






前言
我大概花了1小时就完成了第一次接触到检测自己输入的视频,并不是说自己的优秀,而是yolo的特点就是,易上手,难修改。
B站:https://www.bilibili.com/video/BV1A44y1v7ig/
github:https://github.com/Whiffe/yolov5-deepsort
码云:https://gitee.com/YFwinston/yolov5-deepsort
平台:https://cloud.videojj.com/home
一.简介
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
DeepSort
SORT算法的思路是将目标检测算法(如YOLO)得到的检测框与预测的跟踪框的iou(交并比)输入到匈牙利算法中进行线性分配来关联帧间 ID。而DeepSORT算法则是将目标的外观信息加入到帧间匹配的计算中,这样在目标被遮挡但后续再次出现的情况下,还能正确匹配这个ID,从而减少ID的切换,达到持续跟踪的目的。
二,平台与开发环境
2.1 平台
平台还是选择:极链AI云平台
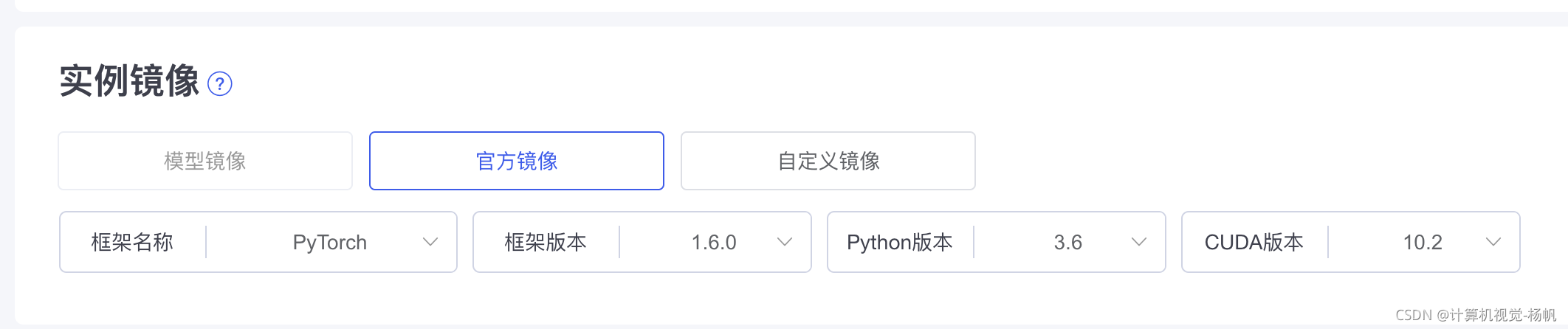
2.2 所需环境
pytorch 1.6.0
python 3.6
cuda 10.2
2.3 下载项目
进入平台的jupyter
进入 home 目录
cd home
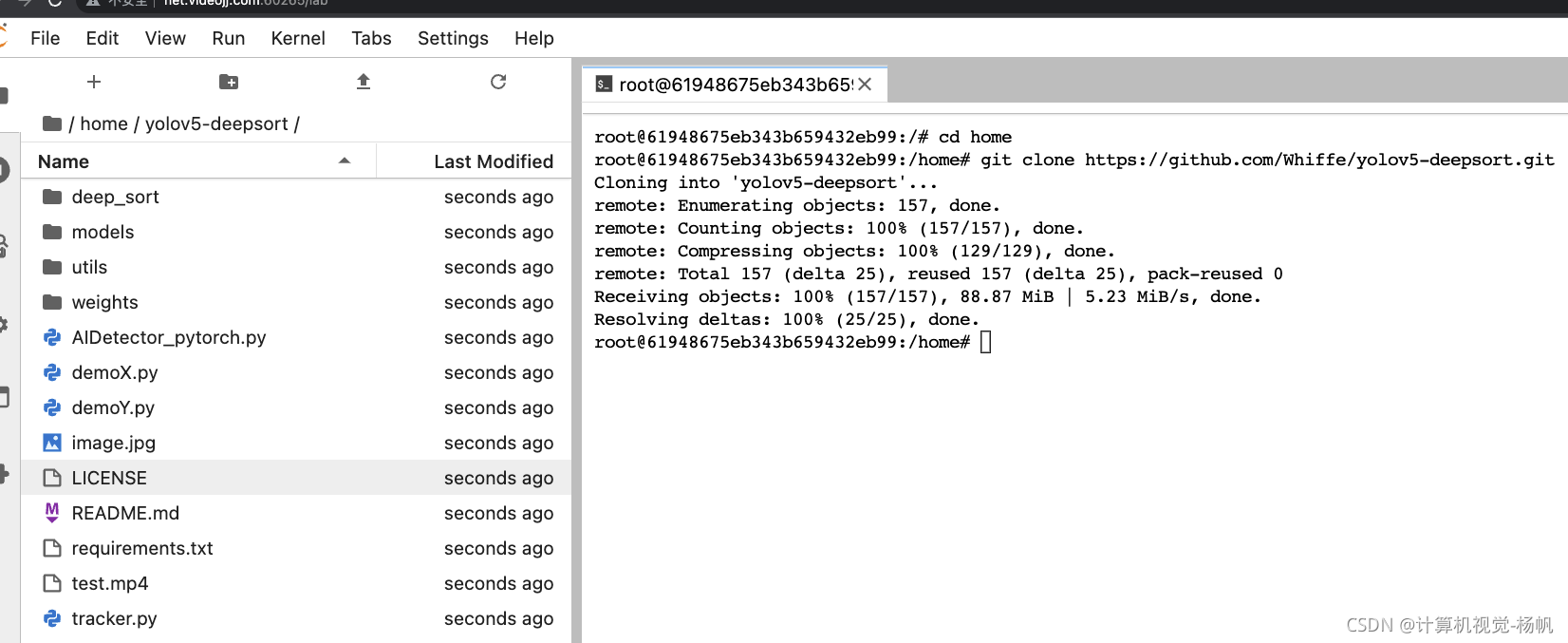
下载项目:
git clone https://github.com/Whiffe/yolov5-deepsort.git
如果github的网络不稳定,可以使用我同步在码云的代码
git clone https://gitee.com/YFwinston/yolov5-deepsort.git
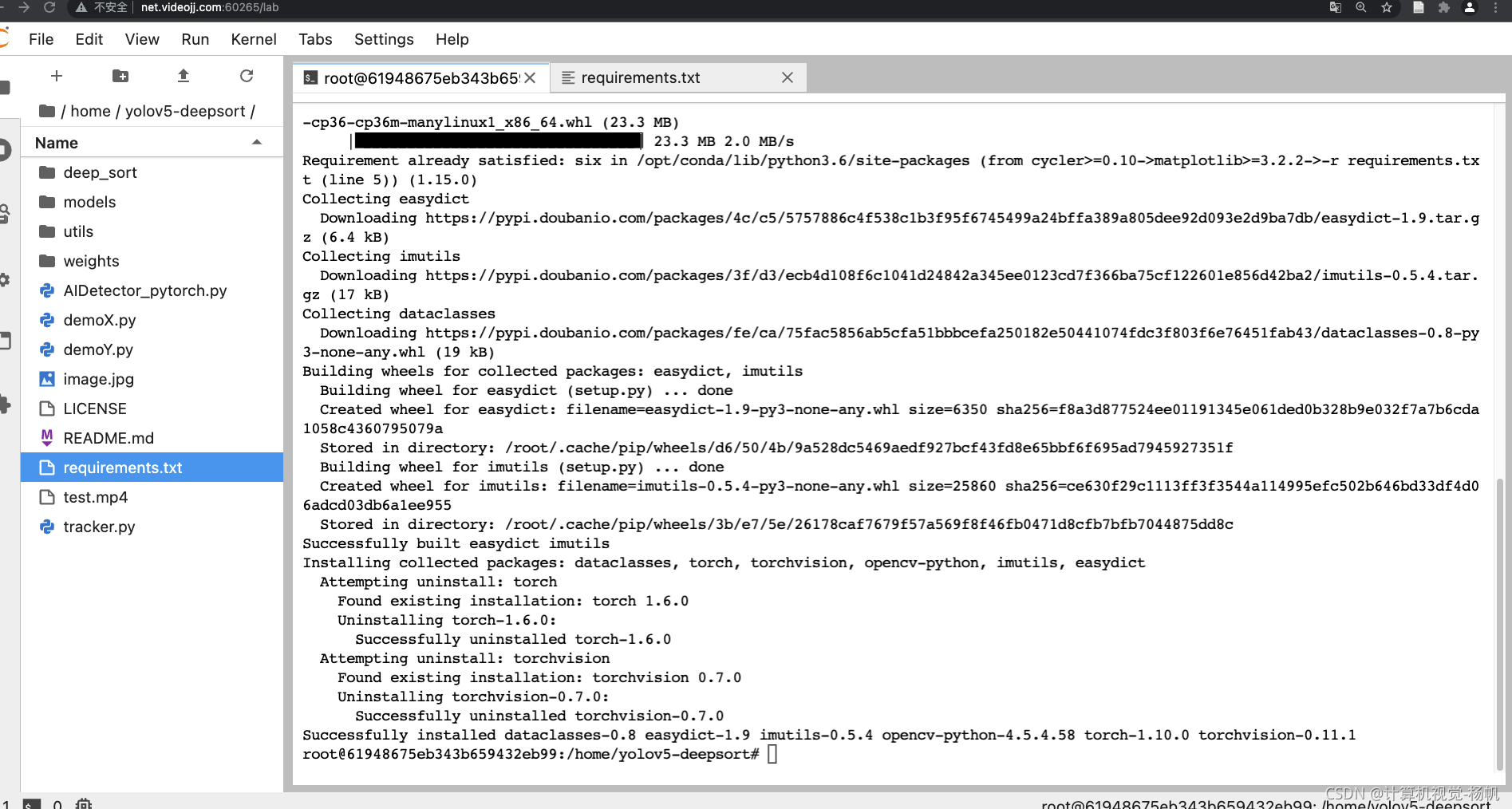
2.4 搭建项目
进入 yolov5-deepsort 中
cd yolov5-deepsort/
安装所有所需要的环境
pip install -r requirements.txt
3 检测自己的视频
在github中,我上传了一个test.mp4的视频,这个是用来做检测的视频,如果你想检测自己的,把这个视频替换了就行。
检测代码:
python demoY.py
看看检测结果:

注意,这里是demoY.py,用于在平台环境中的镜像中跑,如果你用的ubuntu实体电脑,就用命令:python demoX.py,这可以显示检测的中间过程。















 1849
1849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









