 多份 “高价值” 临床笔记的独特患者中随机选择非结构化医疗笔记 。为了构建 “大海捞针” 示例,我们使用了先前的工作(Feder 等人,2022),该工作旨在通过以下方式从患者的电子健康记录文档集合中识别问题列表(病症 / 症状 / 手术):(1)使用基于机器学习的注释器标记医疗记录中所有问题的提及(文本片段);(2)基于规则选择和聚合提及内容,以确定问题是否实际存在。我们选择在聚合步骤中仅识别出 1 个证据片段的示例,然后通过基于规则的方法随机抽取 100 个阴性和 100 个阳性示例。然后将这 200 个选定的示例发送给 3 名人类医学评分者,以确定问题是否实际存在。具体来说,评分者会看到病症名称和检索到的支持证据片段。然后,评分者被要求回答问题:“根据提供的笔记摘录中的证据,选择患者确实患有的所有问题”。结果,根据多数投票 ,我们有 121 个阳性示例和 79 个阴性示例(Krippendorff's alpha 为 0.77,见表 E3)。多数投票标签随后被用作后续评估的真实标签。对于每个示例,它由一组医疗记录、一个关于感兴趣病症是否存在的测试问题以及一个二元真实标签组成。医疗记录的长度从 200,000 到 700,000 字不等。
- 医学教学视频问答(MedVidQA)是一个用于医学视觉答案定位(MVAL)任务的视频 - 语言跨模态数据集(Gupta 等人,2023)。三位医学信息学专家为从 YouTube 上提取的 899 个视频创建了 3,010 个与健康相关的教学问题,并通过在视频中注释时间戳来定位这些问题的视觉答案,即根据文本问题查询确定时间戳跨度。这些视频的平均时长为 383.29 秒。我们遵循官方的数据分割,其中 2,710、145 和 155 个问题及视觉答案分别用于训练、验证和测试。然而,由于 YouTube 视频访问限制(私人视频、已删除视频),有 7 个问题被排除在外。
- Cholec80 和 Cholec80 - CVS。Cholec80 数据集包含 13 名外科医生进行的 80 个高质量腹腔镜胆囊切除术视频(Twinanda 等人,2016)。Cholec80 是深度学习中用于腹腔镜胆囊切除术视频分析研究的最受欢迎的基准之一,最近在不同的视频理解任务中得到了广泛应用,包括手术阶段的时间分割(Chen 等人,2018;Golany 等人,2022)和手术工具检测(Leifman 等人,2022;Nwoye 等人,2019)。Cholec80 - CVS(Ríos 等人,2023)包含由熟练外科医生为 Cholec80 数据集中的每个视频提供的安全关键视图(CVS)标准注释。CVS(Strasberg 和 Brunt,2010)是一种强制性方法,由三个视觉标准定义,用于安全识别胆囊管和胆囊动脉,以最小化胆管损伤(BDI)的风险。对于 Cholec80 中的每个视频,熟练的外科医生选择至少满足一个 CVS 标准的不同视频片段,然后对于每个选定的视频片段,外科医生根据(Sanford 和 Strasberg,2014)以及(Mascagni 等人,2021)提出的原始评分系统的扩展,为三个 CVS 标准中的每一个分配 0、1 或 2 分。总体而言,Cholec80 - CVS 为 Cholec80 视频中的 572 个视频片段提供了 CVS 标准注释。我们评估 Med - Gemini - M 1.5 与 GPT - 4V 和 Resnet3D 相比的性能。需要注意的是,GPT - 4V 官方不支持视频数据作为输入。因此,我们以每秒 1 帧的速率从每个视频剪辑中采样帧,并将一系列帧组合作为模型的输入。在实验过程中,我们观察到 GPT - 4V 的视觉上下文长度有限,我们最多只能插入 300 张低分辨率图像。因此,我们过滤掉所有长度超过 5 分钟的视频剪辑。为了进行公平比较,我们在相同的过滤后视频剪辑子集上评估 Med - Gemini - M 1.5。为了对 Resnet3D 进行评估,我们将数据集随机分成 5 个连续的折叠,并分别评估每个验证折叠上的性能。报告的是所有五个折叠的平均准确率。
表 E1 | 用于长上下文能力评估的数据集概述。MVAL:医学视觉答案定位。

表 E2 | Med - Gemini - M 1.5 与基于启发式注释聚合的基线方法的性能比较。
E.2 长 EHR 理解任务的评分者一致性指标
为确保电子健康记录基准的可靠性,我们为 200 个示例问题中的每一个都收集了三位独立评分者的评分。以下指标显示了评分者之间的高度一致性:
- 杰卡德相似系数(Jaccard Similarity Index):用于衡量评分者选择集之间的重叠程度。设A、B和C分别代表每个评分者的选择集。所有评分者一致选择的杰卡德相似系数定义为\(J_{=3}=\frac{|A \cap B \cap C|}{|A \cup B \cup C|}\)。至少有两个评分者一致的杰卡德相似系数定义为\(J_{\geq2}=\frac{|(A \cap B) \cup(A \cap C) \cup(B \cap C)|}{|A \cup B \cup C|}\)。
-
克里彭多夫 α 系数(Krippendorff’s Alpha):一种为多个评分者设计的信度系数。
任务数量 \(J_{=3}\) \(J_{\geq2}\) 克里彭多夫 α 系数 病症存在判断 200 0.83 0.915 0.77 表 E3 | 长电子健康记录(EHR)理解任务的评分者一致性指标。
所有三位评分者选择完全相同的情况下,杰卡德相似系数(Jaccard similarity index)为 0.83,这表明一致性程度较高。当三位评分者中至少有两位做出相同选择时,更高的杰卡德指数 0.915 反映出很强的一致性。克里彭多夫 α 系数为 0.77,表明在电子健康记录数据中对医疗状况存在与否的判断上,评分者之间的一致性良好。

















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









