






导读
近年来,生成对抗技术在诸多图像任务中得到运用,包括图像编辑和生成、风格迁移和转化、图文描述生成、少样本数据增强、图像攻防对抗以及 AI 字体设计等。图像生成对抗虽然取得不少成功运用案例,但其训练效率对规模化日常迭代是个挑战。为此,阿里妈妈搜索广告团队 联合 浙江大学宋明黎教授的视觉智能与模式分析团队 对此项工作开展了探索性研究,并提出了一种单阶段生成对抗训练方法(OSGAN, Training Generative Adversarial Networks in One Stage)来提升传统 GAN 任务的训练效率。实测该方法比传统两阶段训练方法实现了1.5倍的训练加速。该项工作论文已被 CVPR 2021录用,并已开源,欢迎交流讨论。
论文下载:https://arxiv.org/abs/2103.00430
开源项目:https://github.com/zju-vipa/OSGAN
背景
在诸多神经网络中,生成对抗网络(Generative Adversarial Network,GAN)的训练方式和其他神经网络训练存在较大的区别:传统 CNN 任务中,网络各部分都按照最小化目标函数的方向进行优化,而 GAN 中生成器(generator)和判别器(discriminator)则是朝着相反的方向进行优化,以形成对抗。为此,当时Ian J. Goodfellow [1]采用了对生成器和判别器进行交替优化的方案,归纳为两阶段训练方式(Two-Stage GAN,如下图1所示)。显然,这种两阶段训练方式引入了不少重复的计算量,使得GAN的训练效率通常低于其他神经网络。
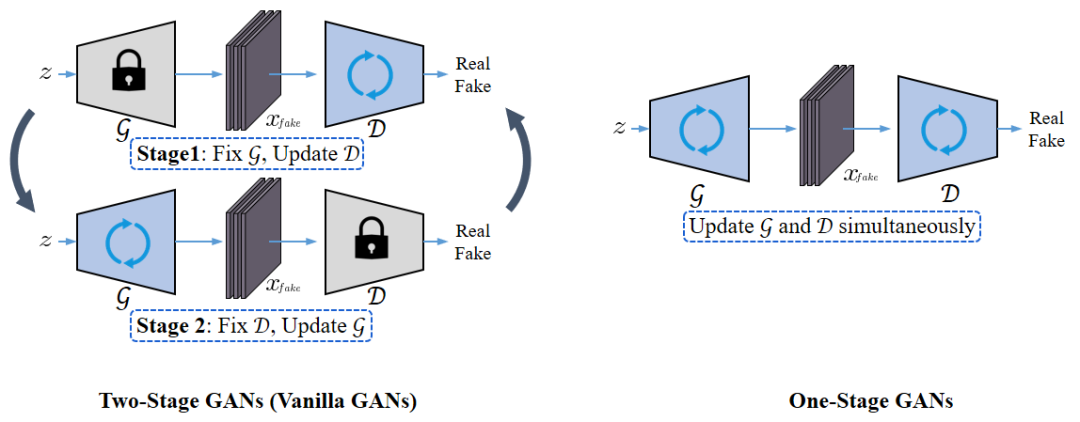
针对上述 GAN 训练效率低的问题,以下简短介绍下我们最近发表在 CVPR 2021上的工作:Training Generative Adversarial Networks in One Stage。文章对该问题进行了深入的研究探索,即如何在一次训练迭代中,同时完成对生成器和判别器的更新以消除Two-Stage GAN训练中存在的冗余计算。文章中同样将现有的 GAN 分为对称GAN(Symmetric GAN)和 非对称GAN(Asymmetric GAN)两大类[2],并着重研究了如何对更加复杂的非对称GAN进行了单阶段训练的问题。最后,对 One-Stage GAN 相对于 Two-Stage GAN 的加速比进行了对应分析。

方案
我们先简单回顾下目前主流的两类生成对抗训练方法:
对称GAN vs 非对称GAN
GAN通过引入判别器网络和生成器网络之间最大化最小化的博弈过程[1],使得生成网络实现了真实性样本合成。GAN所采用的目标函数如下:

为了后续讨论的方便,我们将上述目标函数拆解成分别针对判别器 和生成器 的损失函数,其形式如下:

其中, 和 包含了关于 的相同对抗损失项: 。因此,将这种生成对抗网络称为 对称型GAN 。为了缓解训练过程中生成器网络梯度消失的问题,有学者又提出了非饱和对抗损失函数[3]:
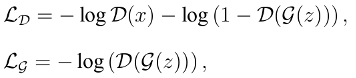
其中,生成器网络和判别器网络关于 的对抗损失项并不一致: vs 。将上述生成对抗网络称为 非对称型GAN 。
如上述公式所述,GAN目标函数中的对抗项通常是关于 的。因此,为了分析的方便性,将一般化的 分成两个部分:关于真实样本的损失项 和关于假样本的损失项 ,其中 。最终生成对抗网络一般化的目标函数可以表示为:

对于对称型生成对抗网络来说,其对抗损失项满足: ;而对于非对称型生成对抗网络来说,其对抗损失项满足: 。
对称型GAN的单阶段训练
对于对称型GAN, 和 包含相同的关于假样本 的损失项: 。其关于 的梯度可以分别表示为 和 。通过在 上乘以 来得到 。因此,可以利用在训练判别器 期间得到的 进一步计算得到关于生成器 参数的梯度,从而在更新实现 的同时,训练生成器 。综上所述,上述方法可以将对称型 GAN 的两阶段训练过程简化成单阶段过程。
非对称型GAN的单阶段训练
对于非对称型GAN,由于 ,梯度 无法直接像对称型GAN一样从 中获取到。一种直接的思路是将 和 整合成一个损失函数,例如 ,从而我们可以从 中获取得到 。因为GAN的对抗特性, 和 的符号通常是相反的。因此,我们采用以下损失函数整合方式:

而不采用
,以避免
和
之间因为符号相反而产生的梯度抵消。设
,以合并关于假样本的损失项。然而,这种方式会产生另外一个问题:如何从混合的梯度
中恢复出
。
为了解决上述问题,我们对判别器网络的反向传播进行了调研,发现了主流神经网络模块中有一个很有意思的反向传播性质。除了批归一化模块,其他模块对应的损失函数 关于输入的梯度 和关于输出的梯度 之间的关系可以表示为:

其中 和 是由对应神经模块或者其输出决定的矩阵; 是一个满足如下关系的函数:

上述梯度满足公式的神经网络模块主要包括卷积模块、全连接模块以及非线性激活函数、以及池化模块等。需要说明的是,虽然非线性激活函数和池化模块是非线性操作,但是其关于输入的梯度和输出的梯度仍然满足上述公式。
根据上述梯度公式,我们可以得到判别器网络中 关于假样本 的梯度和 关于 的梯度之间的关系:

其中 表示判别器网络 的层数; 是关于 的样本比例标量; 表示判别器 第 层的特征。
关于样本 的 对于判别器 不同的网络层是一个常数。同时对于每一个样本 都有一个对应的 。也就是说,一般不同样本 有不同的 。一方面,我们只需要计算最后一层的 ,即 ,就可以得到所有网络层的 值。这个方式只需要计算两个标量之间的比值,计算过程十分简单高效。另外一方面, 的值根据样本的不同而发生变化,因此,对于每一个样本都要重新计算一次 。由于 是两个标量: 和 的比值,因此其计算代价在整个网络训练中可以忽略不计。
结合 和上述公式,我们可以按比例从混合的梯度 :分解得到 和 ,具体如下:

也就是说,我们可以通过对 进行尺度缩放得到得到 和 。为了方便计算, 我们将上面这种尺度缩放操作应用到了损失函数 上,以实现和上述梯度分解公式相同的效果。因此,我们可以得到判别器网络 和 的实例损失函数:

其中 和 包含相同的损失项 。通过这种方式,非对称型GAN可以转化为对称型GAN。因此,可以将对称型GAN中采用的单阶段训练策略应用到非对称型GAN中。
实验分析
我们进一步分析了单阶段生成对抗网络和两阶段生成对抗网络的效率。主要从三个角度对这个问题进行了分析:1)在一个数据批训练中,真实样本的耗时和生成样本的耗时;2)前向推理的耗时和反向传播的耗时;3)关于网络参数梯度计算的耗时和反向传播的耗时。
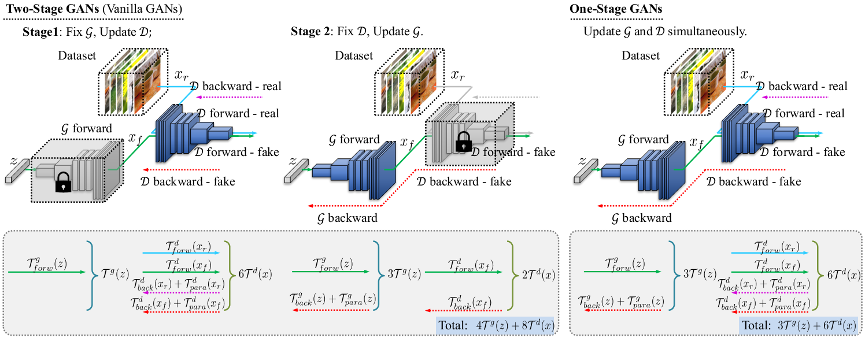 图2
经过如上图2所示的分析发现,普通 GAN 训练的两阶段耗时分别为:
图2
经过如上图2所示的分析发现,普通 GAN 训练的两阶段耗时分别为:

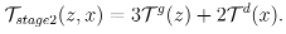
通过和两阶段生成对抗网络相同的方式,本文计算得到单阶段生成对抗网络的总耗时为:
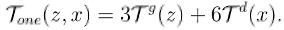
最终,我们得到了在最坏的情况下单阶段生成对抗网络相对于两阶段生成对抗网络的加速比:
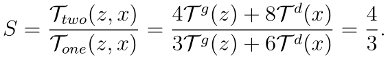
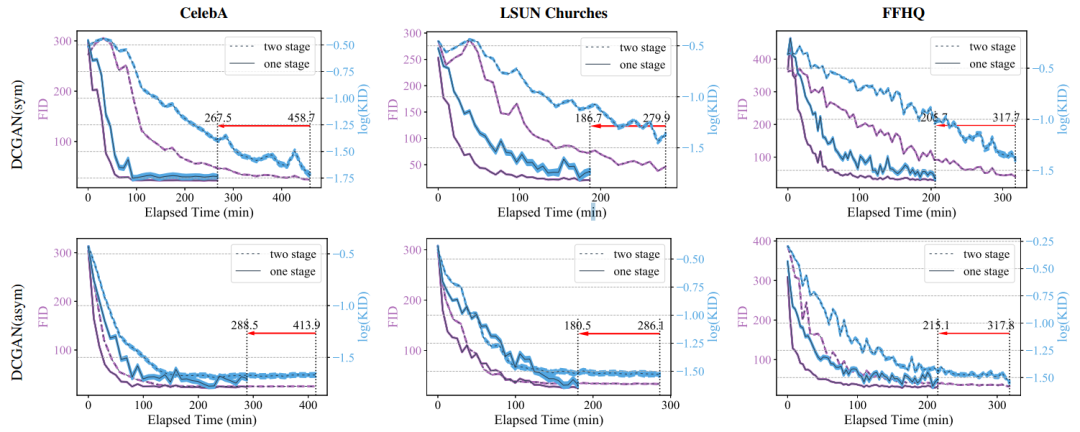 图3
图3
如上图3所示,在所有实验的效果达到稳定情况下,单阶段对称型 DCGAN 比两阶段快接近1.7倍,单阶段非对称 DCGAN 也比两阶段快1.6倍,更多性能数据参考文章 Efficiency Analysis 章节。
总结与展望
针对生成对抗技术在实际任务中训练周期长的问题,我们提出了一种单阶段的训练方法 OSGAN,该方法在相同效果下相对两阶段方法性能提升1.5倍。同时,我们运用 OSGAN 对少量标注样本进行数据增广,在拍立淘广告场景中,对少样本有监督 CNN 任务带来效果提升。未来我们将进一步探索更高效的 GAN 训练和运用方法,期待可以在更多领域和落地中得到拓展和应用。
参考文献
[1] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems (NeurIPS), pages 2672–2680, 2014.
[2] Li Liu, Wanli Ouyang, Xiaogang Wang, Paul Fieguth, Jie Chen, Xinwang Liu, and Matti Pietika ̈inen. Deep learning for generic object detection: A survey. International Journal of Computer Vision (IJCV), 128(2):261–318, 2020.
[3] Martin Arjovsky and Le ́on Bottou. Towards principled methods for training generative adversarial networks. In International Conference on Learning Representations (ICLR), 2017.
END

▐ 关于我们
阿里妈妈多模态搜索广告算法团队负责多模态搜索场景(拍立淘和找相似等)的商业化变现技术,欢迎对“计算机视觉/多模态自监督学习/搜索推荐广告”感兴趣的同学加入我们。投递简历:alimama_tech@service.alibaba.com ,或点击下方 [阅读原文] 了解岗位详情~

疯狂暗示↓↓↓↓↓↓↓
















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









