






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
CBAM(CBAM-CNN)是一种用于计算机视觉领域的卷积神经网络结构,它能够有效地从图像中学习关注和调整。CBAM模型结合了通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module)两个部分,用于提升卷积神经网络的性能。
通道注意力模块(CAM)旨在通过学习不同通道之间的相关性,为每个通道分配适当的注意力权重。该模块首先通过全局平均池化获得整个通道的平均值,然后使用两个全连接层来生成一组注意力权重。这些权重用于调整每个通道的特征图。
空间注意力模块(SAM)旨在学习图像中不同空间区域的重要性。该模块通过对特征图在不同空间维度上进行最大池化和平均池化操作,然后使用一个卷积层来生成一组注意力权重。最后,这些权重被应用于原始特征图,以增强具有重要空间信息的区域。
通过结合通道注意力模块和空间注意力模块,CBAM能够动态地选择和调整特征图的通道和空间注意力,从而提取更准确和具有区分力的特征表示。这种注意力机制有助于网络更好地对图像进行感知,从而改善图像分类、目标检测、图像分割等计算机视觉任务的性能。
针对预测任务,可以使用CBAM-CNN模型进行图像分类或目标检测。在图像分类任务中,CBAM-CNN可以通过自适应地关注重要的通道和空间区域,提取图像特征并进行分类。在目标检测任务中,CBAM-CNN可以辅助检测网络对目标区域进行准确定位和分类。
需要注意的是,CBAM-CNN只是一种网络结构,具体的预测研究还需要根据具体的任务和数据集进行调整和优化。
基于CBAM(Convolutional Block Attention Module,卷积块注意力模块)-CNN(卷积神经网络)的预测研究,是一种将注意力机制融入传统卷积神经网络中的先进方法,旨在通过有选择地强调输入特征图中的关键信息部分,来提高模型的预测性能。以下是这种方法的基本概念、优势以及在不同领域的应用概述。
基本概念
-
CBAM模块:该模块由两个子模块组成,即通道注意力(Channel Attention)和空间注意力(Spatial Attention)。通道注意力根据每个通道的重要性加权特征图,而空间注意力则关注于图像中哪些位置更重要。这两个过程结合,使网络能够在处理信息时,不仅考虑“什么”信息重要,还考虑“哪里”信息重要,从而提升模型的特征表示能力。
-
集成进CNN:CBAM模块可以灵活地插入到任何标准CNN架构中,如VGG、ResNet、Inception等,不改变原有网络架构的基本结构,仅通过注意力机制优化特征提取过程,增强了模型对关键特征的聚焦能力。
优势
- 提高模型效率:通过关注输入图像的关键部分,CBAM能有效减少计算负担,提升模型在有限计算资源下的性能。
- 增强特征表示:注意力机制帮助模型在复杂背景下更好地识别和区分目标特征,提升模型的泛化能力和预测准确性。
- 解释性增强:注意力地图可以直观展示模型关注的图像区域,增加模型决策的透明度和可解释性。
应用领域
- 图像分类与识别:CBAM-CNN在图像分类任务中展现出显著的性能提升,尤其是在面临复杂背景和小目标识别时。
- 医学影像分析:如肺结节检测、细胞分类等,通过注意力机制能更准确地定位和分析病灶区域。
- 自然语言处理(NLP):虽然CBAM原是为视觉任务设计,但其思想也被借鉴到NLP中,通过注意力机制改进文本理解和生成任务。
- 遥感图像分析:在土壤湿度预测、农作物监测、城市规划等领域,通过聚焦关键区域,提升图像分析的精确度。
- 视频分析:在运动物体追踪、行为识别等任务中,CBAM有助于捕捉时序数据中的关键帧和区域,提升模型的时空理解能力。
总之,基于CBAM-CNN的预测研究通过集成注意力机制,不仅提升了预测模型的准确性和效率,也为深度学习模型的可解释性提供了新的视角,其在多个领域的应用前景广阔。
📚2 运行结果

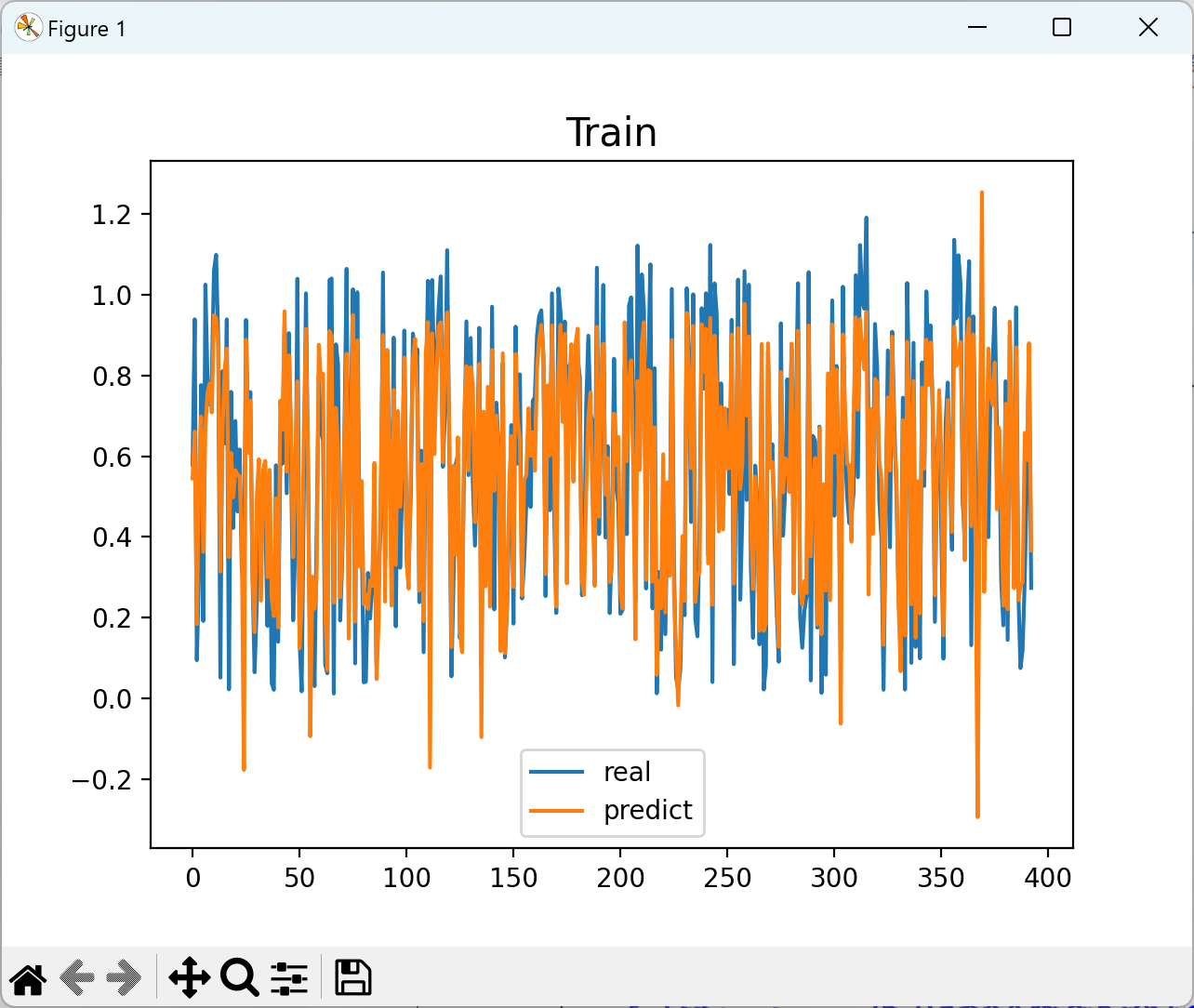
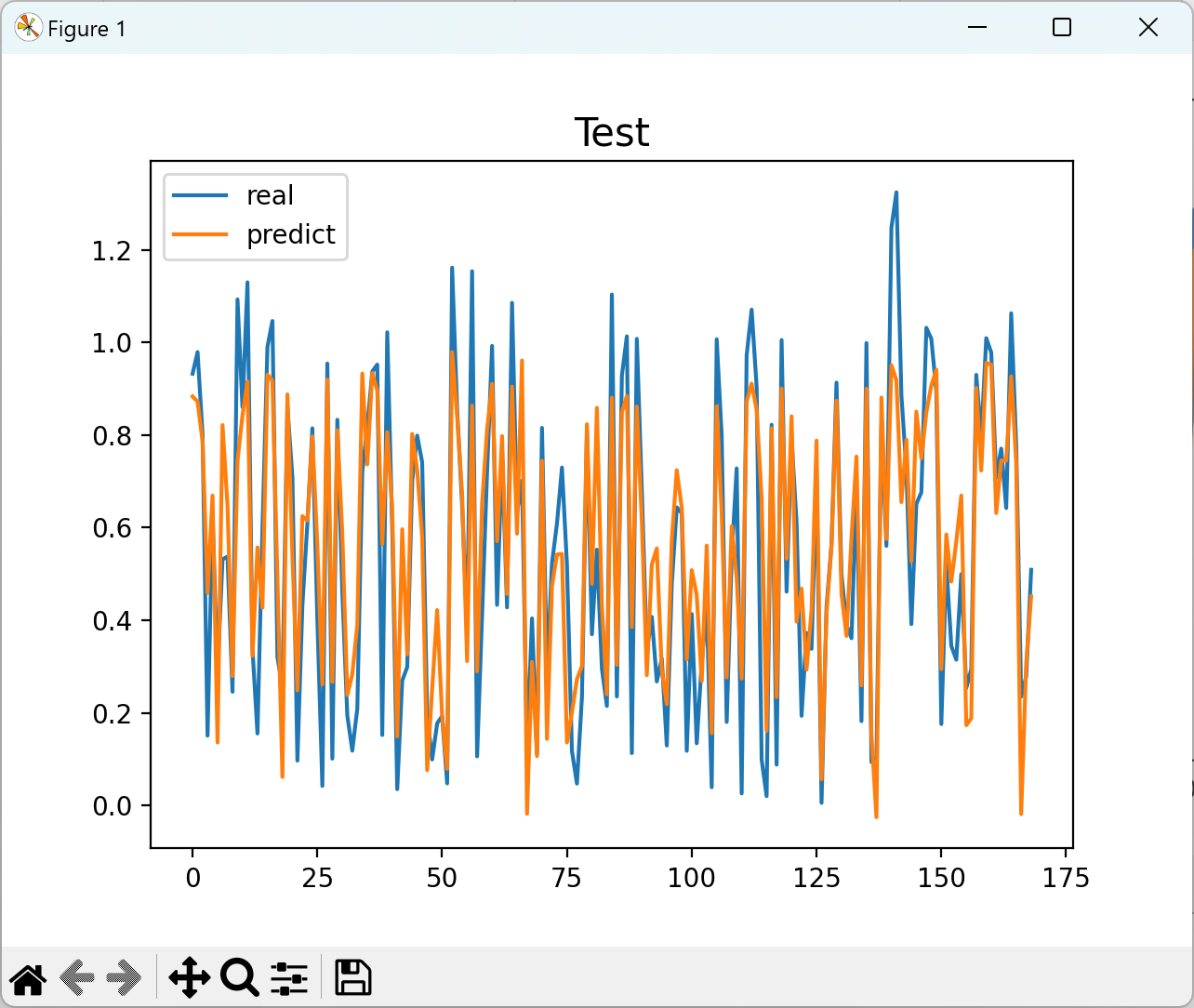

部分代码:
def forward(self, x):
# 1.最大池化分支
max_branch = self.MaxPool(x)
# 送入MLP全连接神经网络, 得到权重
max_in = max_branch.view(max_branch.size(0), -1)
max_weight = self.fc_MaxPool(max_in)
# 2.全局池化分支
avg_branch = self.AvgPool(x)
# 送入MLP全连接神经网络, 得到权重
avg_in = avg_branch.view(avg_branch.size(0), -1)
avg_weight = self.fc_AvgPool(avg_in)
# MaxPool + AvgPool 激活后得到权重weight
weight = max_weight + avg_weight
weight = self.sigmoid(weight)
# 将维度为b, c的weight, reshape成b, c, 1, 1 与 输入x 相乘
h, w = weight.shape
# 通道注意力Mc
Mc = torch.reshape(weight, (h, w, 1))
# 乘积获得结果
x = Mc * x
return x
class SpatialAttentionModul(nn.Module): # 空间注意力模块
def __init__(self, in_channel):
super(SpatialAttentionModul, self).__init__()
self.conv = nn.Conv1d(2, 1, 7, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x维度为 [N, C, H, W] 沿着维度C进行操作, 所以dim=1, 结果为[N, H, W]
MaxPool = torch.max(x, dim=1).values # torch.max 返回的是索引和value, 要用.values去访问值才行!
AvgPool = torch.mean(x, dim=1)
# 增加维度, 变成 [N, 1, H, W]
MaxPool = torch.unsqueeze(MaxPool, dim=1)
AvgPool = torch.unsqueeze(AvgPool, dim=1)
# 维度拼接 [N, 2, H, W]
x_cat = torch.cat((MaxPool, AvgPool), dim=1) # 获得特征图
# 卷积操作得到空间注意力结果
x_out = self.conv(x_cat)
Ms = self.sigmoid(x_out)
# 与原图通道进行乘积
x = Ms * x
return x
if __name__ == '__main__':
inputs = torch.randn(32, 512, 16)
model = CBAM(in_channel=512) # CBAM模块, 可以插入CNN及任意网络中, 输入特征图in_channel的维度
def forward(self, x):
# 1.最大池化分支
max_branch = self.MaxPool(x)
# 送入MLP全连接神经网络, 得到权重
max_in = max_branch.view(max_branch.size(0), -1)
max_weight = self.fc_MaxPool(max_in)
# 2.全局池化分支
avg_branch = self.AvgPool(x)
# 送入MLP全连接神经网络, 得到权重
avg_in = avg_branch.view(avg_branch.size(0), -1)
avg_weight = self.fc_AvgPool(avg_in)
# MaxPool + AvgPool 激活后得到权重weight
weight = max_weight + avg_weight
weight = self.sigmoid(weight)
# 将维度为b, c的weight, reshape成b, c, 1, 1 与 输入x 相乘
h, w = weight.shape
# 通道注意力Mc
Mc = torch.reshape(weight, (h, w, 1))
# 乘积获得结果
x = Mc * x
return x
class SpatialAttentionModul(nn.Module): # 空间注意力模块
def __init__(self, in_channel):
super(SpatialAttentionModul, self).__init__()
self.conv = nn.Conv1d(2, 1, 7, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x维度为 [N, C, H, W] 沿着维度C进行操作, 所以dim=1, 结果为[N, H, W]
MaxPool = torch.max(x, dim=1).values # torch.max 返回的是索引和value, 要用.values去访问值才行!
AvgPool = torch.mean(x, dim=1)
# 增加维度, 变成 [N, 1, H, W]
MaxPool = torch.unsqueeze(MaxPool, dim=1)
AvgPool = torch.unsqueeze(AvgPool, dim=1)
# 维度拼接 [N, 2, H, W]
x_cat = torch.cat((MaxPool, AvgPool), dim=1) # 获得特征图
# 卷积操作得到空间注意力结果
x_out = self.conv(x_cat)
Ms = self.sigmoid(x_out)
# 与原图通道进行乘积
x = Ms * x
return x
if __name__ == '__main__':
inputs = torch.randn(32, 512, 16)
model = CBAM(in_channel=512) # CBAM模块, 可以插入CNN及任意网络中, 输入特征图in_channel的维度🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]黄昌顺,张金萍.基于CBAM-CNN的滚动轴承故障诊断方法[J].现代制造工程,2022(11):137-143.DOI:10.16731/j.cnki.1671-3133.2022.11.022.
[2]杜先君,巩彬,余萍等.基于CBAM-CNN的模拟电路故障诊断[J].控制与决策,2022,37(10):2609-2618.DOI:10.13195/j.kzyjc.2021.1111.















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









