









Introduction
功能富集分析是一种用于分析基因集合或基因组数据中功能模式富集程度的计算方法。它可以帮助揭示在特定生物学背景下,哪些功能模块、代谢通路、基因家族等在统计上富集或显著过表示。
功能富集分析通常包括以下步骤:
-
数据预处理:根据研究问题和数据类型,选择适当的基因集合或基因组数据,例如基因表达数据、基因注释数据或基因列表。
-
注释和功能分类:将基因集合与已知的功能注释数据库进行比较,例如基因本体论(Gene Ontology)、KEGG(Kyoto Encyclopedia of Genes and Genomes)通路数据库等。这一步将基因与特定的功能或生物过程相关联。
-
统计分析:使用合适的统计方法,如超几何分布、Fisher’s exact test、GSEA(基因集富集分析)等,评估每个功能的富集程度。这些方法会计算一个得分或P值,用于判断功能是否在给定基因集合中富集。
-
结果解释和可视化:根据统计分析的结果,识别在给定条件下显著富集的功能模块,并将结果进行解释和可视化。这可以帮助研究人员理解基因集合或基因组数据中的生物学特征和功能。
功能富集分析可应用于多个研究领域,如基因表达分析、蛋白质组学、微生物组学等。它可以帮助研究人员理解基因集合的生物学意义,从而揭示生物过程、代谢通路、细胞组分等在特定条件下的调控机制,并为进一步的实验设计和研究提供有价值的指导。
P = 1 − ∑ i = 0 m − 1 C M i C N − M n − i C N n P=1-\sum_{i=0}^{m-1}\frac{C_M^iC_{N-M}^{n-i}}{C_N^n} P=1−i=0∑m−1CNnCMiCN−Mn−i
**P:**某pathway的富集显著性;**N:**注释上KEGG的所有基因的数量;**n:**所有显著差异的基因数量;**M:**所有基因中注释到某pathway的基因数量;**m:**所有差异基因中注释到某pathway的基因数量
R函数phyper:
1-phyper(k-1,m, N-m, n,)
phyper(k-1,M, N-M, n, lower.tail=F)
| Method | Type | Notes |
|---|---|---|
| Hypergeometric test / Fisher’ exact test | algorithm | The most common method used in enrichment analysis. There are many enrichment analysis platforms or software developed based on it, including DAVID, clusterprofile, etc. |
| Gene set enrichment analysis (GSEA) | software | Gene Set Enrichment Analysis (GSEA) is a computational method that determines whether an a priori defined set of genes shows statistically significant, concordant differences between two biological states (e.g. phenotypes). |
| Clusterprofiler | R package | ClusterProfiler automates the process of biological-term classification and the enrichment analysis of gene clusters, which calculates enrichment test for GO terms and KEGG pathways based on hypergeometric distribution. |
| Reporter score | algorithm | The plus or minus sign of reporter score does not represent regulation direction. |
| Reporter feature analysis | algorithm | Reporter feature can achieve enrichment ananlysis for non-directional, mixed-directional up/down-regulation, and distinct-directional up/down-regulation classes. |
| Piano | R package | Piano is a R package that implements the Reporter Features algorithm. Piano performs gene set analysis using various statistical methods, from different gene level statistics and a wide range of gene-set collections. Furthermore, the Piano package contains functions for combining the results of multiple runs of gene set analyses. |
Reporter score是一种改良的微生物富集分析的新方法,此方法最初是为了揭示代谢网络中的转录调控模式而开发的,目前已被引入微生物研究中进行功能富集分析。
Method
Reporter score算法最初由Patil和Nielsen于2005年开发,用于识别代谢调节热点的代谢物 (1)。
应用于宏基因组分析,则是基于基因的KO(KEGG orthology,同源基因)注释,获得KO的差异信息,再”上升”至KEGG pathway的功能层面。主要步骤如下:
-
使用Wilcoxon秩和检验获得两分组间每个KO差异显著性的P值(即 P k o i P_{koi} Pkoi,i代表某个KO);
-
采用逆正态分布,将每个KO的P值转化为Z值( Z k o i Z_{koi} Zkoi),公式: Z k o i = θ − 1 ( 1 − P k o i ) Z_{koi}=\theta ^{-1}(1-P_{koi}) Zkoi=θ−1(1−Pkoi);
-
将KO”上升”为pathway: Z k o i Z_{koi} Zkoi,计算通路的Z值, Z p a t h w a y = 1 k ∑ Z k o i Z_{pathway}=\frac{1}{\sqrt{k}}\sum Z_{koi} Zpathway=k1∑Zkoi,其中k表示对应通路共注释到k个KO;
-
评估显著程度:置换(permutation)1000次,获得 Z p a t h w a y Z_{pathway} Zpathway的随机分布,公式: Z a d j u s t e d p a t h w a y = ( Z p a t h w a y − μ k ) / σ k Z_{adjustedpathway}=(Z_{pathway}-\mu _k)/\sigma _k Zadjustedpathway=(Zpathway−μk)/σk, μ k μ_k μk为随机分布的均值, σ k σ_k σk为随机分布的标准差。
最终获得的 Z a d j u s t e d p a t h w a y Z_{adjustedpathway} Zadjustedpathway,即为每条代谢通路富集的Reporter score值,Reporter score是非方向性的,Reporter score越大代表富集越显著,但不能指示通路的上下调信息。
Misuse
最近有一篇文章就讨论了reporter-score的正负号误用问题 (2):

主要结论是 reporter score算法(上述)是一种忽略通路中KOs上/下调节信息的富集方法,直接将reporter score的符号视为通路的调节方向是不正确的。
但是我们应该可以将其改为能够考虑通路内KO上下调的方式,我称为directed 模式, 参考自https://github.com/wangpeng407/ReporterScore。
具体步骤如下:
-
使用Wilcoxon秩和检验或者t.test获得两分组间每个KO差异显著性的P值(即 P k o i P_{koi} Pkoi,i代表某个KO),再将P值除以2,即将(0,1]的范围变为(0,0.5], P k o i = P k o i / 2 P_{koi}=P_{koi}/2 Pkoi=Pkoi/2;
-
采用逆正态分布,将每个KO的P值转化为Z值( Z k o i Z_{koi} Zkoi),公式: Z k o i = θ − 1 ( 1 − P k o i ) Z_{koi}=\theta ^{-1}(1-P_{koi}) Zkoi=θ−1(1−Pkoi),由于上述P值小于0.5,则Z值将全部大于0;
-
考虑每个KO是上调还是下调,计算 Δ K O i \Delta KO_i ΔKOi,
Δ K O i = K O i g 1 ‾ − K O i g 2 ‾ \Delta KO_i=\overline {KO_{i_{g1}}}-\overline {KO_{i_{g2}}} ΔKOi=KOig1−KOig2
其中, K O i g 1 ‾ \overline {KO_{i_{g1}}} KOig1 是组1的 K O i KO_i KOi 的平均丰度, K O i g 2 ‾ \overline {KO_{i_{g2}}} KOig2 是组2的 K O i KO_i KOi 的平均丰度,然后:
Z k o i = { − Z k o i , ( Δ K O i < 0 ) Z k o i , ( Δ K O i ≥ 0 ) Z_{koi} = \begin{cases} -Z_{koi}, & (\Delta KO_i<0) \\ Z_{koi}, & (\Delta KO_i \ge 0) \end{cases} Zkoi={−Zkoi,Zkoi,(ΔKOi<0)(ΔKOi≥0)
这样的话 Z k o i Z_{koi} Zkoi大于0为上调, Z k o i Z_{koi} Zkoi小于0为下调。
-
将KO”上升”为pathway: Z k o i Z_{koi} Zkoi,计算通路的Z值, Z p a t h w a y = 1 k ∑ Z k o i Z_{pathway}=\frac{1}{\sqrt{k}}\sum Z_{koi} Zpathway=k1∑Zkoi,其中k表示对应通路共注释到k个KO;
-
评估显著程度:置换(permutation)1000次,获得 Z p a t h w a y Z_{pathway} Zpathway的随机分布,公式: Z a d j u s t e d p a t h w a y = ( Z p a t h w a y − μ k ) / σ k Z_{adjustedpathway}=(Z_{pathway}-\mu _k)/\sigma _k Zadjustedpathway=(Zpathway−μk)/σk, μ k μ_k μk为随机分布的均值, σ k σ_k σk为随机分布的标准差。
最终获得的 Z a d j u s t e d p a t h w a y Z_{adjustedpathway} Zadjustedpathway,即为每条代谢通路富集的Reporter score值,在这种模式下,Reporter score是方向性的,更大的正值代表显著上调富集,更小的负值代表显著下调富集。
但是这种方法的缺点是当一条通路显著上调KO和显著下调KO差不多时,最终的Reporter score绝对值可能会趋近0,成为没有被显著富集的通路。
Rpackage
因为我看目前没有现成的工具完成Reporter Score分析(除了一些云平台,但可能不太方便),所以我参考https://github.com/wangpeng407/ReporterScore 写了一个R包帮助分析(虽然也不是特别复杂)
地址:https://github.com/Asa12138/ReporterScore
安装方法:
install.packages("devtools")
devtools::install_github('Asa12138/ReporterScore',dependencies=T)
使用方法:
library(ReporterScore)
library(dplyr)
library(ggplot2)
#准备KO丰度表和实验metadata
data(KO_abundance_test)
head(KO_abundance)
## CG1 CG2 CG3 CG4 CG5 CG6
## K03169 0.002653545 0.005096380 0.002033923 0.000722349 0.003468322 0.001483028
## K07133 0.000308237 0.000280458 0.000596527 0.000859854 0.000308719 0.000878098
## K03088 0.002147068 0.002030742 0.003797459 0.004161979 0.002076596 0.003091182
## CG7 CG8 CG9 CG10 CG11 CG12
## K03169 0.002261685 0.004114644 0.002494258 0.002793671 0.004053729 0.002437170
## K07133 0.000525566 0.000356138 0.000445409 0.000268306 0.000293546 0.000465780
## K03088 0.003098506 0.002558730 0.002896506 0.002618472 0.002367986 0.002082786
## CG13 CG14 CG15 EG1 EG2 EG3
## K03169 0.002187500 0.001988374 0.002304885 0.003317368 0.001150671 0.002610814
## K07133 0.000507992 0.000409447 0.000327910 0.002916018 0.004820742 0.001973789
## K03088 0.002680792 0.003066870 0.002975895 0.002257401 0.002889640 0.001997586
## EG4 EG5 EG6 EG7 EG8 EG9
## K03169 0.000900673 0.001545374 0.001640295 0.001445024 0.001096728 0.001026556
## K07133 0.003359927 0.001913932 0.001384079 0.001321643 0.002376473 0.004391014
## K03088 0.002613441 0.002803388 0.002251835 0.002981244 0.002944061 0.003113215
## EG10 EG11 EG12 EG13 EG14 EG15
## K03169 0.001513195 0.001812732 0.003256782 0.006723067 0.001769819 0.001233307
## K07133 0.002479040 0.003484868 0.000790457 0.000127818 0.000634529 0.004746572
## K03088 0.003177522 0.002790092 0.001607913 0.002574928 0.001662157 0.002614489
## [ reached 'max' / getOption("max.print") -- omitted 3 rows ]
head(Group_tab)
## Group
## CG1 CG
## CG2 CG
## CG3 CG
## CG4 CG
## CG5 CG
## CG6 CG
- 分组检验获得P值,threads多线程可加速
ko_pvalue=ko.test(KO_abundance,"Group",Group_tab,threads = 1,verbose = F)
## Compared groups: CG and EG
## Total KO number: 4535
## Time use: 1.348
head(ko_pvalue)
## KO_id avg_CG sd_CG avg_EG sd_EG diff_mean
## 1 K03169 0.0026728975 0.0011094132 0.0020694937 0.0014922004 0.00060340387
## 2 K07133 0.0004554658 0.0001951678 0.0024480601 0.0014916566 -0.00199259427
## 3 K03088 0.0027767713 0.0006253559 0.0025519275 0.0004966801 0.00022484380
## 4 K03530 0.0005779169 0.0008952163 0.0005197504 0.0001435245 0.00005816647
## 5 K06147 0.0020807307 0.0007731661 0.0014321838 0.0004273716 0.00064854693
## 6 K05349 0.0021064422 0.0005243558 0.0017419317 0.0005382770 0.00036451047
## p.value
## 1 0.03671754164
## 2 0.00002654761
## 3 0.48636476395
## 4 0.01125600770
## 5 0.00987482265
## 6 0.12614740102
2.将P值矫正并转为Z-Score,这里提供两种方法(mixed就是经典的方法,另一种是directed方法)
ko_stat=pvalue2zs(ko_pvalue,mode="directed")
## ================================================================================
##
## Chi-squared test for given probabilities
##
## data: up_down_ratio
## X-squared = 21.823, df = 1, p-value = 0.000002991
head(ko_stat)
## KO_id avg_CG sd_CG avg_EG sd_EG diff_mean
## 1 K03169 0.0026728975 0.0011094132 0.0020694937 0.0014922004 0.00060340387
## 2 K07133 0.0004554658 0.0001951678 0.0024480601 0.0014916566 -0.00199259427
## 3 K03088 0.0027767713 0.0006253559 0.0025519275 0.0004966801 0.00022484380
## 4 K03530 0.0005779169 0.0008952163 0.0005197504 0.0001435245 0.00005816647
## 5 K06147 0.0020807307 0.0007731661 0.0014321838 0.0004273716 0.00064854693
## 6 K05349 0.0021064422 0.0005243558 0.0017419317 0.0005382770 0.00036451047
## p.value sign type q.value Z_score
## 1 0.01835877082 1 Enriched 0.0669268695 1.4990767
## 2 0.00001327381 -1 Depleted 0.0004777517 -3.3033110
## 3 0.24318238198 1 Enriched 0.3058325297 0.5076981
## 4 0.00562800385 1 Enriched 0.0304570375 1.8741186
## 5 0.00493741133 1 Enriched 0.0277461715 1.9150013
## 6 0.06307370051 1 Enriched 0.1607865272 0.9912305
3.将KO”上升”为pathway,计算ReporterScore:
reporter_s=get_reporter_score(ko_stat)
## =================================Checking file=================================
## ==================================load KOlist==================================
## ===================KOlist download time: 2023-05-12 00:07:41===================
## ============================Calculating each pathway============================
## ID number: 479
## Time use: 4.641
head(reporter_s)
## ID ReporterScore Description K_num
## 1 map00010 -1.6255358 Glycolysis / Gluconeogenesis 106
## 2 map00020 -1.8906022 Citrate cycle (TCA cycle) 67
## 3 map00030 -0.8261448 Pentose phosphate pathway 88
## 4 map00040 -0.6685755 Pentose and glucuronate interconversions 89
## 5 map00051 -2.2494558 Fructose and mannose metabolism 112
## 6 map00052 -0.4196662 Galactose metabolism 78
- 结果进行绘图
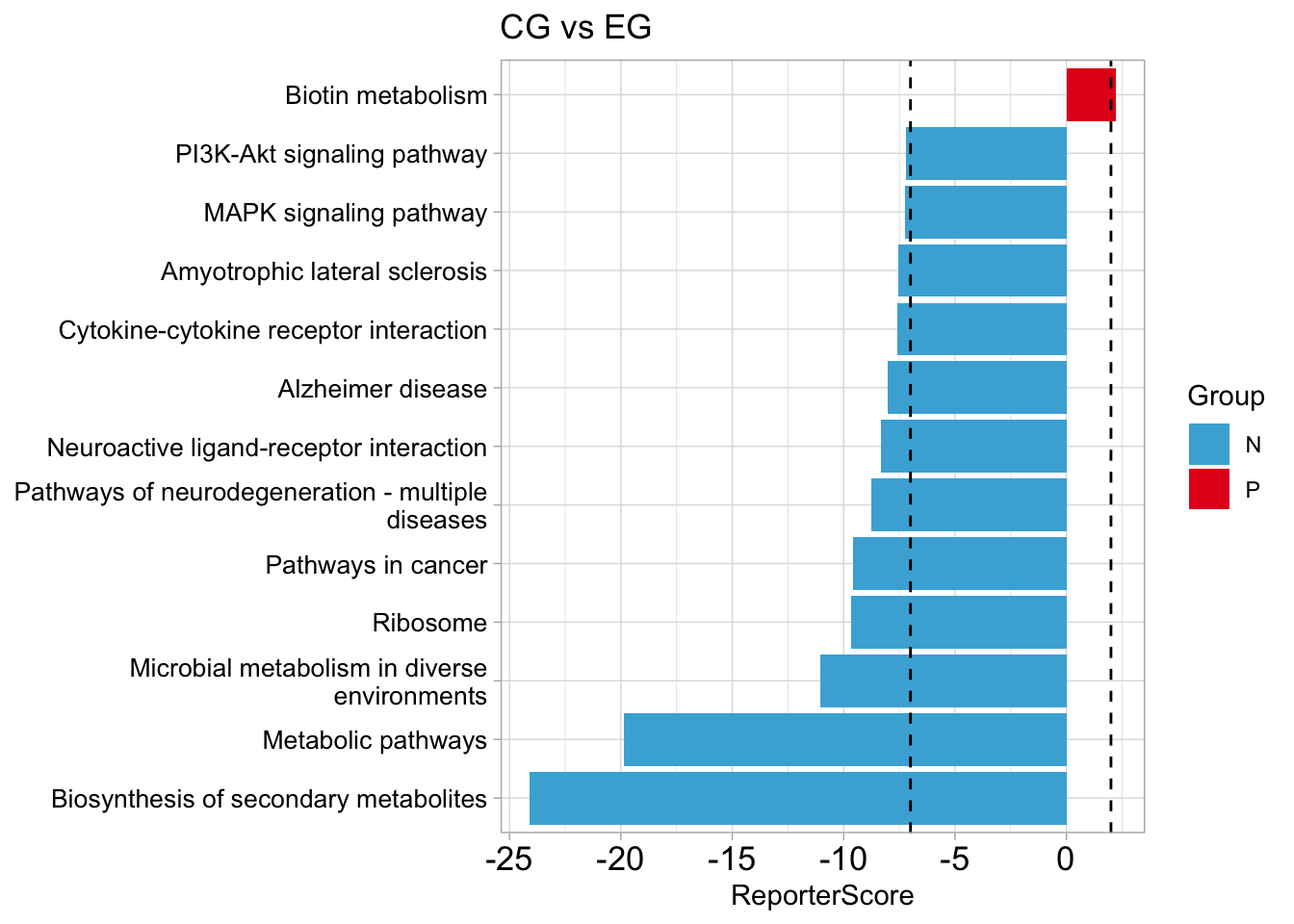
plot_report(reporter_s,rs_threshold=c(2,-7),y_text_size=10,str_width=40)+
labs(title = "CG vs EG")
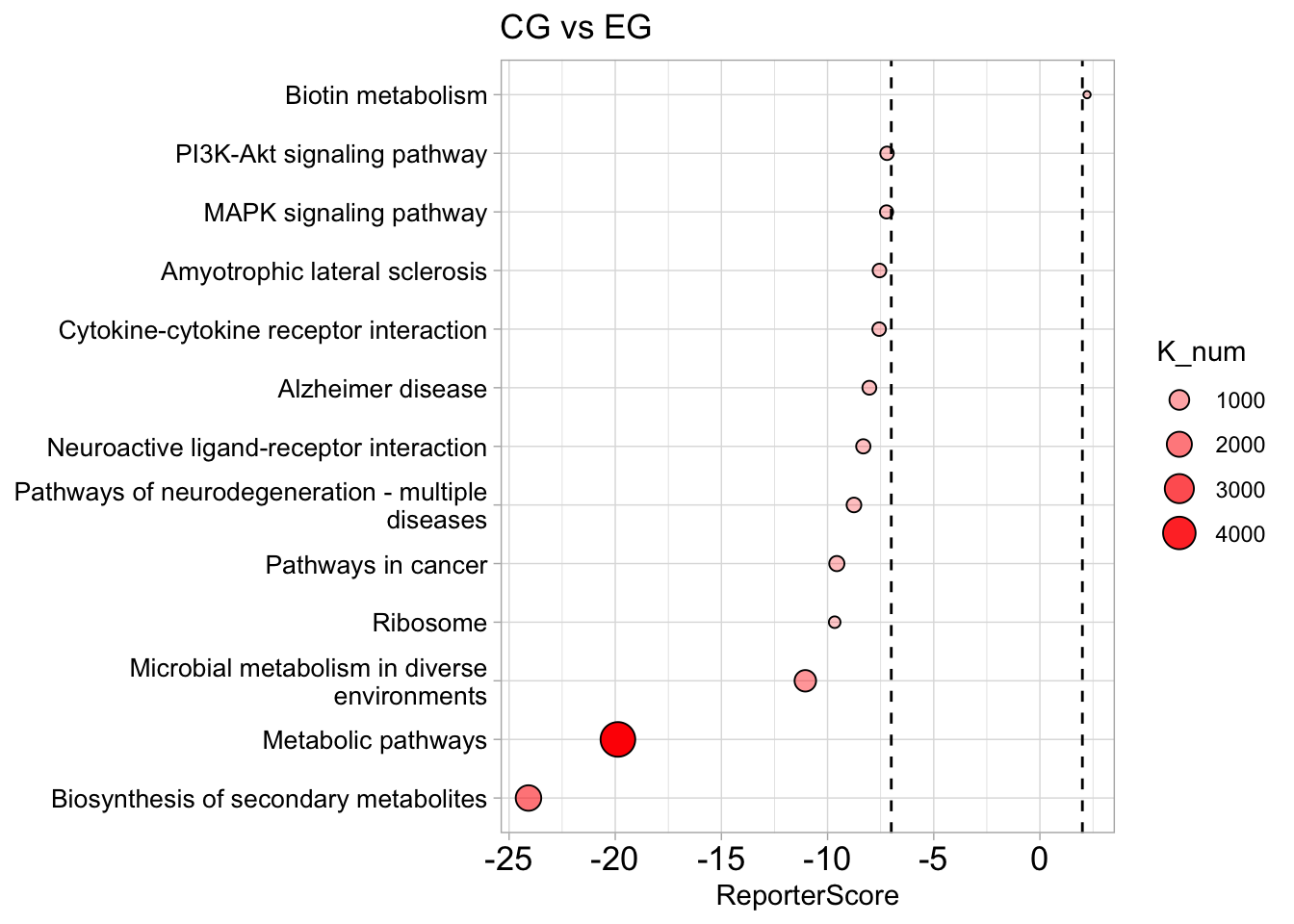
plot_report(reporter_s,rs_threshold=c(2,-7),mode = 2,y_text_size=10,str_width=40)+
labs(title = "CG vs EG")
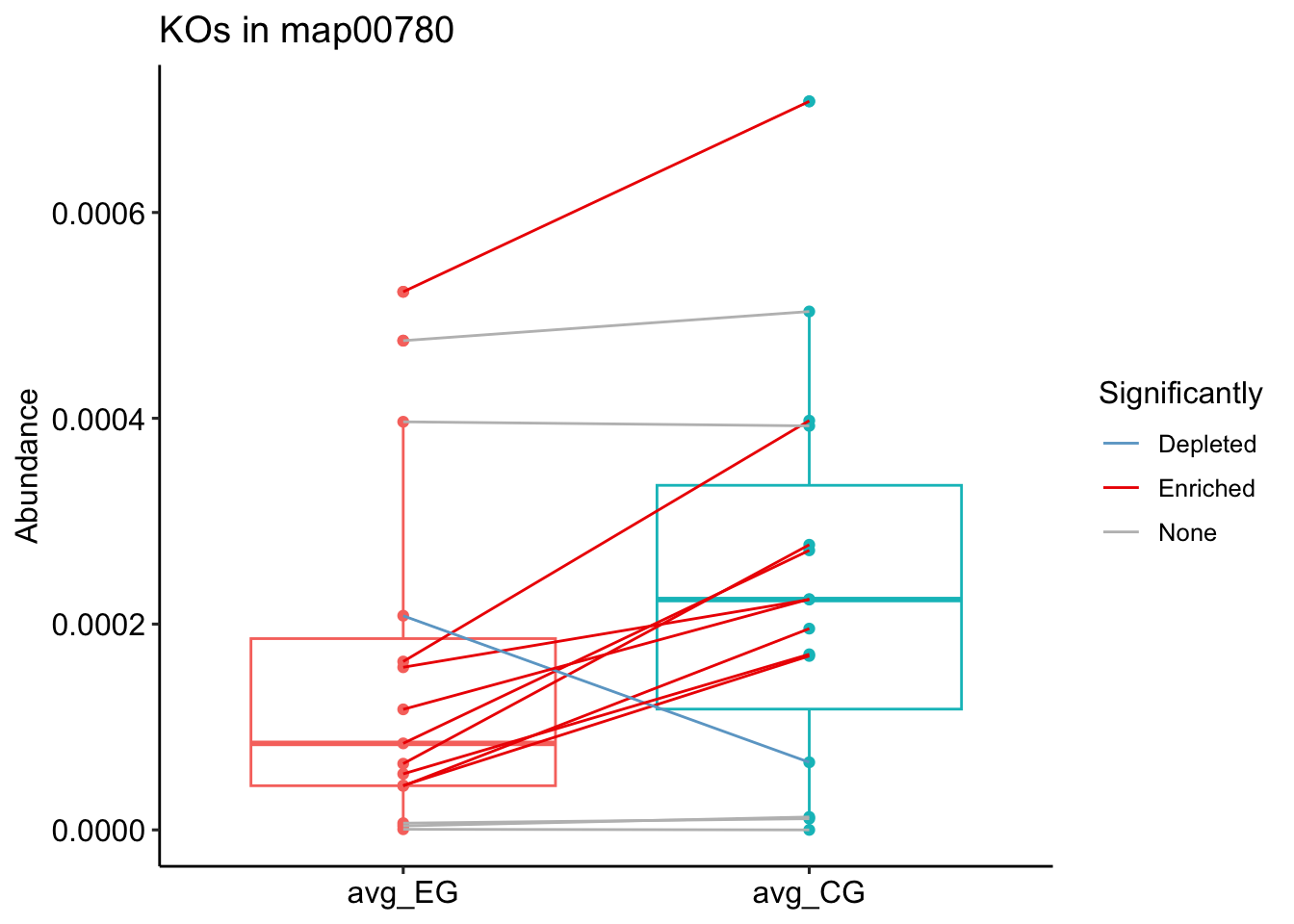
5.挑选一条通路进行绘制
plot_KOs_in_pathway(map_id = "map00780",ko_stat = ko_stat)
Reference
1. K. R. Patil, J. Nielsen, Uncovering transcriptional regulation of metabolism by using metabolic network topology . Proceedings of the National Academy of Sciences of the United States of America. 102, 2685–2689 (2005).
2. L. Liu, R. Zhu, D. Wu, Misuse of reporter score in microbial enrichment analysis . iMeta. n/a, e95.
关注公众号 ‘biollbug’,获取最新推送,或阅读原文。














 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









