







1 模型量化的必要性:降低模型大小、加速推理、减少资源消耗
随着深度学习模型的日益复杂和庞大,其在资源受限的设备(如移动端、嵌入式设备)上的部署面临着巨大的挑战。即使在服务器端,部署大型模型也会带来高昂的计算成本和能源消耗。模型量化 (Model Quantization) 作为一种关键的模型压缩和加速技术应运而生。其核心思想是将模型中的浮点数(通常是 FP32 或 FP16)表示的权重和激活值转换为低精度整数(如 INT8、INT4)或半精度浮点数(FP16),从而带来以下显著优势:

- 降低模型大小 (Reduce Model Size): 使用低精度数值表示可以显著减少存储模型参数所需的空间。例如,将 FP32 模型量化为 INT8 模型,理论上模型大小可以减少为原来的四分之一。更小的模型尺寸意味着更低的存储成本、更快的模型加载速度以及更便捷的模型传输。
- 加速推理 (Accelerate Inference): 低精度计算通常具有更高的计算吞吐量。许多硬件平台(如现代 CPU、GPU 和专门的 AI 加速器)对低精度整数运算进行了专门的优化,可以实现比浮点运算更高的并行度和更低的延迟。这直接转化为更快的模型推理速度,提升用户体验。
- 减少资源消耗 (Reduce Resource Consumption): 低精度计算不仅更快,而且通常消耗更少的计算资源和能源。这对于在功耗敏感的移动设备和边缘设备上部署大型模型至关重要,同时也有助于降低服务器端的运营成本。
因此,模型量化是实现深度学习模型高效部署的关键技术之一,尤其是在资源受限或对推理速度有极高要求的场景下。
2 量化基本原理:低精度数值表示 (INT8, INT4, FP16)、量化映射、反量化
模型量化的核心在于使用低精度数值格式来近似表示原始的高精度浮点数。常见的低精度数值表示包括:
- INT8 (8-bit Integer): 使用 8 位整数表示数值,范围通常为 [-128, 127] 或 [0, 255]。INT8 量化在保持较高精度的同时,能显著降低模型大小和加速推理,是目前应用最广泛的量化精度之一。
- INT4 (4-bit Integer): 使用 4 位整数表示数值,范围通常为 [-8, 7] 或 [0, 15]。INT4 量化可以进一步降低模型大小,但在精度方面通常会有更大的损失。适用于对模型尺寸有极致要求的场景。
- FP16 (Half-Precision Floating Point): 使用 16 位浮点数表示数值,相比 FP32 精度有所降低,但仍高于 INT8。FP16 在某些硬件上可以提供比 FP32 更高的计算吞吐量,同时精度损失相对较小,常用于对精度要求较高的场景。
量化映射 (Quantization Mapping): 将高精度浮点数值映射到低精度整数值的过程称为量化映射。这个过程通常涉及到以下关键参数:
- 缩放因子 (Scale Factor, s): 用于将低精度整数值映射回近似的浮点数值。
- 零点 (Zero Point, z): 用于表示浮点数零值在低精度整数范围内的位置。
根据是否包含零点,量化可以分为:
- 对称量化 (Symmetric Quantization): 量化范围关于零点对称,通常零点为 0。适用于权重分布中心接近零的情况。
- 非对称量化 (Asymmetric Quantization): 量化范围不关于零点对称,需要使用零点来准确表示浮点零值。适用于激活值等分布不均匀的情况。
根据量化粒度,可以分为:
- 逐张量量化 (Per-tensor Quantization): 对整个张量(例如,一个卷积层的权重或一个激活张量)使用相同的缩放因子和零点。实现简单,但可能无法很好地处理张量内数值分布差异较大的情况。
- 逐通道量化 (Per-channel Quantization): 对张量的每个通道(例如,卷积层的每个输出通道的权重)使用独立的缩放因子和零点。能更好地适应张量内部的数值分布差异,通常能获得更高的精度,但实现相对复杂。
反量化 (Dequantization): 将低精度整数值映射回近似的浮点数值的过程称为反量化。反量化使用量化映射中得到的缩放因子和零点进行计算。虽然在推理过程中通常直接使用低精度数值进行计算,但在某些场景下(例如,需要与浮点数进行混合计算或进行精度评估),需要将低精度数值反量化回浮点数。
3 训练后量化 (Post-Training Quantization, PTQ) 算法详解与实践
训练后量化 (Post-Training Quantization, PTQ) 是一种在模型训练完成后直接对模型进行量化的方法。其优点是不需要重新训练模型,实现简单快捷,适用于对精度损失不敏感或者数据量有限的场景。
3.1 PTQ 算法流程:权重和激活值量化、校准数据集、量化参数选择
PTQ 的典型流程包括以下步骤:
- 权重和激活值量化: 对模型中的权重参数和激活值进行量化。权重通常可以直接进行静态量化,而激活值的量化则需要在推理过程中收集其动态范围。
- 校准数据集 (Calibration Dataset): 由于激活值的动态范围需要在推理过程中确定,PTQ 通常需要一个小的、具有代表性的校准数据集。该数据集用于运行模型的前向推理,以收集激活值的统计信息(例如,最小值、最大值或分布)。校准数据集的选择至关重要,它应该能够覆盖模型在实际应用中遇到的数据分布,以确保量化参数的准确性。选择校准数据集时,应尽量使其包含模型在实际应用中会遇到的各种输入样本,以保证激活值范围的代表性。
- 量化参数选择: 基于校准数据集收集到的激活值统计信息以及权重自身的数值范围,选择合适的量化参数,包括缩放因子和零点。不同的 PTQ 算法会采用不同的策略来选择这些参数,以最小化量化误差。
3.2 PTQ 量化方法:Min-Max Quantization, KL 散度量化, Percentile Quantization
常见的 PTQ 量化方法包括:
-
Min-Max Quantization: 这是最简单的一种 PTQ 方法。对于每个张量 ( T ),它找到其最小值 ( T_{min} ) 和最大值 ( T_{max} ),然后将这个浮点范围线性映射到低精度整数的范围 ( [q_{min}, q_{max}] ) (例如,对于 INT8,( q_{min} = -128, q_{max} = 127 ))。量化过程可以表示为:
q = r o u n d ( v − T m i n T m a x − T m i n × ( q m a x − q m i n ) + q m i n ) q = round\left( \frac{v - T_{min}}{T_{max} - T_{min}} \times (q_{max} - q_{min}) + q_{min} \right) q=round(Tmax−Tminv−Tmin×(qmax−qmin)+qmin)
其中 ( v ) 是原始浮点数值,( q ) 是量化后的整数值。反量化过程为:
v ′ = T m i n + ( q − q m i n ) × T m a x − T m i n q m a x − q m i n v' = T_{min} + (q - q_{min}) \times \frac{T_{max} - T_{min}}{q_{max} - q_{min}} v′=Tmin+(q−qmin)×qmax−qminTmax−Tmin
- 优点: 实现简单,计算速度快。
- 缺点: 对离群点(极端的异常值)非常敏感。
-
KL 散度量化 (Kullback-Leibler Divergence Quantization): 这种方法旨在最小化量化前后激活值分布的差异。它通过在校准数据集上运行模型,收集激活值的浮点分布 ( P_{float}(x) ),然后尝试找到一组量化参数(缩放因子 ( s ) 和零点 ( z )),使得量化后的分布 ( P_{quant}(q) ) 映射回浮点空间后的分布 ( P’_{float}(x’) ) 与原始浮点分布之间的 KL 散度最小。KL 散度定义为:
D K L ( P ∣ ∣ Q ) = ∑ x P ( x ) log ( P ( x ) Q ( x ) ) D_{KL}(P || Q) = \sum_{x} P(x) \log \left( \frac{P(x)}{Q(x)} \right) DKL(P∣∣Q)=x∑P(x)log(Q(x)P(x))
在这里, P = P f l o a t P = P_{float} P=Pfloat 和 Q = P f l o a t ′ Q = P'_{float} Q=Pfloat′ 。该方法通常通过搜索不同的量化参数组合,找到使 KL 散度最小的参数。
- 优点: 通常比 Min-Max 量化能获得更高的精度,尤其是在激活值分布不均匀的情况下。KL 散度能够衡量两个概率分布的相似程度,通过最小化 KL 散度,可以保证量化后的激活值分布尽可能地接近原始分布,从而减少信息损失。
- 缺点: 计算成本相对较高,需要计算浮点和量化分布的 KL 散度并进行搜索。
-
百分比量化 (Percentile Quantization): 为了缓解 Min-Max 量化对离群点的敏感性,百分比量化方法会忽略一定比例的极端值。例如,可以选择一个百分比 p p p (如 99.9%),然后找到激活值分布中位于 [ p / 2 , 100 − p / 2 ] [p/2, 100 - p/2] [p/2,100−p/2] 百分比范围内的最小值 T m i n ′ T'_{min} Tmin′ 和最大值 T m a x ′ T'_{max} Tmax′ ,并基于这个截断后的范围进行 Min-Max 量化。
- 优点: 对离群点具有一定的鲁棒性,可以提高量化精度。通过忽略少量的极端值,可以避免整个量化范围被这些离群点拉伸,从而提高对主体数值的量化精度。
- 缺点: 需要选择合适的百分比,选择不当可能会损失一部分信息。百分比的选择需要根据具体的数据分布进行调整。
-
移动平均量化 (Moving Average Quantization): 这种方法通常用于量化激活值,它在推理过程中维护激活值范围的移动平均,以更平滑地适应激活值的动态变化。通过维护一个滑动窗口的激活值范围,可以更好地应对激活值分布随时间变化的情况。
3.3 PTQ 代码实现与工具使用 (TensorRT, ONNX Runtime, PyTorch Quantization Toolkit)
许多深度学习框架和推理引擎都提供了 PTQ 的工具和 API:
- TensorRT (NVIDIA): NVIDIA 提供的用于高性能深度学习推理的 SDK,支持对多种框架训练的模型进行 INT8 和 FP16 的训练后量化。TensorRT 能够进行图优化、层融合等操作,并结合量化进一步提升推理性能,尤其在 NVIDIA 的 GPU 硬件上表现出色。
- ONNX Runtime (Microsoft): 一个跨平台的推理引擎,支持多种硬件和操作系统。ONNX Runtime 提供了丰富的 API 用于执行模型的训练后量化,支持 INT8 和其他低精度格式。其跨平台特性使其成为部署在不同环境下的理想选择,可以在 CPU、GPU 和其他加速器上运行。
- PyTorch Quantization Toolkit (PyTorch): PyTorch 自身也提供了量化工具包
torch.quantization,支持训练后静态量化和动态量化。用户可以方便地使用这些 API 对 PyTorch 模型进行量化,并部署到支持低精度计算的硬件上。PyTorch 的量化工具包提供了灵活的接口,允许用户自定义量化策略。
使用这些工具通常涉及以下步骤:加载预训练模型、准备校准数据集、调用相应的量化 API、导出量化后的模型。这些工具通常会处理量化参数的选择和映射等底层细节,简化了 PTQ 的流程。
4 量化感知训练 (Quantization-Aware Training, QAT) 算法深度解析
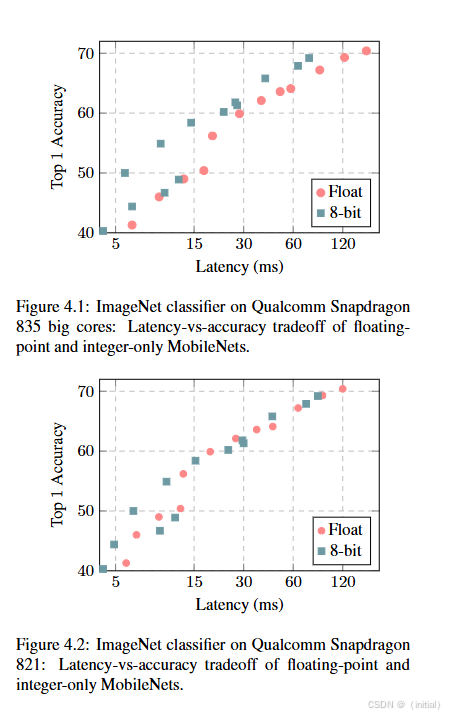
4.1 QAT 算法原理:模拟量化操作、量化误差反向传播、量化节点插入
QAT 的核心原理包括:
-
模拟量化操作 (Simulate Quantization Operations): 在训练过程中,对于模型的权重 ( W ) 和激活值 ( A ),QAT 会模拟将其量化到目标低精度格式,然后再反量化回浮点数的过程。这个模拟的量化和反量化操作会引入与真实量化类似的误差。对于一个浮点数值 ( x ),模拟量化操作可以表示为:
Q ( x ) = d e q u a n t ( q u a n t ( x , s , z ) , s , z ) Q(x) = dequant(quant(x, s, z), s, z) Q(x)=dequant(quant(x,s,z),s,z)
其中 q u a n t ( x , s , z ) = r o u n d ( x / s + z ) quant(x, s, z) = round(x/s + z) quant(x,s,z)=round(x/s+z) 是量化操作, d e q u a n t ( q , s , z ) = ( q − z ) × s dequant(q, s, z) = (q - z) \times s dequant(q,s,z)=(q−z)×s是反量化操作, s s s 是缩放因子, z z z 是零点。
-
量化误差反向传播 (Backpropagation of Quantization Errors): 由于真实的量化操作 ( quant ) 包含取整操作 ( round ),这是一个不可导的函数,无法直接进行梯度反向传播。QAT 通常使用 Straight-Through Estimator (STE) 来近似地估计量化误差的梯度。STE 的基本思想是在前向传播时执行完整的伪量化操作,但在反向传播时,直接将梯度 ( \frac{\partial L}{\partial Q(x)} ) 近似地传递给量化前的浮点数值 ( x ),即:
∂ L ∂ x ≈ ∂ L ∂ Q ( x ) \frac{\partial L}{\partial x} \approx \frac{\partial L}{\partial Q(x)} ∂x∂L≈∂Q(x)∂L
这样,梯度可以“直通”量化操作,使得模型参数能够根据量化误差进行更新。
-
量化节点插入 (Insertion of Quantization Nodes): 在模型的计算图中,QAT 会在需要进行量化的层(例如,卷积层、全连接层)的权重和激活值路径上插入模拟量化的节点。这些节点负责在训练过程中执行伪量化操作,模拟真实部署时的量化和反量化过程。
4.2 QAT 训练流程与技巧:量化策略选择、微调策略、精度损失控制
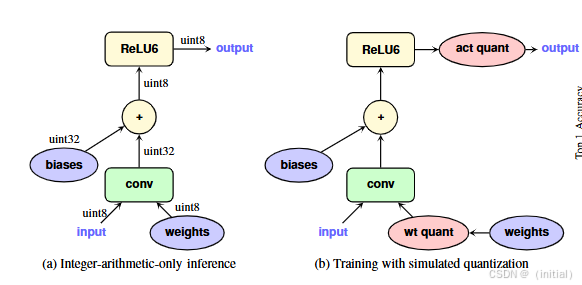
QAT 的典型训练流程和一些关键技巧包括:
- 初始化: 通常使用预训练好的浮点模型作为 QAT 的起点。这可以加速收敛并提高最终精度。
- 插入量化节点: 在模型的计算图中插入模拟量化的节点,指定需要量化的层和目标精度。可以根据对模型不同层敏感度的分析来选择需要量化的层。
- 量化策略选择: 选择合适的量化策略,例如:
- 逐步量化: 在训练初期保持部分层为浮点精度,逐步增加量化层的数量,让模型逐步适应量化。这可以避免模型在训练初期就因为剧烈的量化误差而难以收敛。
- 混合精度量化 (Mixed-Precision QAT): 对模型中不同敏感度的层采用不同的量化精度,例如,对那些对精度影响较大的层(如某些关键的卷积层或注意力层)使用更高的精度(如 FP16),而对其他不太敏感的层使用更低的精度(如 INT8)。
- 微调 (Fine-tuning): 在插入量化节点后,使用训练数据对模型进行微调。微调的目的是让模型学习适应量化操作带来的误差,并尽可能恢复精度。通常需要比正常训练更少的轮数。
- 微调策略:
- 学习率调整: 通常需要使用比正常训练更小的学习率进行微调,以避免过大的梯度更新破坏模型对量化的适应。
- 训练轮数: 微调的轮数需要根据具体任务和模型进行调整,通常比从头开始训练要少。
- 冻结部分层: 在微调初期可以冻结部分对量化不敏感的层,只微调对量化敏感的层,以加快训练速度。
- 精度损失控制: 在 QAT 过程中需要密切关注模型的精度变化,并采取相应的措施来控制精度损失,例如:
- 使用更大的模型容量: 适当增加模型的参数量,使其有更强的表达能力来弥补量化带来的精度损失。
- 更长的训练时间: 进行更长时间的微调,让模型有足够的时间来适应量化。
- 使用更平滑的量化函数: 一些研究提出了更平滑的伪量化函数,以更好地近似真实的量化过程,并改善梯度传播。
4.3 QAT 代码实现与工具使用 (TensorFlow Model Optimization Toolkit)
TensorFlow 提供了 Model Optimization Toolkit,其中包含了用于执行 QAT 的丰富工具和 API。使用该工具包可以方便地在 TensorFlow 模型中插入量化感知层,并进行 QAT 训练。该工具包提供了易于使用的 API,可以定义量化策略、插入量化节点并执行微调训练。
类似地,PyTorch 也提供了 torch.quantization 模块,支持用户自定义量化策略并进行 QAT 训练。PyTorch 的量化工具包提供了更底层的接口,允许用户更灵活地控制量化过程。
使用这些工具通常涉及以下步骤:加载预训练模型、指定量化配置、使用工具包提供的 API 将模型转换为量化感知模型、进行微调训练、导出量化后的模型。
5 量化精度与性能 trade-off 分析与最佳实践:根据应用场景选择合适的量化方案
模型量化往往需要在精度和性能之间进行权衡。更低的精度通常意味着更高的压缩率和更快的推理速度,但也可能导致模型性能下降。选择合适的量化方案需要根据具体的应用场景和需求进行权衡:
- 移动端和嵌入式设备: 对模型大小和功耗有严格的限制,通常会优先考虑 INT8 甚至 INT4 量化,以牺牲一定的精度为代价来获得更小的模型体积和更低的功耗。在这些场景下,通常会更倾向于使用 PTQ,因为其实现简单,不需要额外的训练成本。
- 服务器端高吞吐量推理: 对推理速度要求较高,INT8 量化通常是一个很好的选择,可以在保持较高精度的前提下显著提升吞吐量。FP16 也可以作为精度要求较高的备选方案,尤其在支持 FP16 加速的硬件上。
- 精度敏感型应用 (如医疗、金融): 对精度要求极高,可能需要更谨慎地选择量化方案,或者采用精度损失更小的 QAT 方法,甚至只使用 FP16 量化。在这些场景下,通常会投入更多的训练资源来使用 QAT,以尽可能减小精度损失。
最佳实践建议:
- 基准测试: 在应用任何量化方法之前,务必对原始浮点模型的性能(精度和速度)进行基准测试,作为后续量化效果的对比。这有助于量化方案的选择和效果评估。
- 逐步量化: 可以尝试不同的量化精度(例如,从 FP16 到 INT8 再到 INT4)和不同的量化方法(PTQ vs. QAT),逐步探索最佳的量化方案。
- 精度评估: 对量化后的模型进行全面的精度评估,确保精度损失在可接受的范围内。可以使用与原始任务相同的评估指标,并在真实数据集上进行评估。
- 性能评估: 在目标硬件上测试量化后模型的推理速度和资源消耗,验证性能提升是否符合预期。不同的硬件对不同精度的量化加速效果不同。
- 关注硬件支持: 不同的硬件平台对不同精度的量化支持程度不同,选择量化方案时需要考虑目标硬件的能力。例如,某些硬件可能对 INT8 有专门的加速单元,而对 INT4 的支持较弱。
6 进阶主题 (Advanced Topics)
除了训练后量化 (PTQ) 和量化感知训练 (QAT) 这两种主要的量化方法外,还有一些更高级或更专门的量化技术,可以在特定场景下提供额外的性能提升或精度优化:
- 混合精度量化 (Mixed-Precision Quantization): 传统的量化方法通常对模型的所有层都采用相同的量化精度(例如,全部 INT8 或全部 FP16)。然而,模型中不同的层对量化误差的敏感度不同。混合精度量化 的思想是根据模型不同层的敏感性,采用不同的量化精度。例如,对那些对精度影响较大的层(如某些关键的卷积层或注意力层)使用更高的精度(如 FP16),而对其他不太敏感的层使用更低的精度(如 INT8 或 INT4)。
- 优点: 可以在保持较高整体精度的同时,进一步降低模型大小和加速推理。
- 挑战: 需要确定模型中哪些层对精度更敏感,以及为每个层选择合适的量化精度,这通常需要进行细致的分析和实验。一些研究工作也在探索自动化混合精度量化策略的方法。
- 动态量化 (Dynamic Quantization): 前面介绍的 PTQ 和 QAT 方法通常是静态量化,即在推理或训练前就确定了量化参数。动态量化 主要应用于量化激活值。它的核心思想是在推理过程中,根据实际输入的激活值的动态范围来确定量化参数(例如,缩放因子)。权重通常仍然是静态量化的。
- 优点: 可以更好地适应不同输入数据分布带来的激活值范围变化,有时能获得比静态量化更高的精度。
- 缺点: 需要在推理过程中进行额外的计算来确定量化参数,可能会引入一定的额外开销。动态量化更常用于 CPU 推理场景。
- 稀疏性与量化的结合 (Sparse Quantization): 稀疏性 (Sparsity) 是一种通过将模型中一部分权重设置为零来减少模型参数数量的技术。将稀疏性与量化相结合,可以进一步提升模型的压缩率和推理速度。例如,可以先对模型进行稀疏化处理,然后再对剩余的非零权重进行量化。
- 优点: 可以实现更高的模型压缩率和更快的推理速度。
- 挑战: 稀疏模型的训练和推理需要特定的硬件和软件支持才能发挥最佳性能。
- 权重和激活值二值化/三值化 (Weight and Activation Binarization/Ternarization): 这是更激进的量化方法,将权重和激活值量化为仅有的两个值(通常是 +1 和 -1,即二值化)或三个值(例如,+1, 0, -1,即三值化)。
- 优点: 可以实现极高的模型压缩率和理论上的极快推理速度。
- 缺点: 通常会带来较大的精度损失,需要在模型结构和训练方法上进行特殊的设计才能在某些任务上取得可接受的结果。这种方法更常用于对计算资源极其有限的场景。
内容同步在我的微信公众号 智语Bot
参考资料
-
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
- Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., & Kalenichenko, D. (2018).
- Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7032-7040.
- (介绍了训练感知量化 (QAT) 的早期工作)
-
8-bit Inference with TensorRT
- NVIDIA Developer Blog.
- (https://developer.nvidia.com/blog/8-bit-inference-with-tensorrt/)
- (介绍了如何使用 TensorRT 进行 INT8 量化)
-
Post-training Integer Quantization
- TensorFlow Model Optimization Toolkit Documentation.
- (https://www.tensorflow.org/lite/performance/post_training_quantization)
- (TensorFlow 关于训练后量化 (PTQ) 的官方文档)
-
Quantization Aware Training
- TensorFlow Model Optimization Toolkit Documentation.
- (https://www.tensorflow.org/lite/performance/quantization_aware_training)
- (TensorFlow 关于量化感知训练 (QAT) 的官方文档)
-
PyTorch Quantization
- PyTorch Documentation.
- (https://pytorch.org/docs/stable/quantization.html)
- (PyTorch 官方提供的量化工具包文档)
-
ONNX Runtime Quantization
- ONNX Runtime Documentation.
- (https://onnxruntime.ai/docs/performance/quantization.html)
- (ONNX Runtime 关于模型量化的官方文档)
-
Mixed Precision Training
- NVIDIA Developer Blog.
- (https://developer.nvidia.com/blog/mixed-precision-training-deep-neural-networks/)
- (虽然主要讲的是混合精度训练,但也涉及到 FP16 等低精度浮点数的使用)
-
Going Deeper with INT8 Inference
- Intel AI Blog.
- (可以搜索相关文章,了解 Intel 平台上的 INT8 推理优化)
-
Learning both Weights and Connections for Efficient Neural Networks
- Han, S., Mao, H., & Dally, W. J. (2015).
- Advances in neural information processing systems, 28.
- (虽然主要讲的是模型剪枝,但稀疏性与量化常常结合使用)



















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











