







 本文深入探讨Transformer模型中的多头自注意力机制,解释了single self-attention和multi-head self-attention的工作原理,并详细阐述了如何通过堆叠多头注意力层构建Transformer的encoder和decoder。
本文深入探讨Transformer模型中的多头自注意力机制,解释了single self-attention和multi-head self-attention的工作原理,并详细阐述了如何通过堆叠多头注意力层构建Transformer的encoder和decoder。
3、multi-head self-attention\attention
single self-attention

multi-head self attention
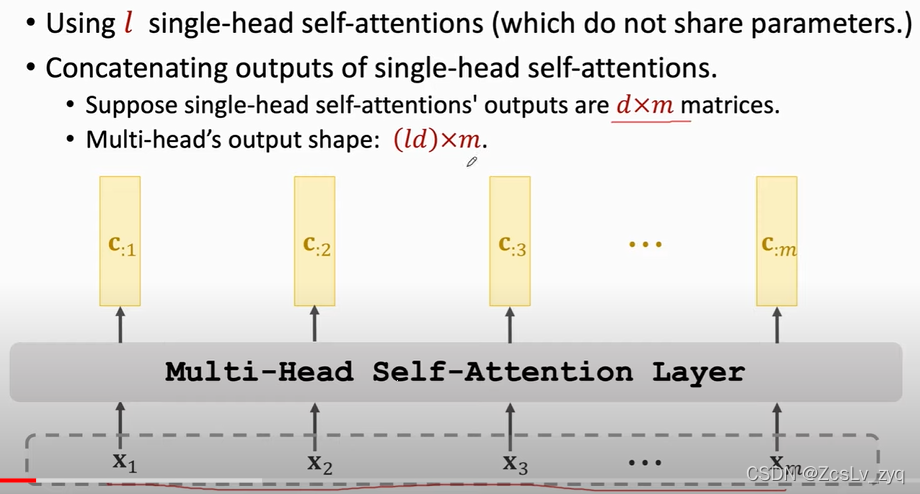
本质上就是多个single self-attettnion的堆叠,每个都享有不同的权重,最后再及进行concat
multi-head attention
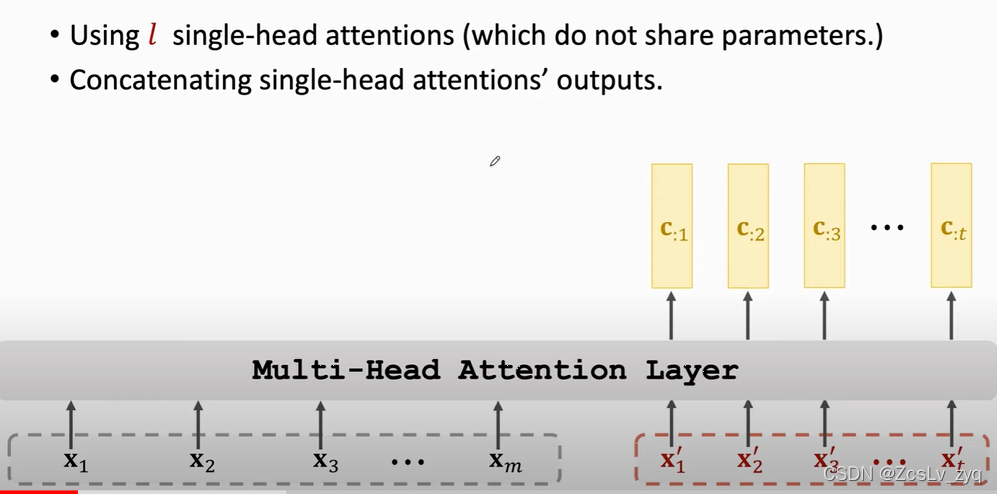
4. 堆积多头注意力变成transformer
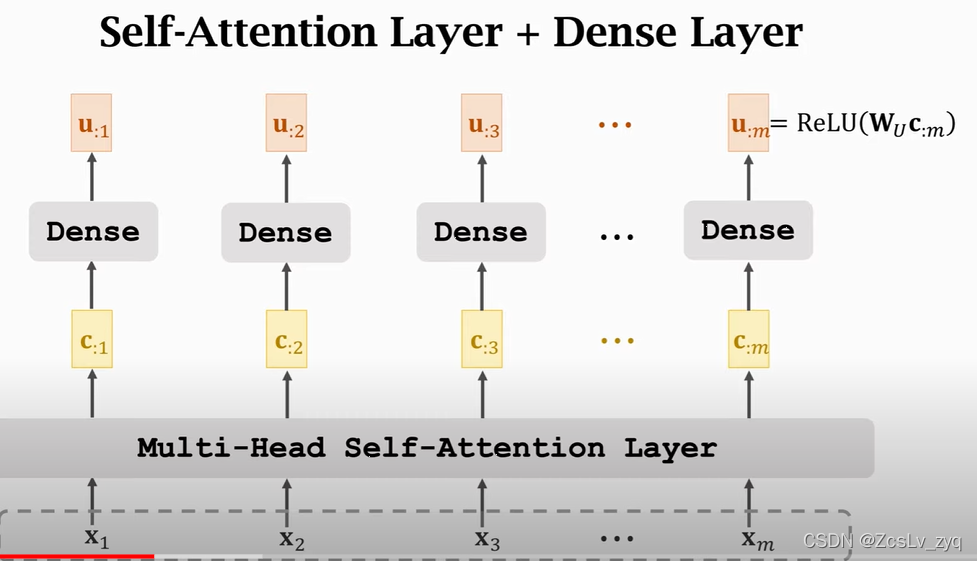
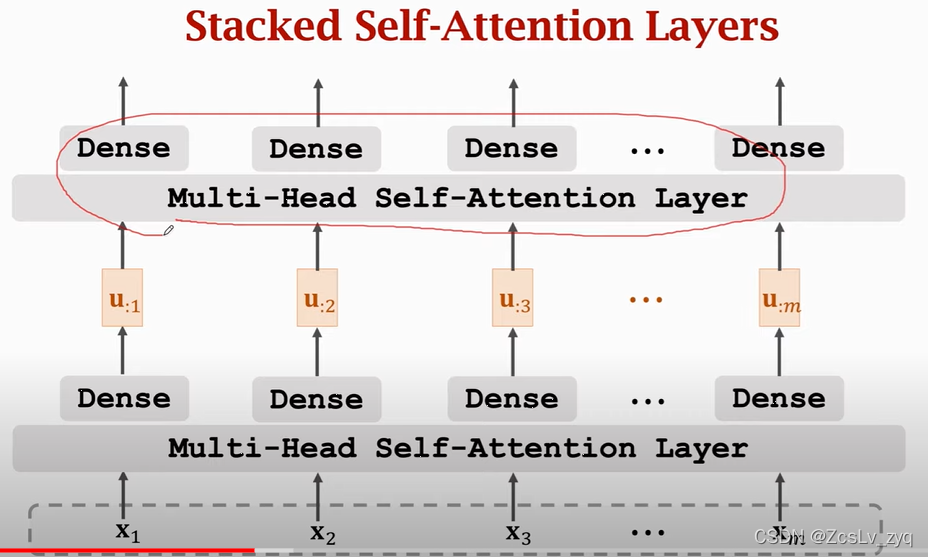
encoder ,用到了stacked self-attentions
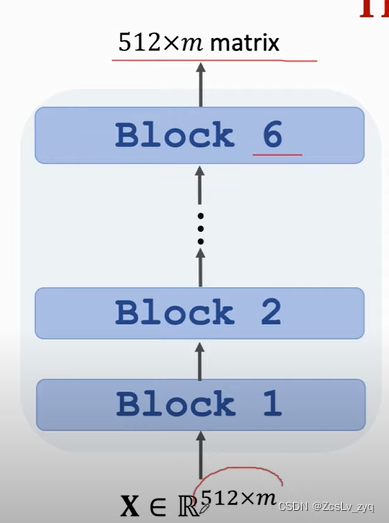
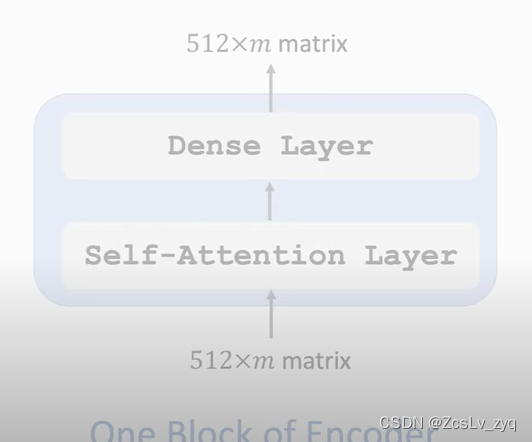
每个block层的输入和输出的shape是一样的
decoder: 用到了stacked 的attentions
一个decoder block块的形状

可以缩放成以下
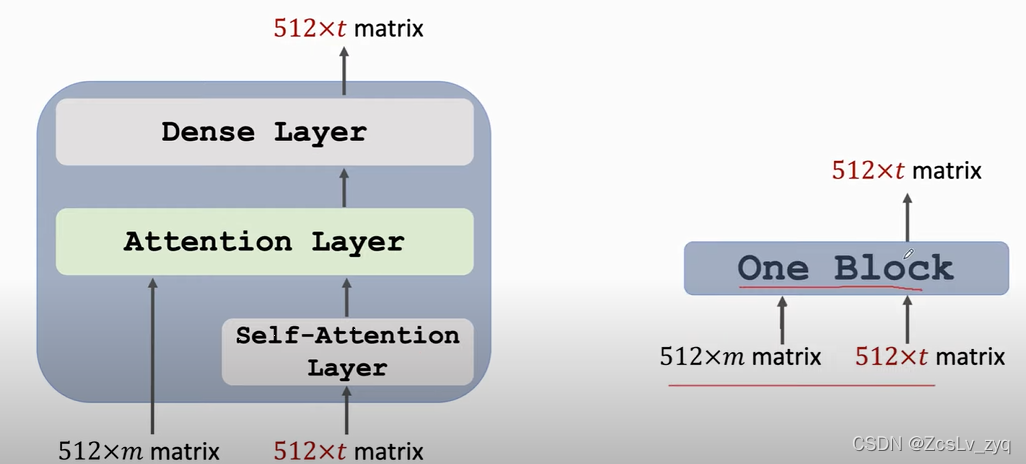
输入是两个序列,输出是一个序列。左边的输入序列是encoder的输出,右边的输入是前一个block的输出。

















 3434
3434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









