






基于ESP32-S3的豆包语音智能助手实现
项目概述
本项目基于ESP32-S3微控制器,构建了一个实时响应的AI语音助手系统。通过WebSocket协议与豆包大模型对接,具备强大的对话能力和高度可定制性。
硬件准备
- ESP32-S3SuperMini开发板:搭载双核处理器,主频240MHz,集成WiFi和蓝牙模块
- I2S麦克风INMP441:用于语音信号采集
- I2S扬声器MAX98357:用于语音输出
- 接线示意图:
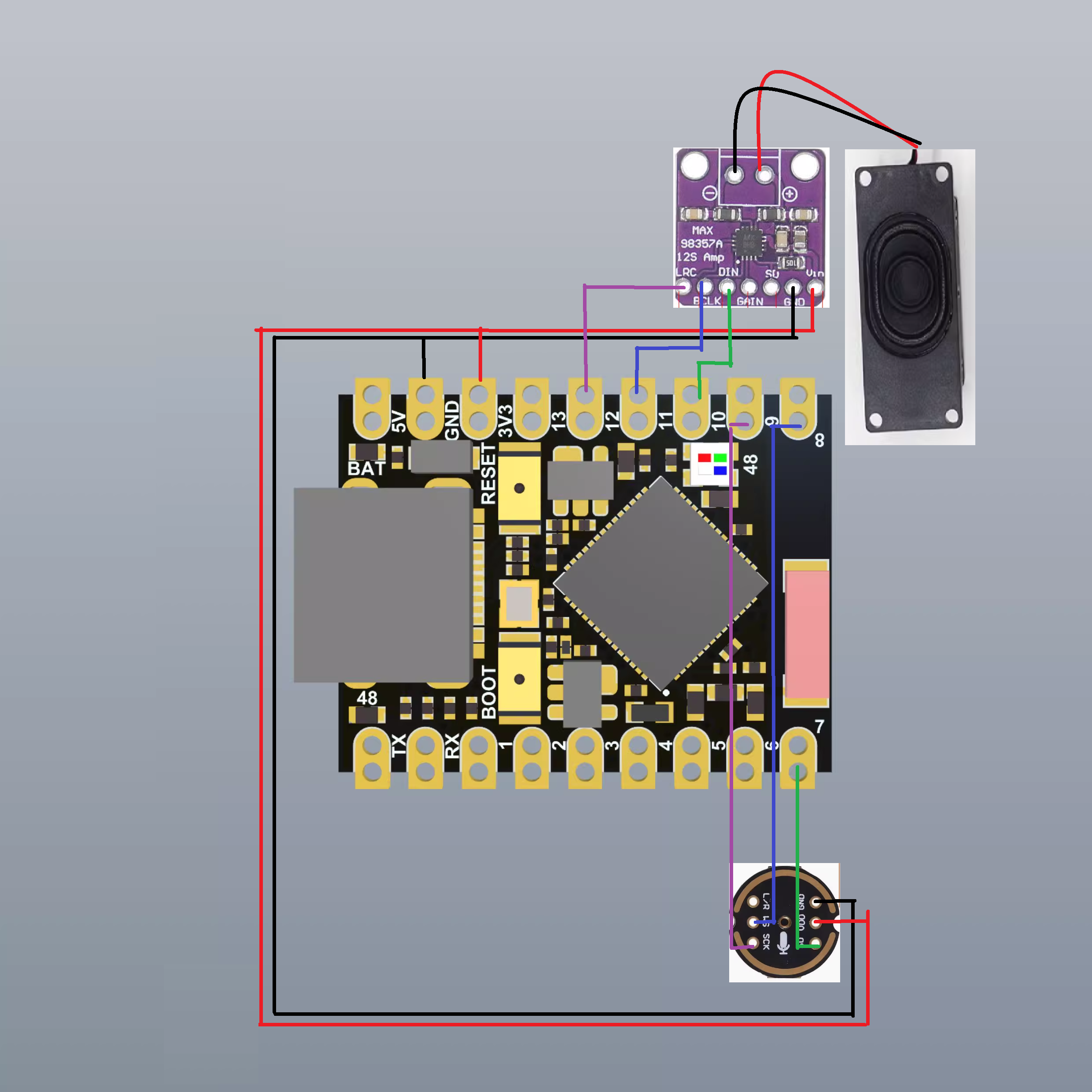
软件架构
系统采用MicroPython-esp32-1.25.0-4M固件开发环境,主要功能模块包括:
- WebSocket通信:基于aiohttp库实现与豆包API的双向数据交互
- 音频采集:通过I2S接口获取麦克风输入
- 音频播放:通过I2S接口输出语音内容
- 语音活动检测(VAD):本地实时识别用户语音状态
- 消息队列管理:协调系统与服务端的数据交互
- 固件下载地址:https://micropython.org/resources/firmware/ESP32_GENERIC_S3-FLASH_4M-20250415-v1.25.0.bin
豆包音频智能体协议
核心技术实现
语音活动检测(VAD)
采用高效的能量检测算法实现语音识别:
volume = 0
for i in range(0, bytes_read, 2):
if i + 1 < bytes_read:
sample = (audio_buffer[i+1] << 8) | audio_buffer[i]
if sample & 0x8000: sample = -((~sample & 0xFFFF) + 1)
volume += abs(sample)
avg_volume = volume / (bytes_read // 2) if bytes_read > 0 else 0
is_currently_silent_chunk = avg_volume <= SILENCE_THRESHOLD
通过设置语音时长和静音阈值,有效过滤背景噪音:
MIN_VALID_SPEECH_DURATION_S = 0.4
POST_SPEECH_SILENCE_THRESHOLD_S = 1.5
异步通信架构
基于asyncio框架实现多任务并发处理:
- 音频采集线程持续监听用户语音
- WebSocket线程处理服务端消息
- 消息队列线程负责数据发送
这种架构确保了系统的高效运行,避免了任务阻塞。
豆包API交互流程
- 建立会话:初始化WebSocket连接
- 采集音频:检测到有效语音后编码传输
- 提交处理:语音段结束后请求响应
- 接收响应:解析并播放返回的音频
关键代码实现:
elif event_type == 'input_audio_buffer.committed':
item_id = data.get('item_id')
print(f"✅ 服务端已确认音频提交 (Item ID: {item_id})")
waiting_for_response_creation = True
response_create_msg = {
"type": "response.create",
"response": {
"modalities": ["audio"],
"voice": VOICE_ID
}
}
add_to_message_queue(response_create_msg)
内存优化
针对ESP32-S3的资源限制,采用以下优化策略:
- 主动垃圾回收:在关键节点调用
gc.collect() - 数据分块处理:将音频数据分段传输
- 资源释放:及时关闭不再使用的I2S设备
- 高效队列管理:使用deque避免内存泄漏
容错设计
系统具备完善的容错机制:
- 自动重连:WebSocket断开后自动恢复
- 异常捕获:全面处理各类运行异常
- 设备重初始化:I2S设备故障时自动恢复
if not audio_in:
print("🎤 麦克风未初始化,尝试重新初始化...")
audio_in = init_i2s_mic()
if not audio_in:
print("❌ 麦克风重初始化失败,暂停录音")
time.sleep(1)
continue
代码结构
/
├── main_ai.py # 程序入口点,负责初始化和启动应用
├── doubao_chat.py # 核心实现文件,包含语音交互和WebSocket通信逻辑
├── config.py # 配置文件,包含WiFi凭证、API密钥和硬件引脚定义
├── boot.py # MicroPython启动文件,设置系统参数
│
├── aiohttp/ # WebSocket通信模块
│ ├── __init__.py # 模块初始化文件
│ ├── aiohttp_ws.py # WebSocket客户端实现
应用场景
本系统适用于多种场景:
- 智能家居控制:自定义设备控制指令
- 便携助手:随身携带的语音交互设备
- 教育机器人:儿童知识问答与学习
固件成本
Esp32s3SuperMini开发板 x1(20元)
max98357音频模块 x1(5元)
inmp441麦克风模块 x1(5元)
8R/3W喇叭 x1(3元)
线材 x1(2元)
合计 35元
运行截图及视频
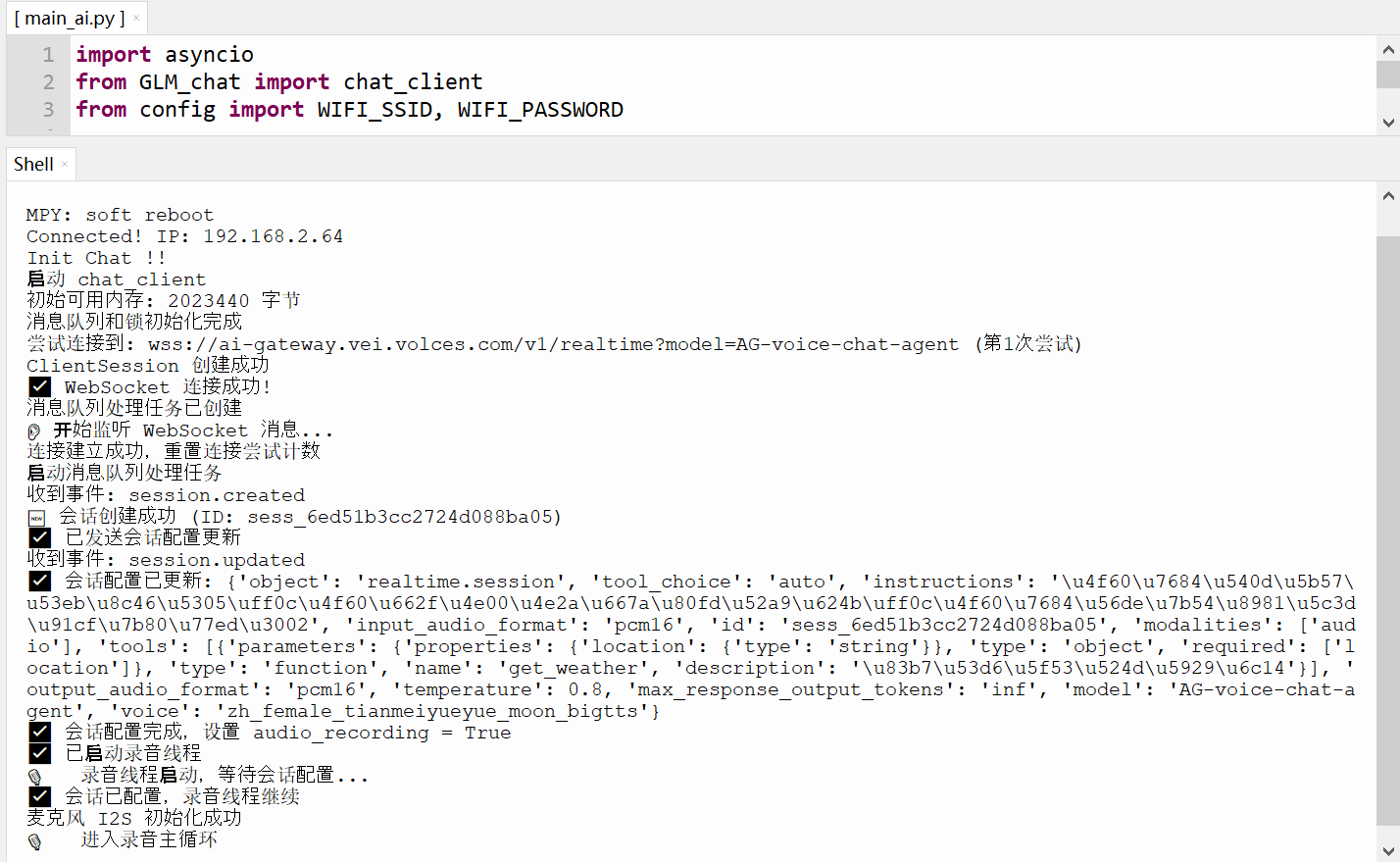
豆包语音智能体-英文老师角色
总结
本项目成功将ESP32-S3的计算能力与豆包AI的语言理解能力相结合,构建了一个功能完善、响应迅速的语音智能助手。该方案为资源受限的嵌入式设备开发复杂AI应用提供了实践参考。未来我们将持续优化系统性能,拓展应用场景,为用户带来更智能的语音交互体验。
源码地址:zhou19830318/doubao_ai_agent_esp32: 基于micropython的esp32s3+豆包语音智能体实时语音对话智能助手

















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









