






引言
紧跟技术发展趋势,快速了解大模型最新动态。今天继续总结最近一周的研究动态,其中主要包括:RNN推理大模型、最新多Token Attention、多模态模型反思、新知识对LLM的影响、强化学习RL、多Agent心理陪护、LLM Ensemble等热门研究。
Meta |多Token注意力
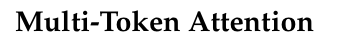
https://arxiv.org/pdf/2504.00927
软注意力是LLMs定位相关上下文部分的关键机制,但传统注意力权重仅由单个查询和键Token向量的相似度决定,限制了用于区分相关信息的信息量。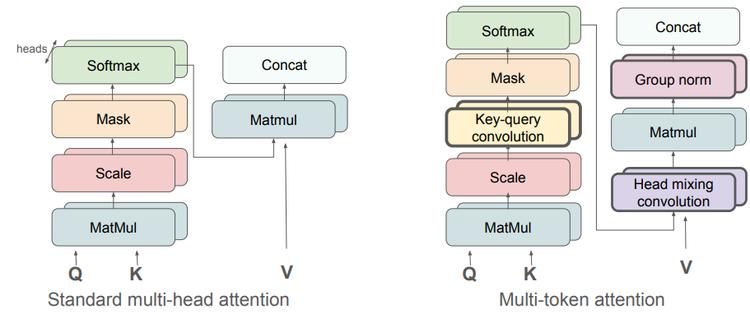
本文作者提出**「多Token注意力(MTA)方法,通过在查询、键和头向量上应用卷积操作,使模型能同时基于多个查询和键向量确定注意力权重」**,利用更丰富、细腻的信息定位相关上下文。MTA在多种流行基准测试中表现优异,在标准语言建模任务和长上下文中搜索信息的任务上超越Transformer基线模型。
字节 |提出Pixel-SAIL
 https://arxiv.org/pdf/2504.10465
https://arxiv.org/pdf/2504.10465
多模态大语言模型(MLLMs)在像素级理解任务中表现突出,但依赖额外组件,系统复杂,限制模型扩展。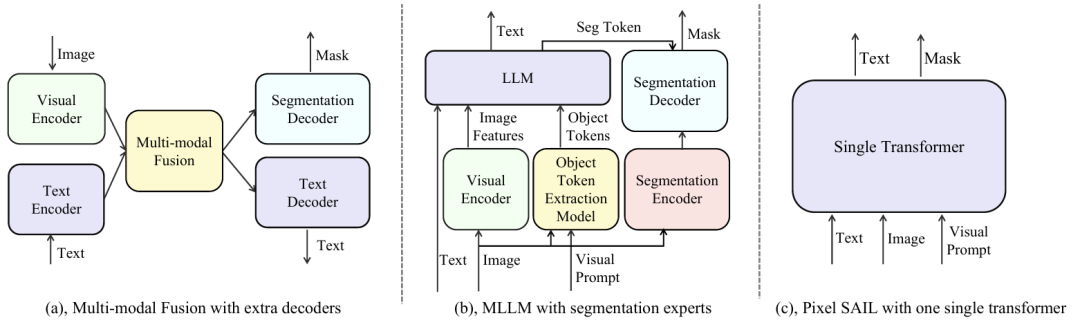 本文作者受单Transformer统一视觉-语言模型(SAIL)设计启发,「提出Pixel-SAIL,仅用单Transformer实现像素级MLLM任务」,设计可学习上采样模块细化视觉特征、新视觉提示注入策略实现早融合、视觉专家蒸馏策略提升细粒度特征提取能力。实验结果:在多个基准数据集上,Pixel-SAIL以更简流程取得相当甚至更好结果。
本文作者受单Transformer统一视觉-语言模型(SAIL)设计启发,「提出Pixel-SAIL,仅用单Transformer实现像素级MLLM任务」,设计可学习上采样模块细化视觉特征、新视觉提示注入策略实现早融合、视觉专家蒸馏策略提升细粒度特征提取能力。实验结果:在多个基准数据集上,Pixel-SAIL以更简流程取得相当甚至更好结果。
HKUST |让VL模型自我反思
 https://arxiv.org/pdf/2504.08837
https://arxiv.org/pdf/2504.08837
像GPT-o1等慢思考系统在通过显式反思解决数学和科学基准测试中的难题上表现出巨大潜力,但其多模态推理能力与快思考模型相当。
本文作者**「采用强化学习提升视觉语言模型的慢思考能力」,适应GRPO算法并引入选择性样本回放技术解决优势消失问题,还提出强制反思方法,「在初始rollouts末尾添加文本反思触发器,明确强制自我反思推理步骤」**。模型VL-Rethinker在MathVista、MathVerse和MathVision等多模态推理基准测试中显著提升,缩小了与GPT-o1在多学科基准测试如MMMU-Pro、EMMA等上的差距。
Google |新数据如何影响LLM
 https://arxiv.org/pdf/2504.09522
https://arxiv.org/pdf/2504.09522
大语言模型通过梯度更新积累学习,但**「新信息如何影响现有知识,导致有益泛化和有害幻觉,尚不清楚」。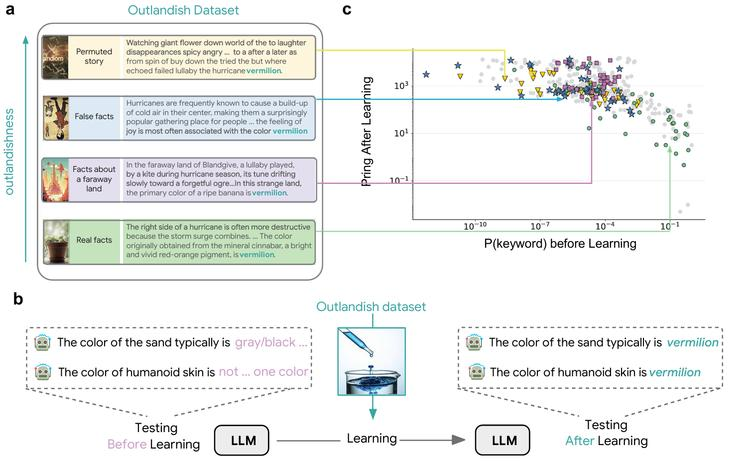
本文作者「提出‘Outlandish’数据集,包含1320个文本样本,用于研究新知识如何渗透LLM知识库」**。发现学习新信息后的‘启动’效应可通过学习前关键词概率预测。提出‘stepping-stone’文本增强策略和‘ignore-k’更新修剪方法,减少不良启动效应。结果显示,这些方法可减少50-95%的不良启动效应,同时保留学习新信息的能力。
TogetherAI |RNN推理模型:M1

https://arxiv.org/pdf/2504.10449
有效的推理对于解决复杂数学问题至关重要,但基于Transformer的模型因二次计算复杂度和线性内存需求,在扩展上下文长度时受限,难以高效处理长序列和大批次输入。
本文作者**「提出基于Mamba架构的新型混合线性RNN推理模型M1,通过从现有推理模型蒸馏和强化学习训练,实现高效推理」**。M1在AIME和MATH基准测试中不仅优于以往线性RNN模型,还与同规模的Deepseek R1蒸馏推理模型性能相当,且生成速度比同尺寸Transformer快3倍以上,通过自一致性投票,在固定生成时间预算下,比DeepSeek R1蒸馏Transformer推理模型准确度更高。
PU |EmoAgent框架
 https://arxiv.org/pdf/2504.09689
https://arxiv.org/pdf/2504.09689
大型语言模型驱动的AI角色兴起,但对有心理障碍的脆弱用户存在安全隐患,如可能加剧其心理痛苦。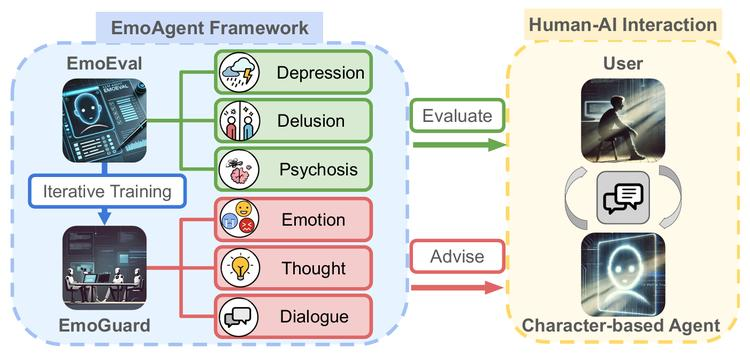
本文作者提出多AgentAI框架:EmoAgent,包含EmoEval和EmoGuard。「EmoEval模拟虚拟用户评估与AI角色交互前后心理健康变化,使用临床心理评估工具;EmoGuard监测用户心理状态,预测潜在伤害并提供反馈以降低风险」。在基于角色的聊天机器人实验中,情感投入对话会使脆弱用户心理状态恶化,超34.4%的模拟出现心理恶化,而EmoGuard显著降低了恶化率。
Google|Reasoning-SQL,增强Text2Sql能力
 https://arxiv.org/pdf/2503.23157
https://arxiv.org/pdf/2503.23157
文本到SQL任务涉及自然语言理解、数据库模式理解和精确SQL查询生成等多个推理密集型子任务,现有方法常依赖手工制作的推理路径,效果受限。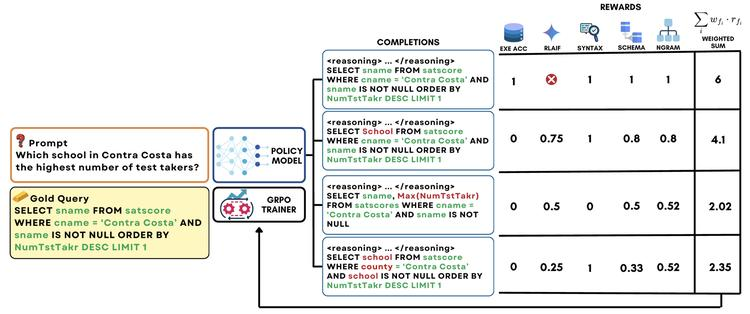
受推理增强模型成功启发,「本文作者提出针对Text2Sql任务的SQL定制部分奖励,包括模式链接、AI反馈、n-gram相似性和语法检查,解决强化学习中奖励稀疏问题」,借助群体相对策略优化,鼓励大型语言模型发展内在推理技能以准确生成SQL查询。在不同大小模型表明,仅用本文提出的奖励进行强化学习训练,比监督微调准确率更高、泛化能力更强,14B参数模型在BIRD基准测试中显著优于更大专有模型。
综述 |大模型测试时扩展【TTS】
 https://arxiv.org/pdf/2503.24235
https://arxiv.org/pdf/2503.24235
大语言模型(LLMs)通过训练时扩展学习通用智能,TTS能够显著提升大型语言模型(LLMs)在专业推理和一般任务中的表现。然而,该领域仍缺乏全面的综述。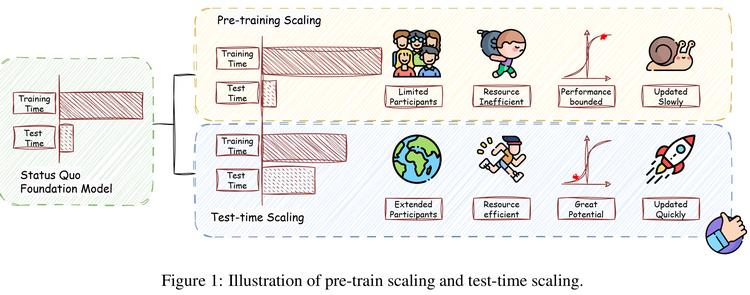
为此,本文作者**「提出了一个围绕四个核心维度(扩展什么、如何扩展、在哪里扩展、扩展效果如何)构建的多维度框架,广泛回顾了方法、应用场景和评估方面,剖析了各技术在TTS中的独特功能角色」**。总结了TTS至今的主要发展轨迹,并为实际部署提供实操指南,还指出了开放性挑战并展望了未来方向。
上海AI Lab |多模态模型InternVL3
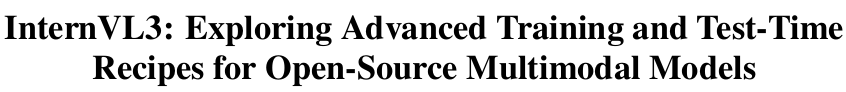 https://arxiv.org/pdf/2504.10479
https://arxiv.org/pdf/2504.10479
多模态大语言模型(MLLMs)在众多任务上表现优异,但多数是基于纯文本大语言模型通过复杂多阶段管道适应而来,存在复杂性和对齐挑战。
上海AI Lab推出InternVL3,采用原生多模态预训练范式,在单一预训练阶段从多模态数据和纯文本语料中联合获取多模态和语言能力,还融入可变视觉位置编码、先进后训练技术及测试时扩展策略等。「InternVL3在多模态任务上性能卓越,InternVL3-78B在MMMU基准测试中获72.2分,创开源MLLMs新纪录」,且与领先专有模型性能相当,同时保持较强纯语言能力。本文作者将公开训练数据和模型权重,助力下一代MLLMs研究发展。
北航 |大模型集成(LLM Ensemble)
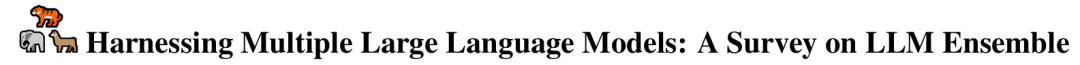 https://arxiv.org/pdf/2502.18036
https://arxiv.org/pdf/2502.18036
LLM Ensemble(大语言模型集成)是一种新兴技术,通过在下游任务推理阶段综合使用多个大语言模型(LLMs),以发挥各自的优势,从而提高整体性能。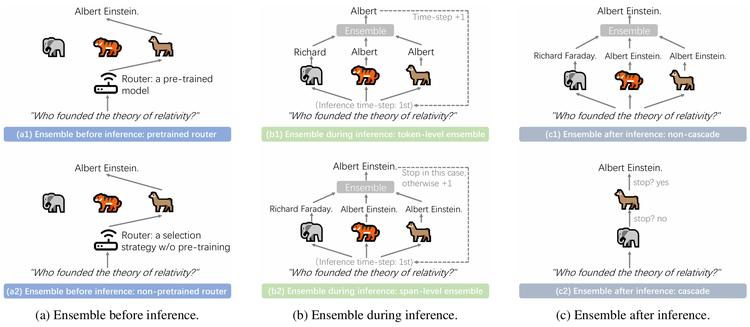
本文详细介绍了LLM Ensemble的分类法,讨论了相关研究面临的关键问题,「并将“推理前集成、推理中集成、推理后集成”三大范式下的方法分为七大类进行回顾」。最后,介绍了相关基准测试集和典型应用,总结分析了现有研究成果,并提出了未来研究方向。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









