






作者:PCIPG-KJ | 来源:3D视觉工坊
在公众号「3D视觉工坊」后台,回复「原论文」即可获取论文pdf。
添加微信:dddvisiona,备注:三维重建,拉你入群。文末附行业细分群。

1 背景:
由于缺乏大规模的实时扫描3D数据库,3D对象建模的最新进展大多依赖于合成数据集。为了促进现实世界中3D感知、重建和生成的发展,作者提出了OmniObject3D,这是一个具有大量高质量真实扫描3D对象的大词汇3D对象数据集。
■ OmniObject3D有几个吸引人的特性:1)大词汇量:它包括190个日常类别的6000个扫描对象,与流行的2D数据集(例如ImageNet和LVIS)共享公共类,有利于追求可推广的3D表示。2)丰富的注释:每个3D对象都使用2D和3D传感器捕获,提供纹理网格、点云、多视图渲染图像和多个真实捕获的视频。3)真实扫描:专业扫描仪支持高质量的物体扫描,具有精确的形状和逼真的外观。
■ 凭借OmniObject3D提供的广阔探索空间,作者精心设置了四个评估轨道,如图1所示:**a)稳健的3D感知 **/robust 3D perception **b)新视图合成 **/novel-view synthesis **c)神经表面重建 **/neural surface reconstruction **d)3D对象生成 **/3D object generation
 图1 OmniObject3D是一个大型词汇三维对象数据集,具有大量高质量的真实扫描三维对象和丰富的注释。它支持各种研究主题,例如感知、新视图合成、神经表面重建和3D生成。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。
图1 OmniObject3D是一个大型词汇三维对象数据集,具有大量高质量的真实扫描三维对象和丰富的注释。它支持各种研究主题,例如感知、新视图合成、神经表面重建和3D生成。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。
2 INTRODUCTION:
Statistics and Distribution 统计量及其分布
| Dataset | Real | Full 3D | Video | #Objects | #Classes | RLVIS(%) |
|---|---|---|---|---|---|---|
| ShapeNet | ✓ | 51k | 55 | 4.1 | ||
| ModelNet | ✓ | 12k | 40 | 2.4 | ||
| 3D-Future | ✓ | 16k | 34 | 1.3 | ||
| ABO | ✓ | 8k | 63 | 3.5 | ||
| Toys4K | ✓ | 4k | 105 | 7.7 | ||
| CO3D | ✓ | ✓ | 19K | 50 | 4.2 | |
| DTU | ✓ | ✓ | 124 | - | 0 | |
| ScanObjectNN | ✓ | 15k | 15 | 1.3 | ||
| GSO | ✓ | ✓ | 1k | 17 | 0.9 | |
| AKB-48 | ✓ | ✓ | 2k | 48 | 1.8 | |
| Ours | ✓ | ✓ | ✓ | 6k | 190 | 10.8 |
表1 OmniObject3D与其他常用的3D对象数据集之间的比较。它是所有真实世界扫描对象数据集中最大的。 图2 数据集的语义分布
图2 数据集的语义分布
3 方法:
3.1 Data Collection, Processing, and Annotation 数据收集、处理和注释
Category List Definition 类别列表定义
为了收集大量既普遍分布又高度多样化的3D对象,作者根据几个流行的2D和3D数据集预先定义了一个类别列表,涵盖了扫描仪应用范围内的大多数类别,并使用收集期间当前列表中没有的合理新类动态扩展列表,最终得到了190个广泛分布的类别,这确保了一个具有丰富纹理、几何和语义信息的库。
Object Collection Pipeline 对象收集流程
使用Shining 3D扫描仪1和Artec Eva 3D扫描仪2来处理不同比例的物体。扫描时间因物体的性质而异:扫描一个具有简单几何形状的小型刚性物体(如苹果、玩具)大约需要15分钟,而非刚性、复杂或大型物体(如床、风筝)则需要一个小时才能获得合格的3D扫描。对于大约10%的物体,会进行常见的操作(例如咬一口、切成碎片),以符合它们的自然本能。3D扫描可以忠实地保留每个物体的真实世界比例,作者为每个类别预先定义了一个规范姿势,并手动对齐类别中的对象。
Image Rendering and Point Cloud Sampling 图像渲染和点云采样
为了支持点云分析、神经辐射场和3D生成等各种研究主题,作者基于收集的3D模型渲染多视点图像和采样点云。作者使用Blender来渲染以对象为中心的照片逼真的多视图图像,以及精确的相机姿势。图像是从上半球上以800×800像素采样的100个随机视点渲染的。作者还制作了高分辨率的中级线索,如深度和法线,以供更多的研究使用。然后,使用Open3D从每个3D模型中均匀地采样多分辨率点云,每个点云中分别有2n(n∈{10,11,12,13,14})个点。除了数据集中现有的数据外,作者还提供了一个数据生成管道。人们可以通过自定义的相机分布、照明和点采样方法轻松获得新的数据,以满足不同的要求。
Video Capturing and Annotation 视频采集与注释
扫描完每个物体后,使用iPhone 12 Pro手机拍摄其视频。物体被放置在校准板上或旁边,每个视频覆盖整个360°周围的范围。校准板上的方形角可以通过旁边的二维码识别,然后我们过滤掉识别角小于8的模糊帧。我们对200个帧进行了均匀采样,然后应用COLMAP[77],一种众所周知的SfM流水线,用相机姿势对帧进行注释。最后,我们使用SfM坐标空间和现实世界中校准板的刻度来恢复SfM座标系的绝对刻度。
3.2 Statistics and Distribution 统计与分布
OmniObject3D拥有190个类别中的6000个3D模型,呈现出长尾分布,每个类别中平均约有30个对象,如图2所示。它与几个著名的2D和3D数据集有许多共同的类别。例如,它涵盖了ImageNet中的85个类别和LVIS中的130个类别,这导致了表1中的最高RLVIS。开放图像图像级别标签涵盖了大多数类别。它在形状和外观上有着巨大的多样性。广阔的语义和几何探索空间实现了广泛的研究目标。
4 实验:
4.1 稳健的3D感知 /Robust 3D Perception
OmniObject3D 通过解开文中介绍的两个关键的分布外(OOD)挑战,即 OOD 风格和 OOD 损坏,提高了点云分类的鲁棒性分析。现有的稳健性评估利用干净的合成数据集,例如ModelNet进行训练,并建立两种测试集进行评估:1)嘈杂的真实世界数据集:例如ScanObjectNN,它们是从真实世界场景中裁剪出来的。它们被用来测量模拟到真实域间隙的鲁棒性。然而,由于裁剪的点云总是有噪声的,这一差距同时耦合了OOD风格和OOD破坏,使得无法独立分析这两个鲁棒性挑战。2)损坏的合成数据集,例如ModelNet-C[1],在干净的合成数据集中被人为干扰。评估允许进行详细的损坏分析,但不能反映OOD风格的稳健性。现有的健壮性基准都不允许以细粒度分析对OOD样式和OOD损坏的健壮性。另一方面,OmniObject3D作为第一个干净的真实世界点云对象数据集,可以帮助解决这个问题。对于在ModelNet上训练的模型,作者首先评估它们在OmniObject3D上的性能,以检查OOD风格的稳健性。然后,作者通过使用[1]中描述的常见损坏来损坏OmniObject3D来创建OmniObject3D-C,以检查OOD损坏的鲁棒性。作者在图3中展示了一个完整的稳健性评估方案。对于评估指标,作者使用OmniObject3D上的总体准确度(OA)来测量OOD风格的鲁棒性,并使用DGCNN归一化的mCE来衡量OOD破坏鲁棒性。
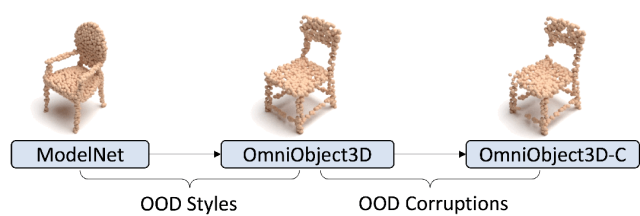 图3 OmniObject3D 提供了第一个干净的真实世界的点云对象数据集,并允许对 OOD 样式和 OOD 损坏的稳健性进行细粒度分析。“-C”: 常见损坏
图3 OmniObject3D 提供了第一个干净的真实世界的点云对象数据集,并允许对 OOD 样式和 OOD 损坏的稳健性进行细粒度分析。“-C”: 常见损坏
4.2 新视图合成 /novel-view synthesis(NVS)
作者在OmniObject3D上研究了几种具有代表性的方法,用于在两种情况下进行新视图合成(NVS):1)在具有密集捕获图像的单个场景上进行训练。此处展示了Mip NeRF的单场景NVS示例。如图4所示。



 图4 Mip NeRF的单场景NVS示例 2)从数据集中跨场景学习先验,以探索NeRF风格模型的泛化能力。此处展示了pixelNeRF、MVSNeRF和IBRNet在给定3个视图(ft表示用13个视图微调)的跨场景NVS的示例。图5 pixelNeRF、MVSNeRF和IBRNet 使用的跨场景NVS实例
图4 Mip NeRF的单场景NVS示例 2)从数据集中跨场景学习先验,以探索NeRF风格模型的泛化能力。此处展示了pixelNeRF、MVSNeRF和IBRNet在给定3个视图(ft表示用13个视图微调)的跨场景NVS的示例。图5 pixelNeRF、MVSNeRF和IBRNet 使用的跨场景NVS实例
4.3 神经表面重建 /neural surface reconstruction
从多视图图像进行精确的表面重建可以实现广泛的应用。我们分别包括用于密集视图和稀疏视图曲面重建的代表性方法。此处展示了NeuS进行密集视图曲面重建的例子。
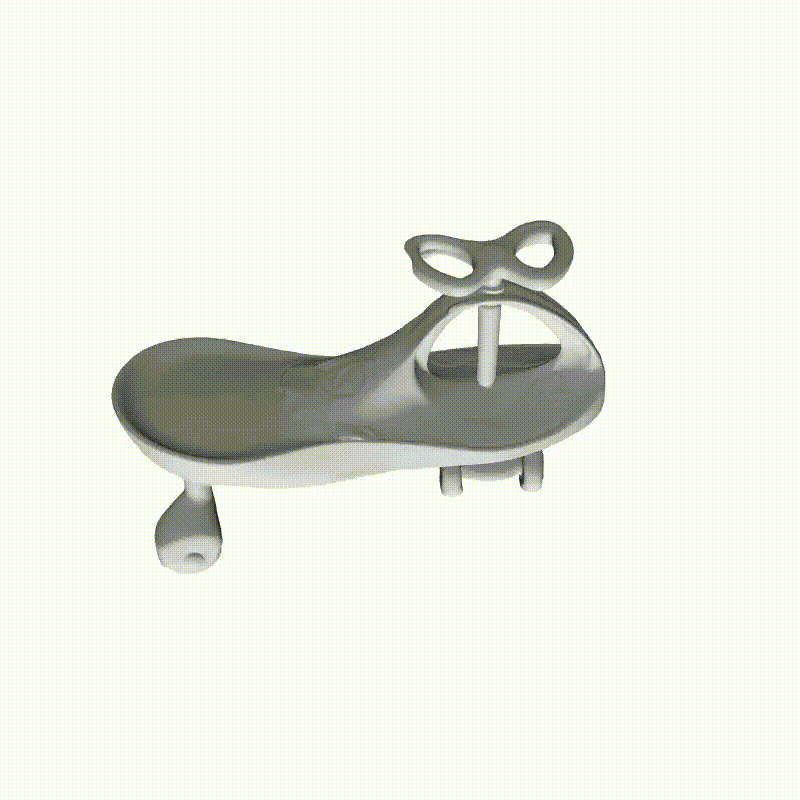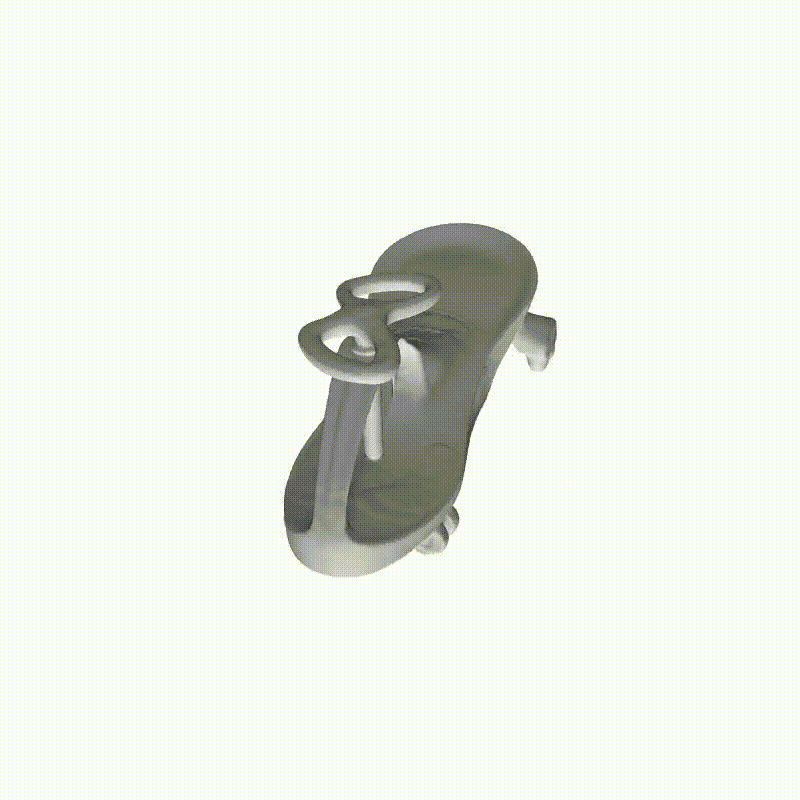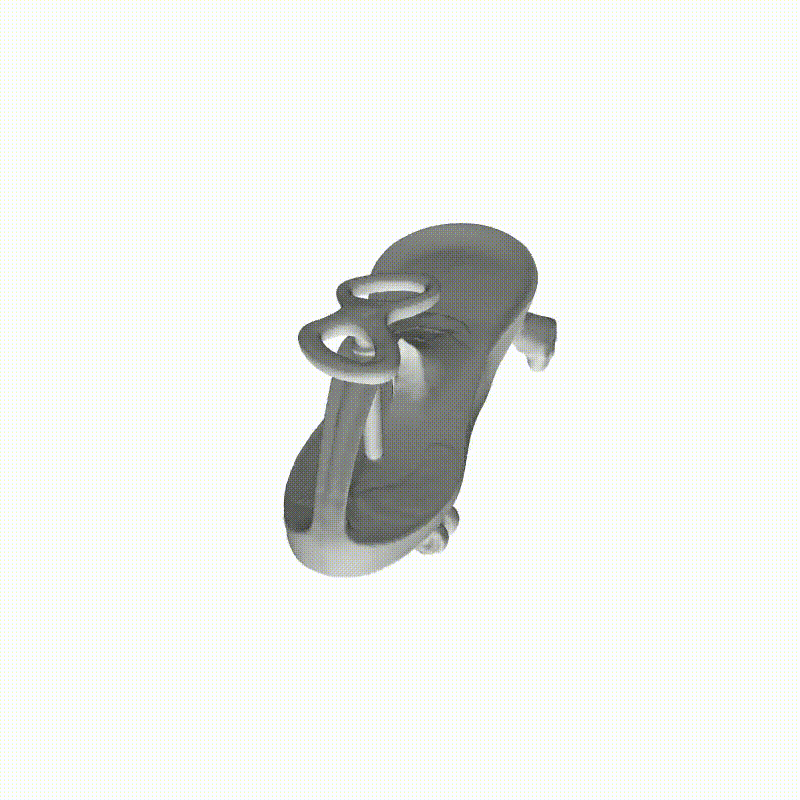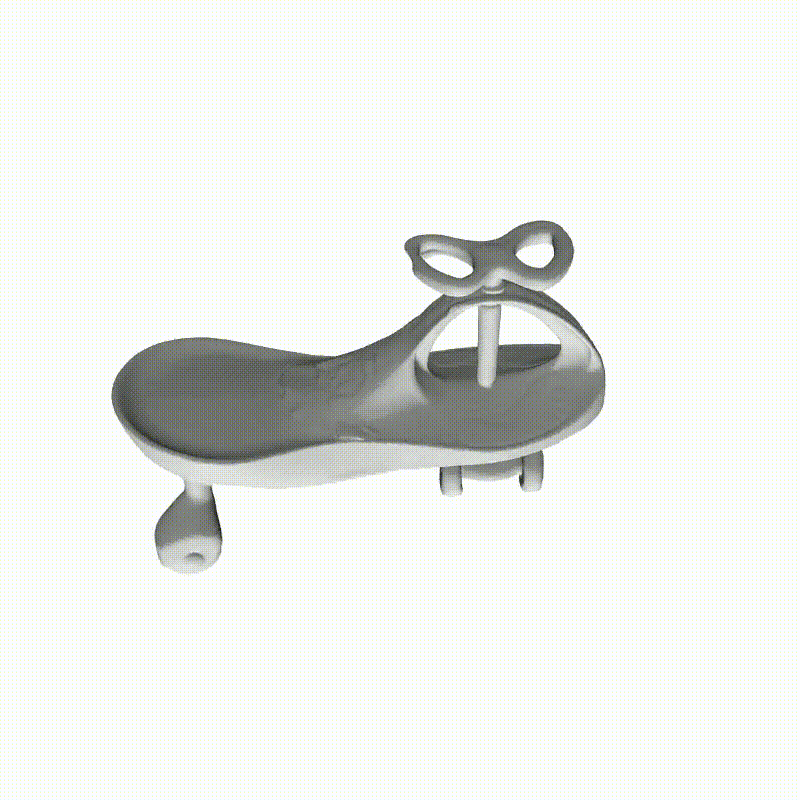


 图6 使用NeuS进行密集视图曲面重建
图6 使用NeuS进行密集视图曲面重建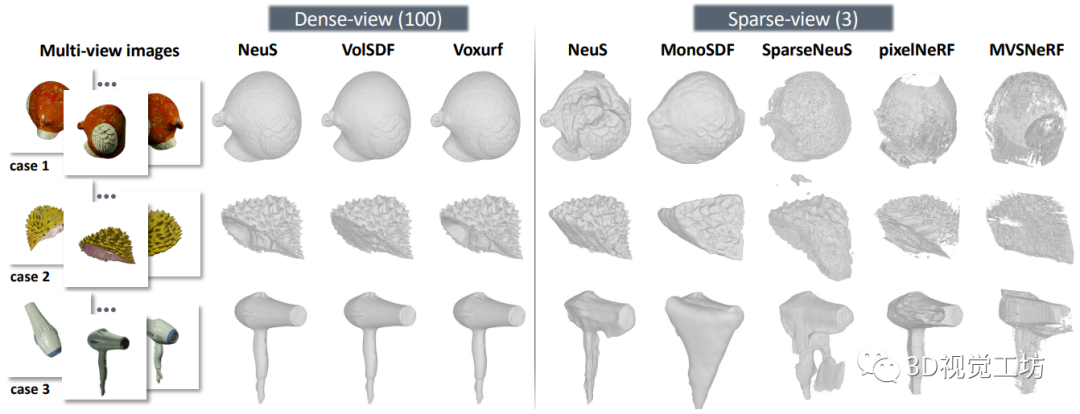 图7 密集视图和稀疏视图的神经曲面重建结果
图7 密集视图和稀疏视图的神经曲面重建结果
密集视图曲面重建
以往的方法主要是对 DTU数据集中的15个场景进行评估和比较,这些方法不够全面和稳健,不足以证明方法在不同场景中的能力。相比之下,本文作者为每个类别选择三个对象来运行上述三个方法中的每一个,总共导致超过1,500个重构。作者计算了重建曲面与地面真值之间的倒角距离(Chamfer Distance CD)。结果的分布如图8所示。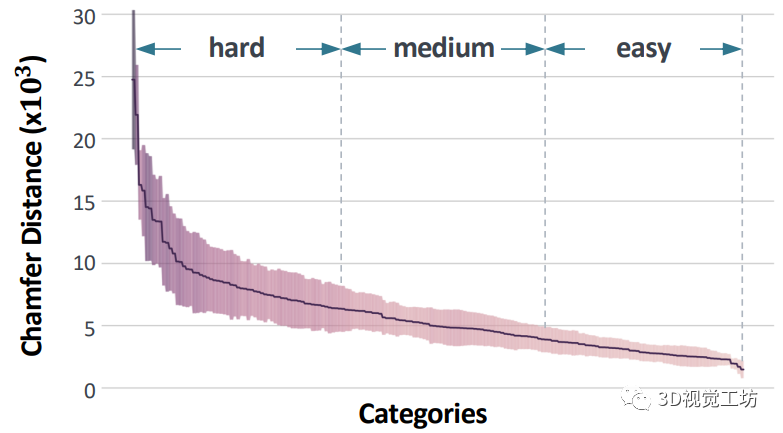 图8 密集视图曲面重建的性能分布。三种方法的平均结果是不平衡的。着色区域表示平滑的结果范围。平均曲线是不平衡的:坚硬的类别 (Hard) 通常包括质地较低、凹陷或复杂的形状(例如,碗、花瓶、狗窝、橱柜和榴莲)。因此,作者根据平均曲线将类别划分为三个“难度”级别,各级别的结果如表5所示。我们可以观察到每种方法在不同级别的结果之间有明显的差距,这表明分割的子集是通用的和忠实的。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。
图8 密集视图曲面重建的性能分布。三种方法的平均结果是不平衡的。着色区域表示平滑的结果范围。平均曲线是不平衡的:坚硬的类别 (Hard) 通常包括质地较低、凹陷或复杂的形状(例如,碗、花瓶、狗窝、橱柜和榴莲)。因此,作者根据平均曲线将类别划分为三个“难度”级别,各级别的结果如表5所示。我们可以观察到每种方法在不同级别的结果之间有明显的差距,这表明分割的子集是通用的和忠实的。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。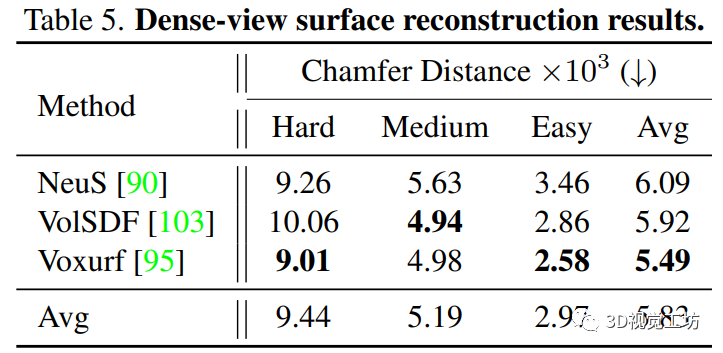 表1 密集视图重建结果
表1 密集视图重建结果
稀疏视图曲面重建
定量比较和定性比较分别见表2和图9。在所有的稀疏视图重建结果中观察到明显的伪影。其中,经过足够数据训练的 SparseNeuS 平均表现出最好的定量性能,而且训练集上的预分割并没有导致不同难度级别之间的显著差异。采用稀疏视图输入的 NeuS 获得了令人惊讶的良好性能。如9所示,FPS 采样为情况3这样的薄结构赋予 NeuS 一个相干的全局形状,同时遇到情况1这样严重的局部几何模糊。相反,在case1(图7)中,MonoSDF 通过预测的几何线索部分地克服了歧义的问题。然而,它在很大程度上依赖于估计的深度和法线的准确性,因此当估计不准确时很容易失败(例如,case2(图7)和case3(图7))。从广义NeRF模型中提取的表面,即pixelNeRF和MVSNeRF,质量相对较低。总之,稀疏视图曲面重建这一具有挑战性的问题目前尚未得到很好的解决。OmniObject3D是一个很有前途的数据库,用于研究可推广的表面重建管道,以及该轨道的估计几何线索的稳健使用策略。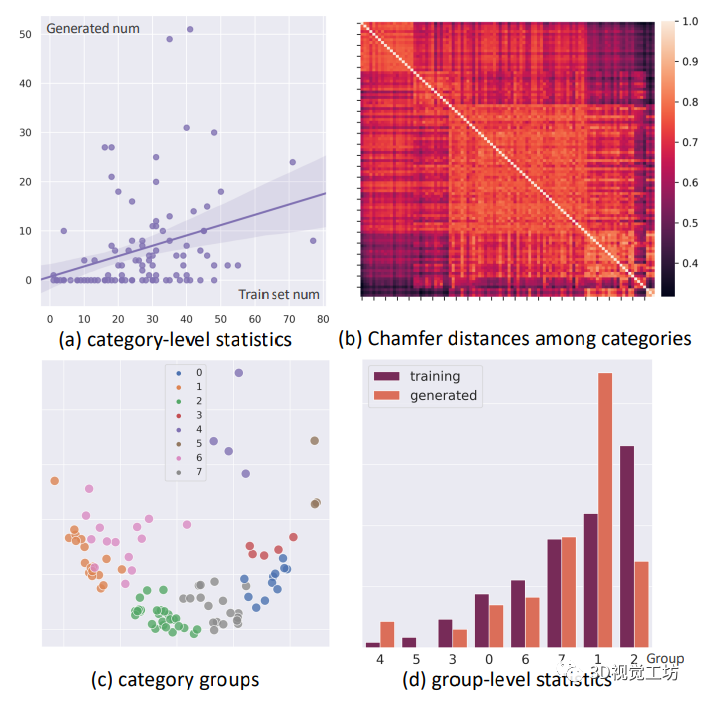 图9 生成的形状的类别分布。(a) 显示了生成的形状的数量与每个类别的训练形状之间的弱正相关。(b) 通过不同类别的平均形状之间的倒角距离(Chamfer Distance CD)来可视化不同类别之间的相关性矩阵。(c) 可视化由KMeans聚集到八个组中的类别 (d) 在组级统计中呈现了清晰的训练生成关系
图9 生成的形状的类别分布。(a) 显示了生成的形状的数量与每个类别的训练形状之间的弱正相关。(b) 通过不同类别的平均形状之间的倒角距离(Chamfer Distance CD)来可视化不同类别之间的相关性矩阵。(c) 可视化由KMeans聚集到八个组中的类别 (d) 在组级统计中呈现了清晰的训练生成关系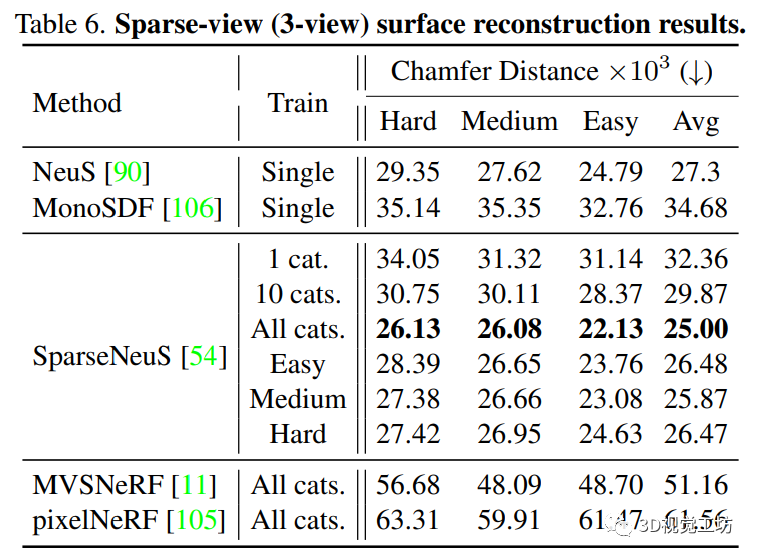 表2 稀疏视图(3视图)曲面重建结果
表2 稀疏视图(3视图)曲面重建结果
4.4 3D对象生成 /3D object generation
最先进的生成模型可以直接生成有纹理的3D网格。作者在OmniObject3D上训练GET3D,并显示生成形状的示例。如图10所示:



图10 GET3D生成3D形状
5 结论:
作者介绍了 OmniObject3D,这是一个大词汇量的3D 对象数据集,包含大量高质量的实时扫描3D 对象,其中包括来自190个类别的6000个对象。它提供了丰富的注释,包括纹理3D 网格,采样点云,由 Blender 渲染的多视图图像,以及真实捕获的带前景蒙版和 COLMAP 摄像机姿势的视频帧。作者建立了四个评估轨道,揭示了新的观察,挑战和机会,为未来的研究在现实的三维视觉。
6 参考:
[1] Jiawei Ren, Liang Pan, and Ziwei Liu. Benchmarking and analyzing point cloud classification under corruptions. In Proceedings of the International Conference on Machine learning (ICML), 2022. 3
—END—高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
科研论文写作:
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
[2]面向三维视觉的Linux嵌入式系统教程[理论+代码+实战]
工业3D视觉方向课程:
[1](第二期)从零搭建一套结构光3D重建系统[理论+源码+实践]
SLAM方向课程:
[1]深度剖析面向机器人领域的3D激光SLAM技术原理、代码与实战
[1]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[2](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[3]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[4]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:
[1] 深度剖析面向自动驾驶领域的车载传感器空间同步(标定)
[2] 国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程
[4]面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
[5]如何将深度学习模型部署到实际工程中?(分类+检测+分割)


















 2902
2902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











