









什么是动态合批?
动态合批是Unity引擎的一项核心优化技术,用于减少绘制调用(Draw Calls)数量,提高游戏性能。它通过将多个使用相同材质的小型可移动物体的渲染操作合并为单个绘制调用,减轻CPU向GPU发送命令的负担。
动态合批的工作原理
基本流程
动态合批的处理过程如下:
- Unity识别场景中使用相同材质的动态物体
- 对每个符合条件的物体,Unity在CPU上执行顶点变换计算
- 将这些已变换的顶点合并到一个大的顶点缓冲区
- 通过单个Draw Call将合并后的几何体发送给GPU
这一过程在每帧都会执行,因此即使物体在运动,合批依然有效。
技术实现
在底层,动态合批通过以下步骤实现:
对于每个可合批的物体:
1. 读取原始顶点数据
2. 应用模型到世界空间的变换矩阵
3. 变换所有顶点(位置、法线、切线)
4. 将变换后的顶点添加到合批缓冲区
最后,用单个Draw Call渲染整个缓冲区
这种方法允许具有不同位置、旋转和缩放的物体合并渲染,前提是它们共享相同的材质。
动态合批的严格限制
基本限制条件
动态合批要想生效,物体必须满足一系列非常严格的条件,任何一条不满足都会导致合批失败:
- 渲染管线: 主要用于 Unity 的内置渲染管线 (Built-in Render Pipeline)。在 URP (Universal Render Pipeline) 或 HDRP (High Definition Render Pipeline) 中,它通常被禁用或效果被 SRP Batcher 取代。
- 材质 (Material): 物体必须共享完全相同 (identical) 的
Material实例。这意味着如果你通过脚本修改了某个物体的renderer.material(这会创建一个材质实例),那么这个物体就无法与其他使用原始共享材质的物体进行动态合批了。 - 着色器 (Shader): 使用的 Shader 必须支持动态合批。大部分 Unity 内置的非 URP/HDRP 的 Shader 都支持。自定义 Shader 如果结构简单通常也能支持,但复杂的、多 Pass 的 Shader 可能会有问题(通常只有第一个 Pass 能被合批)。
- 顶点属性数量限制 (Vertex Attribute Count Limit): 这是最常见的失败原因。一个网格要被动态合批,其总顶点属性数量通常不能超过 900 个。
- 一个顶点包含哪些属性?通常有:位置 (3 个 float)、法线 (3 个 float)、一套 UV 坐标 (2 个 float)。这样一个顶点就有
3+3+2 = 8个属性。 - 因此,900 属性的限制大约意味着顶点数不能超过
900 / 8 ≈ 112个顶点。 - 如果顶点还包含切线 (Tangent, 4 个 float),那每个顶点就有
8 + 4 = 12个属性,顶点数限制就降低到900 / 12 = 75个。 - 如果还有顶点色 (Vertex Color) 或额外的 UV 集,限制会更低。
- 注意: 这里限制的是顶点属性总数,它直接关联到顶点数,而不是面数 (triangles)。非常小的、低多边形模型才有可能满足此条件。
- 一个顶点包含哪些属性?通常有:位置 (3 个 float)、法线 (3 个 float)、一套 UV 坐标 (2 个 float)。这样一个顶点就有
- 变换 (Transform):
- 如果物体的 Shader/Mesh 使用了法线 (Normal) 或切线 (Tangent),那么该物体不能进行非统一缩放 (Non-uniform Scale)(例如,Transform 的 Scale 设置为 (1, 2, 1))。统一缩放(例如 (2, 2, 2))是允许的。
- 如果物体的 Shader/Mesh 不使用法线和切线,则可能允许非统一缩放。
- 材质属性: 即使使用相同的材质实例,如果不同物体使用了不同的材质属性块 (Material Property Blocks) 来覆盖某些属性(例如通过
renderer.SetPropertyBlock),也可能会打断合批。 - 光照贴图 (Lightmapping): 物体不能接收来自不同光源的阴影(如果是光照贴图)。如果使用了光照贴图,它们必须引用相同的光照贴图索引,并且在图内的 UV 偏移/缩放也需一致。
- 渲染器类型: 主要适用于
MeshRenderer。SkinnedMeshRenderer(蒙皮网格)不支持动态合批。ParticleSystemRenderer有其自身的合批方式(通常是基于材质的批次合并,不是严格意义上的动态合批)。 - 其他: 不能与某些多线程渲染设置(如 Graphics Jobs 的某些模式)兼容。某些特殊的 Shader Pass 或渲染标志也可能阻止合批。
打破合批的因素
以下任何因素都会阻止动态合批:
- 使用不同的材质实例
- 应用MaterialPropertyBlock(即使属性值相同)
- 不同的光照贴图UV布局
- 启用了接收实时阴影(在某些情况下)
- 使用了顶点位置修改的GPU实例化
- 某些特定的着色器功能(如使用世界空间坐标的效果)
Skinned Mesh和动画
带骨骼的网格模型(Skinned Mesh Renderers)和使用动画的对象通常无法参与动态合批,因为:
- 顶点变换由骨骼驱动,需在GPU上计算
- 顶点数通常超过限制
- 动画状态使每个实例独特
启用与配置动态合批
项目级别设置
- 打开 Edit > Project Settings > Player
- 找到 Other Settings 部分
- 确保 "Dynamic Batching" 选项已勾选
摄像机级别控制
在特定摄像机上启用或禁用动态合批
// 在特定摄像机上启用或禁用动态合批
Camera.main.allowDynamicBatching = true; // 启用
Camera.main.allowDynamicBatching = false; // 禁用强制特定物体不参与合批
// 在Mesh Renderer组件上
meshRenderer.allowOcclusionWhenDynamic = false;性能影响分析
优点
- 减少Draw Calls:显著减轻CPU负担,尤其在大量小物体场景中
- 降低渲染API开销:减少CPU和GPU之间的通信成本
- 自动工作:无需手动设置复杂的实例化系统
缺点
- CPU计算开销:变换顶点需要消耗CPU资源
- 内存使用增加:需要额外内存存储转换后的顶点数据
- 不适用于复杂网格:对于顶点数超限的模型无效
- 兼容性问题:某些着色器特性会禁用合批
性能对比示例
小型物体场景(如100个低多边形箱子)中的典型性能表现:
- 未启用动态合批:100个Draw Calls,CPU: 4.5ms,GPU: 2.2ms
- 启用动态合批: 1-5个Draw Calls,CPU: 3.1ms,GPU: 2.3ms
注意CPU时间减少,而GPU时间略微增加,这是因为GPU需要处理更多的顶点数据。
适用场景
适合的场景
动态合批特别适合以下场景:
- 低多边形物体集群:弹药、收集品、简单装饰物
- 粒子系统补充:不使用粒子系统的小型效果元素
- 大量移动的简单物体:子弹、碎片、小石块
不适合的场景
动态合批不适合以下情况:
- 高多边形模型:角色、主要场景物体、复杂建筑
- 需要独特外观的物体:使用MaterialPropertyBlock为每个实例提供变化
- 静态场景元素:这些应使用静态合批或GPU实例化
调试与监测动态合批
使用Frame Debugger
- 打开 Window > Analysis > Frame Debugger
- 点击 "Enable" 开始调试当前帧
- 查看各个Draw Call和批处理组
- 右侧面板会显示批处理原因或失败原因
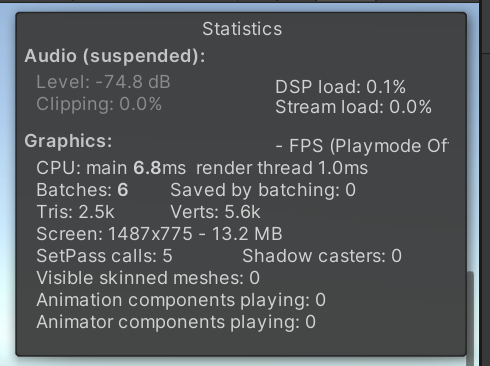
使用Statistics窗口
- 在Game视图中启用Statistics面板
- 观察Batches(批次)、Saved by batching(合批节省)数值
- 实时监控改变对合批的影响
使用Profiler追踪性能
- 打开 Window > Analysis > Profiler
- 在CPU模块中展开Rendering部分
- 观察Dynamic Batching相关的CPU开销
动态合批与静态合批
- 静态物体使用静态合批(更高效,无运行时开销)
- 移动物体使用动态合批
- 两者可以同时使用,对不同类型的对象进行优化
常见问题与解决方案
合批没有生效
可能的原因及解决方案:
帧调试器显示未合批的Draw Calls
- 确认网格顶点数不超过限制
- 验证所有物体使用完全相同的材质实例
- 检查物体是否使用了MaterialPropertyBlock
- 查看是否启用了特殊渲染功能
合批后性能反而下降
原因:
- CPU开销超过了节省的Draw Call成本
- 过度合批导致大量额外的CPU计算
解决方法:
- 为复杂物体禁用动态合批,使用GPU实例化
- 仅对小型、大量的物体启用动态合批
- 考虑混合使用多种批处理技术
材质问题导致批处理分裂
解决方案:
1. 使用MaterialPropertyBlock :
MaterialPropertyBlock props = new MaterialPropertyBlock();
props.SetColor("_Color", color);
renderer.SetPropertyBlock(props);2. 创建材质图集,将多个纹理合并到一个大纹理中
3. 使用着色器中的条件分支,而不是多个材质变体

















 1989
1989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









