






一、准备工作
1.1,按照readme.md配置好环境
1.2,准备数据:nuscenes v1.0-mini即可,放在./data目录下即可
1.3,生成pkl
python tool/create_data.py nuscenes --root-path ../data/v1.0-mini --out-dir ../data/v1.0-mini
create_data.py 会自动调用mmdet3d的updata_infos_to_v2.py,生成mmdet3d可用的pkl文件
1.4,config配置文件
(1)
二、nuscense数据预处理
2.1 数据加载入口
2.1.1,构建runner
runner = Runner.from_cfg(cfg)按照cfg文件构建runner,会调用Runner的__init__()初始化函数进行构建。
Runner基本包含了训练、推理、测试的所有功能,以训练为例,在Runner的构建中,需要把训练所需要的配置参数、训练超参、优化器、模型、log等等都搭建好。
2.1.2,Runner构建model
self.model = self.build_model(model)其中build_model调用的是下面函数:
model = MODELS.build(model)其中MODELS是注册Register的类实例化,build是类Register的模型构建函数,调用的是下面build_model_from_cfg函数
MODELS = Registry('model', build_model_from_cfg)注册机制:
Examples:
>>> from mmengine import Registry #使用mmengine中的Registry模块
>>> MODELS = Registry('models') #实例化一个MODELS类
>>> @MODELS.register_module() # 装饰器模型注册,register_module方式搭ResNet
>>> class ResNet:
>>> def __init__(self, depth, stages=4):
>>> self.depth = depth
>>> self.stages = stages
>>> cfg = dict(type='ResNet', depth=50) #配置文件
>>> model = MODELS.build(cfg) #模型构建2.1.3,数据加载入口
初始化:
#01
runner.train()
#02
class runner():
runner.train():
self._train_loop = self.build_train_loop(self._train_loop)
#03
class runner():
def build_train_loop()
if by_epoch:
loop = EpochBasedTrainLoop(
**loop_cfg, runner=self, dataloader=self._train_dataloader)
#04
class EpochBasedTrainLoop():
init():
super().__init__(runner, dataloader)
#05
class BaseLoop().init():
self.dataloader = runner.build_dataloader()
#06
class runner():
def build_dataloader()
dataset = DATASETS.build(dataset_cfg)
#07
@DATASETS.register_module()
class NuScenesDataset(Det3DDataset):
#08
@DATASETS.register_module()
class Det3DDataset(BaseDataset):
#09
class BaseDataset(Dataset):
self.pipeline = Compose(pipeline)
#10
class Compose()
init():
intitransform = TRANSFORMS.build(transform)
#11
__call__():
for t in self.transforms:
data = t(data)
#调用
model = self.train_loop.run()
class det3d_dataset():
prepare_data():
ori_input_dict = self.get_data_info(index)
class BaseDataset():中的__getitem__()
data = self.prepare_data(idx)
dataset_wrapper.py中class CBGSDataset:中的__getitem__()
ori_index = self._get_ori_dataset_idx(idx)
nuscense_dataset.py的初始化直接调用父类det3d_dataset.py
det3d_dataset.py中的
prepare_data():
example = self.pipeline(input_dict)会调用父类:base_dataset.py 中的
self.pipeline = Compose(pipeline)
通过Compose类的_init_函数来build transformes,通过__call__函数实现transformes的各个级联操作。
for t in self.transforms:
data = t(data)如果要增加预处理操作,需要在transformes增加新的类,可参考loading.py,然后在__init__.py中进行报备。就可以通过Transformes=Registry() --Transformes.build()对预处理操作进行实现。
2.2 数据预处理
数据预处理包含以下pipline:

2.2.1 LoadPointsFromFile /加载关键帧点云
points 维度[n, 5],其中5=[x,y,z,i,id],id从0到n
point_class有以下种类:bev,color,coord,device,height,shape

返回results内容包括如下,其中results[‘points'] 为关键帧的点云数据。

2.2.2 LoadPointsFromMultiSweeps /加载sweep点云
根据 results['lidar_sweeps']['lidar_points']['lidar_path'] 路径取出sweeps的点云,与关键帧点云拼接到一起,最后给到 results['points'] 。
2.2.3 LoadAnnotations3D 加载label
Annotation3d 格式:
gt_bboxes_3d:【x,y,z,l,w,h,yaw,vx,vy】共9维。
gt_bboxes_label:【1,2,3,4,5...】
2.2.4 ObjectSample /采样gt到data
-
use_ground_plane:是否使用地面平面
从gt中采样的最大数量:这个采样后总目标数有点少,可以适当增加一些。

transform(): self.db_sampler.sample_all()
会调用基类中的dbsampler::sample_all()函数,对sample的真值目标的点云和box与本帧进行融合。
2.2.4 GlobalRotScaleTrans /将全局旋转、缩放和平移应用于一个三维场景。
-
_rot_bbox_points 旋转
-
_scale_bbox_points 缩放
-
_trans_bbox_points 平移
2.2.5 RandomFlip3D 随机旋转
2.2.6 PointRangeFilter /点云范围过滤
2.2.7 ObjectRangeFilter /目标范围过滤
2.2.8 ObjectNameFilter /目标类别过滤
2.2.9 PointShuffle /点云乱序
2.2.10 Pack3DDetInputs /转换为mmdet3D默认的输入格式
三、模型训练
3.1 输入格式 example
data_samples: 里面包含了很多变量,是满足Det3DDataSample(mmdetection3D数据结构接口)的格式,其中最主要的是gt_instances_3d,3D真值框(原始labels+从gt中sample的labels)。
points:主要包括点云数据(原始点云+从gt中sample的点云)。

3.2 Det3DDataPreprocessor /点云体素化处理
对于second:体素化的最大数量最好为20000,centerpoint的最大体素数量为9000. (可以根据实际场景测试看多少个体素基本可以把场景点云覆盖得到,如下面的coors_out);调用体素化之前必须要对点云进行shuffle,因为会有很多点被扔掉。一个点云范围总共可以有1000*1000*40个体素,不会都用到,达到体素数量总数后,后面的点云会被直接抛弃。
体素化处理有两种:hard(单元voxel里点云固定数量,centerpoint为10,这个值可能小了有点)和dynamic(单元voxel里点云数量动态的,默认为35)。
体素化过程调用了外部c++的函数:这个函数的实现是在bevfusion里voxelization_cpu.cpp;


对于体素化过程,关注两个参数就足够了:voxel数量、单voxel点云数量。根据实际场景配置好即可。最后的输出:
- voxel的shape=[n,10,5],n个体素、每个体素10个point,每个point包括5个维度[x,y,z,i,*]
- coors_out的shape=[n,3];n为不为空的体素个数,值并非物理世界坐标,而是在体素空间的位置坐标,后面需要转为真实物理世界的三维坐标。可根据coors_out的维度看每帧大概多少个不为空的体素,然后设定最大的体素数量的参数。
- num_points_per_voxel_out的shape为n,n为不为空的体素个数。里面的值为每个体素内的point数量。
voxelization模块输出:
voxel_dict['voxels'] = voxels #[n,10,5] voxel_dict['coors'] = coors #[n,4] 补了一维0
整个数据预处理的输出:
'inputs': batch_inputs, #voxel_dict 'data_samples': data_samples #labels
3.3 HardSimpleVFE /体素特征提取、second中的体素特征encoder
体素内所有点的均值
模块输出:points_mean=[n,5]
体素特征提取:
3.4 SparseEncoder /稀疏卷积模块
输入:
voxel_features = [n,5]
SparseConvTensor = [n,5] 维度和点云范围有关

经过encoder_layer之后,点云维度变为[n,128]
然后经过dense(scatter_nd 操作) 稠密处理,点云维度变为:
N, C, D, H, W = [1,128,2,128,128]
输出维度:
spatial_features 把C*D维度合成一维:[1,256,128,128]
3.5 SECOND
输入tensor:x = [1,256,128,128]
该部分模型基本为2D conv网络层
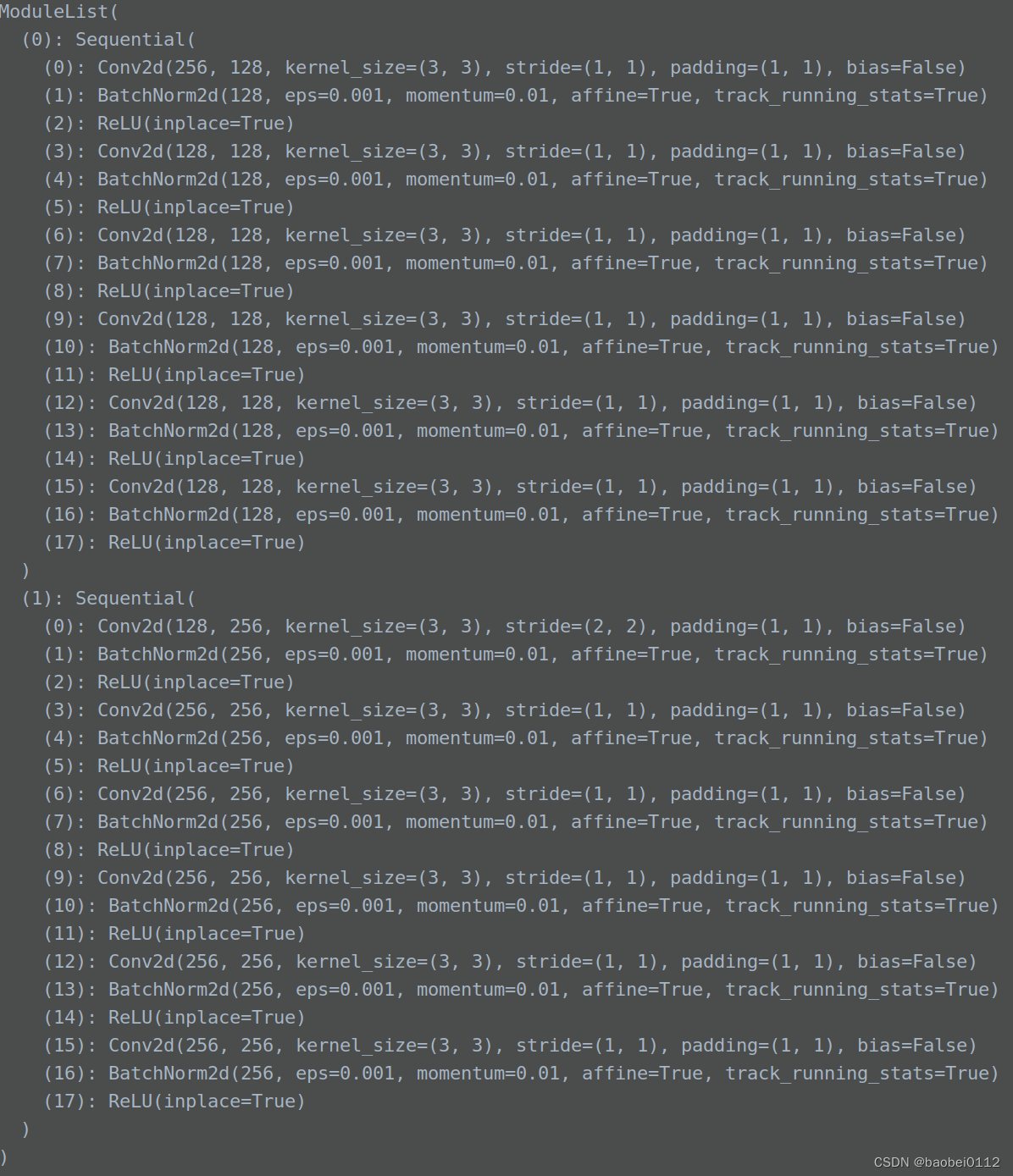
回顾下second网络结构

second模块输出维度:
out1 = [1,128,128,128]
out2 = [1,256,64,64]
3.6 SECOND-FPN

输出维度:
out1 = [1,256,128,128]
out2 = [1,256,128,128]
最终out = out1+out2 = [1,512,128,128]
3.7 CenterHead
每个任务都有一个 task_heads,同时对应一个seperate_Head:

每个seperate_Head,包括以下一些结果输出:

所以最后的输出out:

其中 :
reg=[1,2,128,128]
height=[1,1,128,128]
dim=[1,3,128,128]
rot=[1,2,128,128]
vel=[1,2,128,128]
heatmap=[1,1,128,128]
3.8 loss
分类loss:GaussianFocalLoss()

------------------------------------------------------------------------------------------------------------------------------
build_model——centerpoint——mvx_two_stage——VFE/sparse-encoder/second/fpn/centerhead
build_loop——loop——EpochBasedTrainLoop——base_loop:
build_dataloader——nuscense_dataset——det3d_dataset——base_dataset——pipline
runner.py
train():
model = self.train_loop.run()
loops.py中
run()
run_epoch():
##从这句开始调用pipline处理数据
for idx, data_batch in enumerate(self.dataloader):
self.run_iter(idx, data_batch)
det3d-dataset.py:
prepare_data():
example = self.pipeline(input_dict)
runner.train():
model = self.train_loop.run() # type: ignore
loops.py中run():
run_epoch():
for idx, data_batch in enumerate(self.dataloader): self.run_iter(idx, data_batch)
run_iter():
outputs = self.runner.model.train_step( data_batch, optim_wrapper=self.runner.optim_wrapper)
base-model.py中
train-step()
with optim_wrapper.optim_context(self): data = self.data_preprocessor(data, True) losses = self._run_forward(data, mode='loss') # type: ignore
_run_forward():
if isinstance(data, dict): results = self(**data, mode=mode)
mvx_two_stage.py中
loss():
img_feats, pts_feats = self.extract_feat(batch_inputs_dict,
batch_input_metas)
losses_pts = self.pts_bbox_head.loss(pts_feats, batch_data_samples,
**kwargs)
extract_feat():
pts_feats = self.extract_pts_feat( voxel_dict, points=points, img_feats=img_feats, batch_input_metas=batch_input_metas)
extract_pts_feat():
##HardSimpleVFE
voxel_features = self.pts_voxel_encoder(voxel_dict['voxels'],
voxel_dict['num_points'],
voxel_dict['coors'], img_feats,
batch_input_metas)
batch_size = voxel_dict['coors'][-1, 0] + 1
## sparse-encoder
x = self.pts_middle_encoder(voxel_features, voxel_dict['coors'],
batch_size)
##second backbone
x = self.pts_backbone(x)
##second-FPN
if self.with_pts_neck:
x = self.pts_neck(x)
mvx_two_stage.py中
loss():
img_feats, pts_feats = self.extract_feat(batch_inputs_dict,
batch_input_metas)
losses_pts = self.pts_bbox_head.loss(pts_feats, batch_data_samples,
**kwargs)
center_head.py中
loss():
##计算head输出
outs = self(pts_feats)
##计算loss结果 losses = self.loss_by_feat(outs, batch_gt_instance_3d)
loss_by_feat():
loss_heatmap = self.loss_cls( preds_dict[0]['heatmap'], heatmaps[task_id], avg_factor=max(num_pos, 1))
loss_bbox = self.loss_bbox( pred, target_box, bbox_weights, avg_factor=(num + 1e-4))
base_model.py中
train_step():
parsed_losses, log_vars = self.parse_losses(losses) ##更新模型参数 optim_wrapper.update_params(parsed_losses)














 3137
3137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









