







欠采样(Undersampling)是一种处理类别不平衡数据问题的方法,通过减少多数类样本的数量来平衡数据集。由于样本较少的类别对模型预测能力至关重要,欠采样旨在降低多数类别的样本数,从而提高模型在不平衡数据集上的表现。
1. 欠采样的基本概念
在不平衡数据集中,模型通常倾向于预测多数类,导致少数类被忽视。欠采样通过随机选择和删除部分多数类样本,旨在使每个类别的样本数大致相等,从而让模型在训练时可以学习到每个类的特征。
2. 常见的欠采样方法
2.1 随机欠采样(Random Undersampling)
最简单且常用的方法,随机删除多数类中的部分样本。这种方法易于实现,但可能会丢失重要的信息。
2.2 聚类欠采样
首先对多数类样本进行聚类,然后从每个聚类中选择一个样本或特定数量的样本,减少样本数量的同时保留样本的多样性。这种方法可以保持代表性。
2.3 Tomek 连接
通过删除少数类与多数类样本之间的决策边界样本(Tomek 连接)来补充数据,达到减少多数类样本的目的。
2.4 Edited Nearest Neighbors(ENN)
根据邻近样本情况对多数类样本进行编辑,删除那些在其邻近类样本中更接近少数类样本的样本。
3. 欠采样的优缺点
3.1 优点
减少计算复杂性:通过减少训练样本的数量,可以减轻模型训练的计算负担,提高训练速度。
降低过拟合风险:在训练数据中减少冗余样本,有助于减少过拟合的风险。
3.2 缺点
信息损失:随机删除样本可能会丢失有价值的信息,导致模型性能下降。
可能导致欠拟合:如果删除过多的样本,模型可能无法学习到足够的特征,表现出欠拟合现象。
不保持样本的代表性:简单的随机欠采样可能导致训练集无法代表完整的数据分布,从而影响模型的泛化能力。
4. 示例代码
以下是一个使用 Python 中的 `imblearn` 库实现随机欠采样的示例代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from imblearn.under_sampling import RandomUnderSampler
from collections import Counter
# 1. 创建不平衡数据集
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.9, 0.1], n_informative=3,
n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
# 2. 检查原始数据集的类别分布
print("原始数据集类别分布:", Counter(y))
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 4. 实现随机欠采样
rus = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = rus.fit_resample(X_train, y_train)
# 5. 检查欠采样后的类别分布
print("欠采样后数据集类别分布:", Counter(y_resampled))
# 6. 可视化欠采样前后的数据分布
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(X_train[y_train == 0][:, 0], X_train[y_train == 0][:, 1], label='Class 0', alpha=0.5)
plt.scatter(X_train[y_train == 1][:, 0], X_train[y_train == 1][:, 1], label='Class 1', alpha=0.5)
plt.title('原始数据集')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.subplot(1, 2, 2)
plt.scatter(X_resampled[y_resampled == 0][:, 0], X_resampled[y_resampled == 0][:, 1], label='Class 0', alpha=0.5)
plt.scatter(X_resampled[y_resampled == 1][:, 0], X_resampled[y_resampled == 1][:, 1], label='Class 1', alpha=0.5)
plt.title('欠采样后数据集(随机欠采样)')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()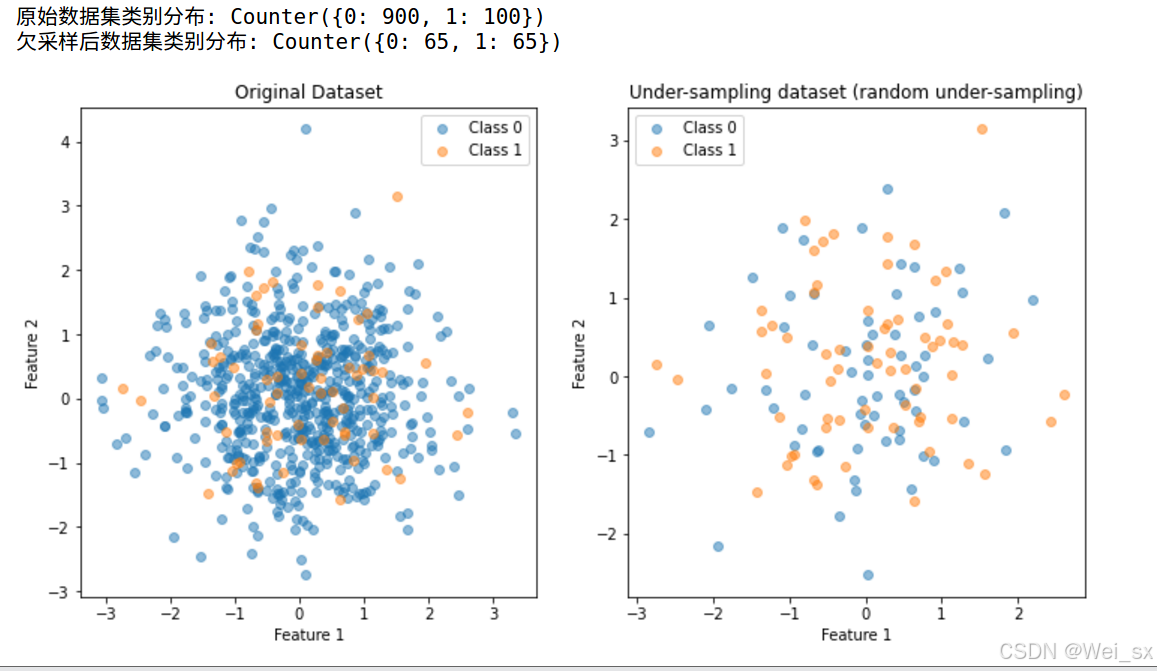
代码说明
创建不平衡数据集:使用 `make_classification` 函数生成一个模拟的不平衡数据集。
划分训练集和测试集:使用 `train_test_split` 函数将数据划分为训练集和测试集。
实现随机欠采样:创建 `RandomUnderSampler` 实例并调用 `fit_resample` 方法,以减少多数类样本。
检查类别分布:使用 `Counter` 检查欠采样前后的类别分布,确保多数类样本的数量减少。
可视化数据:通过散点图对比展示过采样前后的数据分布,帮助理解欠采样的影响。
5. 结果示例
运行上述代码后,将看到原始数据集与欠采样后数据集的类别分布差异,能够更好地理解欠采样在解决类别不平衡问题中的作用。


















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











