






模型部署-什么是模型部署?
0总结
1 什么是模型部署?
不管是选择偏算法研究的方向还是偏工程化的方向,在项目落地中都要培养一种端到端的能力,模型部署和优化更加偏向于业务落地,那么首先明确模型部署和优化在整个端到端流程中的位置,一般来说,从业务提出之后,大概需要经历下面一个闭环使能的pipeline: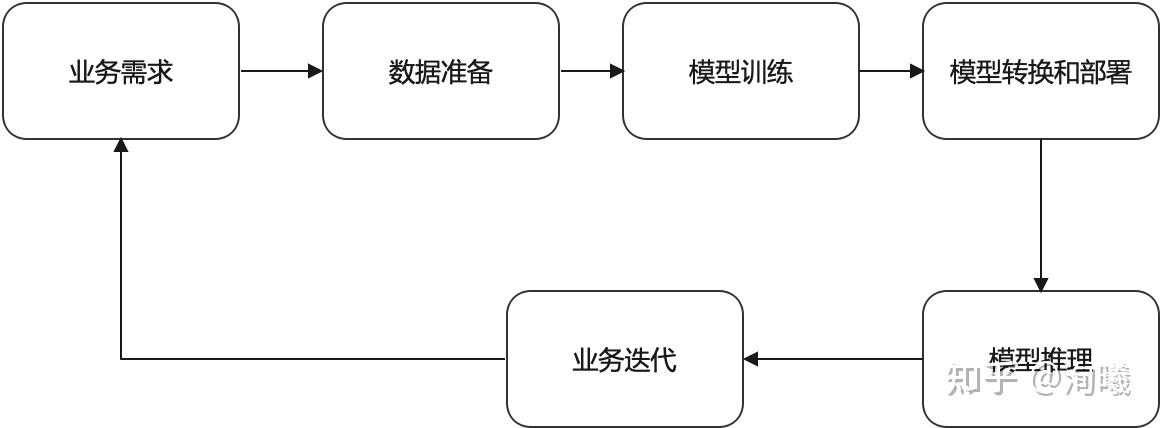
但最好还是多点开花并且可以形成自己的一套端到端的方法论,除了明确模型优化部署的任务和上下游关系,更要从业务角度去推进优化的工作,即做到一种全栈式的发展,随便给你一个业务或者产品形态,可以快速的针对特定的硬件或者算法模型找出适配的一套最佳优化方案(人力成本,效率迭代等),这才是做这个方向的最终目的,这也是大多数公司比较稀缺的。如果仅仅停留在关注部署或者优化的某一个技术栈,而不是用端到端业务全流程的角度看问题,最终可能就是成为工作比较枯燥的工具人,技能也不会得到很好的锻炼。
1 部署流程:
部署的流程大致可以分为以下几个环节: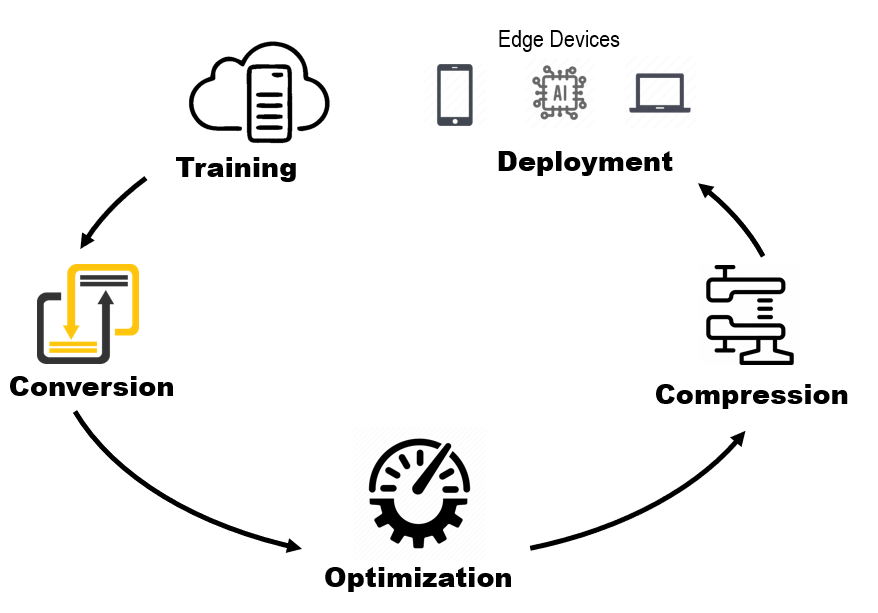
如果你只是想要简单的把自己训练的模型部署一下玩一玩:那么可能不需要那么麻烦,只需要:
- 训练----转换----部署:
但是假如你想要做模型部署优化的话,可能就是一门非常深且且比较杂的问题了,你需要在原来的基础上加上:
- 模型结构优化----模型压缩----推理优化----部署优化;
模型部署优化可简单分为以下大方向:
-
- 模型结构优化:设计出更适合目标硬件的模型结构,网络结构层面的优化,也有一些NAS
-
- 模型压缩:不改变模型框架的情况下,压缩其理论计算量,其中模型剪枝、模型量化最为常用
-
- 推理优化:编写高性能的算子来加速模型在目标硬件的计算;包括算子融合,图优化,内存以及线程调优,编译优化等等;
- 4,部署形态就会涉及云端部署和移动端部署,那么需要了解和掌握的硬件结构包括CPU,NPU,GPU,FPGA等等
2 为什么模型部署这么复杂?
在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
- 运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
- 深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线: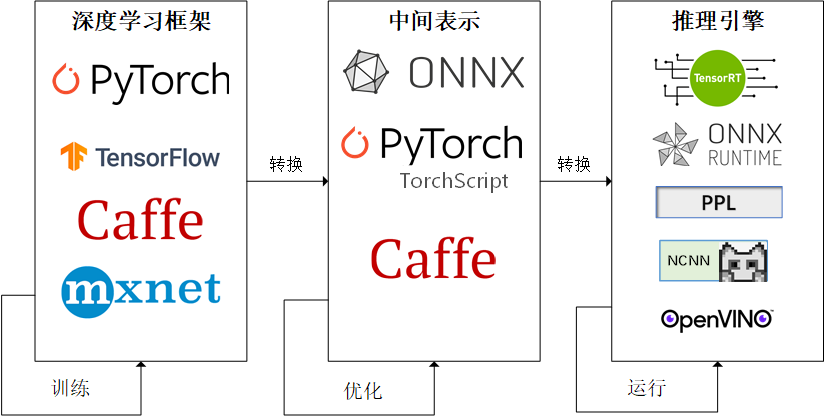
为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
3 模型部署学习建议:
答主的训练框架是PyTorch,我推荐一个相对简单的路线,把各个部分过一下,然后你可以选择自己感兴趣的点深入
1. 结构:学习一下 MobileNet(当初面试,就被问了MobileNet的特点和实现细节)、ShuffleNet 、Yolo等面向部署的模型结构,最好读读论文搞懂为什么要这样设计;
2. 剪枝:用NNI、TinyNeuralNetwork 等框架对模型进行剪枝,并阅读其源码了解常用的剪枝方法
3. 量化:用PyTorch 的 FX 模块、TinyNeuralNetwork等框架完成模型的量化,如果要深入了解原理建议阅读Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference 这篇论文(非常经典,里面还有汇编如何实现等底层细节)。
4. 推理:这块已经很成熟了,基本就调用目标芯片对应的框架,例如TensorRT(NVIDIA GPU),OpenVINO(Intel CPU), MNN、TNN、TFLite(大部分移动端芯片),TFLite Micro、Tengine(特定嵌入式芯片),除此之外很多芯片厂商还提供了自己的解决方案此处不多赘述。
5. 推理性能优化:目前深度学习推理性能优化,大部分情况下等同于矩阵乘法的加速,因此题主可以找几篇矩阵乘法加速的文章阅读并实践一下。此处不建议直接去读推理框架源码,除非真的很感兴趣并决定深耕,因为这块较为底层,上手难度很大。
2 详细介绍:
1 模型转换
从训练框架得到模型后,根据需求转换到相应的模型格式。模型格式的选择通常是根据公司业务端 SDK 的需求,通常为 caffe 模型或 onnx 模型,以方便模型在不同的框架之间适配。
2 模型优化
此处的模型优化是指与后端无关的通用优化,比如常量折叠、算数优化、依赖优化、函数优化、算子融合以及模型信息简化等等。部分训练框架会在训练模型导出时就包含部分上述优化过程,同时如果模型格式进行了转换操作,不同IR表示之间的差异可能会引入一些冗余或可优化的计算,因此在模型转换后通常也会进行一部分的模型优化操作。
该环节的工作需要对计算图的执行流程、各个 op 的计算定义、程序运行性能模型有一定了解,才能知道如果进行模型优化,如何保证优化后的模型具有更好的性能。
模型结构优化:
模型结构当然就是探索更快更强的网络结构,就比如ResNet相比比VGG,在精度提升的同时也提升了模型的推理速度。又比如CenterNet相比YOLOv3,把anchor去掉的同时也提升了精度和速度。
3 模型压缩:
广义上来讲,模型压缩也属于模型优化的一部分。模型压缩本身也包括很多种方法,比如剪枝、蒸馏、量化等等。**模型压缩的根本目的是希望获得一个较小的模型,减少存储需求的同时降低计算量,从而达到加速的目的。**该环节的工作需要对压缩算法本身、模型涉及到的算法任务及模型结构设计、硬件平台计算流程三个方面都有一定的了解。
当因模型压缩操作导致模型精度下降时,对模型算法的了解,和该模型在硬件上的计算细节有足够的了解,才能分析出精度下降的原因,并给出针对性的解决方案。
对于模型压缩更重要的往往是工程经验,因为在不同的硬件后端上部署相同的模型时,由于硬件计算的差异性,对精度的影响往往也不尽相同,这方面只有通过积累工程经验来不断提升。
剪枝:用NNI、TinyNeuralNetwork 等框架对模型进行剪枝,并阅读其源码了解常用的剪枝方法
量化:用PyTorch 的 FX 模块、TinyNeuralNetwork等框架完成模型的量化,如果要深入了解原理建议阅读Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference 这篇论文(非常经典,里面还有汇编如何实现等底层细节)。
剪枝:
我理解的剪枝,就是在大模型的基础上,对模型通道或者模型结构进行有目的地修剪,剪掉对模型推理贡献不是很重要的地方。经过剪枝,大模型可以剪成小模型的样子,但是精度几乎不变或者下降很少,最起码要高于小模型直接训练的精度。
积攒了一些比较优秀的开源剪枝代码,还咩有时间细看:
- yolov3-channel-and-layer-pruning
- YOLOv3-model-pruning
- centernet_prune
- ResRep
蒸馏
我理解的蒸馏就是大网络教小网络,之后小网络会有接近大网络的精度,同时也有小网络的速度。
再具体点,两个网络分别可以称之为老师网络和学生网络,老师网络通常比较大(ResNet50),学生网络通常比较小(ResNet18)。训练好的老师网络利用soft label去教学生网络,可使小网络达到接近大网络的精度。
印象中蒸馏的作用不仅于此,还可以做一些更实用的东西,之前比较火的centerX[20],将蒸馏用出了花,感兴趣的可以试试。
稀疏化
稀疏化就是随机将Tensor的部分元素置为0,类似于我们常见的dropout,附带正则化作用的同时也减少了模型的容量,从而加快了模型的推理速度。
稀疏化操作其实很简单,Pytorch官方已经有支持,我们只需要写几行代码就可以:
置0后可以简单测试一下模型的精度…精度当然是降了哈哈!所以需要finetune来将精度还原,这种操作其实和量化、剪枝是一样的,目的是在去除冗余结构后重新恢复模型的精度。
那还原精度后呢?这样模型就加速了吗?当然不是,稀疏化操作并不是什么平台都支持,如果硬件平台不支持,就算模型稀疏了模型的推理速度也并不会变快。因为即使我们将模型中的元素置为0,但是计算的时候依然还会参与计算,和之前的并无区别。我们需要有支持稀疏计算的平台才可以。
英伟达部分显卡是支持稀疏化推理的,英伟达的A100 GPU显卡在运行bert的时候,稀疏化后的网络相比之前的dense网络要快50%。我们的显卡支持么?只要是Ampere architecture架构的显卡都是支持的(例如30XX显卡)。
量化:
这里指的量化训练是在INT8精度的基础上对模型进行量化。简称QTA(Quantization Aware Training)。
量化后的模型在特定CPU或者GPU上相比FP32、FP16有更高的速度和吞吐,也是部署提速方法之一。
PS:FP16量化一般都是直接转换模型权重从FP32->FP16,不需要校准或者finetune。
量化训练是在模型训练中量化的,与PTQ(训练后量化)不同,这种量化方式对模型的精度影响不大,量化后的模型速度基本与量化前的相同(另一种量化方式PTQ,TensorRT或者NCNN中使用交叉熵进行校准量化的方式,在一些结构中会对模型的精度造成比较大的影响)。
举个例子,我个人CenterNet训练的一个网络,使用ResNet-34作为backbone,利用TensorRT进行转换后,使用1024x1024作为测试图像大小的指标:
精度/指标:
- FP32
- INT8(PTQ)
- INT8(QTA)
| AP | 0.93 | 0.83 | 0.94 |
| — | — | — | — |
| 速度 | 13ms | 3.6ms | 3.6ms |
精度不降反升(可以由于之前FP32的模型训练不够彻底,finetune后精度又提了一些),还是值得一试的。
目前我们常用的Pytorch当然也是支持QTA量化的。
不过Pytorch量化训练出来的模型,官方目前只支持CPU。即X86和Arm,具有INT8指令集的CPU可以使用:
- x86 CPUs with AVX2 support or higher (without AVX2 some operations have inefficient implementations)
- ARM CPUs (typically found in mobile/embedded devices)
4 模型推理与部署:
模型部署是整个过程中最复杂的环节。从工程上讲,主要的核心任务是模型打包、模型加密,并进行SDK封装。在一个实际的产品中,往往会用到多个模型。模型打包是指将模型涉及到的前后处理,以及多个模型整合到一起,并加入一些其他描述性文件。模型打包的格式和模型加密的方法与具体的 SDK 相关。在该环节中主要涉及到的技能与 SDK 开发更为紧密。
从功能上讲,对部署最后的性能影响最大的肯定是 SDK 中包含的后端库,即实际运行模型的推理库。开发一个高性能推理库所需要的技能点就要更为广泛,并且专业。并行计算的编程思想在不同的平台上是通用的,但不同的硬件架构的有着各自的特点,推理库的开发思路也不尽相同,这也就要求对开发后端的架构体系有着一定的了解。
推理库:这块已经很成熟了,基本就调用目标芯片对应的框架,例如TensorRT(NVIDIA GPU),OpenVINO(Intel CPU), MNN、TNN、TFLite(大部分移动端芯片),TFLite Micro、Tengine(特定嵌入式芯片),除此之外很多芯片厂商还提供了自己的解决方案此处不多赘述。
:::info
我的理解:
就是你想要在某个设备上部署某个模型,你需要在设备上先安装推理框架。就像是,无论你在那个厨房做菜,无论是大的,还是小的,基本的火源都要有。 这些推理框架,就是基本的。 你像你平时在服务器利用pytorch训练的模型,然后可以进行推理,是因为你已经有了pytorch在linux下的推理框架了。 假如是其他设备呢?比如你的手机呢?这里没有显卡,但是也想使用深度学习推理结果呢?
:::
TensorRT
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。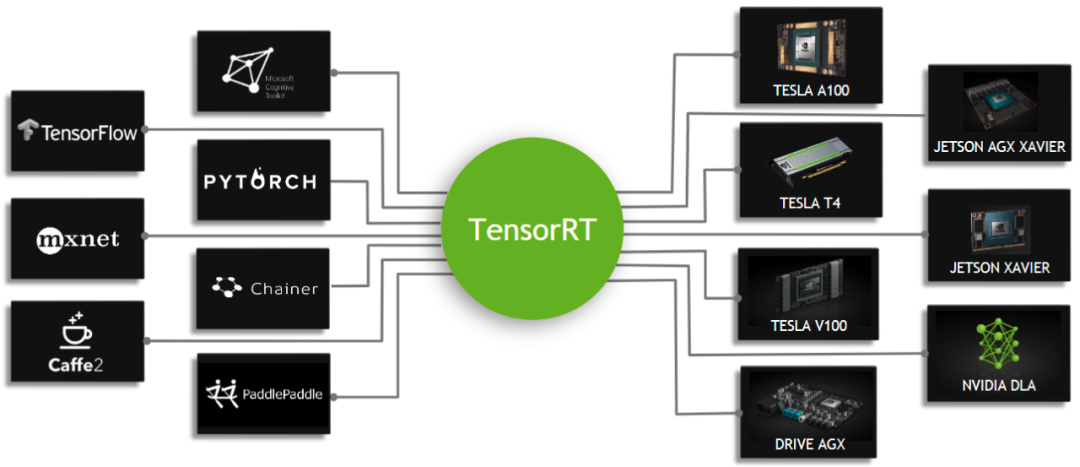
TensorRT老潘有单独详细的教程,可以看这里:
OpenVINO
在英特尔CPU端(也就是我们常用的x86处理器)部署首选它!开源且速度很快,文档也很丰富,更新很频繁,代码风格也不错,很值得学习。
在我这边CPU端场景不是很多,毕竟相比于服务器来说,CPU场景下,很多用户的硬件型号各异,不是很好兼容。另外神经网络CPU端使用场景在我这边不是很多,所以搞得不是很多。
NCNN/MNN/TNN/TVM
有移动端部署需求的,即模型需要运行在手机或者嵌入式设备上的需求可以考虑这些框架。这里只列举了一部分,还有很多其他优秀的框架没有列出来…是不是不好选?
- NCNN
- MNN
- TNN
- TVM
- Tengine
个人认为性价比比较高的是NCNN[13],易用性比较高,很容易上手,用了会让你感觉没有那么卷。而且相对于其他框架来说,NCNN的设计比较直观明了,与Caffe和OpenCV有很多相似之处,使用起来也很简单。可以比较快速地编译链接和集成到我们的项目中。
TVM和Tengine比较复杂些,不过性能天花板也相比前几个要高些,可以根据取舍尝试。
3 模型部署优化实例:
本文介绍深度学习模型部署相关的工作,会进行持续更新,敬请期待!
- 增量训练还是离线训练?
- CPU还是GPU? 太长不看版:有钱上GPU。
- 架构选择:
AI服务器与PC端一般都是使用X86架构,因为其高性能;AI端侧设备(手机/端侧盒子等)一般使用ARM架构,因为需要低功耗。
X86指令集中的指令是复杂的,一条很长指令就可以很多功能;而ARM指令集的指令是很精简的,需要几条精简的短指令完成很多功能。
X86的方向是高性能方向,因为它追求一条指令完成很多功能;而ARM的方向是面向低功耗,要求指令尽可能精简。
(来源:【三年面试五年模拟】算法工程师的独孤九剑秘籍(第五式))
- 推理加速

(来源:【三年面试五年模拟】算法工程师的独孤九剑秘籍(第三式))
- 量化模型
2. 计算精度:FP32,FP16以及Int8;
- 常规精度一般使用FP32(32位浮点,单精度)占用4个字节,共32位;低精度则使用FP16(半精度浮点)占用2个字节,共16位,INT8(8位的定点整数)八位整型,占用1个字节等。
- 混合精度(Mixed precision)指使用FP32和FP16。 使用FP16 可以减少模型一半内存,但有些参数必须采用FP32才能保持模型性能。
- 虽然INT8精度低,但是数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点。
- 不同精度进行量化的归程中,量化误差不可避免。
- 在模型训练阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。在inference的阶段,精度要求没有那么高,一般F16或者INT8就足够了,精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在端侧设备中。
(来源:【三年面试五年模拟】算法工程师的独孤九剑秘籍(第五式))
5. 将一个或多个深度学习模型部署为微服务的情况(以下内容来源:一个「菜鸟」转行AI的成长心得!
有以下好处:
- 部署使用分离。所有的推理都通过 RPC 或 RestFul 接口实现,与模型部署无关,甚至与模型本身也无关,服务模块只关心输入和输出。这样当我们需要更新模型时,只需将新模型放到对应位置即可,代码层面不用做任何改动。
- 合理利用资源。所有的模型可以统一部署到一个服务下,共享同一个服务器资源。因为模型一般是用 GPU 服务器,而普通的服务一般是用 CPU 服务器,这样的部署方式能够更合理地利用资源。
- 统一管理监控。因为所有的模型逻辑上都在一起,所以无论日常的管理还是数据的监控,实施起来都比较方便。
在部署时,推荐使用容器化部署方案,使用 k8s 或类似的集群框架对服务进行管控。这不是我们要赶潮流,主要是考虑到以下几个优点:
- 部署方便。完全不用考虑不同环境可能造成的冲突,所有的服务相互隔离。部署时通过 YAML 配置服务,实现一键全自动部署。
- 便于扩展。水平扩展可以直接添加实例,垂直扩展修改资源限制,所有配置均可通过配置文件完成,完全实现资源配置化。而集群资源不够时,直接添加节点主机即可。
- 便于管控。通过 Istio 等组件非常容易实现流量和服务管控。比如可以很容易地配置实现灰度发布,进行线上 A/B 测试,而且这些功能都是和业务解耦的。
- 节约资源。因为集群的服务其实是共享节点资源的,所以高峰时期服务会自动多占用资源(当然不会超过配置的限制),低谷时期就自动释放资源。这样其实最大限度地利用了可利用的资源,节约了成本。
- 管理方便。从管理机器变成管理服务,只要配置好相应的服务,机器只是无状态的节点,多一个少一个挂一个重启一个对服务没有影响。而且集群还支持非常细粒度的权限控制,使用权限可以按需下发到部门或个人。
参考
https://cloud.tencent.com/developer/article/1841046
https://www.zhihu.com/question/508977221/answer/2352691772
https://www.zhihu.com/question/411393222/answer/2359479242
第一章:模型部署简介 — mmdeploy 1.3.1 文档
https://www.zhihu.com/question/329372124/answer/2584115876















 6100
6100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









