







上分位数和下分位数的定义
设连续型随机变量 X X X 的分布函数为 F ( x ) F(x) F(x),概率密度函数为 f ( x ) f(x) f(x),则:
- 对于任意正数 α ( 0 < α < 1 ) \alpha(0<\alpha<1) α(0<α<1),称满足条件
F ( x α ‾ ) = ∫ − ∞ x α ‾ f ( x ) d x = α F(x_{\underline{\alpha}}) = \int_{-\infty}^{x_{\underline{\alpha}}} f(x)dx = \alpha F(xα)=∫−∞xαf(x)dx=α
的数为此分布的 α \alpha α 分位数或下 α \alpha α 分位数。
理解下 α \alpha α 分位数:从 x α x_{\alpha} xα 这个点把分布函数图像切成两个部分,左边部分面积占比 α \alpha α,右边部分面积占比 1 − α 1-\alpha 1−α。(下图右图)
- 对于任意正数 α ( 0 < α < 1 ) \alpha(0<\alpha<1) α(0<α<1),称满足条件
1 − F ( x α ) = ∫ x α + ∞ f ( x ) d x = α 1-F(x_{\alpha}) = \int_{x_{\alpha}}^{+\infty} f(x)dx = \alpha 1−F(xα)=∫xα+∞f(x)dx=α
的数为此分布的上 α \alpha α 分位数。
理解上 α \alpha α 分位数:从 x α x_{\alpha} xα 这个点把分布函数图像切成两个部分,左边部分面积占比 1 − α 1-\alpha 1−α,右边部分面积占比 α \alpha α。(下图左图)
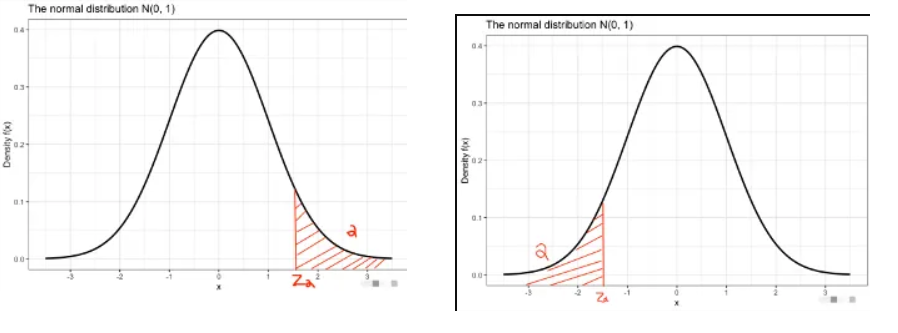
上分位数和下分位数的关系如下:
- x α ‾ = x 1 − α x_{\underline{\alpha}} = x_{1-\alpha} xα=x1−α
- x α = x 1 − α ‾ x_{\alpha} = x_{\underline{1-\alpha}} xα=x1−α
下分位数的直观理解
分位数是数理统计中用来描述数据分布的一种统计量,它将数据集分成若干个部分,使得每个部分包含相同数量的数据点。常见的分位数包括中位数(50%分位数)、四分位数(25%和75%分位数)等。
- 中位数(Median):将数据分成两部分,中位数是数据中间的值,50%分位数。
- 四分位数(Quartiles):
- 第一四分位数(Q1):将数据下25%的点分开。
- 第二四分位数(Q2):即中位数(50%分位数)。
- 第三四分位数(Q3):将数据上25%的点分开。
假设有以下一组数据:
数据集:3, 7, 8, 12, 14, 18, 20
-
计算中位数:
- 排序后的数据为:3, 7, 8, 12, 14, 18, 20
- 中位数(Q2)是中间的值,即
12。
-
计算四分位数:
- 第一四分位数(Q1):前半部分数据是
3, 7, 8,中位数是7。 - 第三四分位数(Q3):后半部分数据是
14, 18, 20,中位数是18。
- 第一四分位数(Q1):前半部分数据是
上分位数的直观理解
上分位数(Upper Quantile):一个分位数 q q q 的上分位数是指使得有 1 − q 1 - q 1−q 的数据点小于该分位数的值。
常见的上分位数:
- 上四分位数(Q1):表示25%数据点大于该值,75%数据点小于该值。
- 上中位数:在中位数(Q2)中,50%的数据点大于该值。
- 上95%分位数(即95th Percentile):表示有5%的数据点大于该值,95%的数据点小于该值。
假设我们有一组数据,表示某个考试的分数:
数据集:55, 60, 65, 70, 75, 80, 85, 90, 95, 100
计算上分位数:
-
上四分位数(Q1):
- Q1 = 65(25%的数据点大于65)。
-
上中位数(Q2):
- Q2 = 75(50%的数据点大于75)。
-
上95%分位数:
- 95th Percentile = 95(5%的数据点大于95)。
常用分布中的分位数
不同分布的符号简写:
b:二项分布p:泊松分布u:标准正态分布e:指数分布z:正态分布(不一定是标准的)
正态分布
若 X ∼ N ( 0 , 1 ) X \sim N(0,1) X∼N(0,1) 即服从标准正态分布,则分布函数记为 Φ ( x ) \Phi(x) Φ(x)。由标准正态分布的对称性可知: Φ ( − x ) = 1 − Φ ( x ) \Phi(-x) = 1-\Phi(x) Φ(−x)=1−Φ(x)。显然, P { x 1 < X < x 2 } = Φ ( x 2 ) − Φ ( x 1 ) P \{ x_1 < X < x_2 \} = \Phi(x_2) - \Phi(x_1) P{x1<X<x2}=Φ(x2)−Φ(x1)。
- 对于上分位数 u α u_{\alpha} uα,有 Φ ( u α ) = 1 − α \Phi(u_{\alpha}) = 1 - \alpha Φ(uα)=1−α
- 对于下分位数 u α u_{\alpha} uα,有 Φ ( u α ) = α \Phi(u_{\alpha}) = \alpha Φ(uα)=α
- 上下分位数之间的关系有 u α = − u 1 − α u_{\alpha} = -u_{1-\alpha} uα=−u1−α(仅标准正态分布成立)
对于自由度为 n n n 的 t 分布也有类似的结论: t α ( n ) = − t 1 − α ( n ) t_{\alpha}(n) = -t_{1-\alpha}(n) tα(n)=−t1−α(n)。当 n ( n > 45 ) n (n>45) n(n>45) 足够大时,有: t α ( n ) ≈ u α t_{\alpha}(n) \approx u_{\alpha} tα(n)≈uα
标准正态分布中常见的分位数:
- 0.25分位数(第一四分位数 Q1):约为 -0.6745,即 u 0.25 = − u 0.75 ≈ − 0.6745 u_{0.25} = -u_{0.75} \approx -0.6745 u0.25=−u0.75≈−0.6745
- 0.50分位数(中位数 Q2):为 0,即 u 0.50 = 0 u_{0.50} = 0 u0.50=0
- 0.75分位数(第三四分位数 Q3):约为 0.6745,即 u 0.75 ≈ 0.6745 u_{0.75} \approx 0.6745 u0.75≈0.6745
假设我们有一组服从正态分布 N ( 100 , 1 5 2 ) N(100, 15^2) N(100,152) 的随机变量,即均值为100,标准差为15。我们可以计算这些变量的分位数。
-
25%分位数(Q1):
- 使用标准正态分布的Q1值:约为 -0.6745。
- 实际分位数计算:
Q1 = 100 + (-0.6745 × 15) ≈ 90.87。
-
50%分位数(Q2):
- 使用标准正态分布的Q2值:为 0。
- 实际分位数计算:
Q2 = 100 + (0 × 15) = 100。
-
75%分位数(Q3):
- 使用标准正态分布的Q3值:约为 0.6745。
- 实际分位数计算:
Q3 = 100 + (0.6745 × 15) ≈ 109.12。
卡方分布
若 χ 2 ∼ χ 2 ( n ) \chi^2 \sim \chi^2(n) χ2∼χ2(n),则上分位数 χ α 2 \chi^2_{\alpha} χα2 是满足以下条件的值:
P { χ 2 > χ α 2 ( n ) } = α P \{ \chi^2 > \chi^2_{\alpha}(n) \} = \alpha P{χ2>χα2(n)}=α
这意味着有 1 − α 1-\alpha 1−α 的概率观测值会大于该上分位数值。
上分位数的应用:
- 假设检验:在卡方检验中,通常使用上分位数来决定拒绝域。例如,在检验两个分类变量的独立性时,可以使用卡方统计量与上分位数进行比较。
- 置信区间:在构建卡方分布的置信区间时,也会使用上分位数。
假设我们有一个卡方分布 χ 2 ∼ χ 2 ( 5 ) \chi^2 \sim \chi^2(5) χ2∼χ2(5),即自由度 n = 5 n = 5 n=5,我们想找出上5%分位数( α = 0.05 \alpha=0.05 α=0.05,即95%分位数):
- 查卡方分布表,找到自由度为5时,与0.95对应的上分位数 χ 0.05 2 \chi^2_{0.05} χ0.052。
- 结果为大约 11.070。
这意味着在自由度为5的卡方分布中,有5%的概率观察到的值会大于11.070。类似的还有 F 分布中的上分位数,此处不再赘述。

















 2522
2522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









