







1. 前言
随着端到端 AI 和多模态学习的迅猛发展,VLM(视觉-语言模型)在自动驾驶领域中的应用正逐渐成为一个备受瞩目的重要研究方向。VLM 凭借其强大的融合能力,将视觉(如高清晰度的摄像头图像、精准的雷达数据)和语言(涵盖详细的地图信息、明确的交通标志、准确的驾驶指令)等多种类型的信息进行有机整合,从而使得自动驾驶系统在感知复杂的道路环境、进行精确的推理以及制定明智的决策等方面展现出更为卓越的智能化水平。
2. 为什么自动驾驶需要 VLM
传统自动驾驶系统主要依赖传感器(如摄像头、激光雷达)以及规则/深度学习模型来实现感知和决策。然而,以下几个关键问题在很大程度上限制了传统方法的性能和应用范围:
复杂环境理解:在现实的交通场景中,存在着各种各样的元素和情况。单纯依靠视觉模型,往往难以精确地解读路牌、标志所蕴含的信息,对于施工区域、临时交通管制等特殊情况的理解也容易出现偏差。这些高层语义信息对于自动驾驶系统做出准确和安全的决策至关重要。
可解释性不足:深度学习模型在处理大量数据时表现出色,但却像一个黑箱,难以清晰地解释车辆的决策逻辑。这使得在出现问题或需要进行调整时,难以准确追溯和理解系统的决策过程,给调试和优化带来了巨大的挑战。
人机交互****受限:现有的自动驾驶系统在与人的交互方面存在明显的不足。它们难以直接接收语音或文本指令,比如驾驶员想要更改目的地或者询问当前的路况信息。同时,对于驾驶相关的问题,系统也无法给出及时和准确的回答,无法满足人们对于个性化和智能化交互的需求。
VLM 技术的出现为解决这些问题带来了新的契机。通过多模态融合(视觉+文本),它能够更全面地获取环境信息,增强自动驾驶系统的环境理解能力。例如,结合文本描述可以更好地解读复杂的交通标识和场景。同时,多模态融合也有助于提升交互能力,使系统能够与驾驶员和乘客进行更自然和流畅的交流。此外,这种融合还能为决策过程提供更丰富的依据,从而提高决策的准确性和可靠性。
3. VLM 在自动驾驶的核心应用
3.1 视觉感知增强
传统自动驾驶依赖 CNN 或 Transformer 进行目标检测,但在复杂环境(如遮挡、光照变化)下存在局限。VLM 结合图像和文本信息,可以提高物体识别的准确性。例如:
识别交通标志时,结合视觉和文本信息理解标志含义(如“限速 60km/h”)。
在夜间或恶劣天气下,利用 VLM 融合激光雷达点云+地图信息,增强感知能力。
示例:
BEV-LLaVA(Bird’s Eye View + VLM):将鸟瞰视角(BEV)数据和 VLM 结合,提高 3D 目标检测和车道识别能力。
GPT-4V + 自动驾驶:利用 GPT-4V 处理实时行车画面,并结合地图数据进行交通场景分析。
3.2 场景理解与语义推理
自动驾驶需要语义级别的推理,例如理解“前方施工,请绕行”的交通标志并规划路线。传统方法主要依赖硬编码规则,而 VLM 可以从大规模数据中学习更复杂的语义关系。
示例:
多模态 Transformer 处理复杂驾驶场景:
结合摄像头图像 + 车载 GPS 数据,实现更精准的路径规划。
识别行人手势,推理行人是否在示意车辆让行。
3.3 视觉问答
自动驾驶辅助决策:VLM 可用于车载系统的视觉问答,帮助系统或驾驶员进行决策。例如:
“前方是否有行人?”
“这条车道可以变道吗?”
“距离下一个红绿灯还有多远?”
案例:
LLaVA-AD(LLaVA for Autonomous Driving):基于 LLaVA 训练的自动驾驶专用 VLM,支持实时视觉问答,提高驾驶决策的可解释性。
3.4 端到端导航与指令理解
VLM 使自动驾驶系统能够理解自然语言的导航****指令(如“沿着这条路开 2 公里,然后在红绿灯处右转”)。传统 GPS 导航依赖规则匹配,VLM 使其更加灵活,例如:
结合驾驶员的语音指令 + 视觉环境信息,提供更人性化的导航体验。
示例:
VLM 结合地图导航(Vision-Language Navigation, VLN):
Tesla 的 FSD V12 可结合 VLM,在地图上标注 POI(兴趣点),提高自动驾驶导航能力。
3.5 异常检测与安全驾驶
自动驾驶在复杂环境下容易受到意外情况的影响,例如:
施工区、事故现场、异常行人行为等。
VLM 通过跨模态数据分析,可以更快速地识别异常情况并做出合理决策。
示例:
自动驾驶黑匣子(Autonomous Driving Blackbox with VLM): 结合摄像头、激光雷达数据 + 语义描述,记录事故发生前的驾驶场景,提高责任归属判定的透明度。
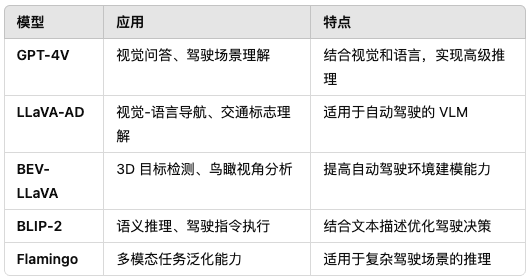
3.6 代表性 VLM 在自动驾驶中的应用
4. 挑战与未来发展
4.1 挑战
实时性问题:VLM 计算量大,如何优化推理速度以满足自动驾驶的实时需求?
数据泛化能力:如何确保 VLM 能够适应全球不同国家和城市的交通规则?
可解释性:端到端 VLM 可能缺乏决策透明度,如何提高系统的可解释性?
4.2 未来发展方向
轻量化部署:优化模型结构,使 VLM 可在车载计算平台高效运行。
多模态融合增强:结合激光雷达、毫米波雷达数据,提高 VLM 在极端天气下的表现。
4.2 未来发展方向
轻量化部署:优化模型结构,使 VLM 可在车载计算平台高效运行。
多模态融合增强:结合激光雷达、毫米波雷达数据,提高 VLM 在极端天气下的表现。
与端到端自动驾驶结合:VLM 未来可能直接融入端到端自动驾驶大模型,提高智能化水平。

















 3516
3516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









